数据挖掘RapidMiner工具使用----解析客户流失模版CHURN MODELING
在电信企业面向市场、面向国内外众多的竞争者、努力创造更高价值的同时,客户流失的不断增加,客户平均生命周期的不断缩短严重影响了电信企业的发展。那么,在激烈的市场竞争和不断变化的市场需求面前,如何最大程度的降低客户的流失率呢?常用的方法之一就是利用数据挖掘技术。
数据挖掘技术是目前数据仓库领域最强大的数据分析手段。它的分析方法是利用已知的数据通过建立数学模型的方法找出隐含的业务规则,在很多行业已经具有成功的应用。在电信行业的应用领域主要有客户关系管理,客户欺诈分析,客户流失分析,客户消费模式分析,市场推广分析等。
在客户流失分析系统中,如何应用数据挖掘技术?主要方式是根据以前拥有的客户流失数据建立客户属性、服务属性和客户消费数据与客户流失可能性关联的数学模型,找出客户属性、服务属性和客户消费数据与客户流失的最终状态的关系,并给出明确的数学公式。只要知道客户属性、服务属性和客户消费数据,我们就可以计算出客户流失的可能性。市场/销售部门可以根据得到的数模型随时监控客户流失的可能性。如果客户流失的可能性过高,高于事先划定的一个限度,就可以通过多种促销手段提高客户的忠诚度,防止客户流失的发生,从而可以大大降低客户的流失率。基于严格数学计算的数据挖掘技术能够彻底改变以往电信企业在成功获得客户以后无法监控客户的流失,无法实现客户关怀的状况,把基于科学决策的客户关系管理全面引入到电信企业的市场/销售工作中来。
挖掘过程
通常一个完整的数据挖掘过程由业务问题定义,数据选择,数据清洗和预处理,模型选择与预建立,模型建立与调整,模型的评估与检验,模型解释与应用等多个步骤组成。这里我们以个人客户流失为例说明各个步骤的功能。
1. 业务问题的定义
业务问题的定义要求非常明确。任何不明确的定义都会严重影响模型的准确和应用时的效果。例如:在客户流失分析系统中,需要明确客户流失的定义。在客户流失分析中,主要有两个核心的变量:1.财务原因/非财务原因;2.主动流失/被动流失。客户的流失类别根据这两个核心变量可以分为四种。其中自愿的、非财务原因的流失客户往往是高价值的、稳定的客户。他们会正常支付自己的服务费用,并对市场活动有所响应。所以这种客户才是我们真正想保持的客户。而真正在分析客户流失的状况时,我们还必须区分公司客户与个人客户,不同服务的贡献率,或者是不同客户消费水平流失标准的不同。举例来说,对于用一种新服务替代原有服务的客户,是否作为流失客户?又或者,平均月消费额为2000元左右的客户,当连续几个月消费额降低到500元以下,我们就可以认为客户发生流失了,而这个流失标准就不能适用于原本平均月消费额就为500元左右的客户。实际上,在国外成熟的电信行业客户流失分析系统中,经常是根据相对指标判别客户流失。市场调查表明,通常大众的个人通信费用约占总收入的1%-3%,当客户的个人通信费用降低到远远低于此比例时,就可以认为客户流失发生。所以,客户流失分析系统必须针对各种不同的种类分别定义业务问题,进而分别进行处理。
2. 数据选择
数据选择包括目标变量的选择,输入变量的选择和建模数据的选择等多个方面。
目标变量的选择
目标变量表示了数据挖掘的目标。在客户流失分析应用目标变量通常为客户流失状态。依据业务问题的定义,我们可以选择一个已知量或多个已知量的明确组合作为目标变量。目标变量的值应该能够直接回答前面定义的业务问题。在客户流失分析系统中,们实际面对的流失形式主要有两种:账户取消发生的流失和账户休眠发生的流失。对于不同的流失形式,我们需要选取不同的目标变量。对于账户取消发生的流失,目标变量直接就可以选取客户的状态:流失或正常。对于账户休眠发生的流失,情况就较为复杂。
通常的定义是持续休眠超过给定时间长度的客户被认为是发生了流失。但是,这个给定时间长度定义为多长合适呢?另外一方面,
每月的通话金额低于多少就可以认为是客户处于休眠状态?或者要综合考虑通话金额,通话时长和通话次数来划定流失标准?实际上,目标变量的选择是和业务问题的定义紧密关联在一起的。选择目标变量所要面对的这些问题,都需要业务人员给予明确的答。
输入变量的选择
输入变量用于在建模时作为自变量寻找与目标变量之间的关联。在选择输入变量时,我们通常选择两类数据:静态数据和动态数据。静态数据指的是通常不会经常改变的数据,包括服务合同属性,如服务类型,服务时间,交费类型等等;和客户的基本状态,如性别,年龄,收入,婚姻状况,受教育年限/学历,职业,居住地区等等。动态数据指的是经常或定期改变的数据,如每月费金额,交费纪录,消费特征等等。输入变量的选择应该在业务人员帮助下进行,这样才能选择出真正与客户流失可能性具有潜在关联的输入变量。业务人员经常在实际业务活动中深深感觉到输入变量与目标变量的内在联系,但是却无法以量化表示出来。在这种情况下,数据挖掘的工作往往能够得到良好的回报。在一时无法确定某种数据是否与信用卡流失可能性有关联时,应该选取,在后续步骤考察各变量分布情况和相关性时再决定取舍。
建模数据的选择
通常电信行业客户流失的方向有两种。第一种是客户的自然消亡。例如由于客户的身故,破产,迁徙,移民等原因,导致客户不再存在。或者是由于客户的升级,如GSM 升级为CDMA,造成特定服务的目标客户消失。第二种是客户的转移流失。通常指客户转移到竞争对手享受服务。显然第二种流失的客户才是电信企业真正关心的,对企业具有挽留价值的客户。因此,我们在选择建模数据时必须选择第二种流失的客户数据参与建模,才能建立出较精确的模型。3. 数据清洗和预处理
数据清洗和预处理是建模前的数据准备工作。数据清洗和预处理的目的一方面保证建模的数据是正确和有效的;另一方面,通过对数据格式和内容的调整,使建立的模型更加准确和有效。数据整理的主要工作包括对数据的转换和整合,抽样,随机化,缺失值的处理等等。数据转换和整合的工作目的就是为了保证数据的质量和可用性。例如,样本数据中客户最终流失的数据比例较低,只占全部数据的8%。用这样的数据建模不容易找出流失了的客户的特征,建立精确的模型。我们可以按比例抽取未流失客户和流失了的客户,把两者合并构成建模的数据源。还有,在建模之前,我们建议把样本数据分为两到三部分。一部分用来建模,其他数据用来对模型进行修正和检验。一个模型在建立以后,需要用大量的数据对它进行检验。只有经过实际数据检验并被证明正确的模型才能得到充分的相信。如果一个未经检验的模型被贸然推广使用,就有可能由于模型的不精确带来应用的损失。所以我们通常会把数据分为两部分:2/3的数据用来建模,1/3的数据用来检验。
4. 模型选择与预建立
到底哪些变量和客户流失概率有密切关系呢?我们需要利用数据挖掘工具中的相关性比较功能找出每一个输入变量和客户流失概率的相关性。通过这样的比较选择,我们可以删除那些和客户流失概率相关性不大的变量,减少建模变量的数量。这样不仅可以缩短建立模型的时间,减小模型的复杂程度,而且有时还能够使建立的模型更精确。Oracle的数据挖掘工具能够提供包括决策树,神经网络,近邻学习,回归,关联,聚类,贝叶斯判别等多种建模方法。但是哪种方法最适合用于信用卡流失分析呢?我们可以使用多种建模方法,预建立多个模型,再比较这些模型的优劣,从而选择出最适合客户流失分析的建模方法。oracle的数据挖掘工具提供了建模方法选择的功能,它能够预建立决策树,神经网络,近邻学习,回归等多种方法,十个模型供使用者选择。它还能自动判别哪一个是最优的模型,供使用者参考。在预建模之前,使用者还能够改变模型的参数,从而根据实际情况生成更好的模型。
5. 模型建立与调整
模型建立与调整是数据挖掘过程中的核心部分。通常这部分工作会由专业的分析专家完成。需要指出的是,不同的商业问题和不同的数据分布与属性,经常会影响到模型建立与调整的策略。而且在建模过程中还会使用多种近似算法来简化模型的优化过程。所有这些处理方法,对模型的预测结果都会产生影响。所以在模型建立与调整过程中,需要业务专家参与制定调整策略,避免不适当的优化导致业务信息的丢失。
6. 模型的评估与检验
模型的评估应该利用未参与建模的数据进行,这样才能得到准确的结果。如果我们使用建模的数据对模型进行检验,由于模型就是按照这些数据建立的,检验结果自然会很好。但是一旦运用到实际数据中,就会产生很大的偏差。所以我们必须使用未参与建模的数据对模型进行检验。检验的方法是对已知客户状态的数据利用模型进行预测,得到模型的预测值,和实际的客户状态相较。
预测正确值最多的模型就是最优的模型。
7. 模型解释与应用
得到最优的模型以后,我们需要业务人员针对得到的模型做出一些合理的业务解释。例如:我们可能发现在开户时长与的客户的流失可能性相关度较高。那么,业务人员利用业务知识可以解释为:由于客户在使用一定年限后需要换领新SIM卡,而换领新SIM卡的手续比较繁琐或时间周期过长,客户宁愿去申请新号码,导致流失可能性上升量。通过对模型做出合理的业务解释,我们就有能找出一些以前没有发现,但实实在在存在的潜在的业务规律。找出这些规律后,就可以指导我们的业务行为。另一方面,如果真的能够根据业务知识解释我们得到的数学模型,也说明了这个数学模型在业务上的合理性,我们就更能够大胆应用于业务活动中了。
模型的真正应用推广必须谨慎从事。我们可以先选择一个试点单位应用模型,避免由于模型的不精确导致高额的业务损失。试点的时间可以界定在半年到一年,期间必须随时注意模型应用的收益情况。一旦发生异常偏差,应该立即停止,检查偏差是由于模型本身的原因还是由于应用环境发生了重大变化,从而导致模型不再适用。如果是由于模型本身不准确造成的,可以对模型不精确的部分进行修正。如果是由于应用环境发生了重大变化,就应该重新进行建模工作。当试点结束后,这个模型被证明应用良好,就可以考虑大面积的推广。
在大面积推广时应该注意的是,由于地区经济差异的原因,模型不能完全照搬。所以可以由总公司建立一个通用的模型,各分公司在此基础上利用本地数据进行进一步修正,得到适用于本地的精确模型。模型在应用一段时期后,或经济环境发生重大变后,有可能模型的偏差会增大,这时候就可以考虑重新建立一个更合适的模型。
RapidMiner下CHURN MODELING案例分析
模型建立步骤步骤1:加载一个客户数据集并检索数据
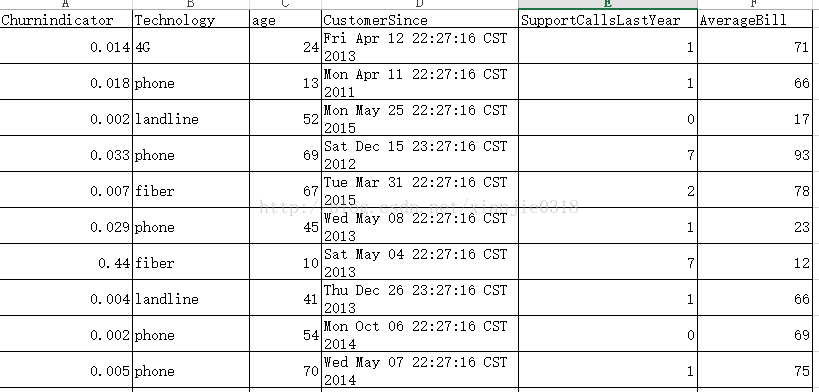
包含客户属性:
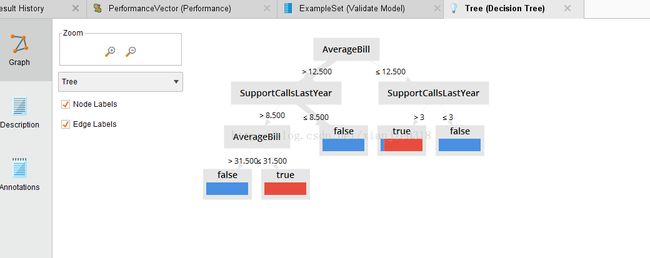
age:客户的年龄
Technology:技术类型(4G、光纤等)
CustomerSince:客户开始使用时间
AverageBill:去年客户平均使用帐单
SupportCallsLastYear:去年客户支持电话访问次数
Churnindicator:客户流失指标值
如下:
如果数据为excel或cvs数据文件可以通过ADD data加载数据入口,把excel数据文件加载进来
这里软件已经存储到工具中,通过Data Access下的Retrieve直接进行数据检索
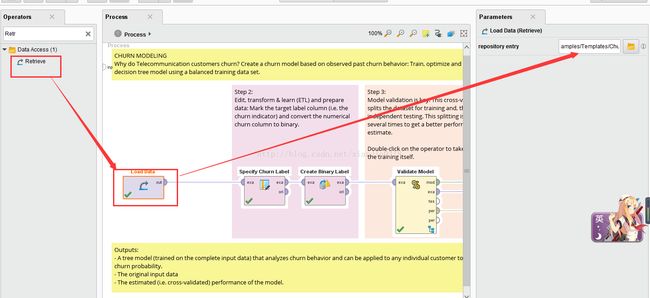
步骤2:挖掘目标列设定、数据转换并准备数据
标记目标标记列(即流失指示器)并将数值卷列转换为二进制。
首先通过set role组件设置需要挖掘的目标列:客户流失指标,即Churnindicator为标签列
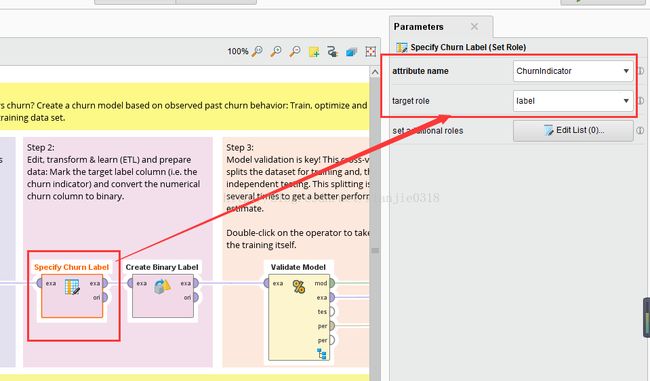
因客户流失指标作为挖掘目标,但是这目标为数值,需要转换为FALSE、TRUE,预估一下范围,预测转换为客户已经流失为true、客户未流失为False
这里把Churnindicator小于0.5的定为客户未流失,Churnindicator大于0.5的为客户已经流失

步骤3:模型建立
1)模型验证是关键!这种交叉验证将训练数据集进行分裂,然后能够独立的测试。这种分裂是做几次以获得更好的性能估计。
以下配置参数:自动模式:按自动模式使用分层抽样:10层,若不适合分层,就混合采样替代;

2)模型中---流程图包含:样本、自动参数组合优化(决策树算法、应用模型、二项式统计性能评价)、应用模型、二项式统计性能评价
样本选择
采用‘relative’采样模式,并设置平衡训练数据集:也就是说采用‘相对’样本,即按照设置的比例从总体数据中抽取部分数据作为样本进行学习。样本概率参数由每个类的样本大小、每类的抽样比率所代替。
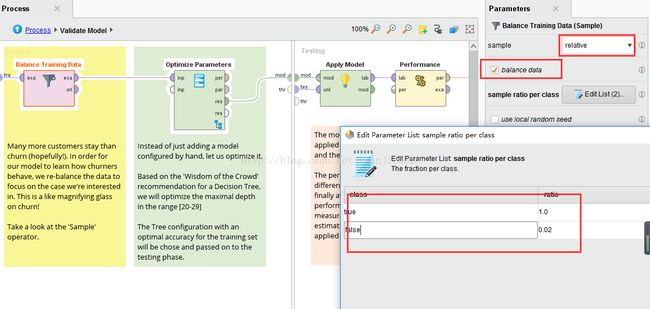
自动参数组合优化:优化参数(网格)算子,提供最佳参数组合
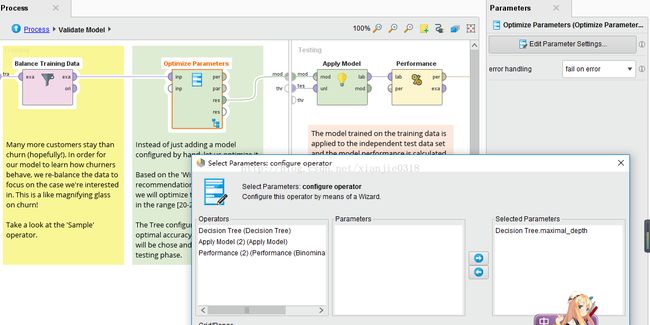
决策树算子:
rapidminner提供的决策树常用算法属性-:information_gain(信息增益)、gain_ratio(信息增益率)、gini_index(基尼系数)、accuracy(精度),
信息熵表示的是不确定度。均匀分布时,不确定度最大,此时熵就最大;
信息增益可以衡量某个特征对分类结果的影响大小;
基尼指数是另一种数据的不纯度的度量方法;
决策树常用算法:ID3 (信息增益) 、C4.5 (信息增益率)、CART (基尼指数)

决策树参数设置:
criterion-为选择的属性和数值分裂指定使用的标准
maximal depth: 树的最大深度(-1:无边界),树的深度取决于树的大小和性质。此参数用于限制决策树的大小。树生成当树深度等于最大深度时,进程不会继续。如果它值设置为“-1”,最大深度参数不限制树的深度,如果其值设置为“1”,则具有单个节点的树生成.
apply pruning (boolean):默认情况下选中,剪枝生成决策树。设置此参数为false(即不选中)禁用修剪和修剪树提供了一个
confidence: 用于修剪的封闭式错误计算的置信度等级
apply prepruning (boolean):默认情况下同时按参数限制生成决策树,设置此参数为false(即不选中)禁用以下参数限制生成决策树。
minimal size for split: 允许分裂的节点的最小尺寸
minimal leaf size: 树叶的最小尺寸
minimal gain: 为了产生一个分裂必须达到的最小增益
number of prepruning alternatives: 当预先修剪将阻止一个分裂时,可选择的节点数
决策树的默认criterion是gain_radio(增益率)
应用模型:预测数据模型的合理性,强制行检测数量、顺序、类型和角色属性的一致性,否则报错
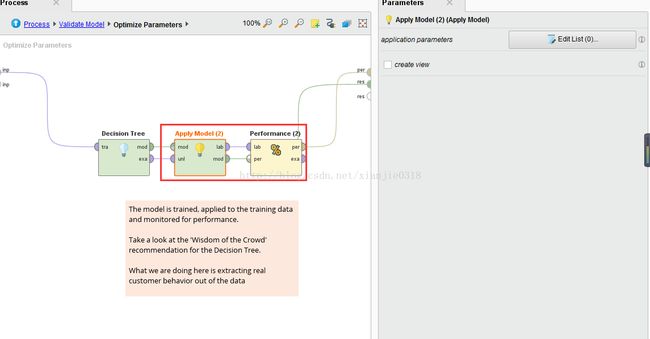
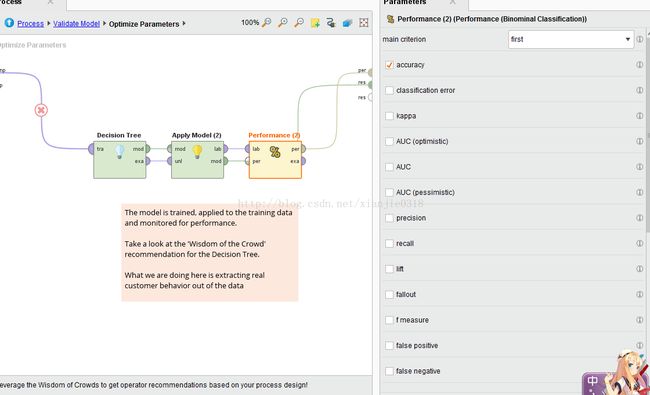
二项式统计性能评价:
分类任务即标签中的分类任务,属性有一个二项式型,也就说该组件同时进行两种不同目标标签挖掘分析任务,自动进行学习分析,
执行结果:
1)以criterion=gain_ratio(信息增益率)来测试,查看输出结果
2)以criterion=information_radio(信息增益)来测试,查看输出结果

3)以criterion=gini_index(基尼系数)来测试,查看输出结果

4)以criterion=accuracy(精度)来测试,查看输出结果

总结:
1、决策树算法是一种逼近离散函数值的方法,它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。
2、决策树算法构造决策树来发现数据中蕴含的分类规则。如何构造精度高、规模小的决策树是决策树算法的核心内容
3、构造决策树
(1)由训练样本数据集来训练生成决策树
(2)决策树的剪枝,决策树的剪枝是对上一阶段生成的决策树进行检验、校正和修正的过程,主要是用测试数据集的数据校验决策树生成过程中产生的初步规则,把那些影响预测准确性的分枝剪除
4、决策树可以处理非数值类型属性