ElasticSearch教程与实战:从搭建服务到Spring Boot整合
目录
写在前面
Elasticsearch是什么?可以解决什么问题?
关于Elasticsearch版本的选择
Elasticsearch的几个基本概念
索引(index)
类型(type)
文档(document)
安装之前的准备工作
开始安装Elasticsearch
配置IK中文分词器
启动、停止Elasticsearch服务
IK分词器测试
Spring Boot整合Elasticsearch
新建ES文档实体类
新建ES操作接口
新建服务层组件
新建控制层组件
配置ES连接信息
启动项目,测试
整合优化:高亮显示关键词
总结
写在前面
因为我之前用过Solr全文检索,深知Solr的局限性以及在分布式搜索引擎方面的短板,所以Elasticsearch是我老早就想学习并应用的一门技术,只不过一直都没有什么机会。直到前一段时间,公司的一个产品需要用到全文检索,上级也把这个任务交给了我,所以学习了这一套技术。所以今天,我想记录一下这过程中的各种坑,以及整合到实际项目中的案例,希望能够帮助后来者。
本次文章的示例源码已经上传到百度网盘,下载地址(永久有效):
https://pan.baidu.com/s/1wsC8H_infIlNecos5Hxzuw
另外,以下篇幅中,Elasticsearch全部简写为ES。
Elasticsearch是什么?可以解决什么问题?
ES是什么,百度百科比我解释的要专业。至于它可以做什么,按照我的理解就是一句话:实现“智能化”的搜索、用最大的可能去理解意图。
首先,ES作为一个搜索引擎,再加上它天生具有的对分布式架构的支持,对数据的处理速度非常快,经常用来缓解数据库的压力;其次,它是一个全文检索引擎,会根据你输入的字符串,尽可能的去匹配你想要的信息,就像百度一样,无论你给的关键字多么模糊,只要是沾一点边,那么就会把数据返回给你。
比如这样的一个查询字符串:“叶问的咏春拳游戏”,如果拿到数据库去匹配对应的标题,先不说模糊查询的性能问题,首先模糊查询可以实现这样的功能吗?它不能!但是ES呢?请看效果图:

这就是全文检索+分词器的效果,不仅快,而且还能达到很好的搜索效果。
关于Elasticsearch版本的选择
先贴出来ES的官方文档地址:
https://www.elastic.co/guide/en/elasticsearch/reference/7.x/elasticsearch-intro.html
ES的版本最近比较活跃,从官方文档可以看出来,版本之间的相隔时间并不长。但是我想说,并不是版本越高越好,笔者就在过程中走过版本的坑。相信大家可能也遇到过这种情况:自己在网上搜了一篇资料,明明是按照过程来的,为什么资料上就能成功,我的就会报错?这就是版本的问题,不同的版本有不同的特性,有不同的要求,甚至连命令都不一样。
由于ES的版本比较多,这里就说一下比较有代表性的6.x之前、6.x-7.x、7.x之后。
在6.x之前的版本中,一个索引库可以存在多个type(这个概念先不用管,下文会解释),放到MySQL里讲就是“一个数据库可以建多张表”,而且6.x之前的版本,集成到Spring Boot之后,写入数据时如果要指定文档的ID,只能是数字,是字符串就报错(除非不指定,采用ES默认生成的ID,但是ES默认生成的ID也是字符串,我也很懵逼)。
从6.x开始,每个索引库只可以创建一个type,拿MySQL来比喻就是“一个数据库只能创建一张表”,我也不知道ES为啥要这样做,可能是跟集群环境下对数据的分片有关系吧,但是老子是真的不知道它到底优化到哪了……但是好在ES在搜索数据的时候,可以跨索引库、跨type搜索,用MySQL来说就是可以一块查询n个数据库中的n张表。
到了7.x之后的版本,ES开始自带JDK,就好像Spring Boot自己内置了一个Tomcat一样。7.x版本它自己还集成了好多东西,整合到咱自己的项目中时会有各种冲突,而且它的一些API参数格式也发生了变化(指的是通过REST API创建索引、映射、type时的JSON请求体参数)。
综上,大家根据自己的实际情况去选择对应的版本,此处笔者选择6.4.2版本。
Elasticsearch的几个基本概念
因为此篇文章以实战应用为主,并不会大篇幅的解释什么是倒排序、ES是怎样实现数据分片的、IK分词器的工作原理,否则的话篇幅实在太长了,所以在开始安装之前,我们先说一下ES的3个基本概念,会有助于下面的学习。
索引(index)
按照官方文档的说法,索引是具有相同结构的文档集合。例如,可以有一个客户信息的索引,包括一个产品目录的索引,一个订单数据的索引。我更喜欢叫它为索引库,因为它的概念就相当于MySQL中的数据库。
类型(type)
文档里的解锁是:在索引中,可以定义一个或多个类型(6.x版本开始每个index只允许有一个type),类型是索引的逻辑分区。在一般情况下,一种类型被定义为具有一组公共字段的文档。说白了,就是MySQL中的表。
文档(document)
文档是存储在ElasticSearch中的一个JSON格式的字符串。它就像在关系数据库中表的一行。每个存储在索引中的一个文档都有一个类型和一个ID,每个文档都是一个JSON对象,存储了零个或者多个字段。
综上所述,笔者做了一幅图来解释它们的关系:
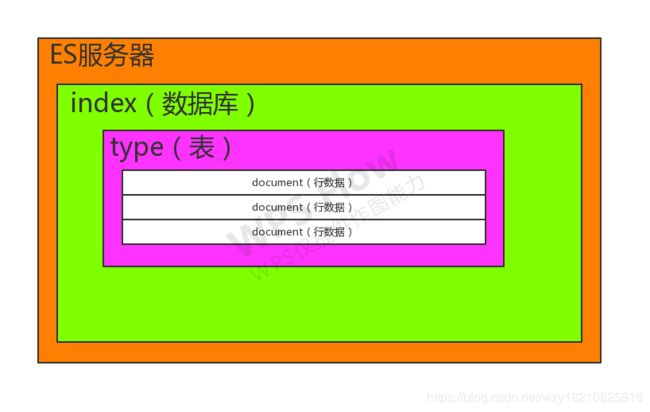
ES还有几个概念,比如分片、映射、复制、主分片、副本分片、路由……这些往往都是和分布式相关的,而且ES都已经为我们提供很好的实现了,只是为了让我们学习一下它的工作原理,所以不花费大量的篇幅在这里,关于更多概念的学习大家可以去看官方文档,我们还有很多干货要讲,相信大家也都希望先接触干货,上来就学原理,怎么会有兴趣?
安装之前的准备工作
在安装ES之前,你都需要做哪些事情?
第一,准备一台Linux的虚拟机;因为我们的生产环境大多以Linux作为服务器,所以我们也安装Linux环境来搭建ES。
第二,在Linux上安装一个JDK,版本要1.8以上。
第三,确保你的虚拟机可以连接网络,因为我们要下载ES的Linux解压包。
第四,除了root用户外,新建一个普通用户,笔者这里就新建一个名叫elsearch的用户;因为出于安全考虑,ES是不允许以root用户的身份启动服务的。
开始安装Elasticsearch
安装有两种方式:要么直接在Linux虚拟机上安装,要么先下载到Windows上,然后通过XShell这种工具拉到虚拟机上,反正最后把压缩包放到你的虚拟机上就行,然后找一个目录解压出来。
通过XShell的方式就不说了,通过命令行直接安装的命令:
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.2-linux-x86_64.tar.gz注意版本号是可以切换的,上面的脚本是我从官方文档拉下来的。
下载好之后,找一个规则的文件夹,解压出来:
tar -zvxf elasticsearch-6.4.2-linux-x86_64.tar.gz
然后我们在此目录下新建一个data文件夹,用于存放ES数据:
然后我们进入config文件夹,编辑elasticsearch.yml:
#集群名称,同一内网下此属性相同的ES服务,会自动组成一个集群
cluster.name: my-application
#节点名称,在某个集群中必须是唯一的,此处我们只有一个节点
node.name: node-1
#节点备注
node.attr.rack: This is a node for ES
#数据文件存放的路径
path.data: /home/elsearch/elasticsearch-6.4.2/data
#日志文件存放的路径
path.logs: /home/elsearch/elasticsearch-6.4.2/logs
#host地址,写虚拟机的IP地址
network.host: 192.168.241.132
#与外部通信的http端口
http.port: 9200配置IK中文分词器
IK分词器是专门为中文搜索而产生的,它会根据汉语的习惯进行分词,达到更好的汉语搜索效果,而不是像ES默认的中文分词那样把字符串拆成一个一个的汉字。
在启动之前,我们先配置IK分词器,一步到位。
首先我们需要去git上下载IK分词器的解压包,这个解压包是.zip的,所以必须需要我们先下载到Windows上,解压出来再传给我们的虚拟机。注意,IK分词器的版本必须和ES的版本一致,这里我们需要下载IK-6.4.2版本。
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v6.4.2
解压出来之后,我们在ES安装目录下的plugins文件夹下,新建一个名叫ik的文件夹,把压缩包里的文件传到ik文件夹下:

然后就OK了,待会等ES服务跑起来之后,我们再测试。
启动、停止Elasticsearch服务
在启动之前,需要注意几点:
第一:不可以root用户启动,需要新建elsearch用户;
第二:需要把ES安装目录的权限分配给这个elsearch用户;
第三:需要修改系统可打开的最大文件数和最大线程数;
第四:elsearch用户拥有的内存权限需要调整,至少262144。
所以我们先更改/etc/security文件夹下的limits.conf文件,加上以下四行配置:
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096然后我们再编辑/etc文件夹下的 sysctl.conf文件,在最后追加一行:
vm.max_map_count=262144然后我们以root身份,为我们的用户赋予文件夹权限(我的叫elsearch,你们同理):
chown -R elsearch:elsearch /home/elsearch/elasticsearch-6.4.2/然后我们切回elsearch用户,进入到ES安装目录下的bin目录,执行脚本:
./elasticsearch打印一堆日志之后,你会看到启动成功的信息:
把防火墙关了,9200端口放开,用我们的Postman访问:虚拟机IP:9200,就会看到:
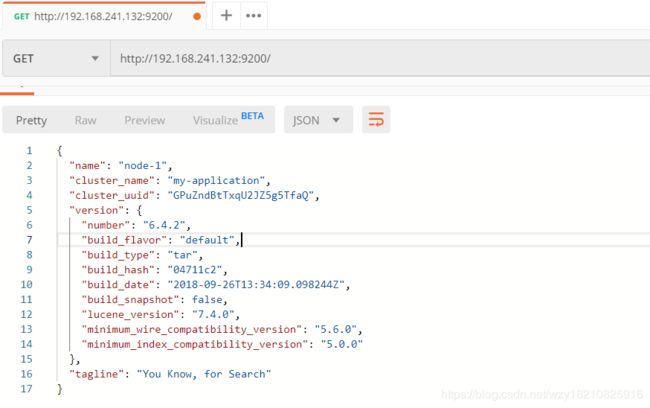
至此,ES服务就已经搭建成功了。
IK分词器测试
ES有很多API,让我们调用,虽然我们真正在项目中都是通过SDK调用而不是REST API,但是这些API可以让我们快速上手学习它。
由于篇幅原因,我们这里只测试分词器,那些API我们不在这里书写了,那些API我一个一个的从官网复制粘贴到这里,真的没啥意思,主要是怎样真正的整合到项目中去才是重点,稍后会带大家进行实战,有兴趣的话大家可以去看官方文档,不懂的地方可以给我留言或评论。
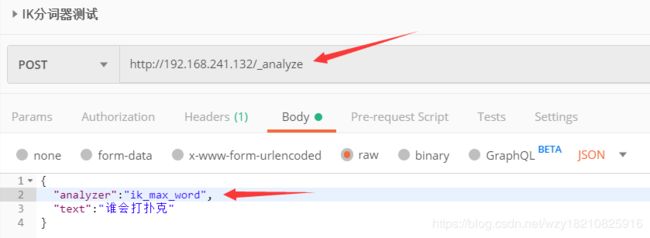
上面的路径是死的,参数 是一个JSON,第一个参数是我们要采用的分词器模式,测试IK分词器的话有两个模式:
ik_max_word和ik_smart,前者的粒度更细,后者的粒度相对粗一点。
分词效果:

Spring Boot整合Elasticsearch
在我们搭建好了ES服务之后,现在就应用到我们的项目中。
笔者在这里的案例是基于Spring Boot的,不懂的可以参考我上一篇文章,去创建Spring Boot项目,或者SSM也一样,主要是操作ES的相关代码要弄清楚。
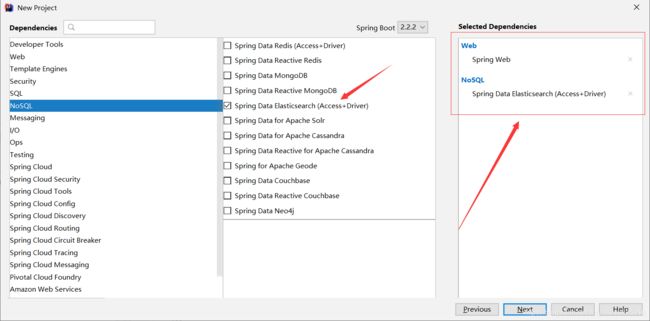
创建项目的时候别忘了选择ES依赖和Web依赖,我们只用这两个就好了:
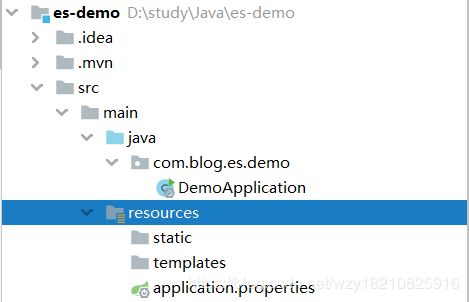
最终的项目结构:
注意:笔者是基于IDEA开发,用到了Lombok插件,需要在pom文件里添加如下依赖:
org.projectlombok
lombok
1.18.6
另外,还需要在IDEA里安装Lombok组件,在File-Settings-Plugins里搜索安装即可。
假设我们现在要做一个新闻搜索的业务。
新建ES文档实体类
package com.blog.es.demo.entity;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
/**
*
* 新闻实体类
*
*
* @author 秋枫艳梦
* @date 2020-01-11
* */
@Data
@Document(indexName = "blog-demo" , type = "news" , shards=5)
public class NewsEntity {
//在ES中的唯一ID,此处我们用一个uuid
@Id
private String id;
//新闻标题
@Field(index = true , type = FieldType.Text , analyzer = "ik_max_word" , searchAnalyzer = "ik_smart")
private String title;
//新闻内容
@Field(index = false , type = FieldType.Text)
private String content;
//创建时间
@Field(index = false , type = FieldType.Long)
private Long date;
}
以上主要牵扯到了三个注解(@Data就不说了):
@Document:说明这个实体类是一个可写入到ES的文档对象,indexName属性表示索引库的名字,可理解为数据库名;type属性表示类型,可理解为表名;shards属性是数据的分片数量。
@Id:准确的说这不是ES中的注解,是spring-data中的注解,说明此字段是唯一的ID。
@Field:字段注解,它的功能主要是设置字段的类型、要不要被索引、如何分词等等。index属性表示是否对此字段进行索引,由于我们只根据新闻标题搜索,所以只索引了title字段;type属性表示此字段在ES中的数据类型,常用的有text、long、integer等等;analyzer表示存储到ES中时采用的分词策略,此处我们按照较细的粒度进行分词;searchAnalyzer表示在搜索时采用的分词策略,我们此处设置为稍微粗一点的粒度。
新建ES操作接口
package com.blog.es.demo.repository;
import com.blog.es.demo.entity.NewsEntity;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
/**
*
* 封装了对ES的操作的接口,我们只需要继承ElasticsearchRepository,
* 第一个泛型参数指定为我们的文档实体,此处即NewsEntity,第二个泛型
* 参数指定我们的实体中的id类型,我们这里即为String.
*
* 在实际开发中,往往只用到此接口的save方法,用于向ES写入数据,其他的
* 操作我们用更好的ElasticsearchTemplate
*
*
* @author 秋枫艳梦
* @date 2020-01-11
* */
public interface NewsRepository extends ElasticsearchRepository {
}
新建服务层组件
在新建服务层组件之前,我们为了规范,先写一个统一的返回格式类:
package com.blog.es.demo.back;
import lombok.*;
import lombok.experimental.Accessors;
import java.io.Serializable;
/**
*
* 统一返回数据
*
*
* @author 秋枫艳梦
* @date 2020-01-11
* */
@Builder
@ToString
@Accessors(chain = true)
@AllArgsConstructor
public class Back implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 运行成功
*/
final String RUN_SUCCESS = "0";
/**
* 运行失败
*/
final String RUN_ERROR = "1";
/**
* 业务失败
*/
final Boolean BACK_ERROR = false;
/**
* 业务成功
*/
final Boolean BACK_SUCCESS = true;
@Getter
@Setter
private String code = RUN_SUCCESS;
@Getter
@Setter
private String msg = "success";
@Getter
@Setter
private Boolean state = BACK_SUCCESS;
@Getter
@Setter
private Long count = null;
@Getter
@Setter
private T data;
public Back() {
super();
}
public Back(T data) {
super();
this.data = data;
}
public Back error(String msg) {
this.state = BACK_ERROR;
this.msg = msg;
return this;
}
public Back msg(String msg) {
this.msg = msg;
return this;
}
}
然后写我们的服务层组件,代码如下:
package com.blog.es.demo.service;
import com.blog.es.demo.back.Back;
import com.blog.es.demo.entity.NewsEntity;
import com.blog.es.demo.repository.NewsRepository;
import lombok.AllArgsConstructor;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.SearchQuery;
import org.springframework.stereotype.Service;
/**
*
* 新闻模块,服务层组件
*
*
* @author 秋枫艳梦
* @date 2020-01-11
* */
@Service
@AllArgsConstructor
public class NewsService {
//一些操作接口
private NewsRepository repository;
//Spring提供的更牛逼的模板,可以满足我们大部分的要求
private ElasticsearchTemplate template;
/**
* 新增或更新数据,如果传入的实体有ID属性,则为更新,否则是插入
* @param entity 数据实体
* @return 返回信息
* */
public Back save (NewsEntity entity) {
//不管是新增还是更新,时间戳都设置为当前时间戳
entity.setDate(System.currentTimeMillis());
repository.save(entity);
return new Back().msg("写入成功");
}
/**
* 删除数据
* @param id ID
* @return 返回信息
* */
public Back delete (String id) {
//从索引库blog-demo中的news,删除某ID的数据
template.delete("blog-demo" , "news" , id);
//刷新此索引库的数据,防止延迟
template.refresh("blog-demo");
return new Back().msg("删除成功");
}
/**
* 搜索数据
* @param id ID
* @return 返回信息
* */
public Back search (String title , int page , int limit) {
try {
//设置根据文档中的title字段进行模糊搜索
QueryBuilder queryBuilder = QueryBuilders.matchQuery("title" , title);
//设置分页条件
Pageable pageable = PageRequest.of(page - 1 , limit);
//组装搜索条件
SearchQuery query = new NativeSearchQueryBuilder()
//查询条件
.withQuery(queryBuilder)
//分页条件
.withPageable(pageable)
//按时间倒序
.withSort(SortBuilders.fieldSort("date").order(SortOrder.DESC))
//查询哪些索引库,多个索引库可用逗号分开
.withIndices("blog-demo")
//查询哪些索引库的哪些type,多个type用逗号分开
.withTypes("news")
.build();
//queryForList方法,第一个参数是我们的搜索条件,第二个参数是用哪个类接收返回的数据,这里我们就用实体接收
//但是不一定非得是实体,任何类都行,只要字段名和ES文档数据里的字段名有一致的,就会封装上值,否则为null
return new Back(template.queryForList(query , NewsEntity.class));
}catch (Exception e) {
//如果ES中的所有分片都没有数据,会报一个错,需要处理一下
return new Back().error("系统暂无数据");
}
}
}
新建控制层组件
package com.blog.es.demo.controller;
import com.blog.es.demo.back.Back;
import com.blog.es.demo.entity.NewsEntity;
import com.blog.es.demo.service.NewsService;
import lombok.AllArgsConstructor;
import org.springframework.web.bind.annotation.*;
/**
*
* 新闻模块,控制器
*
*
* @author 秋枫艳梦
* @date 2020-01-11
* */
@RestController
@RequestMapping(value = "/news")
@AllArgsConstructor
public class NewsController {
//装配服务层组件
private NewsService service;
/**
* 保存
* */
@PostMapping(value = "/save")
public Back save (@RequestBody NewsEntity entity) {
return service.save(entity);
}
/**
* 删除
* */
@DeleteMapping(value = "/del/{id}")
public Back delete (@PathVariable String id) {
return service.delete(id);
}
/**
* 搜索
* */
@GetMapping(value = "/search")
public Back search (String title , int page , int limit) {
return service.search(title, page, limit);
}
}
配置ES连接信息
在application.properties配置文件添加如下代码:
# 集群名称
spring.data.elasticsearch.cluster-name = my-application
# ES地址,注意这里是9300,而不是http的9200
spring.data.elasticsearch.cluster-nodes = 192.168.241.132:9300
启动项目,测试
在启动之前,有一个坑需要避让一下,需要在启动类的main()方法中加上如下代码:
System.setProperty("es.set.netty.runtime.available.processors", "false");而且要加在run()方法之前:
public static void main(String[] args) {
System.setProperty("es.set.netty.runtime.available.processors", "false");
SpringApplication.run(DemoApplication.class, args);
}启动项目,用Postman访问我们的后端API接口。
一开始我们没有数据:

新增一条:

然后我们再次查询:
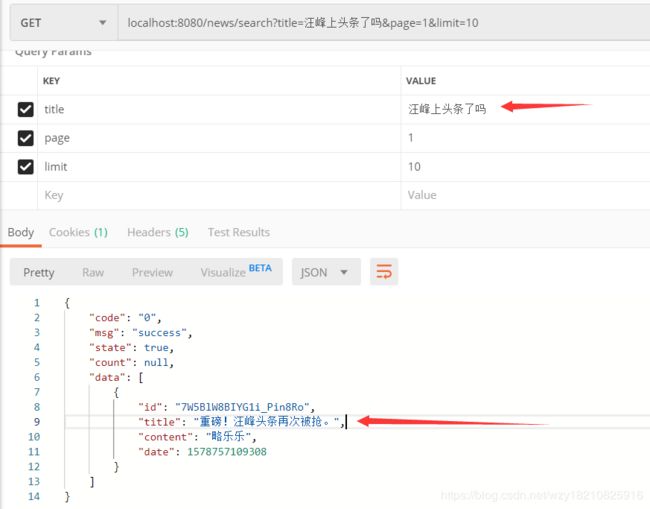
再写一条其他的数据:

继续查询:

更新数据:

再次查询:

删除数据:

再次搜索,数据已经不在了:
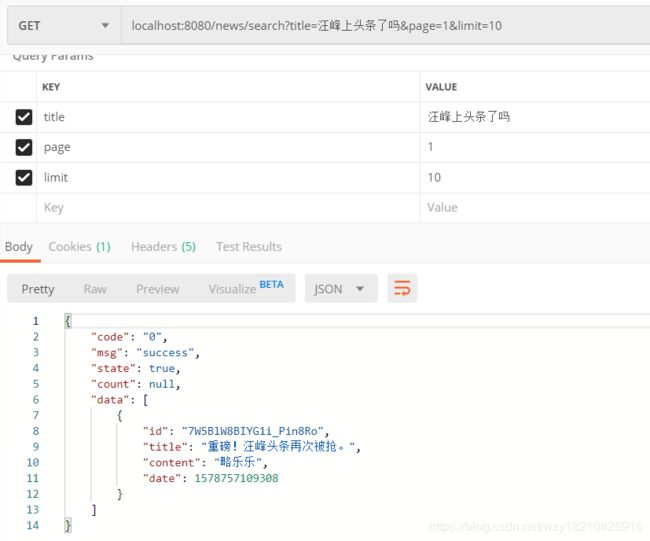
整合优化:高亮显示关键词
ES还支持高亮功能,但是很不幸,在好多版本中,Spring Boot集成的时候设置高亮并不好用,没有效果,需要我们自己处理一下。
先在pom文件引入如下依赖:
commons-beanutils
commons-beanutils
1.9.3
然后把这篇代码放到你的项目里,这一篇代码MyResultMapper出自于:https://blog.csdn.net/wenguanjun/article/details/86687690
/*
* Copyright 2014-2019 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.example.elasticsearch.springbootelasticsearch.repository;
import com.fasterxml.jackson.core.JsonEncoding;
import com.fasterxml.jackson.core.JsonFactory;
import com.fasterxml.jackson.core.JsonGenerator;
import org.apache.commons.beanutils.PropertyUtils;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.get.MultiGetItemResponse;
import org.elasticsearch.action.get.MultiGetResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.common.document.DocumentField;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.ElasticsearchException;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.ScriptedField;
import org.springframework.data.elasticsearch.core.AbstractResultMapper;
import org.springframework.data.elasticsearch.core.DefaultEntityMapper;
import org.springframework.data.elasticsearch.core.EntityMapper;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.aggregation.impl.AggregatedPageImpl;
import org.springframework.data.elasticsearch.core.mapping.ElasticsearchPersistentEntity;
import org.springframework.data.elasticsearch.core.mapping.ElasticsearchPersistentProperty;
import org.springframework.data.elasticsearch.core.mapping.SimpleElasticsearchMappingContext;
import org.springframework.data.mapping.context.MappingContext;
import org.springframework.stereotype.Component;
import org.springframework.util.Assert;
import org.springframework.util.StringUtils;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.nio.charset.Charset;
import java.util.*;
/**
* @author Artur Konczak
* @author Petar Tahchiev
* @author Young Gu
* @author Oliver Gierke
* @author Chris White
* @author Mark Paluch
* @author Ilkang Na
* @author Sascha Woo
* @author 王向东
*/
@Component
public class MyResultMapper extends AbstractResultMapper {
private final MappingContext, ElasticsearchPersistentProperty> mappingContext;
public MyResultMapper() {
this(new SimpleElasticsearchMappingContext());
}
public MyResultMapper(MappingContext, ElasticsearchPersistentProperty> mappingContext) {
super(new DefaultEntityMapper(mappingContext));
Assert.notNull(mappingContext, "MappingContext must not be null!");
this.mappingContext = mappingContext;
}
public MyResultMapper(EntityMapper entityMapper) {
this(new SimpleElasticsearchMappingContext(), entityMapper);
}
public MyResultMapper(
MappingContext, ElasticsearchPersistentProperty> mappingContext,
EntityMapper entityMapper) {
super(entityMapper);
Assert.notNull(mappingContext, "MappingContext must not be null!");
this.mappingContext = mappingContext;
}
@Override
public AggregatedPage mapResults(SearchResponse response, Class clazz, Pageable pageable) {
long totalHits = response.getHits().getTotalHits();
float maxScore = response.getHits().getMaxScore();
List results = new ArrayList<>();
for (SearchHit hit : response.getHits()) {
if (hit != null) {
T result = null;
if (!StringUtils.isEmpty(hit.getSourceAsString())) {
result = mapEntity(hit.getSourceAsString(), clazz);
} else {
result = mapEntity(hit.getFields().values(), clazz);
}
setPersistentEntityId(result, hit.getId(), clazz);
setPersistentEntityVersion(result, hit.getVersion(), clazz);
setPersistentEntityScore(result, hit.getScore(), clazz);
populateScriptFields(result, hit);
results.add(result);
}
}
return new AggregatedPageImpl(results, pageable, totalHits, response.getAggregations(), response.getScrollId(),
maxScore);
}
private String concat(Text[] texts) {
StringBuilder sb = new StringBuilder();
for (Text text : texts) {
sb.append(text.toString());
}
return sb.toString();
}
private void populateScriptFields(T result, SearchHit hit) {
if (hit.getFields() != null && !hit.getFields().isEmpty() && result != null) {
for (java.lang.reflect.Field field : result.getClass().getDeclaredFields()) {
ScriptedField scriptedField = field.getAnnotation(ScriptedField.class);
if (scriptedField != null) {
String name = scriptedField.name().isEmpty() ? field.getName() : scriptedField.name();
DocumentField searchHitField = hit.getFields().get(name);
if (searchHitField != null) {
field.setAccessible(true);
try {
field.set(result, searchHitField.getValue());
} catch (IllegalArgumentException e) {
throw new ElasticsearchException(
"failed to set scripted field: " + name + " with value: " + searchHitField.getValue(), e);
} catch (IllegalAccessException e) {
throw new ElasticsearchException("failed to access scripted field: " + name, e);
}
}
}
}
}
for (HighlightField field : hit.getHighlightFields().values()) {
try {
PropertyUtils.setProperty(result, field.getName(), concat(field.fragments()));
} catch (InvocationTargetException | IllegalAccessException | NoSuchMethodException e) {
throw new ElasticsearchException("failed to set highlighted value for field: " + field.getName()
+ " with value: " + Arrays.toString(field.getFragments()), e);
}
}
}
private T mapEntity(Collection values, Class clazz) {
return mapEntity(buildJSONFromFields(values), clazz);
}
private String buildJSONFromFields(Collection values) {
JsonFactory nodeFactory = new JsonFactory();
try {
ByteArrayOutputStream stream = new ByteArrayOutputStream();
JsonGenerator generator = nodeFactory.createGenerator(stream, JsonEncoding.UTF8);
generator.writeStartObject();
for (DocumentField value : values) {
if (value.getValues().size() > 1) {
generator.writeArrayFieldStart(value.getName());
for (Object val : value.getValues()) {
generator.writeObject(val);
}
generator.writeEndArray();
} else {
generator.writeObjectField(value.getName(), value.getValue());
}
}
generator.writeEndObject();
generator.flush();
return new String(stream.toByteArray(), Charset.forName("UTF-8"));
} catch (IOException e) {
return null;
}
}
@Override
public T mapResult(GetResponse response, Class clazz) {
T result = mapEntity(response.getSourceAsString(), clazz);
if (result != null) {
setPersistentEntityId(result, response.getId(), clazz);
setPersistentEntityVersion(result, response.getVersion(), clazz);
}
return result;
}
@Override
public LinkedList mapResults(MultiGetResponse responses, Class clazz) {
LinkedList list = new LinkedList<>();
for (MultiGetItemResponse response : responses.getResponses()) {
if (!response.isFailed() && response.getResponse().isExists()) {
T result = mapEntity(response.getResponse().getSourceAsString(), clazz);
setPersistentEntityId(result, response.getResponse().getId(), clazz);
setPersistentEntityVersion(result, response.getResponse().getVersion(), clazz);
list.add(result);
}
}
return list;
}
private void setPersistentEntityId(T result, String id, Class clazz) {
if (clazz.isAnnotationPresent(Document.class)) {
ElasticsearchPersistentEntity persistentEntity = mappingContext.getRequiredPersistentEntity(clazz);
ElasticsearchPersistentProperty idProperty = persistentEntity.getIdProperty();
// Only deal with String because ES generated Ids are strings !
if (idProperty != null && idProperty.getType().isAssignableFrom(String.class)) {
persistentEntity.getPropertyAccessor(result).setProperty(idProperty, id);
}
}
}
private void setPersistentEntityVersion(T result, long version, Class clazz) {
if (clazz.isAnnotationPresent(Document.class)) {
ElasticsearchPersistentEntity persistentEntity = mappingContext.getPersistentEntity(clazz);
ElasticsearchPersistentProperty versionProperty = persistentEntity.getVersionProperty();
// Only deal with Long because ES versions are longs !
if (versionProperty != null && versionProperty.getType().isAssignableFrom(Long.class)) {
// check that a version was actually returned in the response, -1 would indicate that
// a search didn't request the version ids in the response, which would be an issue
Assert.isTrue(version != -1, "Version in response is -1");
persistentEntity.getPropertyAccessor(result).setProperty(versionProperty, version);
}
}
}
private void setPersistentEntityScore(T result, float score, Class clazz) {
if (clazz.isAnnotationPresent(Document.class)) {
ElasticsearchPersistentEntity entity = mappingContext.getRequiredPersistentEntity(clazz);
if (!entity.hasScoreProperty()) {
return;
}
entity.getPropertyAccessor(result) //
.setProperty(entity.getScoreProperty(), score);
}
}
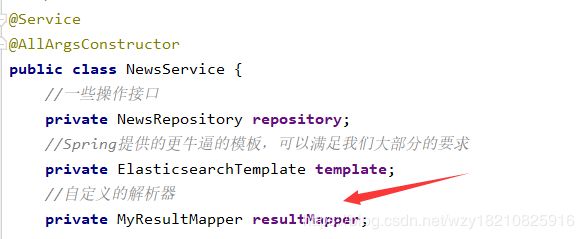
} 然后把MyResultMapper作为组件,写到我们的service里:
然后优化我们的搜索方法:
/**
* 搜索数据
* @param id ID
* @return 返回信息
* */
public Back search (String title , int page , int limit) {
//设置根据文档中的title字段进行模糊搜索
QueryBuilder queryBuilder = QueryBuilders.matchQuery("title" , title);
//设置分页条件
Pageable pageable = PageRequest.of(page - 1 , limit);
//高亮显示的前缀、后缀
String preTag = "";
String postTag = "";
//组装搜索条件
SearchQuery query = new NativeSearchQueryBuilder()
//查询条件
.withQuery(queryBuilder)
//分页条件
.withPageable(pageable)
//按时间倒序
.withSort(SortBuilders.fieldSort("date").order(SortOrder.DESC))
//查询哪些索引库,多个索引库可用逗号分开
.withIndices("blog-demo")
//查询哪些索引库的哪些type,多个type用逗号分开
.withTypes("news")
//设置高亮字段
.withHighlightFields(new HighlightBuilder.Field("title").preTags(preTag).postTags(postTag))
.build();
//queryForList方法,第一个参数是我们的搜索条件,第二个参数是用哪个类接收返回的数据,这里我们就用实体接收
//但是不一定非得是实体,任何类都行,只要字段名和ES文档数据里的字段名有一致的,就会封装上值,否则为null
//return new Back(template.queryForList(query , NewsEntity.class));
//高亮查询必须是queryForPage方法,因为queryForList方法的入参没有SearchResultMapper解析器
return new Back(template.queryForPage(query , NewsEntity.class , resultMapper));
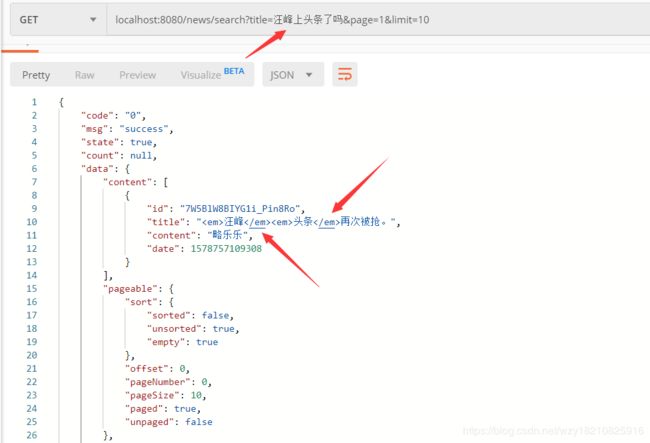
}然后重启项目,再次搜索,由于我们调用的是queryForPage,所以返回的结构也有变化,可以看到匹配上的关键字已经按照我们配置的em标签进行高亮了:
总结
不多说了,Elasticsearch牛逼!!!
从晚上8点半写到现在凌晨12点,睡觉!如果有问题,可以在下方评论,或者给我留言。