使用webmagic爬取51job网站的招聘信息
最近做了一个爬虫项目,爬取了51job网站的招聘信息。
1.首先编写数据库表:
CREATE TABLE job_info (
id bigint(20) NOT NULL AUTO_INCREMENT COMMENT ‘主键id’,
company_name varchar(100) DEFAULT NULL COMMENT ‘公司名称’,
company_addr varchar(200) DEFAULT NULL COMMENT ‘公司联系方式’,
job_name varchar(100) DEFAULT NULL COMMENT ‘职位名称’,
job_addr varchar(50) DEFAULT NULL COMMENT ‘工作地点’,
salary varchar(50) DEFAULT NULL COMMENT ‘薪资范围’,
url varchar(150) DEFAULT NULL COMMENT ‘招聘信息详情页’,
time varchar(100) DEFAULT NULL COMMENT ‘职位最近发布时间’,
job_detail text COMMENT ‘职位详情’,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=13266 DEFAULT CHARSET=utf8 COMMENT=‘招聘信息’;
2.然后创建springboot项目,在pom.xml文件中导入依赖,编写配置文件,并编写pojo类:
pom.xml文件:
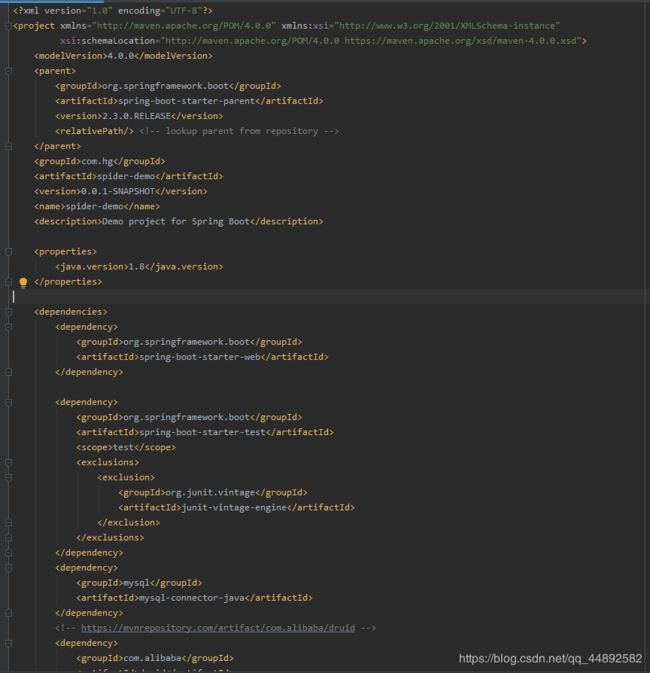


4.0.0
org.springframework.boot
spring-boot-starter-parent
2.3.0.RELEASE
com.hg
spider-demo
0.0.1-SNAPSHOT
spider-demo
Demo project for Spring Boot
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.junit.vintage
junit-vintage-engine
mysql
mysql-connector-java
com.alibaba
druid
1.1.22
com.baomidou
mybatis-plus-boot-starter
3.2.0
org.projectlombok
lombok
1.18.10
provided
org.apache.jclouds.provider
rackspace-cloudservers-us
2.2.1
test
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
cn.hutool
hutool-all
5.3.5
com.google.guava
guava
29.0-jre
org.apdplat
word
1.2
org.springframework.boot
spring-boot-maven-plugin
配置文件
spring:
application:
name: spider-demo
jackson:
time-zone: UTC
date-format: yyyy-MM-dd HH:mm:ss
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/job51?serverTimezone=UTC&autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=CONVERT_TO_NULL&useSSL=false
username: root
password: 123456
type: com.alibaba.druid.pool.DruidDataSource
druid:
initialSize: 10
minIdle: 10
maxActive: 50
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
filters: stat,wall
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
#mybatis
mybatis-plus:
mapper-locations: classpath:mapper/**/*.xml
typeAliasesPackage: com.hg.POJO
global-config:
db-config:
id-type: auto
field-strategy: not_empty
table-underline: true
db-type: mysql
refresh: true
configuration:
map-underscore-to-camel-case: true
cache-enabled: false
logging:
level:
org.springframework.web: info
org.apache.http: info
us.codecraft.webmagic: info
pojo类:
package com.hg.POJO;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.extern.slf4j.Slf4j;
@Data
@TableName(“job_info”)
@Slf4j
public class JobInfo {
@TableId
private Long id;
/**
* 公司名
*/
private String companyName;
/**
* 公司地址
*/
private String companyAddr;
/**
* 工作名称
*/
private String jobName;
/**
* 工作地址
*/
// private String jobAddr;
/**
* 工作详情
/
private String jobDetail;
/*
* 薪资
/
private String salary;
/*
* 爬取的url
/
private String url;
/*
* 职位发布时间
*/
private String time;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getCompanyName() {
return companyName;
}
public void setCompanyName(String companyName) {
this.companyName = companyName;
}
public String getCompanyAddr() {
return companyAddr;
}
public void setCompanyAddr(String companyAddr) {
this.companyAddr = companyAddr;
}
public String getJobName() {
return jobName;
}
public void setJobName(String jobName) {
this.jobName = jobName;
}
// public String getJobAddr() {
// return jobAddr;
// }
//
// public void setJobAddr(String jobAddr) {
// this.jobAddr = jobAddr;
// }
public String getJobDetail() {
return jobDetail;
}
public void setJobDetail(String jobDetail) {
this.jobDetail = jobDetail;
}
public String getSalary() {
return salary;
}
public void setSalary(String salary) {
this.salary = salary;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
}
3.编写dao层:
package com.hg.dao;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.hg.POJO.JobInfo;
import org.apache.ibatis.annotations.Mapper;
import org.springframework.stereotype.Component;
import org.springframework.stereotype.Repository;
/**
- @Author skh
- @Date 2020/3/21 16:27
- @Desc
*/
@Mapper
public interface JobInfoDao extends BaseMapper {
}
4.编写service层:
package com.hg.service;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.hg.dao.JobInfoDao;
import com.hg.POJO.JobInfo;
import com.hg.webmagic.JobProcessor;
import com.hg.webmagic.MysqlPipeline;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.scheduler.BloomFilterDuplicateRemover;
import us.codecraft.webmagic.scheduler.QueueScheduler;
import java.util.List;
/**
-
@Author skh
-
@Date 2020/3/21 12:10
-
@Desc
*/
@Service
@Slf4j
public class JobInfoService extends ServiceImpl//开始爬取的url
String url = “https://search.51job.com/list/200200%252C010000%252C020000%252C030200%252C040000,000000,0000,00,9,99,Java,2,1.html”;@Autowired
private MysqlPipeline mysqlPipeline;@Autowired
private JobProcessor jobProcessor;public void getJobInfo() {
System.out.println(“开始爬取数据”);
//设置爬虫配置
Spider.create(jobProcessor)
.addUrl(url) //设置初始爬取的url
//使用布隆过滤器过滤重复url,需要引入guava包
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000)))
.thread(50) //设置线程数
.addPipeline(mysqlPipeline) //设置持久化
.run();
}public List selectJobInfoByUrl(String url) {
QueryWrapper wrapper = new QueryWrapper<>();
wrapper.eq(“url”, url);
List jobInfos = this.baseMapper.selectList(wrapper);
return jobInfos;
}
}
编写controller层:
package com.hg.controller;
import com.hg.service.JobInfoService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/**
-
@Author skh
-
@Date 2020/3/21 12:24
-
@Desc
*/
@RestController
public class JobInfoController {@Autowired
private JobInfoService jobInfoService;@GetMapping("/getJobInfo")
public String getJobInfo() {
jobInfoService.getJobInfo();
return “success”;
}
}
5.编写webmagic代码:
(1)JobProcessor类:
package com.hg.webmagic;
import cn.hutool.core.collection.CollUtil;
import cn.hutool.core.util.StrUtil;
import com.hg.POJO.JobInfo;
import com.hg.service.JobInfoService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.Selectable;
import java.util.List;
/**
-
@Author skh
-
@Date 2020/3/20 22:56
-
@Desc 解析页面
*/
@Component
@Slf4j
public class JobProcessor implements PageProcessor {@Autowired
private JobInfoService jobInfoService;/**
-
解析页面
-
@param page
*/
@Override
public void process(Page page) {//解析列表页
List nodes = page.getHtml().css(“div#resultList div.el”).nodes();if (CollUtil.isEmpty(nodes)) {
//为空表示这是招聘详情页,解析页面,获取招聘详情信息,保存数据
try {
this.saveJobInfo(page);
} catch (Exception e) {
System.out.println(“解析异常,异常原因:{}”+ e.getMessage()+e);
}
} else {
//不为空表示这是列表页,解析出详情页url,放到任务队列中
for (Selectable node : nodes) {
//获取url地址
String jobInfoUrl = node.css(“p.t1 span a”).links().toString();
if (StrUtil.isNotBlank(jobInfoUrl)) {
//判断记录是否已存在
List jobInfoList = jobInfoService.selectJobInfoByUrl(jobInfoUrl);
if (CollUtil.isEmpty(jobInfoList)) {
//把url放到任务队列中
page.addTargetRequest(jobInfoUrl);
} else {
System.out.println(“记录已存在,记录url:{}”+jobInfoUrl);} } } //获取下一页的url Listall = page.getHtml().css("div.p_in li.bk a").links().all(); String bkUrl = all.get(all.size() - 1); System.out.println("下一页Url:{}"+ bkUrl); if (StrUtil.containsAny(bkUrl, "301.html")) { System.out.println("已查到300页数据,无须无限爬取数据"); return; } page.addTargetRequest(bkUrl); }
}
/**
-
解析job详情页
-
@param page
*/
private void saveJobInfo(Page page) {
//解析页面
Html html = page.getHtml();
String companyName = html.css(“div.cn p.cname a”, “text”).get();
List text = html.css(“div.bmsg.inbox p.fp”, “text”).all();
String companyAddr = text.get(text.size() - 1);
String jobName = html.css(“div.cn h1”, “text”).get();
String jobStr = html.css(“p.msg.ltype”, “text”).get();
String[] s = StrUtil.split(jobStr, " ");
// String Addr_time = s[0];String time = “”;
for (String s1 : s) {
if (StrUtil.containsAny(s1, “发布”)) {
time = StrUtil.removeAll(s1, “发布”);
break;
}
}
String jonDetail = html.css(“div.bmsg.job_msg.inbox”, “allText”).get();
String url = page.getUrl().get();
String salary = html.css(“div.in div.cn strong”, “text”).get();JobInfo jobInfo = new JobInfo();
jobInfo.setJobName(jobName);
// jobInfo.setJobAddr(Addr_time);
jobInfo.setJobDetail(jonDetail);
jobInfo.setSalary(salary);
jobInfo.setUrl(url);
jobInfo.setTime(time);
jobInfo.setCompanyName(companyName);
jobInfo.setCompanyAddr(companyAddr);
// System.out.println(time);
//把结果保存到resultItems,为了持久化
page.putField(“jobInfo”, jobInfo);
}
//配置爬虫信息
private Site site = Site.me()
.setUserAgent(“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36”)
.setCharset(“gbk”)
.setTimeOut(10 * 1000)
.setRetryTimes(3)
.setRetrySleepTime(3000);@Override
public Site getSite() {
return site;
}
}
(2).MysqlPipeline类:
package com.hg.webmagic; -
import com.hg.POJO.JobInfo;
import com.hg.service.JobInfoService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
/**
-
@Author skh
-
@Date 2020/3/21 16:18
-
@Desc
*/
@Component
@Slf4j
public class MysqlPipeline implements Pipeline
{
@Autowired
private JobInfoService jobInfoService;@Override
public void process(ResultItems resultItems, Task task) {
//获取封装好的数据
JobInfo jobInfo = resultItems.get(“jobInfo”);
if (jobInfo != null) {
jobInfoService.save(jobInfo);
}
}
}
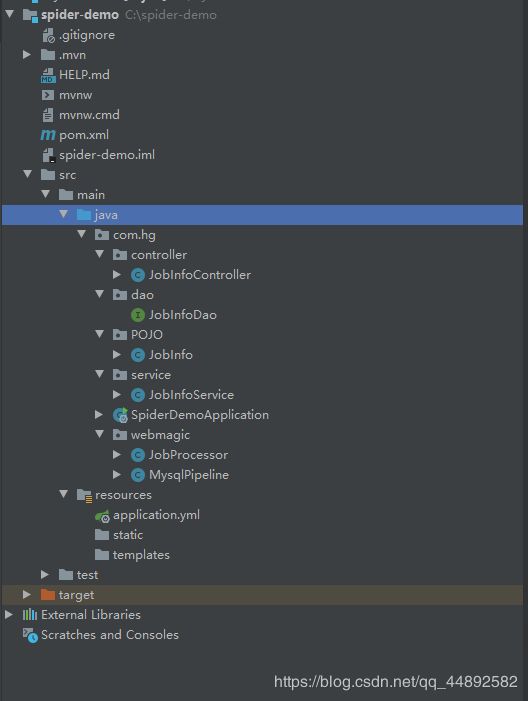
以下是每个类所在包的截图:
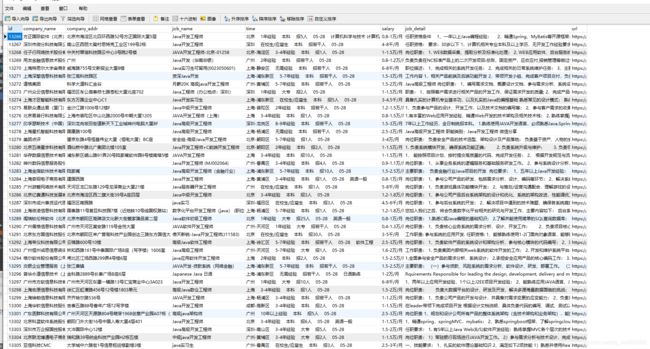
代码写到这里,就完成啦。最后展示一下最终成果:
后期如果解析岗位要求,可以用word分词工具,来进行进一步解析。
word分词器api:http://www.51sjk.com/b1b68857/