【NLP CS224N笔记】Lecture 2 - Word Vectors2 and Word Senses
本次梳理基于Datawhale 第12期组队学习 -CS224n-预训练模块
详细课程内容参考(2019)斯坦福CS224n深度学习自然语言处理课程
1. 写在前面
自然语言处理( NLP )是信息时代最重要的技术之一,也是人工智能的重要组成部分。NLP的应用无处不在,因为人们几乎用语言交流一切:网络搜索、广告、电子邮件、客户服务、语言翻译、医疗报告等。近年来,深度学习方法在许多不同的NLP任务中获得了非常高的性能,使用了不需要传统的、任务特定的特征工程的单个端到端神经模型。 而【NLP CS224N】是入门NLP的经典课程, 所以这次借着Datawhale组织的NLP学习的机会学习这门课程, 并从细节层面重新梳理NLP的知识。
今天是该课程的第二篇笔记, 在第一篇Introduction and Word VectorsWord2Vec的基础上又进行了一步, 首先会简单的回顾上一篇里面Word2Vec的工作过程并补充一些训练方面的微观细节,因为Word2Vec只是一种计算词嵌入的一种模式, 实际训练中我们得用它的具体的算法模型, 比如Skip-gram Model(这两者之间的关系给我的感觉就是Word2Vec是理论基础, 而Skip-gram是实践层面), 所以针对Skip-gram Model, 也对微观训练细节进行补充, 然后分析Skip-Model模型的问题并介绍一种叫做负采样的高效训练方法, 而计算词向量并不只是Word2Vec的方法, 这种计算词向量的方法叫做Direct Prediction 模型, 还有一种叫做Count-based模型, 这个在第一节课的大作业中做了一些铺垫, 就是那个共现矩阵的方式, 两者各有优势和不足, 所以后来又提出了一种结合这两种计算词向量的思路就是Glove, 最后会对Glove算法进行详细介绍。 这次的内容会比较多, 并且有大量的数学公式, 所以感觉有压力, 依然是建议先从吴恩达老师的课程学起!
大纲如下:
- 简单Word2Vec的工作过程和细节补充
- Skim-Model 的高效训练方式负采样
- Count-Based 模型
- Glove算法介绍
Ok, let’s go!
2. Word2Vec的工作过程和细节补充
Word2Vec的详细工作过程, 在第一篇文章中已经做了介绍, 这里简单的回顾一下, 首先Word2Vec是一种计算单词词向量的一种方式, 核心思想是预测每个单词和上下文单词之间的关系。具体实现算法有Skip-gram和CBOW两种模型。 具体的流程细节, 是下面的这张图:

下面简单的回顾Word2Vec的计算细节:
给定一个中心词, 其窗口内context出现的概率为:
P ( o ∣ c ) = exp ( u o T v c ) ∑ w ∈ V exp ( u w v c ) P(o \mid c)=\frac{\exp \left(u_{o}^{T} v_{c}\right)}{\sum_{w \in V} \exp \left(u_{w} v_{c}\right)} P(o∣c)=∑w∈Vexp(uwvc)exp(uoTvc)
然后我们的目标是通过极大似然估计的方式最大化整个文本出现的概率:
L ( θ ) = ∏ t = 1 T ∏ − m ≤ j ≤ m , j ≠ 0 P ( w t + j ∣ w t , θ ) L(\theta)=\prod_{t=1}^{T} \prod_{-m \leq j \leq m, j \neq 0} P\left(w_{t+j} \mid w_{t}, \theta\right) L(θ)=t=1∏T−m≤j≤m,j=0∏P(wt+j∣wt,θ)
但是这个目标我们说连乘不好, 所以化简了一下:
J ( θ ) = − 1 T log L ( θ ) = − 1 T ∑ t = 1 T ∑ − m ≤ j ≤ m , j ≠ 0 log P ( w t + j ∣ w t , θ ) J(\theta)=-\frac{1}{T} \log L(\theta)=-\frac{1}{T} \sum_{t=1}^{T} \sum_{-m \leq j \leq m, j \neq 0} \log P\left(w_{t+j} \mid w_{t}, \theta\right) J(θ)=−T1logL(θ)=−T1t=1∑T−m≤j≤m,j=0∑logP(wt+j∣wt,θ)
假设词典中有V个单词, 每个单词词向量长度为d, 对于每一个词, 作为中心词(center)和非中心词(outside)时分别使用v和u两个向量表示。
U V × d ( outside ) = [ u 1 u 2 ⋮ u V ] U_{V \times d}(\text {outside})=\left[\begin{array}{c} u_{1} \\ u_{2} \\ \vdots \\ u_{V} \end{array}\right] UV×d(outside)=⎣⎢⎢⎢⎡u1u2⋮uV⎦⎥⎥⎥⎤
V V × d ( center ) = [ v 1 v 2 ⋮ v V ] V_{V \times d}(\text {center})=\left[\begin{array}{c} v_{1} \\ v_{2} \\ \vdots \\ v_{V} \end{array}\right] VV×d(center)=⎣⎢⎢⎢⎡v1v2⋮vV⎦⎥⎥⎥⎤
这就是我们每个单词的词向量, 每个是有两个词向量, 上一篇文章中,我们是把这两个直接堆叠起来的, 而还可以将两个向量平均作为最终词向量表示。这样每个单词就对应一个词向量了。 而对于每个中心词, 我们会先得到它的词向量表示, 然后通过上下文矩阵得到该词与其他词之间的关系:
D V × 1 = U V × d ⋅ v 4 = [ d 1 d 2 ⋮ d V ] D_{V \times 1}=U_{V \times d} \cdot v_{4}=\left[\begin{array}{c} d_{1} \\ d_{2} \\ \vdots \\ d_{V} \end{array}\right] DV×1=UV×d⋅v4=⎣⎢⎢⎢⎡d1d2⋮dV⎦⎥⎥⎥⎤
然后进一步就可以通过softmax转换成概率:
P V × 1 = softmax ( D V × 1 ) = [ p 1 p 2 ⋮ p V ] P_{V \times 1}=\operatorname{softmax}\left(D_{V \times 1}\right)=\left[\begin{array}{c} p_{1} \\ p_{2} \\ \vdots \\ p_{V} \end{array}\right] PV×1=softmax(DV×1)=⎣⎢⎢⎢⎡p1p2⋮pV⎦⎥⎥⎥⎤
这个就是Word2Vec的计算细节了, 接下来就是根据目标函数进行求导数,然后进行U和V参数的更新了, 从而使词向量模型需对出现在同一个context中的词赋予较大的概率。
但是Word2Vec毕竟只是理论的部分, 真实实现上我们是通过训练模型进行上面过程的计算的, 所以还是要注意一些细节, 比如我们用Skip-gram Model实现的时候, 我们是转换成了一个监督学习的问题, 那么该模型的损失函数就不是单纯的上面那种目标函数了, 得能衡量出模型的预测与真实目标之间的差距, 由于这是一个多分类问题, 所以采用了交叉熵损失函数。 再比如梯度下降的时候, 如果是整个数据集上进行更新参数,那么计算量会很大, 所以会采从数据及中随机抽样部分数据(batch), 在词向量计算中对每一个window数据计算一次更新。再比如高频词(the)引起的问题,通过以上计算过程可以知道,如果两个词出现在一个context的次数越频繁,那么他们的词向量就会越接近,这样一来像the这样的高频词,就会使它前后的词向量高度集中,从而导致一些问题。所以采样的时候得考虑这种情况等等。
所以上面的细节最好也了解一下, 下面就对真实训练情景中的损失函数进行梳理, 也就是交叉熵损失函数。

那么对于这样的损失函数, 我们是怎么求导的呢? 其实和上一篇里面的求导方式基本一致, 只不过这里得加上已知的东西:

这就是真实训练里面的梯度计算过程, 有了梯度, 就可以进行梯度下降更新参数了。当然真实实现里面反向传播不需要自己写。
但是Skip-Gram Model训练词向量的方式有没有问题呢? 其实是有的, 因为我们分析一下输出, 可以看到softmax这个公式,分母是有个求和的,也就是如果有10000个单词的时候,模型最后输出的时候都得考虑进来,10000个单词究竟哪个单词概率最大。如果1000000个单词的话,模型得1000000次加和,这样的计算量太大了,所以就有了一些训练的改进版本, Distributed Representations of Words and Phrases and their Compositionality论文里面提到了两种,一个是Hierarchical softmax classifier, 另一个是负采样的方式。我们重点看看第二种。
3. Skim-Model 的高效训练方式负采样
Negative sampling是另外一种有效的求解embedding matrix EE的方法。它的做法是判断选取的context word和target word是否构成一组正确的context-target对,一般包含一个正样本和k个负样本。例如,“orange”为context word,“juice”为target word,很明显“orange juice”是一组context-target对,为正样本,相应的target label为1。若“orange”为context word不变,target word随机选择“king”、“book”、“the”或者“of”等。这些都不是正确的context-target对,为负样本,相应的target label为0。这就是如何生成训练集的方法。选一个正样本和K个负样本(样本是成对出现的)

Negative sampling的数学模型为:
P ( y = 1 ∣ c , o ) = σ ( u o T ⋅ v c ) P(\boldsymbol{y}=\mathbf{1} | \boldsymbol{c}, \boldsymbol{o})=\sigma\left(u_{o}^{T} \cdot \boldsymbol{v}_{c}\right) P(y=1∣c,o)=σ(uoT⋅vc)
其中,σ表示sigmoid激活函数。很明显,negative sampling某个固定的正样本对应k个负样本,即模型总共包含了k+1个binary classification。对比之前介绍的10000个输出单元的softmax分类,negative sampling转化为k+1个二分类问题,计算量要小很多,大大提高了模型运算速度。
(就是每一次训练,都是K+1个二分类问题, 就看target的那几个是不是我们想要的0或者1,然后用这几个去计算损失更新参数即可)。 负采样的损失函数长这个样子:
J n e g − sample ( v c , o , U ) = − log ( σ ( u o ⊤ v c ) ) − ∑ k = 1 K log ( σ ( − u k ⊤ v c ) ) \boldsymbol{J}_{\mathrm{neg}-\operatorname{sample}}\left(\boldsymbol{v}_{c}, o, \boldsymbol{U}\right)=-\log \left(\sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)\right)-\sum_{k=1}^{K} \log \left(\sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)\right) Jneg−sample(vc,o,U)=−log(σ(uo⊤vc))−k=1∑Klog(σ(−uk⊤vc))
这个损失函数可能看起来比较难理解, 那么稍微改写一下:
J n e g − sample ( v c , o , U ) = − [ log ( σ ( u o ⊤ v c ) ) + ∑ k = 1 K log ( σ ( − u k ⊤ v c ) ) ] \boldsymbol{J}_{\mathrm{neg}-\operatorname{sample}}\left(\boldsymbol{v}_{c}, o, \boldsymbol{U}\right)=-[\log \left(\sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)\right)+\sum_{k=1}^{K} \log \left(\sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)\right)] Jneg−sample(vc,o,U)=−[log(σ(uo⊤vc))+k=1∑Klog(σ(−uk⊤vc))]
我们分析中括号里面那块,理解起来的话,就是我们的输入是选择的中心词,也就是这里的 v c v_{c} vc, 是embedding之后的向量,而输出是正负样本的embedding后的向量。 前面的那部分是正确的上下文词和中心词的关系, u o u_{o} uo就是正样本embedding后的形式,这两个的内积操作其实就是两者的关系程度(内积的几何意义)。 后面的那部分是负样本和中心词的关系,我们希望的是中心词与正样本的关系尽可能的近,也就是前面那部分越大越好,希望负样本与中心词的关系尽可能的小,但是后面发现内积前加了个负号,那就表示后面那部分越大越好。 所以中括号那部分应该越大越好。而前面加了负号, 就是希望损失越小越好。
通过这样的方式, 就可以提高训练的效率, 因为这种就相当于每次训练做了一个K+1次的二分类任务, 而之前那种方式是做了V分类的任务, 而这个V是单词的个数, 往往会上百万。 而这里的K, 如果训练样本小, 取5-20, 训练样本大, 取2-5即可。 所以这个计算量上就容易了很多。 当然,我们也可以看一下这个损失函数下各个参数的导数:

从这个偏导也可以看出, 梯度更新的时候, 负采样的计算参数量要远远小于softmax的。 关于具体实现方式, 可以参考Pytorch入门+实战系列三:Pytorch与词向量
最后提一点,关于如何选择负样本对应的target单词,可以使用随机选择的方法。但论文中提出一个更实用、效果更好的方法,就是根据该词出现的频率进行选择,相应的概率公式为:
P ( w i ) = f ( w i ) 3 4 ∑ j 10000 f ( w j ) 3 4 P\left(w_{i}\right)=\frac{f\left(w_{i}\right)^{\frac{3}{4}}}{\sum_{j}^{10000} f\left(w_{j}\right)^{\frac{3}{4}}} P(wi)=∑j10000f(wj)43f(wi)43
这样貌似可以解决一些高频词引起的问题。
好了,关于direct Prediction模型的理论部分就先整理这么多, 下面就是Count-based Model。
4. Count-Based 模型
这种模型也是学习词向量的一种方式, 这类模型的经典代表就是SVD模型, 就是大作业1里面的思路, 在相似的上下文中我们一般会使用意思相似的单词(同义词),因此,意思相近的单词会通过上下文的方式在一起出现。通过检查这些上下文,我们可以尝试把单词用词向量的方式表示出来,一种简单的方式就是依赖于单词在一起出现的次数, 所以就得到了一种叫做共现矩阵的策略,这是一个基于单词频数的词向量矩阵, 然后再进行SVD分解降维得到每个单词的词向量。
共现矩阵 X X X的产生方式有两种选择:
- word-document co-occurrence matrix: 基本假设是在同一篇文章中出现的单词更有可能相互关联。 假设单词 i i i出现在文章 j j j中, 则矩阵元素 X i j X_{ij} Xij加一, 当处理完所有文章后, 就得到了矩阵 X X X, 大小是 ∣ V ∣ × M |V|\times M ∣V∣×M, ∣ V ∣ |V| ∣V∣表示词汇量, M M M是文章数。
- word-word co-occurrence matrix: 利用某个定长窗口中单词与单词同时出现的次数来得到矩阵 X X X, 这个的大小会是 ∣ V ∣ × ∣ V ∣ |V|\times|V| ∣V∣×∣V∣。 具体详细的在大作业一里面已经说明并实现了这种方式, 这里就不详细说了。 看个例子吧:

这就是共现矩阵了, 当然我们很容易发现, 这种矩阵存在问题,可以看出,随着词汇量的增大,矩阵 X X X的尺度会越来大,为了有效的存储,我们可以对其进行SVD处理:

为了减少尺度同时尽量保存有效信息,可保留对角矩阵的最大的k个值,其余置零,并将酉矩阵的相应的行列保留,其余置零:

这就是经典的SVD算法, 具体实现上可以调用sklearn里面的Truncated SVD包实现降维。
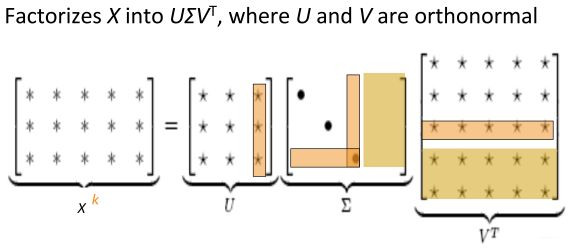
好了, 这就是Count-Based Model了, 下面就对比分析一下direct prediction和Count based这两种方式的优缺点:

Count based模型优点是训练快速,并且有效的利用了统计信息,缺点是对于高频词汇较为偏向,并且仅能概括词组的相关性,而且有的时候产生的word vector对于解释词的含义如word analogy等任务效果不好;Direct Prediction优点是可以概括比相关性更为复杂的信息,进行word analogy等任务时效果较好,缺点是对统计信息利用的不够充分。
所以Manning教授他们想采取一种方法可以结合两者的优势, 并将这种算法命名为GloVe(Global Vectors的缩写),表示他们可以有效的利用全局的统计信息。那么是怎么做的呢?
5. GloVe算法
GloVe的思想是在word-word co-occurrence count的基础上学习到词语背后的含义。 为了更好的描述这个问题, 可以先定义一些符号:
对于共现矩阵 X X X, X i j X_{ij} Xij表示单词 j j j出现在单词 i i i上下文中的次数, 则 X i = ∑ k X i k X_{i}=\sum_{k} X_{i k} Xi=∑kXik,即代表所有单词出现在单词 i i i的上下文中的单词次数。 相当于共现矩阵的一行, 我们用 P i j = P ( j ∣ i ) = X i j X i P_{ij}=P(j|i)=\frac{X_{ij}}{Xi} Pij=P(j∣i)=XiXij来代表单词 j j j出现在单词 i i i上下文中的概率。 这样的感觉:

那么有了这个如何表示词汇的含义呢? 拿PPT里面的例子:

例如, 我们想区分热力学上两种不同的状态ice冰和蒸汽steam, 他们之间的关系可通过与不同的单词 x x x的co-occurrence probability的比值来描述。 例如对于solid固态, 虽然 P ( s o l i d ∣ i c e ) P(solid|ice) P(solid∣ice)与 P ( s o l i d ∣ s t r e a m ) P(solid|stream) P(solid∣stream)本身很小, 不能透露有效的信息, 但是它们的比值 P ( solid ∣ i c e ) P ( solid ∣ steam ) \frac{P(\text {solid} \mid i c e)}{P(\text {solid} \mid \text {steam})} P(solid∣steam)P(solid∣ice)却比较大了, 因为solid更常用来描述ice而不是steam的状态, 所以在ice的上下文中出现的概率较大。 而gas就恰恰相反了, 所以从上面的例子中, 通过比值的方式就可以判断solid和ice相关性大, gas和steam相关性大, water和fashion和这两个中心词基本没啥关系。
所以共现概率比值能比较直观地表达词之间的关系。GloVe试图用有关词向量的函数来表达共现概率比值。 即:
F ( w i , w j , w ~ k ) = P i k P j k F\left(w_{i}, w_{j}, \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}} F(wi,wj,w~k)=PjkPik
其中 w ~ \tilde{w} w~代表了context vector,如上例中的solid,gas,water,fashion等。 w i , w j w_i, w_j wi,wj则是我们要比较的两个词汇, 中心词,如上例中的ice,steam。 下面的目标就是想办法求出左边的 F F F(这个 F F F的求解过程没有严谨的正向推导, 而是往回推的一种思路。 课上老师提到的GloVe论文第一作者Jeffrey Pennington在成为Manning组的PostDoc之前是理论物理的博士,他用了物理学家简化假设做back-of-envelope计算合理推断的习惯)。
F F F的可选的形式过多,我们希望有所限定。首先我们希望的是 F F F能有效的在单词向量空间内表示概率比值,由于向量空间是线性空间, 一个自然的假设是 F F F是关于向量 w j , w i w_j, w_i wj,wi的差的形式, 用向量之差来表达共现概率的比值:
F ( w i − w j , w ~ k ) = P i k P j k F\left(w_{i}-w_{j}, \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}} F(wi−wj,w~k)=PjkPik
等式右边为标量形式,左边如何操作能将矢量转化为标量形式呢?一个自然的选择是矢量的点乘形式:
F ( ( w i − w j ) T w ~ k ) = P i k P j k F\left((w_{i}-w_{j})^T \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}} F((wi−wj)Tw~k)=PjkPik
由于任意一对词共现的对称性, 我们希望下面两个性质可以同时被满足:
- 任意词作为中心词和背景词的词向量应该相等: 对任意词 i i i, w i = w i ~ w_i=\tilde{w_i} wi=wi~
- 词与词之间共现次数矩阵 X X X应该对称: 对任意词 i , j i, j i,j, x i j = x j i x_{ij}=x_{ji} xij=xji
为了满足上面的性质, 一方面令 F ( ( w i − w j ) T w ~ k ) = F ( w i T w k ~ ) F ( w j T w k ~ ) F\left((w_{i}-w_{j})^T \tilde{w}_{k}\right)=\frac{F(w_i^T\tilde{w_k})}{F(w_j^T\tilde{w_k})} F((wi−wj)Tw~k)=F(wjTwk~)F(wiTwk~), 这样能满足对称性, 就得到了 F = e x p F=exp F=exp。 同时与 F ( ( w i − w j ) T w ~ k ) = P i k P j k F\left((w_{i}-w_{j})^T \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}} F((wi−wj)Tw~k)=PjkPik联立会得到 F ( w i T w k ~ ) = P i k = X i k X i = e w i T w k ~ F(w_i^T\tilde{w_k})=P_{ik}=\frac{X_{ik}}{X_i}=e^{w_i^T\tilde{w_k}} F(wiTwk~)=Pik=XiXik=ewiTwk~, 所以有了
w i T w k ~ = l o g ( P i k ) = l o g ( X i k ) − l o g ( X i ) w_i^T\tilde{w_k}=log(P_{ik})=log(X_{ik})-log(X_i) wiTwk~=log(Pik)=log(Xik)−log(Xi)
但是单纯的这个式子会破坏对称性, 因为 l o g ( X i ) log(X_i) log(Xi)的存在, 这个并不依赖 k k k, i 与 k i与k i与k一交换位置这个肯定没法保证等式不变, 所以为了保证平衡性, 把这个替换成了两个偏移项之和 b i + b k b_i+b_k bi+bk, 得到了
w i T w k ~ = l o g ( X i k ) − b i − b k w_i^T\tilde{w_k}=log(X_{ik})-b_i-b_k wiTwk~=log(Xik)−bi−bk
将索引i和k互换,我们可验证对称性的两个性质可以同时被上式满足。
因此,对于任意一对词 i 和 j i和j i和j,用它们词向量表达共现概率比值最终可以被简化为表达它们共现词频的对数:
w i T w k ~ + b i + b k = l o g ( X i k ) w_i^T\tilde{w_k}+b_i+b_k=log(X_{ik}) wiTwk~+bi+bk=log(Xik)
这就类似于一种反推的思想, 要使得 F ( w i , w j , w ~ k ) = P i k P j k F\left(w_{i}, w_{j}, \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}} F(wi,wj,w~k)=PjkPik成立, 需要使得 F ( w i − w j , w ~ k ) = P i k P j k F\left(w_{i}-w_{j}, \tilde{w}_{k}\right)=\frac{P_{i k}}{P_{j k}} F(wi−wj,w~k)=PjkPik成立, 需要使得…, 到了 w i T w k ~ + b i + b k = l o g ( X i k ) w_i^T\tilde{w_k}+b_i+b_k=log(X_{ik}) wiTwk~+bi+bk=log(Xik)。也就是说如果最后的这个等式成立的话, 我们就能用词向量表达共现概率比值。
上式中的共现词频是直接在训练数据上统计得到的,为了学习词向量和相应的偏移项,我们希望上式中的左边与右边越接近越好, 也就是等号尽可能成立, 这才有了PPT里面Glove的损失函数的形式:

另一方面作者注意到模型的一个缺点是对于所有的co-occurence的权重是一样的,即使是那些较少发生的co-occurrence。作者认为这些可能是噪声,所以他加入了前面的 f ( X i j ) f(X_{ij}) f(Xij)项来做weighted least squares regression模型。 这个权重项需要满足下面的条件:
- f ( 0 ) = 0 f(0)=0 f(0)=0, 因为要求 l i m x − > 0 f ( x ) l o g 2 x lim_{x->0}f(x)log^2x limx−>0f(x)log2x是有限的
- 较少发生的co-occurrence所占权重小
- 对于较多发生的co-occurrence, f ( x ) f(x) f(x)也不能过大
作者试验的较好的权重函数形式:

GloVe的优势:

当然, 实际应用中还是Word2Vec用的多一些, 具体任务具体分析吧。对了, 这个的代码实现思路依然是类似于skip gram model那样, 只不过损失函数需要改成上面的这种损失函数。
好了, 到了这里, 基本上把Glove的一些东西交代清楚了, 后面就是分析了一些实验里面的内容了, 具体的看下面的最后一个链接, 这里把结论记一下:
- 关于词向量的维度, 300是一个不错的向量维度
- 不对称上下文(只使用单侧的单词)不是很好,但是这在下游任务重可能不同
- window size 设为 8 对 Glove向量来说比较好
- 训练时间越长越好, 数据集越大越好,并且维基百科数据集比新闻文本数据集要好
- 对于多义的词, 可以先将其上下文聚类, 得到一些清晰的簇,从而将这个常用词分解为多个单词,例如bank_1, bank_2, bank_3
关于更多的内容, 见最后一篇链接吧。
6. 总结一下
这篇文章主要是对词向量求解方式的细节进行了展开, 求解词向量, 大方向上有两种方式, 基于词频和直接预测模型, 后者就是Word2Vec, 所以基于上一篇文章又补充了一些实现层面的细节, 然后就介绍了基于词频的求解词向量的方式, 最后把两者的思路进行组合,得到了GloVe算法, 主要补充了GloVe目标函数的推导过程。
参考:
- cs224n学习笔记L2:word vectors and word senses
- GloVe论文
- CS224N笔记(二):GloVe
- CS224N讲义
- CS224N补充材料
- Glove模型的理解和推导
- 其他参考笔记
- 02 Word Vectors 2 and Word Senses