1、多元线性回归模型
1.1多元回归模型与多元回归方程
设因变量为y,k个自变量分别为![]() ,描述因变量y如何依赖于自变量
,描述因变量y如何依赖于自变量![]() 和误差项ε的方程称为多元回归模型。其一般形式可表示为:
和误差项ε的方程称为多元回归模型。其一般形式可表示为:
![]()
式中,![]() 为模型的参数,ε为随机误差项。
为模型的参数,ε为随机误差项。
上式表明,y是![]() 的线性函数
的线性函数![]() 加上随机误差项ε。随机误差项的解释见:随机误差项。
加上随机误差项ε。随机误差项的解释见:随机误差项。
与一元线性回归类似,在多元线性回归模型中,对误差项同样有三个基本假设:
- 误差项期望为0;
- 对于自变量
 的所有值,ε的值都相等;
的所有值,ε的值都相等; - 误差项ε是一个服从正态分布的随机变量,且相互独立。
根据回归模型的假定,有
![]() ,
,
上式被称为多元回归方程,它描述了因变量y的期望值与自变量![]() 的关系。
的关系。
1.2估计的多元回归方程
回归方程中的参数![]() 是未知的,正是我们感兴趣的值。因此,当用样本数据计算出来的
是未知的,正是我们感兴趣的值。因此,当用样本数据计算出来的![]() 来去估计未知参数
来去估计未知参数![]() 时,就得到了估计的多元回归方程,其一般形式为:
时,就得到了估计的多元回归方程,其一般形式为:
![]()
式中,![]() 是参数
是参数![]() 的估计值,
的估计值,![]() 表示当
表示当![]() 不变时,
不变时,![]() 每变动一个单位,y的平均变动量。其余偏回归系数含义类似。
每变动一个单位,y的平均变动量。其余偏回归系数含义类似。
1.3 参数的最小二乘估计
同一元线性回归的最小二乘法估计,使得残差平方和达到最小的![]() 即为参数的最小二乘估计。
即为参数的最小二乘估计。
由于多元回归参数的最小二乘参数估计计算量比较大,手工几乎无法完成,需要借助于计算机。
本文选取了UCI数据集中一个关于计算机CPU性能的数据,该数据可以从网站http://archive.ics.uci.edu/ml/machine-learning-databases/cpu-performance/上下载。
在R中读取该数据,先对该数据集的数据结构进行探究。
> setwd("D:/Rdata/complex_data_analysis/")
> cpu<-read.table("cpu.txt",header = TRUE,sep=",")
> str(cpu)
'data.frame': 209 obs. of 10 variables:
$ name : Factor w/ 30 levels "adviser","amdahl",..: 1 2 2 2 2 2 2 2 2 2 ...
$ Model: Factor w/ 209 levels "100","1100/61-h1",..: 30 63 64 65 66 67 75 76 77 78 ...
$ MYCT : int 125 29 29 29 29 26 23 23 23 23 ...
$ MMIN : int 256 8000 8000 8000 8000 8000 16000 16000 16000 32000 ...
$ MMAX : int 6000 32000 32000 32000 16000 32000 32000 32000 64000 64000 ...
$ CACH : int 256 32 32 32 32 64 64 64 64 128 ...
$ CHMIN: int 16 8 8 8 8 8 16 16 16 32 ...
$ CHMAX: int 128 32 32 32 16 32 32 32 32 64 ...
$ PRP : int 198 269 220 172 132 318 367 489 636 1144 ...
$ ERP : int 199 253 253 253 132 290 381 381 749 1238 ...
根据R的输出结果可以看出,该数据有209个观测值,共10个变量。其变量名的细节可以从网站中关于该数据的描述中获得。
Name:供应商名称,
Model:型号名称
MYCT:机器周期时间,以纳秒为单位
MMIN:最小主内存千字节
MMAX:最大主内存千字节
CACH:高速缓存,以千字节为单位
CHMIN:单位最小信道
CHMAX:单位最大信道
PRP:发表的相关性能
ERP:根据原始文章估计的相对性能
由于供应商和型号名称属于分类数据,另外ERP是数据提供者根据他的一篇文章预测出来的,这三个变量都需要移除。
>cpu<-cpu[,c(-1,-2,-10)] > str(cpu) #查看需要进行分析的数据的结构 'data.frame': 209 obs. of 7 variables: $ MYCT : int 125 29 29 29 29 26 23 23 23 23 ... $ MMIN : int 256 8000 8000 8000 8000 8000 16000 16000 16000 32000 ... $ MMAX : int 6000 32000 32000 32000 16000 32000 32000 32000 64000 64000 ... $ CACH : int 256 32 32 32 32 64 64 64 64 128 ... $ CHMIN: int 16 8 8 8 8 8 16 16 16 32 ... $ CHMAX: int 128 32 32 32 16 32 32 32 32 64 ... $ PRP : int 198 269 220 172 132 318 367 489 636 1144 ... > head(cpu) #i查看前几行数据特征 MYCT MMIN MMAX CACH CHMIN CHMAX PRP 1 125 256 6000 256 16 128 198 2 29 8000 32000 32 8 32 269 3 29 8000 32000 32 8 32 220 4 29 8000 32000 32 8 32 172 5 29 8000 16000 32 8 16 132 6 26 8000 32000 64 8 32 318 > lm.cpu<-lm(PRP~.,data = cpu) > lm.cpu$coefficients #输出估计的回归系数 (Intercept) MYCT MMIN MMAX CACH CHMIN CHMAX -55.89393361 0.04885490 0.01529257 0.00557139 0.64140143 -0.27035755 1.48247217
与一元线性回归类似,R中也采用lm()函数进行多元回归分析,其中"PRP~."表示PRP为因变量,其他所有变量为自变量,data为所使用的数据框。
输出所有的系数——参数的最小二乘估计。
2、回归方程的拟合度
2.1 多重判定系数
与一元线性回归类似,对多元线性回归方程,需要用多重判定系数来评价其拟合程度。其公式与一元线性回归的判定系数公式相同,即:
![]() 。
。
但是对于多重判定系数,有一点需要注意,即自变量个数的增加将影响到因变量中被估计的回归方程所解释的变差数量。当增加自变量时,会使预测误差变得较小,从而减少残差平方和SSE,因此会增大判定系数R2。如果模型中增加一个自变量,即使这个自变量在统计上并不显著,R2也会变大。因此,为了避免增加自变量的个数而高估R2,可以使用自变量个数k以及样本量n去调整R2,得到估计的R2,其公式为:
![]() ,调整以后的
,调整以后的![]() 永远小于R2,也不会由于模型中自变量的个数的增加越来越接近1.。
永远小于R2,也不会由于模型中自变量的个数的增加越来越接近1.。
R2的平方根称为多重相关系数,也称为复相关系数。在上面的结果中,可以输出R2。
> summary(lm.cpu)
Call:
lm(formula = PRP ~ ., data = cpu)
Residuals:
Min 1Q Median 3Q Max
-195.82 -25.17 5.40 26.52 385.75
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -5.589e+01 8.045e+00 -6.948 5.00e-11 ***
MYCT 4.885e-02 1.752e-02 2.789 0.0058 **
MMIN 1.529e-02 1.827e-03 8.371 9.42e-15 ***
MMAX 5.571e-03 6.418e-04 8.681 1.32e-15 ***
CACH 6.414e-01 1.396e-01 4.596 7.59e-06 ***
CHMIN -2.704e-01 8.557e-01 -0.316 0.7524
CHMAX 1.482e+00 2.200e-01 6.737 1.65e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 59.99 on 202 degrees of freedom
Multiple R-squared: 0.8649, Adjusted R-squared: 0.8609
F-statistic: 215.5 on 6 and 202 DF, p-value: < 2.2e-16
上式输出了R2为0.8649,调整的R2为0.8609,说明模型拟合地还不错。
3、显著性检验
在一元线性回归中,我们已经学会了对回归模型进行线性关系检验与回归系数检验,这里同样也需要进行这两步。但是在这里,线性关系的检验与回归系数的检验并不等价。在多元线性回归模型中,只要有一个变量与因变量的线性关系显著,F检验就能通过,但这不意味着所有的变量都与因变量的线性关系显著。
3.1 线性关系检验
第一步:提出假设。
![]()
![]() 至少有一个不等于0
至少有一个不等于0
第二步:计算检验统计量F。
![]()
第三步:做出统计决策。
根据F的值与查F分布表得出的Fα,做出决策。
根据上述结果,p值为2.2e-16,几乎为0,远远 小于常用的α=0.05,因此线性关系显著。
3.2 回归系数的检验
第一步:提出假设。
![]()
![]()
第二步:计算检验统计量t。
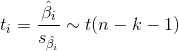 ,式中,
,式中,![]() 是回归系数
是回归系数![]() 的抽样分布的标准差,即
的抽样分布的标准差,即
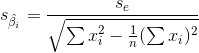
第三步:做出统计决策。
根据上述输出结果,只有一个回归系数——MMIN不显著,其他都比较显著。
4、多重共线性
4.1 多重共线性及其判别
当模型中两个自变量之间高度相关时,则称模型中存在多重共线性。判断模型的多重共线性最直观的方法是求自变量的相关系数矩阵。当然,还可以采取以下几种方法判断模型中是否存在多重共线性。
- 模型的线性关系检验(F检验)显著时,几乎所有的回归系数检验(t检验)都不显著;
- 回归系数的正负号与预期的相反;
- 容忍度与方差扩大因子。
某个自变量的容忍度等于1减去以该变量为因变量,其它变量为自变量所拟合的模型的R2,即1- R2。通常认为容忍度小于0.1时,存在严重的多重共线性。方差扩大因子(VIF)为容忍度的倒数,当VIF大于10时,一般可认为存在严重的多重共线性。下面求出自变量的相关系数矩阵。
> cor(cpu[,1:6])
MYCT MMIN MMAX CACH CHMIN CHMAX
MYCT 1.0000000 -0.3356422 -0.3785606 -0.3209998 -0.3010897 -0.2505023
MMIN -0.3356422 1.0000000 0.7581573 0.5347291 0.5171892 0.2669074
MMAX -0.3785606 0.7581573 1.0000000 0.5379898 0.5605134 0.5272462
CACH -0.3209998 0.5347291 0.5379898 1.0000000 0.5822455 0.4878458
CHMIN -0.3010897 0.5171892 0.5605134 0.5822455 1.0000000 0.5482812
CHMAX -0.2505023 0.2669074 0.5272462 0.4878458 0.5482812 1.0000000
可以看出,MMIN和MMAX的相关系数为0.76,比较大,另外,CHMIN与其他变量(除了CHMAX)的相关系数绝对值也超过了0.5,初步认为存在多重共线性。
4.2 多重共线性的处理
(1)将一个或多个自变量从模型中剔除,使保留的自变量之间尽可能不相关。
(2)如果非要保留模型中所有的自变量,那就应该:
- 避免根据t统计量对单个参数进行检验;
- 对因变量的推断限定在自变量样本的范围内。
5、预测
R中可以根据估计的回归方程进行预测,期预测结果可以表示为:
> predict.lm(lm.cpu,interval = "prediction")[1:6,]
fit lwr upr
1 337.1856 201.45329 472.9180
2 311.9490 192.27143 431.6266
3 311.9490 192.27143 431.6266
4 311.9490 192.27143 431.6266
5 199.0872 79.60871 318.5657
6 332.3273 212.77407 451.8805
上面求出预测区间以及相应的估计值。
6、变量选择与逐步回归
当模型中存在多重共线性时,可以使用以下几种方法进行处理:
- 向前选择
- 向后剔除
- 逐步回归
R中提供了step()函数实现这个功能。
> stpcpu<-step(lm.cpu)
Start: AIC=1718.24
PRP ~ MYCT + MMIN + MMAX + CACH + CHMIN + CHMAX
Df Sum of Sq RSS AIC
- CHMIN 1 359 727279 1716.3
726920 1718.2
- MYCT 1 27985 754905 1724.1
- CACH 1 76009 802929 1737.0
- CHMAX 1 163347 890267 1758.6
- MMIN 1 252179 979099 1778.5
- MMAX 1 271177 998097 1782.5
Step: AIC=1716.34
PRP ~ MYCT + MMIN + MMAX + CACH + CHMAX
Df Sum of Sq RSS AIC
727279 1716.3
- MYCT 1 28343 755623 1722.3
- CACH 1 78715 805995 1735.8
- CHMAX 1 177114 904393 1759.9
- MMIN 1 258252 985531 1777.8
- MMAX 1 270856 998135 1780.5
该函数根据AIC信息准则对变量进行选择,取使AIC最小的回归模型。最终结果保留了5个自变量,CHMIN变量被移除。
> summary(stpcpu) #输出变量选择后的最终结果
Call:
lm(formula = PRP ~ MYCT + MMIN + MMAX + CACH + CHMAX, data = cpu)
Residuals:
Min 1Q Median 3Q Max
-193.37 -24.95 5.76 26.64 389.66
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -5.608e+01 8.007e+00 -7.003 3.59e-11 ***
MYCT 4.911e-02 1.746e-02 2.813 0.0054 **
MMIN 1.518e-02 1.788e-03 8.490 4.34e-15 ***
MMAX 5.562e-03 6.396e-04 8.695 1.18e-15 ***
CACH 6.298e-01 1.344e-01 4.687 5.07e-06 ***
CHMAX 1.460e+00 2.076e-01 7.031 3.06e-11 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 59.86 on 203 degrees of freedom
Multiple R-squared: 0.8648, Adjusted R-squared: 0.8615
F-statistic: 259.7 on 5 and 203 DF, p-value: < 2.2e-16
处理后的R2几乎没有变化,但是调整的R2略微增加。