姓名:张瀚铎 学号:17021211233
转载自:大数据 http://bigdata.evget.com/post/2036.html
【嵌牛导读】:今年的双11再次刷新了记录——支付成功峰值达25.6万笔/秒、实时数据处理峰值4.72亿条/秒。 面对较去年增幅100%的数据洪峰,流计算技术可谓功不可没。今天,我们将揭开阿里流计算技术的神秘面纱。
【嵌牛鼻子】:大数据 数据可视化 数据分析
【嵌牛提问】:阿里流计算技术是什么?
【嵌牛正文】:
今年的双11再次刷新了记录——支付成功峰值达25.6万笔/秒、实时数据处理峰值4.72亿条/秒。 面对较去年增幅100%的数据洪峰,流计算技术可谓功不可没。今天,我们将揭开阿里流计算技术的神秘面纱。

双11刚刚拉下帷幕,激动的心还停留在那一刻:
当秒针刚跨过11号零点的一瞬间,来自线上线下的千万剁手党在第一时间涌入了这场年度大趴——从进入会场到点击详情页,再到下单付款一气呵成。
前台在大家狂欢的同时,后台数据流量也正以突破历史新高的洪峰形式急剧涌入:
支付成功峰值达 25.6 万笔/秒
实时数据处理峰值 4.72亿条/秒
而作为实时数据处理任务中最为重要的集团数据公共层(保障着业务的实时数据、媒体大屏等核心任务),在当天的总数据处理峰值更是创历史新高达1.8亿/秒! 想象下,1秒钟时间内千万人涌入双11会场的同时,依然应对自如。
流计算的产生即来源于数据加工时效性的严苛需求:
由于数据的业务价值会随着时间的流失而迅速降低,因此在数据发生后必须尽快对其进行计算和处理,从而能够通过数据第一时间掌握业务情况。今年双11的流计算也面临着一场实时数据洪峰的考验。
首先来展示今年(2017年)较去年(2016年)数据洪峰峰值的比较:
2016年:支付成功峰值12万笔/秒,总数据处理峰值9300万/秒
2017年:支付成功峰值25.6 万笔/秒,实时数据处理峰值 4.72亿条/秒,阿里巴巴集团数据公共层总数据处理峰值1.8亿/秒
在今年双11流量峰值翻翻的情况下,依然稳固做到实时数据更新频率:从第1秒千万剁手党涌入到下单付款,到完成实时计算投放至媒体大屏全路径,秒级响应。面对越发抬升的流量面前,实时数据却越来越快、越来越准。在hold住数据洪峰的背后,是阿里巴巴流计算技术的全面升级。
流计算应用场景
数据技术及产品部定位于阿里数据中台,除了离线数据外,其产出的实时数据也服务于集团内多个数据场景。包括今年(其实也是以往的任何一年)双11媒体大屏实时数据、面向商家的生意参谋实时数据,以及面向内部高管与小二的各种直播厅产品,覆盖整个阿里巴巴集团大数据事业部。
同时随着业务的不断发展壮大,到目前为止,日常实时处理峰值超4000万/s,每天总处理记录数已经达到万亿级别,总处理数据量也达到PB级别。
面对海量数据的实时数据我们成功做到了数据延迟控制在秒级范围内,在计算准确率上,已实现了高精准、0误差,达到精确处理。比如:今年的双11当天,双十一媒体屏第一条记录从交易表经过流计算计算处理到达媒体大屏秒级响应。
数据中台流计算实践中的数据链路
在经过最近几年大促数据洪峰的经历后,使得我们的流计算团队在引擎选择,优化性能以及开发流计算平台上都积累了丰富的经验。我们也形成了稳定高效的数据链路架构,下图是整个数据链路示意图:
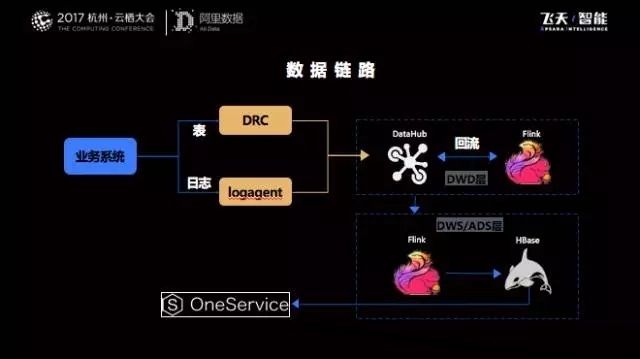
业务数据的来源非常多,分别通过两个工具(DRC与中间件的logagent)实时获取增量数据,并且同步到DataHub(一种PubSub的服务)。
实时计算引擎Flink作业通过订阅这些增量数据进行实时处理,并且在经过ETL处理后把明细层再次回流到Datahub,所有的业务方都会去定义实时的数据进行多维度的聚合,汇总后的数据放在分布式数据库或者关系型数据库中(Hbase、Mysql),并通过公共的数据服务层产品(One Service)对外提供实时数据服务。
最近一年,我们在计算引擎和计算优化方面做了很多工作,实现了计算能力、开发效率的提升。
计算引擎升级及优化
在2017年,我们在实时计算架构上进行了全面的升级,从Storm迁移到Blink,并且在新技术架构上进行了非常多的优化,实时峰值处理能力提高了2倍以上,平稳的处理能力更是提高5倍以上:
优化状态管理
实时计算过程中会产生大量的state,以前是存储在HBase,现在会存储在RocksDB中,本地存储减少了网络开销,能够大幅提高性能,可以满足细粒度的数据统计(现在key的个数可以提升到亿级别了,是不是棒棒哒~)
优化checkpoint(快照/检查点)和compaction(合并)
state会随着时间的流转,会越来越大,如果每次都做全量checkpoint的话,对网络和磁盘的压力非常大;所以针对数据统计的场景,通过优化rocksdb的配置,使用增量checkpoint等手段,可以大幅降低网络传输和磁盘读写。
异步Sink
把sink改成异步的形式,可以最大限度提高CPU利用率,可以大幅提供TPS。
抽象公共组件
除了引擎层面的优化,数据中台也针对性地基于Blink开发了自己的聚合组件(目前所有实时公共层线上任务都是通过该组件实现)。该组件提供了数据统计中常用的功能,把拓扑结构和业务逻辑抽象成了一个json文件。这样只需要在json文件中通过参数来控制,实现开发配置化,大幅降低了开发门槛,缩短开发周期——再来举个栗子:之前我们来做开发工作量为10人/日,现在因为组件化已让工作量降低为0.5人/日,无论对需求方还是开发方来讲都是好消息,同时归一的组件提升了作业性能。
按照上述思路及功能沉淀,最终打磨出了流计算开发平台【赤兔】。
该平台通过简单的“托拉拽”形式生成实时任务,不需要写一行代码,提供了常规的数据统计组件,并集成元数据管理、报表系统打通等功能。作为支撑集团实时计算业务的团队,我们在经过历年双11的真枪实弹后沉淀的[赤兔平台]中独有的功能也成为它独一无二的亮点:
一、大小维度合并
比如很多的实时统计作业同时需要做天粒度与小时粒度的计算,之前是通过两个任务分开计算的,聚合组件会把这些任务进行合并,并且中间状态进行共用,减少网络传输50%以上,同时也会精简计算逻辑,节省CPU。
二、精简存储
对于存储在RocksDB的Keyvalue,我们设计了一个利用索引的encoding机制,有效地将state存储减少一半以上,这个优化能有效降低网络、cpu、磁盘的压力。
三、高性能排序
排序是实时中非常常见的一个场景, top组件利用内存中PriorityQueue(优先队列) 和blink中新的MapState feature(中间状态管理特性),大幅减少序列化次数,性能提高10倍左右。
四、批量传输和写操作
最终写结果表HBase和Datahub时,如果每处理一条记录都去写库的话,就会很大限制我们的吞吐。我们组件通过时间触发或者记录数触发的机制(timer功能),实现批量传输和批量写(mini-batch sink),并且可以根据业务延时要求进行灵活配置,提高任务吞吐的同时,也降低了服务端压力。
数据保障
对于高优先级应用(每天24小时不间断服务),需要做到跨机房容灾,当某条链路出现问题时,能够秒级切换到其他链路,下图是整个实时公共层的链路保障架构图:
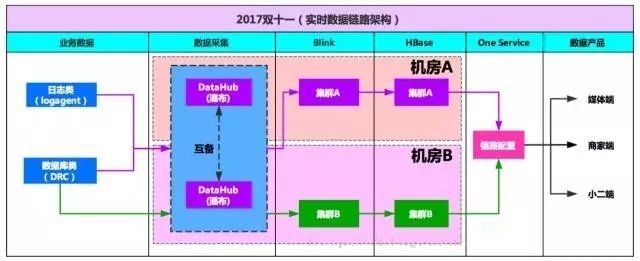
从数据采集、数据同步、数据计算、数据存储、数据服务,整条链路都是独立的。通过在Oneservice中的动态配置,能够实现链路切换,保障数据服务不终端。
上面内容就是保障今年双11流量洪峰的流计算技术秘密武器——我们不仅在于创新更希望能沉淀下来复用、优化技术到日常。
随着流计算的技术外界也在不停更迭,后续基于阿里丰富业务场景下我们还会不断优化升级流计算技术:
平台化,服务化,Stream Processing as a service
语义层的统一,Apache Beam,Flink 的Table API,以及最终Stream SQL都是非常热的project
实时智能,时下很火的深度学习或许未来会与流计算碰撞产生火花
实时离线的统一,这个也是很大的趋势,相较于现在普遍存在的实时一套,离线一套的做法,实时离线的统一也是各大引擎努力想要达到的。