数据可视化——利用pandas和seaborn绘图基础
文章目录
- 一.折线图
- 二.柱状图
- 三.直方图和密度图
- 四.散点图或点图
- 五.分面网格
- 其他绘图工具:
- 图像可视化——matplotlib绘图入门基础
一.折线图
1.Series和DataFrame都有一个plot属性,用于绘制基本的图形。默认情况下,plot绘制的是折线图
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(10),index = np.arange(0, 100, 10))
s.plot()
2.Series对象的索引作为图像的x轴,通过设置参数ues_index = False来禁用这个功能
DataFrame的plot方法在同一个子图中将每一列绘制为不同的折线
df = pd.DataFrame(np.random.randn(10,4),columns = ['A','B','C','D'],index = np.arange(0, 100, 10))
df.plot()
二.柱状图
2.plot.bar()和plat.barh()可以分别绘制垂直和水平的柱状图
通过设置参数ax让索引变为x轴或y轴的刻度
import matplotlib.pyplot as plt
fig,axes = plt.subplots(2, 1)
data = pd.Series(np.random.rand(16),index = list('abcdefghijklmnop'))
data.plot.bar(ax = axes[0],color = 'k',alpha = 0.7) # 水平柱状图
data.plot.barh(ax = axes[1],color = 'k',alpha = 0.7) # 垂直柱状图
3.在DaraFrame中,柱状图将每一行的值分组到并排的柱子中的一组
df = pd.DataFrame(np.random.rand(6, 4),index = ['one','two','three','four','five','six'],columns = pd.Index(['A','B','C','D'],name = 'Genus'))
df
| Genus | A | B | C | D |
|---|---|---|---|---|
| one | 0.521250 | 0.130425 | 0.777971 | 0.961869 |
| two | 0.757899 | 0.277487 | 0.560785 | 0.085239 |
| three | 0.160654 | 0.109345 | 0.095460 | 0.662478 |
| four | 0.224170 | 0.404333 | 0.285609 | 0.899609 |
| five | 0.655649 | 0.375043 | 0.227883 | 0.320732 |
| six | 0.476958 | 0.055556 | 0.372118 | 0.385297 |
df.plot.bar()
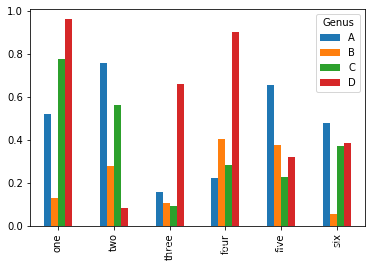
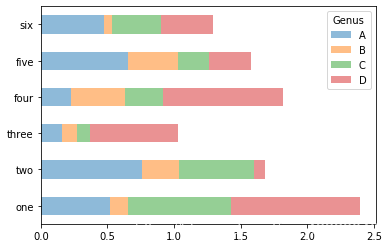
4.列名称’Genus’被用作了图例标题。我们可以通过传递stacked = True来生成堆积柱状图,使每一行的值堆积在一起
df.plot.barh(stacked = True,alpha = 0.5)
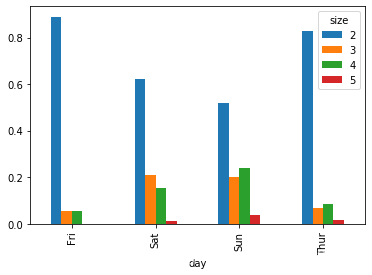
5.下面生成一个堆积状图,用于展示每个派对在每天的数据点占比
使用read_csb载入数据,并根据星期日期和派对规模形成交叉表
tips = pd.read_csv('../examples/tips.csv')
tips.head()
| total_bill | tip | smoker | day | time | size | |
|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 |
party_counts = pd.crosstab(tips['day'],tips['size'])
party_counts
| size | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| day | ||||||
| Fri | 1 | 16 | 1 | 1 | 0 | 0 |
| Sat | 2 | 53 | 18 | 13 | 1 | 0 |
| Sun | 0 | 39 | 15 | 18 | 3 | 1 |
| Thur | 1 | 48 | 4 | 5 | 1 | 3 |
party_counts = party_counts.loc[:,2:5]
party_pcts = party_counts.div(party_counts.sum(1),axis = 0) #标准化至和为1
party_pcts
| size | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| day | ||||
| Fri | 0.888889 | 0.055556 | 0.055556 | 0.000000 |
| Sat | 0.623529 | 0.211765 | 0.152941 | 0.011765 |
| Sun | 0.520000 | 0.200000 | 0.240000 | 0.040000 |
| Thur | 0.827586 | 0.068966 | 0.086207 | 0.017241 |
party_pcts.plot.bar()
6.使用seaborn包会使工作更加简单,下面使用seaborn进行按星期日期计算小费百分比
import seaborn as sns
tips['tip_pct'] = tips['tip'] / (tips['total_bill'] - tips['tip'])
tips.head()
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.063204 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.191244 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.199886 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.162494 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.172069 |
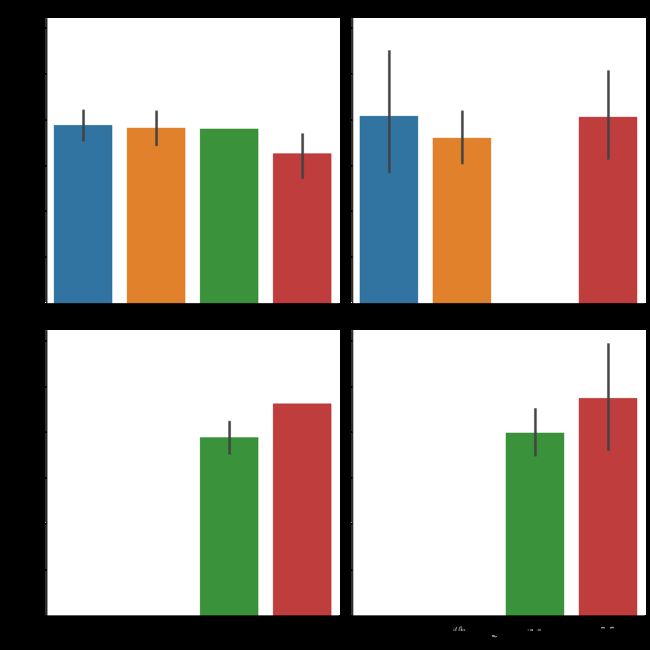
sns.barplot(x = 'tip_pct',y = 'day', data = tips,orient = 'h')
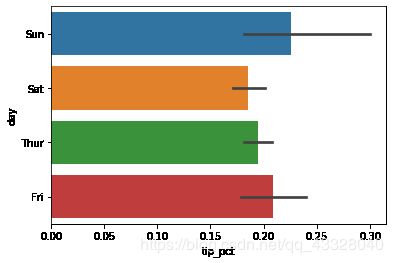
柱子的值表示tip_pct的平均值,黑线表示%95的置信区间
7.sns.barplot拥有一个hue参数,允许我们通过一个额外的分类值将数据分离开
sns.barplot(x = 'tip_pct',y = 'day', hue = 'time', data = tips,orient = 'h')

三.直方图和密度图
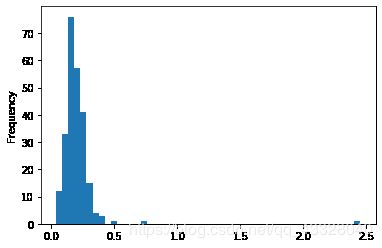
直方图是一种条形图,用于给出频率的离散显示。数据点被分成离散的,均匀间隔的箱,并且绘制每个箱中数据点的数量。
使用之前的小费数据制作小费占总费用百分比的直方图
tips['tip_pct'].plot.hist(bins = 50)
密度图是一种和直方图相关的图表类型,它通过计算可能产生观测数据的连续概率分布估计而产生。通常的做法是将这种分布近似为’内核’的混合,也就是像正态分布那样简单的分布。因此密度图也称为内核密度估计图
tips['tip_pct'].plot.density()
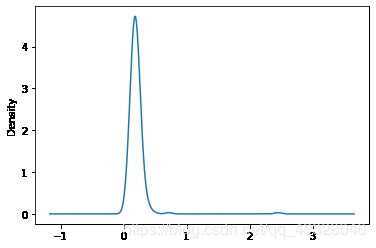
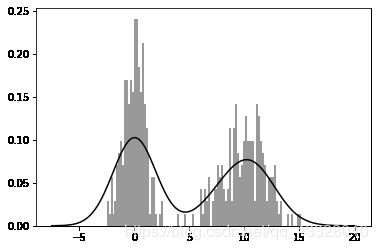
使用distplot方法可以同时绘制直方图和密度图
comp1 = np.random.normal(0, 1, size = 200)
comp2 = np.random.normal(10, 2, size = 200)
values = pd.Series(np.concatenate([comp1,comp2]))
sns.distplot(values,bins = 100,color = 'k')
四.散点图或点图
点图或散点图常用于检验俩个一维数据序列之间的关系。读取文件内容,选择一些变量,计算对数差
macro = pd.read_csv('../examples/macrodata.csv')
macro.head()
| year | quarter | realgdp | realcons | realinv | realgovt | realdpi | cpi | m1 | tbilrate | unemp | pop | infl | realint | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1959.0 | 1.0 | 2710.349 | 1707.4 | 286.898 | 470.045 | 1886.9 | 28.98 | 139.7 | 2.82 | 5.8 | 177.146 | 0.00 | 0.00 |
| 1 | 1959.0 | 2.0 | 2778.801 | 1733.7 | 310.859 | 481.301 | 1919.7 | 29.15 | 141.7 | 3.08 | 5.1 | 177.830 | 2.34 | 0.74 |
| 2 | 1959.0 | 3.0 | 2775.488 | 1751.8 | 289.226 | 491.260 | 1916.4 | 29.35 | 140.5 | 3.82 | 5.3 | 178.657 | 2.74 | 1.09 |
| 3 | 1959.0 | 4.0 | 2785.204 | 1753.7 | 299.356 | 484.052 | 1931.3 | 29.37 | 140.0 | 4.33 | 5.6 | 179.386 | 0.27 | 4.06 |
| 4 | 1960.0 | 1.0 | 2847.699 | 1770.5 | 331.722 | 462.199 | 1955.5 | 29.54 | 139.6 | 3.50 | 5.2 | 180.007 | 2.31 | 1.19 |
data = macro[['cpi','m1','tbilrate','unemp']]
data.head()
| cpi | m1 | tbilrate | unemp | |
|---|---|---|---|---|
| 0 | 28.98 | 139.7 | 2.82 | 5.8 |
| 1 | 29.15 | 141.7 | 3.08 | 5.1 |
| 2 | 29.35 | 140.5 | 3.82 | 5.3 |
| 3 | 29.37 | 140.0 | 4.33 | 5.6 |
| 4 | 29.54 | 139.6 | 3.50 | 5.2 |
trans_data = np.log(data).diff().dropna() # 取对数
trans_data.head()
| cpi | m1 | tbilrate | unemp | |
|---|---|---|---|---|
| 1 | 0.005849 | 0.014215 | 0.088193 | -0.128617 |
| 2 | 0.006838 | -0.008505 | 0.215321 | 0.038466 |
| 3 | 0.000681 | -0.003565 | 0.125317 | 0.055060 |
| 4 | 0.005772 | -0.002861 | -0.212805 | -0.074108 |
| 5 | 0.000338 | 0.004289 | -0.266946 | 0.000000 |
然后我们可以使用seaborn的regplot方法,该方法可以绘制散点图,并拟合出一条线性回归线
sns.regplot('m1','unemp',data = trans_data)
plt.title('changes in log %s versus log %s' %('m1','unemp') )

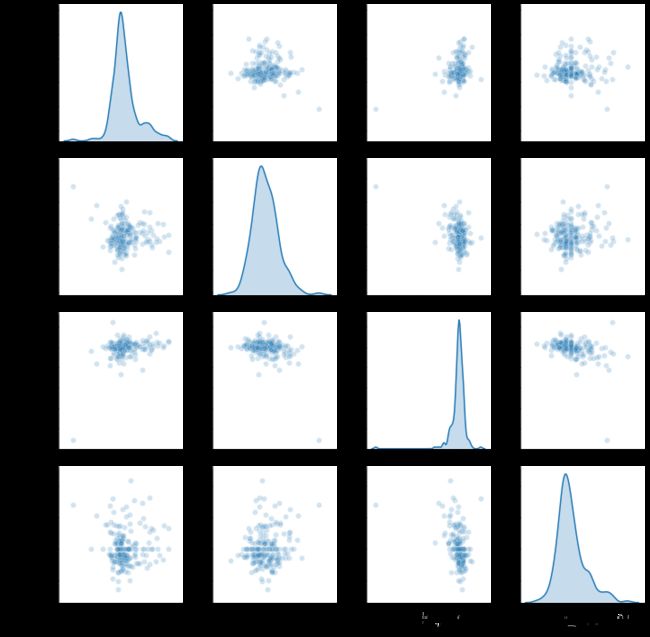
使用pairplot方法,可以绘制任意俩个变量之间的散点图
sns.pairplot(trans_data,diag_kind = 'kde',plot_kws = {'alpha':0.2})
五.分面网格
使用分面网格可以利用多组分组变量对数据进行可视化,根据类别的个数形成多个表格
sns.factorplot(x = 'day',y = 'tip_pct',hue = 'time',col = 'smoker',kind = 'bar',data = tips[tips.tip_pct<1])
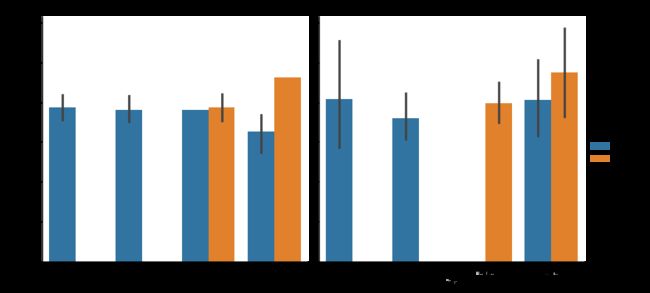
除了根据time在一个面内将不同的柱分组为不同的颜色,我们还可以通过每个时间值添加一行来扩展分面网格
sns.factorplot(x = 'day',y = 'tip_pct',row = 'time',col = 'smoker',kind = 'bar',data = tips[tips.tip_pct<1])
箱型图:通过设置参数kind = box来选择该类型
sns.factorplot(x = 'tip_pct',y = 'day',kind = 'box',data = tips[tips.tip_pct<0.5])
