Python 网络爬虫实战:爬取《去哪儿》网数千篇旅游攻略数据,再也不愁旅游去哪儿玩了
好久不见!
今天我们来爬取 去哪儿网站 的 旅游攻略 数据。
0x00 找一个合理的作案动机
作为一名立志成为技术宅的普通肥宅,每次一到周末就会面临一个人生难题:这周末怎么过?
本来是没有这些问题的,该吃吃该睡睡,打打游戏敲敲代码,也挺自在。
只是后来毕业,来到一个新的城市,赚的钱除了吃住还有富余,总觉得如果不趁着周末和假期出去好好逛逛这个城市,就等于白来一趟,那就太亏了。
话虽如此,旅游岂是说走就走的。好几次我下定决心出门,结果在小区门口的十字路口,看着车来车往陷入沉思:我特么去哪儿玩啊!思索半天,最后去超市买了一提肥宅快乐水,回家躺床上打开了王者荣耀。。。
哎!
都怪没有一份完整的旅游攻略,导致我想出去玩都不知道去哪儿玩!
为了防止我以后再找这种自欺欺人的借口,我决定爬取 去哪儿 https://travel.qunar.com/travelbook/list.htm 网站的旅游攻略库。
0x01 分析目标网站
分析流程主要有以下几步:
1. 打开网站,看看网页上展示一些什么数据。
2. 通过 F12 开发者工具,找到数据的获取接口(数据是 html 还是 json,翻页是 url 控制还是 ajax)
3. 编写简单的代码,发起网络请求,试探对方网站的反爬机制。
4. 完成以上三步之后,就可以完善代码,正式爬取数据了。
1. 我们可以获取哪些数据
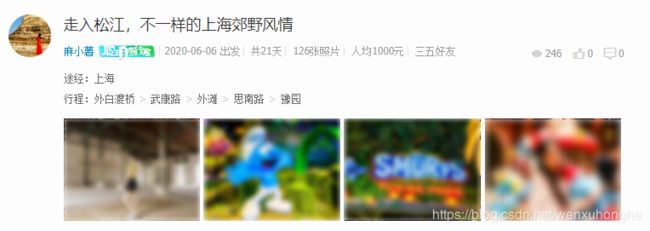
如图,通过观察,我们可以发现网站上展示了以下数据:
- 文章标题:走入松江,不一样的上海郊野风情
- 作者昵称:麻小薯
- 出发日期:2020-06-06 出发
- 游玩天数:共21天
- 照片数量:126张照片
- 人均消费:人均1000元
- 同行人数:三五好友
- 旅游类型:深度游 环游 短途周末(由于篇幅原因网页中隐藏显示此项,但是在开发者工具中可以看到)
- 旅游途经:途经:上海
- 旅游行程:行程:外白渡桥>武康路>外滩>思南路>豫园
- 阅读量:246
- 点赞数:0
- 评论数:0
而且,多翻阅不同的文章,可以发现
【文章标题】【作者昵称】【出发日期】【游玩天数】【阅读量】【点赞数】【评论数】【途经】【行程】这些数据项是每一篇游记文章中共有的数据。
【照片数量】【人均消费】【同行人数】【旅游类型】这四项,会根据作者的设置,显示全部,显示部分,或者全部隐藏。
2. 抓取数据的接口
一般情况下,网站的数据加载方式有两种,一种是直接存放在静态的HTML网页中,另一种是通过 Ajax 动态的加载到网页中。
那怎么判断我们要爬取的网站,到底采用的是哪一种数据加载方式呢?这里教大家几个小办法。
① 通过翻页
- 如果翻页的时候,网址中出现类似于 “p=2” "p=3" 或者 "page=2" "page=3" 的字样,并且后面的数字在翻页的时候跟着页码在变化,那么,这个网站大概率就是静态的 HTML 网页。
- 如果在翻页的时候,网页中的数据变化了,但是地址栏中的 URL 没有出现与页码相关的参数,甚至全程没有变化,那么这个网站数据大概率是通过 Ajax 动态加载的。
- 有的网站没有翻页按钮,也不知道是第几页,当滑动条滚动到底部时会自动加载后面的数据。这种毫无疑问是 Ajax 动态加载的。
② 开发者工具抓包
通过上面 翻页 的方式大致确定了数据加载方式之后,我们可以在浏览器中按 F12,调用 开发者工具 进行抓包,验证我们的想法,并找到数据的接口。
Ⅰ. 打开开发者工具,切换到 Network 项,然后在网页中进行翻页操作(这一步主要是是网站出现 “加载新数据” 这一过程,方便我们抓包分析)。
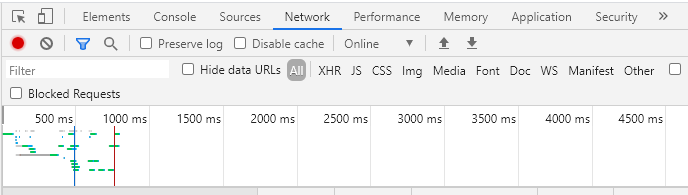
Ⅱ. 开发者工具会为我们抓取整个过程中网站与服务器通信的所有数据包。如截图所示,这些数据包类型有 XHR,JS,CSS,Img 等等,这里我们主要关注 XHR 和 Doc 这两类(一般情况下,XHR 中的数据是 json 格式的,Doc 中的数据是 Html 格式的)。
- 如果在翻页过程中,XHR 中抓取到了新的请求,而且 json 中含有新加载的数据,那么这个网页就是动态加载数据的,且这个请求就是获取数据的接口。
- 如果在翻页的过程中,XHR 中没有捕获到数据,而在 Doc 中有,那么这个网页就是静态加载在html中的,这个请求就是获取数据的接口。
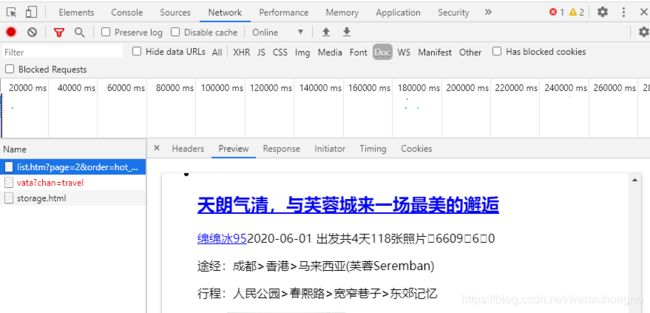
通过测试,我们在 Doc 中找到了 去哪儿网 旅游攻略数据的接口。
3. 试探网站的反爬机制
找到网站的数据接口之后,我们还不能大意,需要简单地编写代码,调用这个接口,来试探网站的反爬机制。只有绕过了反爬机制,用代码获取到了数据,才算是成功了。
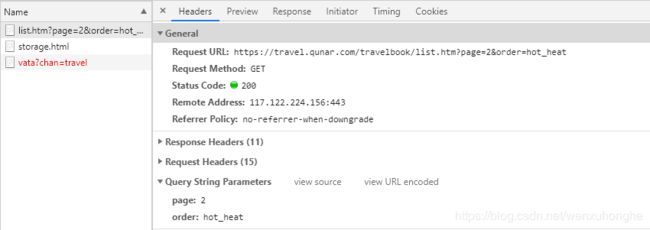
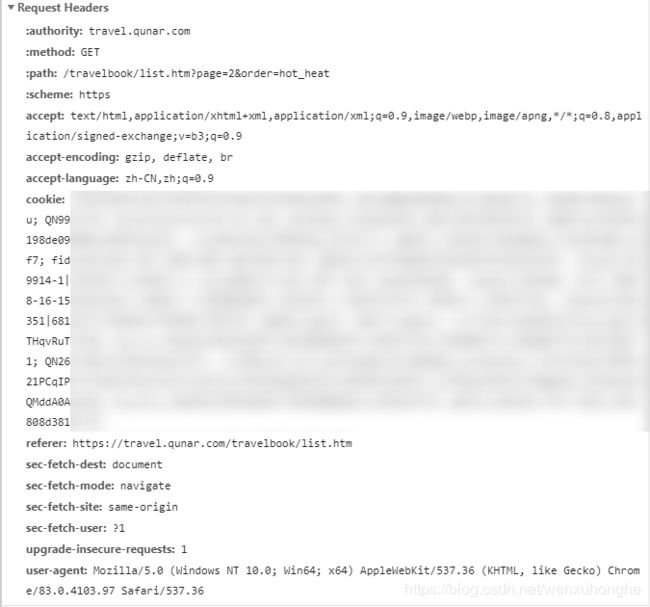
这是我们上一步找到的接口,在 Headers 选项卡中可以看到这个接口的基本参数,我们主要关注以下几个:
- Request Url : 请求的 URL
- Request Method :请求方式
- Request Headers :请求头(通常包含 user-agent 和 accept 即可,有些网站可能需要 cookie)
- Query String Parameters :请求参数
然后我们在 python 中,用代码构造这些参数,访问这个接口,看是否可以获取数据
import requests
# Request Url
url = "https://travel.qunar.com/travelbook/list.htm?page=2&order=hot_heat"
# Request Headers
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
}
# Query String Parameters
params = {
'page': 2,
'order': 'hot_heat',
}
# 发起网络请求,请求方式是 get
r = requests.get(url, data=params, headers=headers)
r.encoding = r.apparent_encoding
print(r.text)执行代码,很幸运,这个网站没有太多的反爬机制,直接就获取到了数据。
0x02 编写代码
上述的操作一步步做下来,我们基本上已经攻克了整个爬虫中最困难的一步了。接下来,只需要对爬取到的内容进行解析,提取出我们需要的数据即可。
由于爬到的数据是 HTML 格式,我们选用 BeautifulSoup 库进行解析。
bsObj = BeautifulSoup(html,"html.parser")
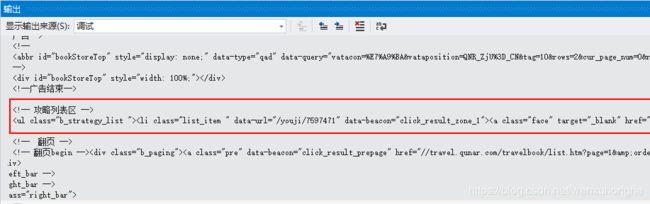
我们对照网页源码来简单分析(有条件的可以去 旅游攻略库 网站,打开开发者工具对照着分析)。
- 攻略列表存放在一个 class="b_strategy_list" 的 ul 标签下,每一个 li 标签对应一篇旅游攻略。
bookList = bsObj.find("ul",attrs = {"class":"b_strategy_list"})
li_List = bookList.find_all("li")- 文章链接在 li -> h2 -> a,在 a 标签的 href 属性中
link = "https://travel.qunar.com" + li.h2.a["href"]- 文章标题在li -> h2 -> a,在 a 标签的 Text 中
title = li.h2.a.text- 作者昵称,出发日期,游玩天数,照片数量,人均消费,游玩人数,游玩类型等信息,在 li -> p(class="user_info") -> span(class="intro") -> span。同一级有多个同名标签时,可以通过 class 名进行区分。
user_info = li.find("p", attrs = {"class":"user_info"})
intro = user_info.find("span", attrs = {"class":"intro"})
user_name = intro.find("span", attrs = {"class":"user_name"}).text
date = intro.find("span", attrs = {"class":"date"}).text
days = intro.find("span", attrs = {"class":"days"}).text
photo_nums = intro.find("span", attrs = {"class":"photo_nums"}).text
people = intro.find("span", attrs = {"class":"people"}).text
trip = intro.find("span", attrs = {"class":"trip"}).text
fee = intro.find("span", attrs = {"class":"fee"}).text- 阅读数,点赞数,评论数 等信息,在 li -> p(class="user_info") -> span(class="nums") -> span。
nums = user_info.find("span", attrs = {"class":"nums"})
icon_view = nums.find("span", attrs = {"class":"icon_view"}).span.text
icon_love = nums.find("span", attrs = {"class":"icon_love"}).span.text
icon_comment = nums.find("span", attrs = {"class":"icon_comment"}).span.text上述代码,对照着网页源码,和上面的分析,大家应该可以很轻易掌握这个库的使用方法。
最后我们将代码整理一下:
import requests
from bs4 import BeautifulSoup
def fetchHotel(url):
# 发起网络请求,获取数据
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36',
}
# 发起网络请求(参数放到 URL 中了)
r = requests.get(url,headers=headers)
r.encoding = "utf-8"
return r.text
def getPageNum(html):
#获取总页数
pageNum=1
bsObj = BeautifulSoup(html,"html.parser")
pageList = bsObj.find("div",attrs = {"class":"b_paging"}).find_all("a")
if(pageList):
pageNum = pageList[-2].text
return int(pageNum)
def parseHtml(html):
#解析html网页,提取数据
bsObj = BeautifulSoup(html,"html.parser")
bookList = bsObj.find("ul",attrs = {"class":"b_strategy_list"})
books = []
for book in bookList:
link = "https://travel.qunar.com" + book.h2.a["href"]
#print("link:",link)
title = book.h2.a.text
#print("title:", title)
user_info = book.find("p", attrs = {"class":"user_info"})
intro = user_info.find("span", attrs = {"class":"intro"})
user_name = intro.find("span", attrs = {"class":"user_name"}).text
#print("user_name:",user_name)
date = intro.find("span", attrs = {"class":"date"}).text
#print("date:",date)
days = intro.find("span", attrs = {"class":"days"}).text
#print("days:",days)
photoTmp = intro.find("span", attrs = {"class":"photo_nums"})
if(photoTmp):
photo_nums = photoTmp.text
else:
photo_nums = "没有照片"
#print("photo_nums:",photo_nums)
peopleTmp = intro.find("span", attrs = {"class":"people"})
if(peopleTmp):
people = peopleTmp.text
else:
people = ""
#print("people:",people)
tripTmp = intro.find("span", attrs = {"class":"trip"})
if(tripTmp):
trip = tripTmp.text
else:
trip = ""
#print("trip:",trip)
feeTmp = intro.find("span", attrs = {"class":"fee"})
if(feeTmp):
fee = feeTmp.text
else:
fee = ""
#print("fee:",fee)
nums = user_info.find("span", attrs = {"class":"nums"})
icon_view = nums.find("span", attrs = {"class":"icon_view"}).span.text
#print("icon_view:",icon_view)
icon_love = nums.find("span", attrs = {"class":"icon_love"}).span.text
#print("icon_love:",icon_love)
icon_comment = nums.find("span", attrs = {"class":"icon_comment"}).span.text
#print("icon_comment:",icon_comment)
#print("----"*20)
books = [[title,link,user_name,date,days,photo_nums,people,trip,fee,icon_view,icon_love,icon_comment]]
yield books
def saveCsvFile(filename,content):
import pandas as pd
# 保存文件
dataframe = pd.DataFrame(content)
dataframe.to_csv(filename, encoding='utf_8_sig', mode='a', index=False, sep=',', header=False )
def downloadBookInfo(url,fileName):
head = [["标题","链接","作者","出发日期","天数","照片数","人数","玩法","费用","阅读数","点赞数","评论数"]]
saveCsvFile(fileName, head)
html = fetchHotel(url)
pageNum = getPageNum(html)
for page in range(1, pageNum + 1):
print("正在爬取",str(page), "页 .......")
url = "https://travel.qunar.com/travelbook/list/%E4%B8%8A%E6%B5%B7/hot_heat/" + str(page) + ".htm"
html = fetchHotel(url)
for book in parseHtml(html):
saveCsvFile(fileName, book)
url = "https://travel.qunar.com/travelbook/list/上海/hot_heat/1.htm"
fileName = "data.csv"
downloadBookInfo(url,fileName)
print("全部完成!")
整理过程中,我对代码做了一些调整,这里简单说明一下,以免给大家造成困惑。
- fetchUrl 函数中, 去掉了 params 参数,因为参数已经拼接到 url 中了,后续如果要更改筛查条件什么的,直接修改 url 即可,不必动这个函数。
- 增加了一个 getPageNum 函数,用来获取总页数。如果前面有好好跟着分析的话,相信这个函数还是比较容易看得懂的。
- 在 parseHtml 函数中,对于 photo_nums,people,trip,fee 等数据,并没有直接获取他们的 text,而是先判一下是否为空。这是因为网页中,这些数据并不是每篇文章中都会展示的,如果不做判断直接取,会报错。
0x03 数据展示
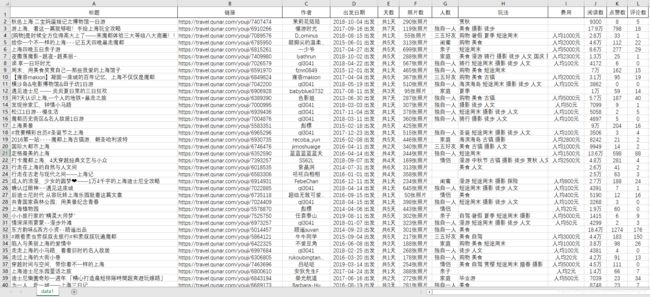
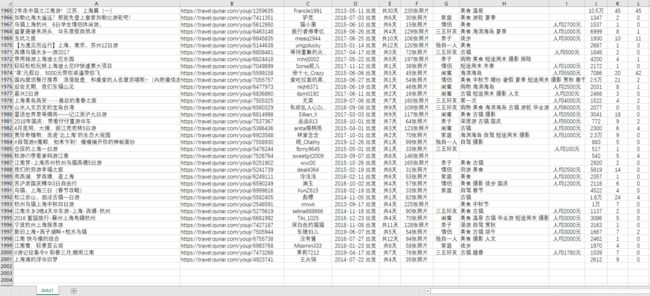
经过一段时间的爬取,整整 200 页,2000 条的数据全部爬取完成。在 Excel 中打开,简单排版一下,如下图所示。
0x04 写在后面的话
在分析网站的时候,我其实分析了更多的内容,包括城市编号,排序方式,以及下面这些参数的编号等,但是想了想还是不写文章里了,一方面我们这个爬虫不需要分析那么深入,另一方面,把人家网站扒的一丝不苟总归是不太礼貌的。大家感兴趣的可以自己去研究研究。

后续的话,削微透露一下,我通过这些文章的链接,将文章内容爬取了下来。
由于是图文,所以我决定用 markdown 格式文本进行保存,近两千篇文章,找一个高颜值的 markdown 编辑器,读起来有种特别的美感。
后面我会写博客介绍如何爬取图文文章保存为markdown,以及其中遇到的问题和解决方法,大家可以期待一下。
如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。
