java通用分页详解
通用分页查询
- 前言
- 通用分页概念
- 通用分页功能模块详谈以及准备工作
- 运行流程详解
- 案例以及易出错点
- 总结
前言
各位小伙伴,通用分页详解版来了…
下面是之前的博文:
| 通用分页初始版 | https://blog.csdn.net/qq_45510899/article/details/106433352 |
|---|---|
| 通用分页优化版 | https://blog.csdn.net/qq_45510899/article/details/106459804 |
通用分页概念
其实通用分页概念很简单,就是抽取有共性的代码部分,构成通用性的代码。
通用分页功能模块详谈以及准备工作
通用分页,大家从字面意思可以看出,它是通用的,我们开发出这个通用分页功能,就是为了我们代码的精简,提高重复利用。如图:
这里举例,我只建了6个方法类(BaseDao为通用分页类),假如现在有个需求,把每个类的分页查询都做出来,那么我需要在每个方法类都写分页查询方法,那如果我有上百个类,那么重复的代码就很多,例如连接数据库和执行方法等字符串:
@Override
public List<Student> getAll() {
List<Student> ls = new ArrayList<Student>();
con = DBHelper.getCon();
try {
String sql = "select * from t_student";
ps = con.prepareStatement(sql);
rs = ps.executeQuery();
Student stu = new Student();
while (rs.next()) {
stu.setSsid(rs.getInt(1));
stu.setSname(rs.getString(2));
stu.setSsex(rs.getString(3));
ls.add(stu);
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return ls;
}
那我就可以抽取出来放在通用类:
package com.xiaoyang.dao;
/**
*
* @author xiaoyang
* 2020年6月4日
* 用来做通用分页
*/
import java.io.File;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.FilterInputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.lang.reflect.Field;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import com.xiaoyang.util.DBAccess;
import com.xiaoyang.util.PageBean;
public class BaseDao<k> {
public List<k> executeQuery(String sql, PageBean pageBean, Class clz) {
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
if (null != pageBean && pageBean.isPagination()) {
try {
con = DBAccess.getConnection();
String countSql = this.getCountSql(sql);
ps = con.prepareStatement(countSql);
rs = ps.executeQuery();
if (rs.next()) {
int total = rs.getInt(1);// 总记录数
pageBean.setTotal(total);// 给pagebean的总记录数赋值
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
DBAccess.close(null, ps, rs);
}
}
// 2.查询指定页码并满足条件的总记录数
try {
if(con==null) {
con=DBAccess.getConnection();
}
String pageSql =sql;
if(null!=pageBean&&pageBean.isPagination()) {
pageSql = this.getPageSql(sql, pageBean);
}
ps = con.prepareStatement(pageSql);
rs = ps.executeQuery();
List<k> list=new ArrayList<k>();
k k;
while(rs.next()) {
//反射实例化
k =(k)clz.newInstance();
//反射获取所有属性对象
Field[] fields = clz.getDeclaredFields();
for (Field field : fields) {
//私有属性,打开权限
field.setAccessible(true);
//给属性对象赋值
field.set(k, rs.getObject(field.getName()));
}
//把对象增加到集合
list.add(k);
}
return list;
} catch (Exception e) {
throw new RuntimeException();
} finally {
DBAccess.close(con, ps, rs);
}
}
/**
* 专门写一个方法用来拼接查询语句的统计满足条件的总行数
*
* @param sql
* @return
*/
public String getCountSql(String sql) {
return "select count(*) from (" + sql + ") t1";
}
/**
* 专门写一个方法用来存储拼接分页的sql
*
* @param sql
* @param pageBean
* @return
*/
public String getPageSql(String sql, PageBean pageBean) {
return sql + " limit " + pageBean.getStartsIndex() + "," + pageBean.getRows();
}
}
通用分页类功能具体化解释:
1.参数的类型设置
public class BaseDao<k>
public List<k> executeQuery
那么大家通过上面的通用方法类可以看出,我用到了泛型作为类和查询结果集合的参数,之所以用泛型就是因为我并不知道继承我方法,用我方法的是什么类,是学生类还是老师类,等等…那设置成泛型之后,继承通用方法的子类只需要带上类是什么就可以继承通用分页的查询分页方法,如下继承类:
public class BookDao extends BaseDao<Book>
2.通用分页查询方法的参数设置
public List<k> executeQuery(String sql, PageBean pageBean, Class clz)
| sql | 子类传递过来的原生sql,例如我要查询所有数据并进行分页String sql="select * from t_mvc_book where 1=1 "; |
|---|---|
| pageBean | 分页实体类参数,进行分页数据赋值和获取值、方法 |
| clz | 反射子类的参数,主要用于反射获取到子类的所有属性进行遍历赋值 |
3.反射实例化子类对象属性
List<k> list=new ArrayList<k>();
k k;
while(rs.next()) {
k =(k)clz.newInstance();
//反射获取所有属性对象
Field[] fields = clz.getDeclaredFields();
for (Field field : fields) {
//私有属性,打开权限
field.setAccessible(true);
//给属性对象赋值
field.set(k, rs.getObject(field.getName()));
}
//把对象增加到集合
list.add(k);
}
其实对于反射这个点在这里的运用,在子类里的效果是很直观的,我们可以简化很多查询赋值代码,像之前我们一张表要是有10多个列字段,子类用方法查询出来进行赋值时是这样:
public List<Job> find(Job job, PageBean pageBean) {
String sql = "select * from t_solr_job where 1=1 ";
return this.executeQuery(sql, pageBean, new Callback<Job>() {
@Override
public List<Job> foreach(ResultSet rs) throws SQLException {//通用分页遍历
List<Job> jobList = new ArrayList<Job>();
Job job1 = null;
while (rs.next()) {
job1 = new Job();
job1.setId(rs.getString(1));
job1.setJob(rs.getString(2));
job1.setCompany(rs.getString(3));
job1.setAddress(rs.getString(4));
job1.setSalary(rs.getString(5));
job1.setUrl(rs.getString(6));
job1.setLimits(rs.getString(7));
job1.setTime(rs.getString(8));
job1.setDescs(rs.getString(9));
job1.setJobHandle(rs.getString(10));
job1.setAddressHandle(rs.getString(11));
jobList.add(job1);
}
return jobList;
}
});
}
反射后子类实现类代码:
public List<Book> find(Book book,PageBean pageBean) throws Exception{
String sql="select * from t_mvc_book where 1=1 ";
if(StringUtils.isNotBlank(book.getBname())) {
sql+=" and bname like '%"+book.getBname()+"%' ";
}
return super.executeQuery(sql, pageBean, Book.class);
}
运行流程详解
看完通用分页的主要功能点后,我们再了解一下它的一个运行流程,其实流程图在上面的链接博文里有,不过还不够详细,这次给大家重新重新画了一个流程图:
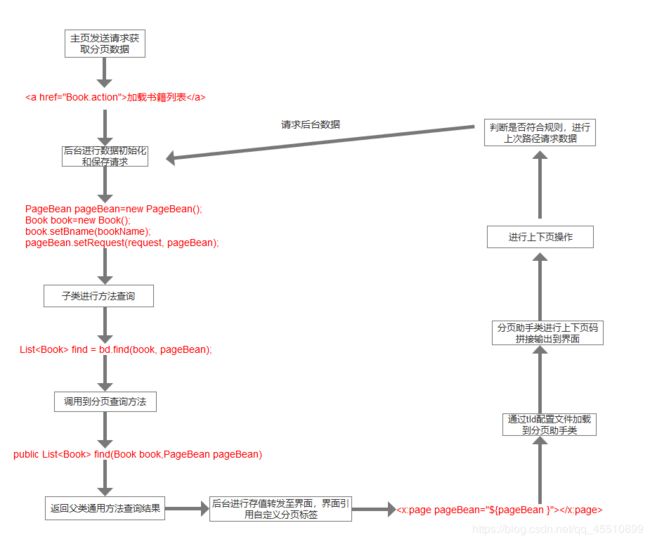
其实这个流程,之前也是做过一次流程图解析,多用一下debug就知道具体项目的一个运行流程了…
案例以及易出错点
这里结合mysql写了一个书籍类的分页查询显示,并结合bootstrap做了一个样式调节:
数据库脚本就不贴出来了,可以随便创个表添加数据进行测试。
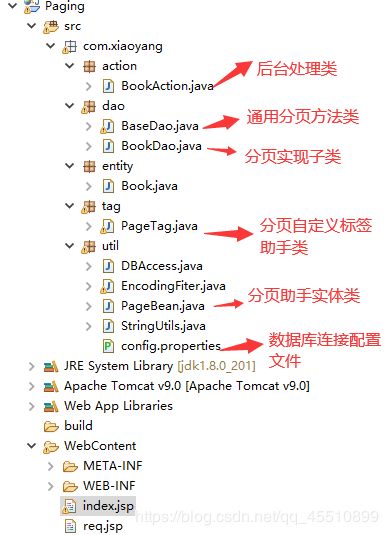
通用方法类和具体实现子类代码在上面已经贴过,篇幅原因就不再贴一次了
助手类:
package com.xiaoyang.tag;
import java.io.IOException;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.JspWriter;
import javax.servlet.jsp.tagext.BodyTagSupport;
import com.xiaoyang.util.PageBean;
public class PageTag extends BodyTagSupport {
/**
*
*/
private static final long serialVersionUID = 1L;
// 定义pageBean数属性
private PageBean pageBean;
public PageBean getPageBean() {
return pageBean;
}
public void setPageBean(PageBean pageBean) {
this.pageBean = pageBean;
}
public PageTag() {
}
@Override
public int doStartTag() throws JspException {
// TODO Auto-generated method stub
JspWriter out = pageContext.getOut();
try {
out.println(toHtml());
} catch (IOException e) {
throw new RuntimeException(e);
}
return SKIP_BODY;
}
public String toHtml() {
StringBuffer sb = new StringBuffer();
// 这里拼接的是一个上一次发送的请求以及携带的参数,唯一改变的就是页码
sb.append(");
// sb.append("");
sb.append("");
// 重要设置拼接操作,将上一次请求参数携带到下一次
Map<String, String[]> paMap = pageBean.getParameterMap();
if (paMap != null && paMap.size() > 0) {
Set<Map.Entry<String, String[]>> entrySet = paMap.entrySet();
for (Map.Entry<String, String[]> entry : entrySet) {
for (String val : entry.getValue()) {
if (!"page".equals(entry.getKey())) {
sb.append("");
}
}
}
}
sb.append("");
// 获取当前页数
int page = pageBean.getPage();
// 获取最大页数
int max = pageBean.getMaxPage();
// 判断当前页码之前的页码个数是否>4,是则前面有四个页码,否则前面对应-1个页码
int before = page > 4 ? 4 : page - 1;
// 赋值当前页码后面的页码数,总共显示10个页码,减掉当前页数占位一个,再减掉当前页码前的页码数,就是当前页码后的页码数
int after = (10 - 1) - before;
// 最后还要判断当前页+后面的页码是否大于最大页数
after = page + after > max ? max - page : after;
// disabled 已是第一页或是最后一页的话上一页、首页或者下一页、尾页禁用
boolean startFlag = page == 1;
boolean endFlag = max == page;
// 拼接分页条
sb.append(""
);
sb.append("首页 ");
sb.append("< ");
// 代表了当前页的前4页
for (int i = before; i > 0; i--) {
sb.append(""
+ (page - i) + "");
}
sb.append("" + pageBean.getPage() + "");
// 代表了当前页的后5页
for (int i = 1; i <= after; i++) {
sb.append(""
+ (page + i) + "");
}
sb.append("> ");
sb.append("尾页 ");
sb.append(
"到第页 ");
sb.append("确定 ");
sb.append("共" + pageBean.getTotal() + "条");
sb.append("");
// 拼接分页的js代码
sb.append("");
return sb.toString();
}
}
这个助手类较之前有些改动,就是通过当前页码对 前后显示页码数的一个判断(总共显示10个页码,当前页码前4个页码后5页码规则,再就是是否到达一个最大页最小页临界点禁用问题):
// 获取当前页数
int page = pageBean.getPage();
// 获取最大页数
int max = pageBean.getMaxPage();
// 判断当前页码之前的页码个数是否>4,是则前面有四个页码,否则前面对应-1个页码
int before = page > 4 ? 4 : page - 1;
// 赋值当前页码后面的页码数,总共显示10个页码,减掉当前页数占位一个,再减掉当前页码前的页码数,就是当前页码后的页码数
int after = (10 - 1) - before;
// 最后还要判断当前页+后面的页码是否大于最大页数
after = page + after > max ? max - page : after;
// disabled 已是第一页或是最后一页的话上一页、首页或者下一页、尾页禁用
boolean startFlag = page == 1;
boolean endFlag = max == page;
action处理层:
package com.xiaoyang.action;
import java.io.IOException;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.xiaoyang.dao.BookDao;
import com.xiaoyang.entity.Book;
import com.xiaoyang.util.PageBean;
/**
* Servlet implementation class BookAction
*/
@WebServlet("/Book.action")
public class BookAction extends HttpServlet {
private static final long serialVersionUID = 1L;
/**
* @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
doPost(request, response);
}
/**
* @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
//设置字符编码
request.setCharacterEncoding("utf-8");
//获取表单值
String bookName = request.getParameter("bookName");
BookDao bd=new BookDao();
PageBean pageBean=new PageBean();
Book book=new Book();
book.setBname(bookName);
pageBean.setRequest(request, pageBean);
try {
List<Book> find = bd.find(book, pageBean);
request.setAttribute("bookList", find);
request.setAttribute("pageBean", pageBean);
request.getRequestDispatcher("index.jsp").forward(request, response);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
最后两个要注意的点就是:
因为方法类用了反射,实体类就不要实现Serializable接口进行序列化了:
private static final long serialVersionUID = 1711744550109467385L;
否则会引起报错,因为通用方法类BaseDao利用反射动态获取了所有属性:
//反射获取所有属性对象
Field[] fields = clz.getDeclaredFields();
但数据库表对应的字段并没有这个列字段…
还有一点就是,这里我用的是在线bootstrap样式库,需要联网才有效果:
<link
href="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/4.5.0/css/bootstrap.css"
rel="stylesheet">
<script
src="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/4.5.0/js/bootstrap.js"></script>
<style type="text/css">
感兴趣的可以自行去官网,有在线文档,样式拿来就可以用:
Bootstrap中文网
最后附上项目案例效果图(带模糊查询功能,主页写一个表单提交就行,后台已经做好判断了):
总结
通用分页所有的流程介绍以及源码就分享到这了,评论区欢迎指出不足,谢谢…