DeepLearing—CV系列(二十)——基于MTCNN与centerloss/arcloss实现的人脸识别项目流程
文章目录
- 一、什么是人脸识别
- 1.1 人脸识别的官方解释和通俗解释
- 1.2 人脸识别出现的时间和影响
- 1.3 目前人脸识别在AI领域的地位
- 二、人脸识别的应用
- 2.1 主动身份认证
- 2.2 被动身份认证
- 2.3 人脸识别的盈利模式
- 三、实现人脸识别的流程
- 四、实现人脸识别的方法有哪些
- 4.1 传统机器学习方法
- 4.2 常用深度学习方法
- 五、Mtcnn+centerloss(arcfaceloss)的人脸识别流程
- 5.1 训练一个特征提取器
- 5.2 创建人脸特征库
- 5.3 获取目标人脸特征
- 5.4 对比人脸特征
- 六、关于视频人脸识别的过程
- 七、人脸识别的两类场景
- 八、人脸图像预处理
- 九、数据集
- 9.1 训练数据
- 9.2 验证数据
- 9.3 测试数据
- 十、网络
- 10.1 基础网络
- 10.2 相似度问题
一、什么是人脸识别
1.1 人脸识别的官方解释和通俗解释
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。通常采用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而大于检测到的人脸进行面部识别的一系列相关技术,通常也叫人像识别、面部识别。
1.2 人脸识别出现的时间和影响
人脸识别系统的研究始于20世纪60年代,80年代后随着计算机技术和光学成像技术的发展得到提高,而真正进入初级的应用阶段则在 90年后期,以美国、德国和日本的技术实现为主。
1.3 目前人脸识别在AI领域的地位
AI的标志
二、人脸识别的应用
第一,我们要区分的,动态和静态配合式的识别还是非配合式的识别。配合式的就是像蚂蚁金服那样的,需要数据的比对方进行配合,可以很好的去采集正脸的二维的数据。另外,就是非配合式的,非配合式的没有办法对排除方的配合,是需要随机采集的图片进行比对,这个识别的效果会差一些,但是识别的时效性会很高。
这两种模式当中,我们关注三点。
第一点,你的人脸建模当中到底提取了多少个特征点进行比对,这个跟我们人脸上面的一些特征是关键节点,每个人的差异很大,而你选取的特征点的数据越多,比对的准确率就会越高。我们也采访了一些专家,他们目前能够做到的特征点的比对,应该是在700个点以上。目前大部分做刷脸的门禁这样系统产品的公司,特征点的选取大概是在50个左右。所以我们去做调研和交流,可以问一下整个公司人脸识别建模当中特征点的数量。
第二点,人脸识别数据库的数据样本和大小,这是一个非常重要的指标。样本及大小,是我们可供的数据集,这些必须要对人脸,比如说一个人有500张照片,拍的都是他的脸,不同的角度和位置、光线,把这些数据进行合理的清洗,供机器去训练包括比对和识别之后,可以告诉你是识别对了还是识别错了,这样的样本数非常重要,有助于训练,提高模型的准确率。因此可标签的数据样本集的大小,这个大小目前至少是百万以上的级别,才会使得现在识别率能够提升到世界领先的水平,这个也是可以甄别的关键点之一。
第三点,是不是你的商业模式能够对你的整个的数据的获取,我们说人脸数据的比对,形成一个 正循环的模式。实际上数据来源,人脸的样本来源,是来源于两个非常重要的渠道,美图秀秀和美颜照相机,这是一个商业的互换,这个数据,因为考虑到做一个脱敏的处理,剩下的只有几百个关键的特征点的数据,其他的都被略去,用脱敏的技术之后,形成了从获取数据到训练模型,再到优化模型,持续的反馈结果,获取新的数据,这样的一个正循环的过程。有了这个以后,你的模型的数据就会获取的很好了,这是商业模式上非常重要的一个指标。
如果有了这三个指标之后,应当说同时具备了这三个,可能是在人脸识别领域当中有非常大的领先优势,或者是未来发展潜力的东西。同时我们在直观的性能方面去分析,直观的到底识别的表现上有两个非常重要的指标,一个是识别的准确率,我们界定了刚才说的学术界当中,每年一比的人脸识别大赛,现在基本上测试水平都在95%以上,但是是人和图片之间相互比对,说明是这个人,这算一个,再比对一个,又对了,算第二个。所有的人和照片都是匹配好的,最后正确率在99.2%左右,这是我们说的目前的正常的比对方法。

2.1 主动身份认证
交通安检、考勤打卡、人脸支付、人脸支付等等
2.2 被动身份认证
逃犯抓捕、其他敏感信息认证等等
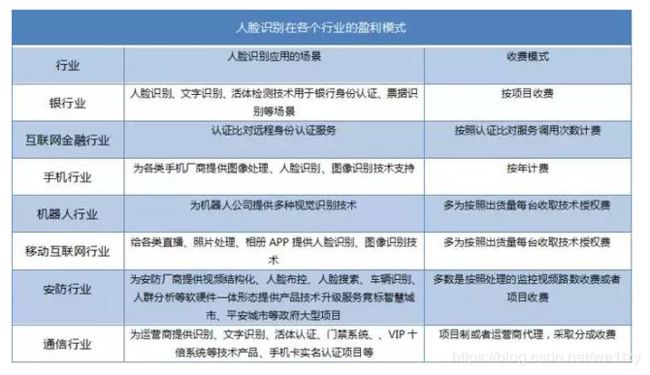
2.3 人脸识别的盈利模式
三、实现人脸识别的流程
(1)人脸检测(face detection)
(2)特征提取(feature extraction)
(3)人脸识别(face recognition)
1)人脸检测:人脸检测是指从输入图像中检测并提取人脸图像,通常采用haar特征和Adaboost算法 训练级联分类器对图像中的每一块进行分类。如果某一矩形区域通过了级联分类器,则被判别为人脸图像。
2)特征提取:特征提取是指通过一些数字来表征人脸信息,这些数字就是我们要提取的特征。
常见的人脸特征分为两类,一类是几何特征,另一类是表征特征。
几何特征是指眼睛、鼻子和嘴等面部特征之间的几何关系,如距离、面积和角度等。由于算法利用了一些直观的特征,计算量小。不过,由于其所需的特征点不能精确选择,限制了它的应用范围。另外,当光照变化、人脸有外物遮挡、面部表情变化时,特征变化较大。
表征特征利用人脸图像的灰度信息,通过一些算法提取全局或局部特征。其中比较常用的特征提取算法是LBP算法。LBP方法首先将 图像分成若干区域,在每个区域的像素640x960邻域中用中心值作阈值化,将结果看成是二进制数。LBP算子的特点是对单调 灰度变化保持不变。每个区域通过这样的运算得到一组直方图,然后将所有的直方图连起来组成一个大的直方图并进行直方图匹配计算进行分类。
3)人脸识别:将待识别人脸所提取的特征与数据库中人脸特征,进行对比,根据相似度判别分类。
人脸识别分为两大类:
四、实现人脸识别的方法有哪些
4.1 传统机器学习方法
检测:
(1)haar特征和Adaboost算法
(2)openCV:
![]()
提取:
LBP
4.2 常用深度学习方法
(1)RCNN+SVM系列
(2)Yolo+centerloss(arcfaceloss)
(3)Mtcnn+centerloss(arcfaceloss)
其他深度学习模型:
(1)PCN
(2)RetinaFace(商汤旷世在用)
(3)version-slim
(4)version-RFB
五、Mtcnn+centerloss(arcfaceloss)的人脸识别流程
5.1 训练一个特征提取器
A、创建特征提取网络(ResNet,MobileNet)
B、准备训练数据集(开源?收费?自制?)
C、设计合理的目标函数(centerloss,arcfaceloss)
D、训练网络使网络获得人脸特征提取的能力
5.2 创建人脸特征库
A、通过Mtcnn网络获得当前图像中的人脸框
B、将获取的人脸框传入特征提取器提取人脸特征
C、讲每个人脸标签和人脸特征作为一组特征值保存到人脸特征库
5.3 获取目标人脸特征
A、通过MTCNN网络获取当前画面中的所有人脸框
B、将获取的所有人脸框传入特征提取器提取人脸特征
5.4 对比人脸特征
A、将从当前画面获取到的每个人脸特征和人脸特征库里的人脸一一对比
B、如果当前画面中的某个人人脸特征和人脸特征库里的某个人脸特征的差异小于所设阈值,则认为当前画面中的我哪里和人脸库中正在对比的人脸是同一个人脸;如果当前画面中的某个人人脸特征和人脸特征库里的某个人脸特征的差异大于所设阈值,则认为当前画面中的我哪里和人脸库中正在对比的人脸不是同一个人脸。
六、关于视频人脸识别的过程
A、关于视频人脸识别的实际使用过程中,对于人脸特征的对比是基于连续帧画面的目标特征提取和对比得出的结果。所以实际应用中,只要某一帧画面中的目标被认为是人脸库的某个人脸,就可以认为完成对这个人的识别。
B、而作为标签的人脸采集也不只是一张人脸的图像特征,而是在相同的光度下对每个标签人脸的各个方位不同表情都进行采集,这样就相当于采集了一个人的各个角度的不同表情的人脸特征,从而提高了对这个人的识别率。但是同样也增大了对比的时间长度,因为当前画面里的人脸框需要和人脸特征库中每个人的每张人脸特征一一对比。
七、人脸识别的两类场景
一类是确认:这是人脸图像与数据库中已存的该人图像比对的过程,回答你是不是你的问题(即通常所说的1:1比对)

另一类是辨认:这是人脸图像与数据库中已存的所有图像匹配的过程,回答你是谁的问题(即通常所说的1:N比对)
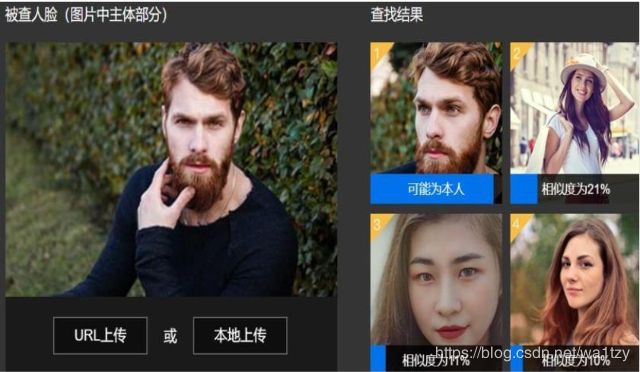
显然,人脸辨认要比人脸确认困难,因为辨认需要进行海量数据的匹配。
八、人脸图像预处理
对于人脸的图像预处理是基于人脸检测结果,对图像进行处理并最终服务于特征提取的过程。系统获取的原始图像由于受到各种条件的限制和随机干扰,往往不能直接使用,必须在图像处理的早期阶段对它进行灰度校正、噪声过滤等图像预处理。对于人脸图像而言,其预处理过程主要包括人脸图像的光线补偿、灰度变换、直方图均衡化、归一化、几何校正、滤波以及锐化等。
九、数据集
9.1 训练数据
VGG-Face 2
MS-Celeb-1M
9.2 验证数据
LFW
CFP
AgeDB
9.3 测试数据
MegaFace
FDDB
十、网络
10.1 基础网络
深度人脸识别常用网络:MobileNet、Resnet、DenseNet、SENet和DPN
10.2 相似度问题
在实际应用中,单词对比很难得到较高的相似度。所以实际使用时都是多帧对比来判断是否为目标人物。