Flink如何解决端到端Exactly-Once的一致性
故障恢复与一致性保障
某条数据投递到某个流处理系统后,该系统对这条数据只处理一次,提供Exactly-Once的保障是一种理想的情况。如果系统不出任何故障,那简直堪称完美。然而现实世界中,系统经常受到各类意外因素的影响而发生故障,比如流量激增、网络抖动、云服务资源分配出现问题等。如果发生了故障,Flink重启作业,读取Checkpoint中的数据,恢复状态,重新执行计算。
Flink的State和Checkpoint机制:
- 在Flink中进行有状态的计算
- Flink Checkpoint机制

Checkpoint和故障恢复过程可以保证内部状态的一致性,但有数据重发的问题,如下图所示。假设系统最近一次Checkpoint时间戳是3,系统在时间戳10处发生故障,在Checkpoint之后和故障之前的3到10期间,系统已经处理了一些数据(图中时间戳为5和8的数据)。从上帝视角来看,我们假设系统在时间戳10处发生的故障,但实际场景中,我们是无法预知故障发生的时间,只能是故障发生后,收到报警信息,并知道最近一次的Checkpoint时间戳是3。重启后,我们可以从最近一次的Checkpoint数据中恢复,整个作业的状态被初始化到时间戳3处。为了保证一致性,时间戳3以后的数据需要重新处理一遍,在这个例子中时间戳为5和8的数据被重新处理。Flink的Checkpoint过程保证了一个作业内部的数据一致性,主要因为Flink将两类数据做了备份:
- 作业中每个算子的状态
- 输入数据的偏移量Offset
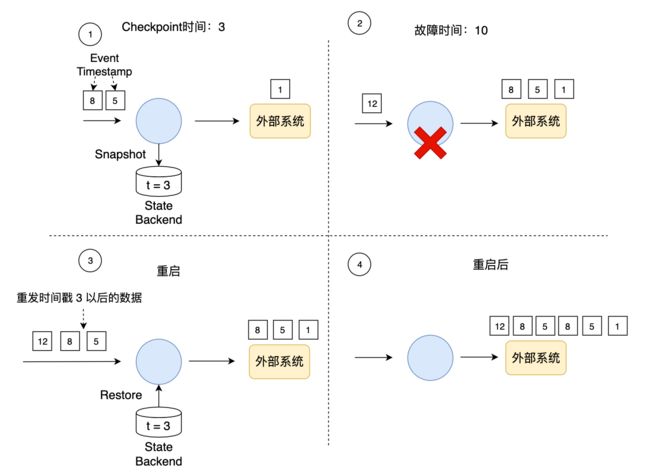
数据重发的过程就像观看实时直播的比赛,即使错过了一些精彩瞬间,我们可以从录像中再次观看重播,英文单词Replay能非常形象地描述这个场景。但是这引发了一个问题,那就是时间戳3至10之间的数据被重发了。故障之前,这部分数据已经被一些算子处理了,甚至可能已经发送到外部系统了,重启后,这些数据又重新发送一次。一条数据不是只被处理一次,而是有可能被处理了多次(At-Least-Once)。从结果的准确性角度来说,我们期望一条数据只影响一次最终的结果。如果一个系统能保证一条数据只影响一次最终结果,我们称这个系统提供端到端的Exactly-Once保证。
端到端的Exactly-Once问题是分布式系统领域最具挑战性的问题之一,很多框架都在试图攻克这个难题。在这个问题上,Flink内部状态的一致性主要依赖Checkpoint机制,外部交互的一致性主要依赖Source和Sink提供的一些功能。Source需要支持重发功能,Sink需要采用一定的数据写入技术,比如幂等写或事务写。
对于Source重发功能,如上图所示,只要我们记录了输入的偏移量Offset,故障重启后数据发送方从该Offset重新开始发送数据即可。Kafka的Producer除了发送数据,还会将数据持久化写到日志文件中。如果下游应用重启,Producer根据下游提供的Offset,从持久化的文件中定位到数据,可以重新开始向下游发送数据。
Source的重发会导致一条数据被处理多次,为了保证只对下游系统产生一次影响,还需要依赖Sink的幂等写或事务写。下面重点介绍这这两个概念。
幂等写
幂等写(Idempotent Write)操作是指,任意多次向一个系统写入数据,只对目标系统产生一次结果影响。例如,重复向一个HashMap里插入同一个Key-Value二元对,第一次插入时这个HashMap发生变化,后续的插入操作不会改变HashMap的结果,这就是一个幂等写操作。重复地对一个整数执行加法操作就不是幂等写,因为多次操作后,这个整数会变大。
像Cassandra、HBase和Redis这样的KV数据库一般经常用来作为Sink,用以实现端到端的Exactly-Once。需要注意的是,并不是说一个KV数据库就百分百支持幂等写。幂等写对KV对有要求,那就是Key-Value必须是可确定性(Deterministic)计算的。假如我们设计的Key是:name + curTimestamp,每次执行数据重发时,生成的Key都不相同,会产生多次结果,整个操作不是幂等的。因此,为了追求端到端的Exactly-Once,我们设计业务逻辑时要尽量使用确定性的计算逻辑和数据模型。
KV数据库作为Sink还可能遇到时间闪回的现象。我们仍以刚才的数据重发为例,假设时间戳5的数据经过计算产生一个(a, t=5)的KV对,时间戳8的数据经过计算产生一个(a, t=8)的结果,不同的元素对同一个Key产生了影响。重启前,(a, t=5)与(a, t=8)先后提交给了数据库,两行数据都基于同一个Key,当(a, t=8)被提交到数据库时,数据库一般认为当前这次提交是最新的,它会将(a, t=5)这行老数据覆盖,这时数据库中应该保存(a, t=8)这条结果。不幸的是,后来发生了故障重启,重启后的最初那段时间,(a, t=5)再次提交给数据库,数据库此时错误地认为这次又是最新的操作,它会再次更新这个Key,但实际上又回退到了时间戳5。只有当后续所有数据都重发一遍后,所有应该被覆盖的Key都被最新数据覆盖后,整个系统才达到数据的一致状态。所以,从这个角度来讲,在重启过程中KV数据库里的数据很有可能是不一致的,当数据重发完成后,数据才恢复一致性,这时它才可以提供端到端的Exatcly-Once保障。
事务写
事务(Transaction)是数据库系统所要解决的最核心问题。Flink借鉴了数据库中的事务处理技术,同时结合自身的Checkpoint机制来保证Sink只对外部输出产生一次影响。
简单概括来说,Flink的事务写(Transaction Write)是指,Flink先将待输出的数据保存下来暂时不向外部系统提交,等待Checkpoint结束的时刻,Flink上下游所有算子的数据都是一致时,将之前保存的数据全部提交(Commit)到外部系统。换句话说,只有经过Checkpoint确认的数据才向外部系统写入。那么数据重发的例子中,入下图所示,如果使用事务写,那只把时间戳3之前的输出提交到外部系统,时间戳3以后的数据(例如时间戳5和8生成的数据)暂时保存下来,等待下次Checkpoint时一起写入到外部系统。这就避免了时间戳5这个数据产生多次结果,多次写入到外部系统。

在事务写的具体实现上,Flink目前提供了两种方式:预写日志(Write-Ahead-Log,WAL)和两阶段提交(Two-Phase-Commit,2PC)。这两种方式也是很多数据库和分布式系统实现事务时经常采用的协议,Flink根据自身的场景对这两种协议做了适应性调整。这两种方式主要区别在于:WAL方式通用性更强,适合几乎所有外部系统,但也不能提供百分百端到端的Exactly-Once;如果外部系统自身就支持事务(比如Kafka),可以使用2PC方式,提供百分百端到端的Exactly-Once。我们将在接下来的文章中详细介绍这两种方式。
事务写的方式能提供端到端的Exactly-Once一致性,它的代价也是非常明显的,就是牺牲了延迟。输出数据不再是实时写入到外部系统,而是分批次地提交。目前来说,没有完美的故障恢复和Exactly-Once保障机制,对于开发者来说,需要在不同需求之间权衡。