CUDA应用:GPU加速的离线渲染技术
NVIDIA Gelato、Tesla、CUDA是一股对传统基于CPU的渲染器挑战的力量。GPU在诸多方面具有软件实现无可比拟的优势比如光栅化部分,遮挡剔除,以及潜在的并行计算能力,但是编程性实在缺少基于CPU的自由度,所以在相当的一段时间内还无法充分发挥性能。本文讨论了下基于GPU、CPU这种混合体系下的渲染器架构,相当思路也是Gelato所采用的。
离线渲染与实时渲染的最大不同在于,前者是近似于忽略性能的照片级渲染,Shader的代码数以万行,纹理尺寸高达上G,导致的结果,一个是我们可以看到乱真的火爆电影场面,另一个就是渲染时间。虽然硬件在不断的发展,Render Farm(以下简称RF)在不断的更新,可是为了达到理想中的效果,即使已经有了20年发展历程的渲染器(主要是Pixar RenderMan与mental ray,以下简称RM与MR),每一帧的渲染对硬件资源的需求依旧是无止境——加勒比海盗3中的场景平均每一帧需要大约70小时,况且ILM使用的RF肯定不会差,应该是最好的。对于电影工业这种与娱乐市场紧密结合的行业来说,时间就是金钱,也许,明天也许就是dealine。
GPU的优势在于高度的并行机制,极其快速的光栅化部件。但是它也是个这样的工厂:所有的原始材料必须同时投入这个黑盒,执行的时候不能中断过程也不可见。所以我们很自然的想到可以使用它来做基本的光栅化操作。但是如果想直接使用GPU渲染几何体这几乎是不可能做到的,首先是GPU的渲染能力有限,其次在于直接光栅化的质量太差。
Occlusion Query
对于一个拥有数量级多物体的场景,我们在渲染前一定要进行遮挡查询,只将我们感兴趣的物体留在屏幕上,其余的可以不需要载入内存。因为在现代渲染器的时间都耗费在Shading上,也就是一堆简单的加加减减的数学操作上,但是计算数量相当的巨大,而不是光线求交,光线求交只是性能耗费极少的一部分。在CPU上我们有些方法可以计算物体的包围盒是否在摄像机的Frustrum里(这个词见过许多版本,从锥台到平截头体的都有,干脆我就不说它了),或者是软件光栅化的方式判断是否可见。对于GPU来说,最简单的莫非于使用OpenGL的ARB_occlusion_query进行查询。对于GPU这样的设备来说最好的工作方式就是给它一大堆数据而不要任何“回报”——回读操作Readback。使用图形管线的这个功能只是给它一大堆不需要着色的立方体,而返回的仅仅是每个立方体将在屏幕上出现的象素数目,很自然的,当返回的数字为0那么就知道这个物体不会在屏幕上出现。记住,NVIDIA的硬件可以以双倍的速度渲染深度。有的人可能会疑问,这样一股脑儿的把数据交给GPU效率高么?答案是,高。因为即使是基于CPU的软件渲染器依然要经过这样的一步。Gelato就是使用了这个来判断物体是否会在屏幕上出现。至于如何使用ARB_occlusion_query大家可以去参考NVIDIA的OpenGL Sepcifiction以及NVSDK中的范例来学习。
Antialiasing Shading
为什么RM或者MR渲染的画面好像没有锯齿?因为它们都使用了Supersampling或者类似的技术,根据用户设定的Rate数值决定实际渲染的Bucket分辨率,一般是从4x到16x,使用过滤器过滤后就缩小为我们设定的Bucket的大小。为什么RM的内存占用率很小?因为它每次只镶嵌一小部分物体将它们打散为多边形,而且Geometry Cache可以多达5级。为什么RM使用的是顶点着色可以达到这样的效果而GPU如果用Per Vertex的光照方式得到的画面是那么的丑陋?因为它的微多边形比象素还要小的多,所以在这些micropolygon上进行Shading要比在Pixel上Shading还要精细的多。
类似的,NVIDIA Gelato依旧是需要对几何体模型进行镶嵌,最后生成Grid,这样每个二次面片就可以当作一个GL_QUADS让OpenGL的管线去做光栅化等等操作。由于此时每个顶点都足够精细,所以此时Per Vertex的光照计算就可以满足要求。当Dicing Rate与Shading Rate不同的时候,此时数据就不在是针对每个顶点的。Gelato将数据装入FP32纹理中进行操作,可惜硬件还无法对这样的纹理格式做过滤,所以渲染质量比起软件的实现会有大约15%的差距。
随后就是超级采样Super Sampling,和随机采样Stochastic Sampling。对于GPU来说,根本不存在实现底层随机采样的可能。因为GPU硬件的光栅化部分是专有而且封闭的,而软件的实现却可以在CPU上自由发挥。所以使用Accumulation操作来模拟是完全可行的。比如这个图,出现在《GPU GEMS2》中,也在Larry Gritz的siggraph 2007的Talk中出现过。

上边是规则采样,下面是随机采样,样本数目从左到右依次为1、4、16、32。
Motion Blur and Depth Of Field
一提到MB就应该想到空间内基于几何体的MB,而不是实时渲染所使用的那种基于屏幕空间的MB。Gelato的MB实现包括Vertex Motion与Per-Pixel Time Sampling来实现MB与DOF。
MB与DOF使用Vertex Buffer Object避免多次数据上传,所有的Accumulation的操作都是在GPU上完成以避免回读。使用Vertex Shader实现Model View Projection变换、插值,针对每个Pass的每个象素计算相应的镜头参数。操作是针对整个Bucket进行的,当提高Pass的数目后可以有效的减少失真。Gelato自动的根据当前渲染的需要选择合适的Pass数目,这样可以有效的提高整体性能。
Transpancy
一个词,深度剥离Depth Peeling。
深度剥离是为了处理透明物体的渲染而发明的技术,原始的版本可以在NVIDIA Developer网站上找到。说白了就是用Multi Pass的方式逐层的把后面透明的、但是被剔除的层给叠加到现有的画面上。但是GPU到现在为止依旧不支持FP32精度的Alpha Bleeding,况且,透明效果有些时候是留给后期人员制作的。
微软亚洲研究院有篇Paper叫做《Multi-Layer Depth Peeling via Fragment Sort》,使用了GPU的MRT能力加速生成深度剥离图层,比原始方法提高了一倍左右的效率。具体详情可以去相应站点去找资料。
Interactive Relighting
无庸置疑,电影动画的创作是一门艺术,而艺术家在制作的时候往往非常迫切的需要看到自己打的灯光在实际场景中效果如何,所以我们需要提供一种辅助的Relighting工具让艺术家指导自己的创作。有些朋友可能会问,难道不能预先渲染一些帧查看效果么。是的,这样可以,但是这样浪费了时间,而且很多东西是不需要渲染的,比如完全模糊抗锯齿的阴影,精确的DOF效果,这些统统都是不需要的,艺术家往往只需要去看他所感兴趣的物体的光照效果,其它的一概忽略,所以Relighting工具需要提供这样的迅速以及自由度。Relighting系统的发展也是走过了一个阶段,其中不乏世界顶级工作室与大学的合作。
|
|
A Fast Relighting Engine for Interactive Cinematic Lighting Design from Stanford University |
| |
Lpics: a Hybrid Hardware-Accelerated Relighting Engine for Computer Cinematography from Pixar Studio |
| |
appeared in the Siggraph 2006 Direct-to-Indirect Transfer for Cinematic Relighting from Conell University Dartmouth College |
| |
appeared in the Siggraph 2007 The Lightspeed Automatic Interactive Lighting Preview System from MIT CSAIL, Industrial Light & Magic, Tippett Studio |




从最新的那片Paper看来,使用GPU加速的Relighting已经成为主流趋势,它的流水线如下图所示:
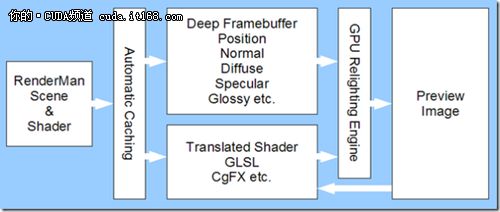
这其中牵涉到的最复杂的部分莫过于Shader的翻译,其次才是Scene的解析。为什么说Shader的翻译是最复杂的,因为这和GPU本身的限制有关。在一部电影中所使用的Shader一般都有几万行,单纯一个物体的渲染就是有大量的几何体、Shader以及Texture。由此导致的结果是,很多RenderMan能跑的,渲染时间上能够忍受的Shader将无法在GPU上执行,我们需要简化以及修改RenderMan Shader,翻译为GPU所能执行的Shader,GLSL、HLSL或者是CgFX等Shading Language。其次才是几何体的简化。由于我们一般来说只是预览一个物体的光照效果,其它的操作比如光线跟踪等一般来说是不需要的,所以就需要为高精细的模型做适当的简化,让GPU可以轻松的处理为Render Target,然后再着色。这种方式类似于Defered Shading延迟着色,不过它准备的材料要比实时渲染多的多了,BRDF数据等等都需要准备好,这样我们才能看到一个与真实结果差不多的效果图。如那个酷酷的大黄锋。(有时我想,未来硬件提高了后,实时渲染是不是也可以使用类似于Relighting的思路,真正达到电影级别的效果)
Shading
事实上,最复杂的部分莫过于Shading部分,尤其是当希望CPU与GPU整合的时候。有些OP在GPU上操作非常快,比如算术运算、三角函数等等,但是其它的一些OP,比如RenderMan中的gether与trace,在GPU上是根本无法使用的。有些朋友可能会问:早就有基于GPU的Raytracer了。是的,不错,但是对于surface shader来说,所有的执行过程应该是连续的,不可以打断的,而且对于这些OP的调用也不是间间单单的计算,而是需要回到CPU层次上,检查光线与物体包围盒的相交情况,然后再将命中的物体传入GPU管线计算求交,而且根据我们希望返回的数值来看,很有可能是迭代Shading的过程。所以,对于简简单单的一个光线跟踪来说,需要三个任意:起始点任意、方向任意、返回数值任意,所以,开发一款使用GPU加速的电影级渲染器,除了硬件厂商比如NVIDIA,其它的厂商极难从底层的加速做起。
结论
GPU是个好资源,可是非常的棘手。我是希望从编译器层次考虑,实现一个虚拟机解释执行编译后的Shader代码或者是基于伪汇编层次的优化,将部分拆解为PTX与CPU OP来顺序执行,保证上下文一致性不被破坏,而且性能有所提高。当GPU工作的时候,CPU可以空闲下来,这样CPU也可以进行Shading工作,这样就实现了加速,当然不苛求加速比,这也是诸多开源渲染器无法立足的原因,单纯的对RT部分优化而忽略了制作方面的需求,这样就成为了一个玩具而不是工业产品。所以我决定把今后的分析时间放在GPU加速的Shading的、光栅化部件的使用技术,而不是纯粹的光线跟踪。