sparkStreaming实现exactly-once,使用redis保存offset
本文主要记录使用SparkStreaming从Kafka里读取数据,并使用Redis保存Offset。
1.Redis Pool
object InternalRedisClient extends Serializable {
@transient private var pool: JedisPool = null
def makePool(redisHost: String, redisPort: Int, redisTimeout: Int,
maxTotal: Int, maxIdle: Int, minIdle: Int): Unit = {
makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle, true, false, 10000)
}
def makePool(redisHost: String, redisPort: Int, redisTimeout: Int,
maxTotal: Int, maxIdle: Int, minIdle: Int, testOnBorrow: Boolean,
testOnReturn: Boolean, maxWaitMillis: Long): Unit = {
if (pool == null) {
val poolConfig = new GenericObjectPoolConfig()
poolConfig.setMaxTotal(maxTotal)
poolConfig.setMaxIdle(maxIdle)
poolConfig.setMinIdle(minIdle)
poolConfig.setTestOnBorrow(testOnBorrow)
poolConfig.setTestOnReturn(testOnReturn)
poolConfig.setMaxWaitMillis(maxWaitMillis)
pool = new JedisPool(poolConfig, redisHost, redisPort, redisTimeout, "root_jinkun")
val hook = new Thread {
override def run = pool.destroy()
}
sys.addShutdownHook(hook.run)
}
}
def getPool: JedisPool = {
assert(pool != null)
pool
}
}2.KafkaRedisStreaming
object KafkaRedisStreaming {
private val LOG = LoggerFactory.getLogger("KafkaRedisStreaming")
def initRedisPool() = {
// Redis configurations
val maxTotal = 20
val maxIdle = 10
val minIdle = 1
val redisHost = "127.0.0.1"
val redisPort = 6379
val redisTimeout = 30000
InternalRedisClient.makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle)
}
/**
* 从redis里获取Topic的offset值
*
* @param topicName
* @param partitions
* @return
*/
def getLastCommittedOffsets(topicName: String, partitions: Int): Map[TopicPartition, Long] = {
if (LOG.isInfoEnabled())
LOG.info("||--Topic:{},getLastCommittedOffsets from Redis--||", topicName)
//从Redis获取上一次存的Offset
val jedis = InternalRedisClient.getPool.getResource
val fromOffsets = collection.mutable.HashMap.empty[TopicPartition, Long]
for (partition <- 0 to partitions - 1) {
val topic_partition_key = topicName + "_" + partition
val lastSavedOffset = jedis.get(topic_partition_key)
val lastOffset = if (lastSavedOffset == null) 0L else lastSavedOffset.toLong
fromOffsets += (new TopicPartition(topicName, partition) -> lastOffset)
}
jedis.close()
fromOffsets.toMap
}
def main(args: Array[String]): Unit = {
//初始化Redis Pool
initRedisPool()
val conf = new SparkConf()
.setAppName("ScalaKafkaStream")
.setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(3))
val bootstrapServers = "hadoop1:9092,hadoop2:9092,hadoop3:9092"
val groupId = "kafka-test-group"
val topicName = "Test"
val maxPoll = 20000
val kafkaParams = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> bootstrapServers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.MAX_POLL_RECORDS_CONFIG -> maxPoll.toString,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer]
)
// 这里指定Topic的Partition的总数
val fromOffsets = getLastCommittedOffsets(topicName, 3)
// 初始化KafkaDS
val kafkaTopicDS =
KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Assign[String, String](fromOffsets.keys.toList, kafkaParams, fromOffsets))
kafkaTopicDS.foreachRDD(rdd => {
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// 如果rdd有数据
if (!rdd.isEmpty()) {
val jedis = InternalRedisClient.getPool.getResource
val p = jedis.pipelined()
p.multi() //开启事务
// 处理数据
rdd
.map(_.value)
.flatMap(_.split(" "))
.map(x => (x, 1L))
.reduceByKey(_ + _)
.sortBy(_._2, false)
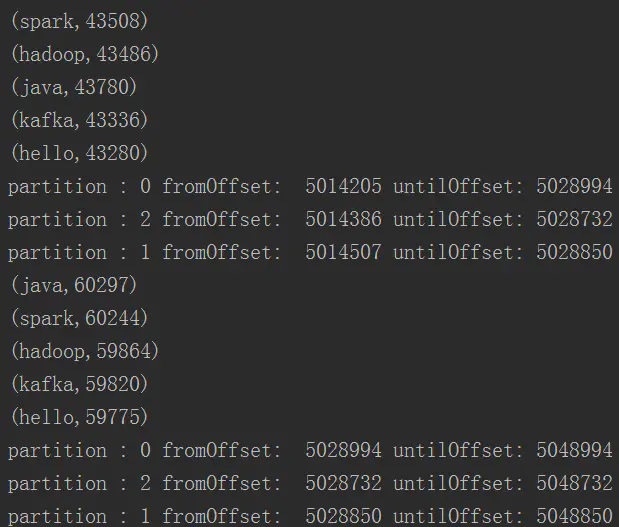
.foreach(println)
//更新Offset
offsetRanges.foreach { offsetRange =>
println("partition : " + offsetRange.partition + " fromOffset: " + offsetRange.fromOffset + " untilOffset: " + offsetRange.untilOffset)
val topic_partition_key = offsetRange.topic + "_" + offsetRange.partition
p.set(topic_partition_key, offsetRange.untilOffset + "")
}
p.exec() //提交事务
p.sync //关闭pipeline
jedis.close()
}
})
ssc.start()
ssc.awaitTermination()
}
}
程序运行结果如下:
链接:https://www.jianshu.com/p/8c0c1c63ae1b