艺赛旗RPA验证码处理系列(三):破解极验滑动验证码
目前艺赛旗RPA已经更新到8.0版本,可以让所有用户免费下载试用http://www.i-search.com.cn/index.html?from=line1 (复制链接下载)
一,介绍
一些网站会在正常的账号密码认证之外加一些验证码,以此来明确地区分人/机行为,从一定程度上达到反爬的效果,对于简单的校验码Tesserocr就可以搞定,如下

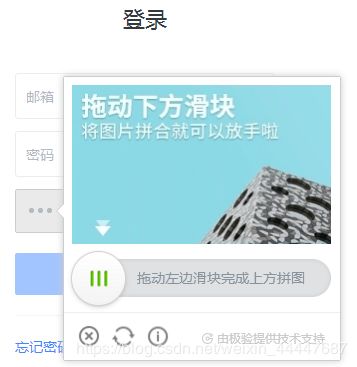
但一些网站加入了滑动验证码,最典型的要属于极验滑动认证了,极验官网:http://www.geetest.com/,下图是极验的登录界面
现在极验验证码已经更新到了3.0版本,截至2017年7月全球已有十六万家企业正在使用极验,每天服务响应超过四亿次,广泛应用于直播视频,金融服务,电子商务,游戏娱乐,政府企业等各大类型网站
对于这类验证,如果我们直接模拟表单请求,繁琐的认证参数与认证流程会让你蛋碎一地,我们可以用selenium驱动浏览器来解决这个问题,大致分为以下几个步骤
#1,输入账号,密码,然后点击登陆
#2,点击按钮,弹出没有缺口的图
#3,针对没有缺口的图片进行截图
#4,点击滑动按钮,弹出有缺口的图
#5,针对有缺口的图片进行截图
#6,对比两张图片,找出缺口,即滑动的位移
#7,按照人的行为行为习惯,把总位移切成一段段小的位移
#8,按照位移移动
#9,完成登录
二,实现
安装:selenium+chrome/phantomjs
安装:Pillow
这里用的是Chrome
Pillow:基于PIL,处理python 3.x的图形图像库。因为PIL只能处理到python 2.x,而这个模块能处理Python3.x,目前用它做图形的很多。
http://www.cnblogs.com/apexchu/p/4231041.html
C:\Users\Administrator>pip3 install pillow
C:\Users\Administrator>python3
Python 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36) [MSC v.1900 64 bit (AMD64)] on win32
Type “help”, “copyright”, “credits” or “license” for more information.
from PIL import Image
代码如下(增加部分注释)
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from PIL import Image
import time
def get_snap():
‘’’
对整个网页截图,保存成图片,然后用PIL.Image拿到图片对象
:return: 图片对象
‘’’
driver.save_screenshot(‘snap.png’)
page_snap_obj=Image.open(‘snap.png’)
return page_snap_obj
def get_image():
‘’’
从网页的网站截图中,截取验证码图片
:return: 验证码图片
‘’’
img=wait.until(EC.presence_of_element_located((By.CLASS_NAME,‘geetest_canvas_img’)))
time.sleep(2) #保证图片刷新出来
localtion=img.location
size=img.size
top=localtion['y']
bottom=localtion['y']+size['height']
left=localtion['x']
right=localtion['x']+size['width']
page_snap_obj=get_snap()
crop_imag_obj=page_snap_obj.crop((left,top,right,bottom))
return crop_imag_obj
def get_distance(image1,image2):
‘’’
拿到滑动验证码需要移动的距离
:param image1:没有缺口的图片对象
:param image2:带缺口的图片对象
:return:需要移动的距离
#两张图大小一样,那就通过两个for循环依次对比每个像素点的RGB值
#如果相差超过60(threshold)则就认为找到了缺口的位置
‘’’
threshold = 60 #色差值
left = 57 #起始位置(开始进行RGB色差判断的最小值)
for i in range(left,image1.size[0]):
for j in range(image1.size[1]):
rgb1=image1.load()[i,j]
rgb2=image2.load()[i,j]
res1=abs(rgb1[0]-rgb2[0])
res2=abs(rgb1[1]-rgb2[1])
res3=abs(rgb1[2]-rgb2[2])
# 如果相差超过60(threshold)则就认为找到了缺口的位置
if not (res1 < threshold and res2 < threshold and res3 < threshold):
return i-7 #经过测试,误差为大概为7
return i-7 #经过测试,误差为大概为7
def get_tracks(distance):
‘’’
拿到移动轨迹,模仿人的滑动行为,先匀加速后匀减速
匀变速运动基本公式:
①v=v0+at
②s=v0t+½at²
③v²-v0²=2as
:param distance: 需要移动的距离
:return: 存放每0.3秒移动的距离
'''
#初速度
v=0
#单位时间为0.2s来统计轨迹,轨迹即0.2内的位移
t=0.3
#位移/轨迹列表,列表内的一个元素代表0.2s的位移
tracks=[]
#当前的位移
current=0
#到达mid值开始减速
mid=distance*4/5
while current < distance:
if current < mid:
# 加速度越小,单位时间的位移越小,模拟的轨迹就越多越详细
a= 2
else:
a=-3
#初速度
v0=v
#0.2秒时间内的位移
s=v0*t+0.5*a*(t**2)
#当前的位置
current+=s
#添加到轨迹列表
tracks.append(round(s))
#速度已经达到v,该速度作为下次的初速度
v=v0+a*t
return tracks
try:
driver=webdriver.Chrome()
driver.get(‘https://account.geetest.com/login’)
wait=WebDriverWait(driver,10)
#步骤一:先点击按钮,弹出没有缺口的图片
button=wait.until(EC.presence_of_element_located((By.CLASS_NAME,'geetest_radar_tip')))
button.click()
#步骤二:拿到没有缺口的图片
image1=get_image()
#步骤三:点击拖动按钮,弹出有缺口的图片
button=wait.until(EC.presence_of_element_located((By.CLASS_NAME,'geetest_slider_button')))
button.click()
#步骤四:拿到有缺口的图片
image2=get_image()
# print(image1,image1.size)
# print(image2,image2.size)
#步骤五:对比两张图片的所有RBG像素点,得到不一样像素点的x值,即要移动的距离
distance=get_distance(image1,image2)
#步骤六:模拟人的行为习惯(先匀加速拖动后匀减速拖动),把需要拖动的总距离分成一段一段小的轨迹
tracks=get_tracks(distance)
print(tracks)
print(image1.size)
print(distance,sum(tracks))
#步骤七:按照轨迹拖动,完全验证
button=wait.until(EC.presence_of_element_located((By.CLASS_NAME,'geetest_slider_button')))
ActionChains(driver).click_and_hold(button).perform()
for track in tracks:
ActionChains(driver).move_by_offset(xoffset=track,yoffset=0).perform()
else:
ActionChains(driver).move_by_offset(xoffset=3,yoffset=0).perform() #先移过一点
ActionChains(driver).move_by_offset(xoffset=-3,yoffset=0).perform() #再退回来,是不是更像人了
time.sleep(0.5) #0.5秒后释放鼠标
ActionChains(driver).release().perform()
#步骤八:完成登录
input_email=driver.find_element_by_id('email')
input_password=driver.find_element_by_id('password')
button=wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'login-btn')))
input_email.send_keys('[email protected]')
input_password.send_keys('linhaifeng123')
# button.send_keys(Keys.ENTER)
button.click()
import time
time.sleep(200)
finally:
driver.close()
案例:
1.破解博客园后台登陆
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from PIL import Image
import time
def get_snap():
driver.save_screenshot(‘full_snap.png’)
page_snap_obj=Image.open(‘full_snap.png’)
return page_snap_obj
def get_image():
img=driver.find_element_by_class_name(‘geetest_canvas_img’)
time.sleep(2)
location=img.location
size=img.size
left=location['x']
top=location['y']
right=left+size['width']
bottom=top+size['height']
page_snap_obj=get_snap()
image_obj=page_snap_obj.crop((left,top,right,bottom))
# image_obj.show()
return image_obj
def get_distance(image1,image2):
start=57
threhold=60
for i in range(start,image1.size[0]):
for j in range(image1.size[1]):
rgb1=image1.load()[i,j]
rgb2=image2.load()[i,j]
res1=abs(rgb1[0]-rgb2[0])
res2=abs(rgb1[1]-rgb2[1])
res3=abs(rgb1[2]-rgb2[2])
# print(res1,res2,res3)
if not (res1 < threhold and res2 < threhold and res3 < threhold):
return i-7
return i-7
def get_tracks(distance):
distance+=20 #先滑过一点,最后再反着滑动回来
v=0
t=0.2
forward_tracks=[]
current=0
mid=distance*3/5
while current < distance:
if current < mid:
a=2
else:
a=-3
s=v*t+0.5*a*(t**2)
v=v+a*t
current+=s
forward_tracks.append(round(s))
#反着滑动到准确位置
back_tracks=[-3,-3,-2,-2,-2,-2,-2,-1,-1,-1] #总共等于-20
return {'forward_tracks':forward_tracks,'back_tracks':back_tracks}
try:
# 1、输入账号密码回车
driver = webdriver.Chrome()
driver.implicitly_wait(3)
driver.get(‘https://passport.cnblogs.com/user/signin’)
username = driver.find_element_by_id('input1')
pwd = driver.find_element_by_id('input2')
signin = driver.find_element_by_id('signin')
username.send_keys('linhaifeng')
pwd.send_keys('xxxxx')
signin.click()
# 2、点击按钮,得到没有缺口的图片
button = driver.find_element_by_class_name('geetest_radar_tip')
button.click()
# 3、获取没有缺口的图片
image1 = get_image()
# 4、点击滑动按钮,得到有缺口的图片
button = driver.find_element_by_class_name('geetest_slider_button')
button.click()
# 5、获取有缺口的图片
image2 = get_image()
# 6、对比两种图片的像素点,找出位移
distance = get_distance(image1, image2)
# 7、模拟人的行为习惯,根据总位移得到行为轨迹
tracks = get_tracks(distance)
print(tracks)
# 8、按照行动轨迹先正向滑动,后反滑动
button = driver.find_element_by_class_name('geetest_slider_button')
ActionChains(driver).click_and_hold(button).perform()
# 正常人类总是自信满满地开始正向滑动,自信地表现是疯狂加速
for track in tracks['forward_tracks']:
ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform()
# 结果傻逼了,正常的人类停顿了一下,回过神来发现,卧槽,滑过了,然后开始反向滑动
time.sleep(0.5)
for back_track in tracks['back_tracks']:
ActionChains(driver).move_by_offset(xoffset=back_track, yoffset=0).perform()
# 小范围震荡一下,进一步迷惑极验后台,这一步可以极大地提高成功率
ActionChains(driver).move_by_offset(xoffset=-3, yoffset=0).perform()
ActionChains(driver).move_by_offset(xoffset=3, yoffset=0).perform()
# 成功后,骚包人类总喜欢默默地欣赏一下自己拼图的成果,然后恋恋不舍地松开那只脏手
time.sleep(0.5)
ActionChains(driver).release().perform()
time.sleep(10) # 睡时间长一点,确定登录成功
finally:
driver.close()
2.修订版博客园后台登陆
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from PIL import Image
import time
def get_snap(driver):
driver.save_screenshot(‘full_snap.png’)
page_snap_obj=Image.open(‘full_snap.png’)
return page_snap_obj
def get_image(driver):
img=driver.find_element_by_class_name(‘geetest_canvas_img’)
time.sleep(2)
location=img.location
size=img.size
left=location['x']
top=location['y']
right=left+size['width']
bottom=top+size['height']
page_snap_obj=get_snap(driver)
image_obj=page_snap_obj.crop((left,top,right,bottom))
# image_obj.show()
return image_obj
def get_distance(image1,image2):
start=57
threhold=60
for i in range(start,image1.size[0]):
for j in range(image1.size[1]):
rgb1=image1.load()[i,j]
rgb2=image2.load()[i,j]
res1=abs(rgb1[0]-rgb2[0])
res2=abs(rgb1[1]-rgb2[1])
res3=abs(rgb1[2]-rgb2[2])
# print(res1,res2,res3)
if not (res1 < threhold and res2 < threhold and res3 < threhold):
return i-7
return i-7
def get_tracks(distance):
distance+=20 #先滑过一点,最后再反着滑动回来
v=0
t=0.2
forward_tracks=[]
current=0
mid=distance*3/5
while current < distance:
if current < mid:
a=2
else:
a=-3
s=v*t+0.5*a*(t**2)
v=v+a*t
current+=s
forward_tracks.append(round(s))
#反着滑动到准确位置
back_tracks=[-3,-3,-2,-2,-2,-2,-2,-1,-1,-1] #总共等于-20
return {'forward_tracks':forward_tracks,'back_tracks':back_tracks}
def crack(driver): #破解滑动认证
# 1、点击按钮,得到没有缺口的图片
button = driver.find_element_by_class_name(‘geetest_radar_tip’)
button.click()
# 2、获取没有缺口的图片
image1 = get_image(driver)
# 3、点击滑动按钮,得到有缺口的图片
button = driver.find_element_by_class_name('geetest_slider_button')
button.click()
# 4、获取有缺口的图片
image2 = get_image(driver)
# 5、对比两种图片的像素点,找出位移
distance = get_distance(image1, image2)
# 6、模拟人的行为习惯,根据总位移得到行为轨迹
tracks = get_tracks(distance)
print(tracks)
# 7、按照行动轨迹先正向滑动,后反滑动
button = driver.find_element_by_class_name('geetest_slider_button')
ActionChains(driver).click_and_hold(button).perform()
# 正常人类总是自信满满地开始正向滑动,自信地表现是疯狂加速
for track in tracks['forward_tracks']:
ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform()
# 结果傻逼了,正常的人类停顿了一下,回过神来发现,卧槽,滑过了,然后开始反向滑动
time.sleep(0.5)
for back_track in tracks['back_tracks']:
ActionChains(driver).move_by_offset(xoffset=back_track, yoffset=0).perform()
# 小范围震荡一下,进一步迷惑极验后台,这一步可以极大地提高成功率
ActionChains(driver).move_by_offset(xoffset=-3, yoffset=0).perform()
ActionChains(driver).move_by_offset(xoffset=3, yoffset=0).perform()
# 成功后,骚包人类总喜欢默默地欣赏一下自己拼图的成果,然后恋恋不舍地松开那只脏手
time.sleep(0.5)
ActionChains(driver).release().perform()
def login_cnblogs(username,password):
driver = webdriver.Chrome()
try:
# 1、输入账号密码回车
driver.implicitly_wait(3)
driver.get(‘https://passport.cnblogs.com/user/signin’)
input_username = driver.find_element_by_id('input1')
input_pwd = driver.find_element_by_id('input2')
signin = driver.find_element_by_id('signin')
input_username.send_keys(username)
input_pwd.send_keys(password)
signin.click()
# 2、破解滑动认证
crack(driver)
time.sleep(10) # 睡时间长一点,确定登录成功
finally:
driver.close()
if name == ‘main’:
login_cnblogs(username=‘linhaifeng’,password=‘xxxx’)
用类封装的版本svcr
import time
import random
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from PIL import Image
def simulate_reaction(func):
“”“模拟人类的反应时间”""
from functools import wraps
@wraps
def inner(self, *args, **kwargs):
time.sleep(random.uniform(0.2, 1))
ret = func(self, *args, **kwargs)
return ret
return inner
class SVCR:
“”“识别滑动验证码 极验验证”""
def __init__(self, driver):
self.driver = driver
self.get_full_img = True
# @simulate_reaction
def run(self):
"""执行识别流程"""
# 1. 点击按钮开始验证
self.click_start_btn()
# 2. 根据验证类型验证
return self.judge_and_auth()
def judge_and_auth(self):
"""判断验证类型并执行相应的验证方法"""
if True:
return self.auth_slide()
else:
pass
def auth_slide(self):
def get_distance(img1, img2):
"""计算滑动距离"""
threshold = 60
# 忽略可动滑块部分
start_x = 57
for i in range(start_x, img1.size[0]):
for j in range(img1.size[1]):
rgb1 = img1.load()[i, j]
rgb2 = img2.load()[i, j]
res1 = abs(rgb1[0] - rgb2[0])
res2 = abs(rgb1[1] - rgb2[1])
res3 = abs(rgb1[2] - rgb2[2])
if not (res1 < threshold and res2 < threshold and res3 < threshold):
return i - 7 # 经过测试,误差为大概为7
def get_tracks(distance):
"""
制造滑动轨迹
策略:匀加速再匀减速,超过一些,再回调,左右小幅度震荡
"""
v = 0
current = 0
t = 0.2
tracks = []
# 正向滑动
while current < distance+10:
if current < distance*2/3:
a = 2
else:
a = -3
s = v*t + 0.5*a*(t**2)
current += s
tracks.append(round(s))
v = v + a*t
# 往回滑动
current = 0
while current < 13:
if current < distance*2/3:
a = 2
else:
a = -3
s = v*t + 0.5*a*(t**2)
current += s
tracks.append(-round(s))
v = v + a*t
# 最后修正
tracks.extend([2, 2, -3, 2])
return tracks
# 1. 截取完整图片
if self.get_full_img:
time.sleep(2) # 等待图片加载完毕
img_before = self.get_img()
else:
img_before = self._img_before
# 2. 点击出现缺口图片
slider_btn = self.driver.find_element_by_class_name("geetest_slider_button")
slider_btn.click()
# 3. 截取缺口图片
time.sleep(2) # 等待图片加载完毕
img_after = self.get_img()
# 4. 生成移动轨迹
tracks = get_tracks(get_distance(img_before, img_after))
# 5. 模拟滑动
slider_btn = self.driver.find_element_by_class_name("geetest_slider_button")
ActionChains(self.driver).click_and_hold(slider_btn).perform()
for track in tracks:
ActionChains(self.driver).move_by_offset(xoffset=track, yoffset=0).perform()
# 6. 释放鼠标
time.sleep(0.5) # 0.5秒后释放鼠标
ActionChains(self.driver).release().perform()
# 7. 验证是否成功
time.sleep(2)
div_tag = self.driver.find_element_by_class_name("geetest_fullpage_click")
if "display: block" in div_tag.get_attribute("style"):
'''判断模块对话框是否存在,如果存在就说明没有验证成功,"display: block",重新去验证'''
self.get_full_img = False
setattr(self, "_img_before", img_before)
return self.auth_slide()
else:
#如果验证成功"display: none"
time.sleep(1000)
return True
# @simulate_reaction
def click_start_btn(self, search_style="CLASS_NAME", search_content="geetest_radar_tip"):
"""找到开始按钮并点击"""
btn = getattr(self.driver, "find_element")(getattr(By, search_style), search_content)
btn.click()
def get_img(self):
"""截取图片"""
div_tag = self.driver.find_element_by_class_name("geetest_slicebg")
# 计算截取图片大小
img_pt = div_tag.location # {'x': 296, 'y': 15}
img_size = div_tag.size # {'height': 159, 'width': 258}
img_box = (img_pt["x"], img_pt["y"], img_pt["x"] + img_size["width"], img_pt["y"] + img_size["height"])
# 保存当前浏览页面
self.driver.save_screenshot("snap.png")
# 截取目标图片
img = Image.open("snap.png")
return img.crop(img_box)
使用类
from selenium import webdriver
from svcr import SVCR
def auth():
driver = webdriver.Chrome()
# browser.get(url)
driver.get(“https://passport.cnblogs.com/user/signin”) #请求页面
driver.implicitly_wait(3)
# 第一步:输入账号、密码,然后点击登陆
input_name = driver.find_element_by_id(‘input1’) #找到输入用户名的框
input_pwd = driver.find_element_by_id(‘input2’) #找到输入密码的框
input_button = driver.find_element_by_id(‘signin’) #找到按钮
input_name.send_keys(“name”)#博客园的账号
input_pwd.send_keys(“pwd”)#博客园的密码
input_button.click() #进行点击
return driver
def main():
driver=auth() #进行验证,
_auth = SVCR(driver)
_auth.run()
if name == ‘main’:
main()