安装条件:
redhat centos7 java1.8 hadoop3.2.1
前言:
此次安装重在配置!
各个虚拟机之间root用户之间的ssh免密登录:
https://blog.csdn.net/mo_ing/article/details/81042816
1、在node01上生产一对钥匙(公钥和私钥)
首先在root用户下,执行
#ssh-keygen -t rsa
一路回车,接着会产生在/root目录下会产生.ssh目录
查看 .ssh 目录,会发现它下面生成了两个 id_rsa , id_rsa.pub文件
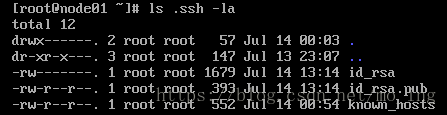
known_hosts文件是通过ssh node02(就是通过ssh登录其他主机)产生的,而不是通过执行ssh-keygen -t rsa命令产生,请不要弄错。
2、在node01上将公钥(id_rsa.pub)拷贝到其它节点,包括本机
#ssh-copy-id ip或hostname
3、在node02节点上和node03节点都要重复上述1、2操作,分别产生各自的一对钥匙,并拷贝到其它节点(包括本机)
安装jdk并配置环境:
查看《linux之springboot项目》
下载安装hadoop:
#cd /usr/local/src
#wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
# tar -xvf hadoop-3.2.1.tar.gz -C /usr/local/

#cd /usr/local/
#sudo mv ./hadoop-3.2.1/ ./hadoop 修改文件夹名称
# sudo chown -R hadoop ./hadoop 如果另创用户hadoop,则赋予权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
#cd /usr/local/hadoop/
#./bin/hadoop version
修改配置文件:
在/etc/profile中,添加下面配置:
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_HOME=/usr/local/hadoop/
export HADOOP_OPTS="- Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
同时将hadoop添加到系统变量:
export PATH=$PATH:$/usr/local/hadoop/bin:$PATH
【后续出现的 ./bin/...,./etc/... 等包含 ./ 的路径,均为相对路径,以 /usr/local/hadoop 为当前目录。】
在hadoop-env.sh中添加:
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
伪分布式:
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件core-site.xml和hdfs-site.xml。
修改配置文件core-site.xml(通过 gedit 编辑会比较方便:gedit ./etc/hadoop/core-site.xml),将当中的
修改为下面配置:
同样的,修改配置文件hdfs-site.xml:
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行,所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化:
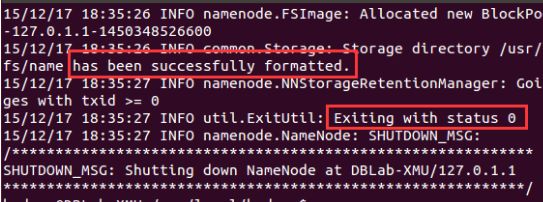
#./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
开启 NameNode 和 DataNode 守护进程:
# ./sbin/start-dfs.sh
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
问题集锦:
1、WARNING: HADOOP_SECURE_DN_USER has been replaced by DFS_DATANODE_SECURE_USER.
将 sbin/start-dfs.sh 和 vim sbin/stop-dfs.sh 两个文件中的一下内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
转换为:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
如果还报错 可以考虑检查$HADOOP_HOME/etc/hadoop/ 目录下的hadoop-env.sh:
export HDFS_DATANODE_USER=root
export HADOOP_SECURE_DN_USER=hdfs
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
在第二行发现问题,将
export HADOOP_SECURE_DN_USER=hdfs
修改为
HDFS_DATANODE_SECURE_USER=hdfs
2、WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable :
开启debug方便找原因
# export HADOOP_ROOT_LOGGER=DEBUG,console
# ./sbin/start-dfs.sh 启动并查看debug报错信息:
Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError,这表明是java.library.path出了问题。
需在hadoop-env.sh中添加:
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
3、执行 hadoop fs -ls时报错:hadoop:commend not find
#vi /etc/profile
将hadoop添加到系统变量中:
export PATH=$PATH:$/usr/local/hadoop/bin:$PATH
#source /etc/profile
4、问题过程中遇到的比较好的链接:
http://blog.csdn.net/l1028386804/article/details/51538611
http://blog.csdn.net/xichenguan/article/details/38797331
http://www.chinahadoop.cn/classroom/5/thread/43
http://www.powerxing.com/install-hadoop-in-centos/
5、比较好的安装教程:
完全分布式:
https://blog.csdn.net/s1078229131/article/details/93846369
集群搭建:
https://blog.csdn.net/qq_41515513/article/details/101873098