编译原理 编译器的实现(C语言实现)
编译原理 编译器的实现(C语言实现)
chap1 词法语法语义的实现
绪论
根据输入Context-free Grammar(上下文无关法)构建分析器,
实现类似于yacc,lex的功能。
例如输入:
S'->S
S->BB
B->bB|a
下面说明,可选择阅读,是构建分析器的主线。
首先构建词法分析器,识别文法,然后把文法储存在文法表中,
然后利用Canonical LR(规范LR)算法,构建项目集,用现有的项目集
构建分析表。前端分析完成。
读者最好知道语法分析,词法分析,语义分析。理论的东西
请参考龙书<<编译原理>>,实践的也可参考虎书
<<现代编译原理 -C语言实现>>
电子版,可在http:://ebook.00083.com
http://www.netyi.net下载,搜索一下就有。推荐
龙书,有详尽的叙述,虽然有很多pascal代码。
还有一本<<现代编译程序设计>>(Modern complier design)
偏重实践,只不过内容有点凌乱。龙书虎书有很多很好的习题,
只是没有答案,有点遗憾,现代编译程序设计,有答案,只不过
很难读进去。
国内的教材,清华编译原理的偏重理论,并且一些理论还不健全,
缺乏实践。国防科大的陈火旺<<现代编译原理>>,惨不忍睹,读完
以首抢地,血流如注,不知所云。科大陈意云,完全抄袭龙书,
稍微改了一些示例程序的代码中的符号,并且翻译的很差,很重要的
必须理解的东西一笔带过,适合读完龙书,然后利用这本书来温习。
别的教材不甚了了。
小弟主修空间物理,毕业后在家卧床养病两年,前途无望,无所事事,
每日坐在樟树下,数数蚂蚁而已。有空写点编译原理的东西,如果有
高洁之士,请不吝指教。zh291@mail.ustc.edu.cn
$1 词法分析
词法分析,有两种实现方法,一个是利用正规表达式构建DFA,
再根据DFA实现程序,一个是预测分析,利用输入符号,用一系列
的case和if判断语句,来构建函数。手工第二种方法较多,第一种
方法多用于词法分析工具构造如lex;
本文构建一个yacc类似程序的读取文法表达式的词法分析器。
读取合法的context-free文法。
下篇根据这个程序构建语法分析;
词法分析,可以从控制台输入中一个一个读取,调用getchar()
读取一个word,然后分析这个读取的word,也可以一次性读取所有输入,
例如控制台输入,文件输入,然后将读取的date存储在一个全局数组中。
例如:这是一个简单函数,没有优化的。
char buffer[1024];
void read()
{
FILE *f;
int index=0;
char c;
f=fopen("date.dat");
while((c=fread(f))!=EOF)buffer[index++]=c;
}
词法分析首先读入字符。首先构建读入date函数。
本文的词法分析,采用读取控制台输入,每次读入一个字符,如果字符
是backspace,tab(' ','/t'),则忽略。因为是空白分隔符。构建读取控制台
输入函数;
char getToken()
{
char c=getchar();
while(c==' '||c=='/t')//如果读入字符是空白符,则忽略读取下一个
//字符,'/n'不忽略的原因是因为,当读入'/n'
//本程序约定则表示一个文法表达式结束。开始
//构建下一个文法表达式。
c=getchar();
return c;
}
本文约定两个符号,'/n'表示一个文法表达式结束,’#‘表示一个文法结束。
如:
S->BB
B->a
#
当输入'#'时,表示文法符号输入结束。
读入字符后,分析字符,构建文法表,用数组表示。
源程序如下:稍后分析。
typedef struct item{
char *expr;/*left指向一个读入的文法符号数组,如指向"Z->S";
这个Struct只有一个字符指针,可以在添加一些
member,如
int index; index是第几个文法表达式。
struct item *next; 指向下一个文法表达式;
struct item *backward; 指向上一个文法表达式;
*/
}GrammarType;
GrammarType grammarTable[10];
int index=0; //index 为grammarTable[index],表示正要读入的表达式。
char lexemes[1024]; //lexemes[1024]读入的数据存储数组,pos,下一个数组可存储的
//地方;
int pos=0;
//读取文法表达式
int getGrammar()
{
char local[16];
int p=0;
char c=getToken(); //读取字符
if(c=='#') return -1; //如果读取'#'表示文法结束,返回-1;
if(c>='A'&&c<='Z')local[p++]=c;
/*
分析一个文法表达式,如S->BB
由于Context-free文法第一个符号S必须是
非终结符属于Vn中,非终结符用大写字母表示
如果第一个字符不是大写字母如A..Z等,则
这个文法出错。local[p]用于存储读入的字符,
读入的表达式,临时存储在local字符数组中,
如果读取一个表达式完毕,再将这个字符数组
copy到字符表中,如果第一个字符不是大写字母,
exit(1);
*/
else {printf("the left of grammar must be UpperCase");exit(1);}
c=getToken(); //读取下两个字符'->';
if(c!='-'){printf("there must be - symbol");exit(1);}
local[p++]=c;
c=getToken();
if(c!='>'){printf("there must be > symbol");exit(1);}
local[p++]=c;
c=getToken();//读取'->'右边第一个字符,如果是'/n'代表表达式结束
//右边没有字符,则出错,exit(1);
if(c!='/n')local[p++]=c;
else {printf("the right of grammar is null");exit(1);}
c=getToken(); //读取'->'右边继第一个字符之后的后续字符。直到'/n'结束;
while(c!='/n')
{ //如果表达式是B->bB|a,则必须分解成B->bB,B->a两个表达式;
//所以如果读入的字符为’|‘,构建两个表达式;
if(c=='|')
{
local[p++]='/0'; //将'|'左边的字符存储为一个表达式,并将开始符号
//与后续字符构建另一个表达式,如B->bB|a;
//将左边B->bB构建一个表达式,并让lolal存储’B->‘
//以构建B->a;
strcpy(&lexemes[pos],local);//将读入的字符存储到lexems,的date存储地方。
grammarTable[index].left=&lexemes[pos];
pos+=strlen(local)+1; //pos指向下个date数组lexemes可用处。
index++;
p=3;
}
else local[p++]=c;
c=getToken();
}
local[p]='/0';
grammarTable.left=&lexemes[pos];
strcpy(&lexemes[pos],local);
pos+=strlen(local)+1;
index++;
return index;
}
文法表达式,(Vn,Vt,P,S);
非终结符用大写字母表示,所以第一个字符必须是大写字母,然后读取余下字母,直到'/n',读取
表达式结束。如果第一个字母是'#'时,表示输入结束,返回。
程序采用全局数组存储符号表grammarTable,然后读取形如B->bB|ad的表达式,并将字符存储在
局部变量local中,当确定是一个表达式时,再将表达式复制到全局数组存储符号表grammarTable中,
grammarTable,是一个文法表, 每个读取的文法表达式如S->BB就存储在
文法表中,如S->BB存储在grammarTable[i]中;它是一个大小固定为10的表达式,
只能接受10个表达式,这是静态的。由于这是一个示范程序,所以定义全局变量grammarTable[10],
程序比较简单。
如果像取消这个限制,能够接受任意多的文法表达式,可以采用动态分配数组的方式。
当采用这种动态分配方式时,必须要增加GrammarType结构,方便遍历整个表达式。
typedef struct item
{
char *expr;
struct item *next;
struct item *backward;
}GrammarType;
例如读取S->BB完成,假设S->BB存储在expr中
并且全局只存在一个GrammarType *start;指向第
一个表达式,GrammatType *input;指向现在正要
读取的表达式。
GrammarType *start,*input;
int index=0; //表示已读入几个表达式;
void f(...)
{
...
char expr[10];
expr="S->BB";
int length=strlen(expr)+1;
//length包括'/0'这个字符
GrammarType *temp=malloc(sizeof(GrammarType));
temp->expr=malloc(sizeof(char)*length);
strcpy(temp.expr,expr);
if(index==0)
{start=temp;//当读取的是第一个表达式时
input=temp; //input=start=temp;temp没有
temp->backward=null; //next,backward,所以为null
temp->next=null ;
}else
{
input->next=temp;
temp->foward=input;
input=temp;
}
index++;
...
}
上面采用动态分配方式。
构建一个驱动程序即main()来驱动一下。
void lex()
{
while(getGrammar()!=-1);
}
int main()
{
int i;
lex();
for(i=0;iprintf("%c->%s/n",grammarTable[i].left[0],&grammarTable[i].left[1]);
return 0;
}
这个词法分析程序很简单,但下面关于这个收到的词法进行语法分析,
语义分析,有点难度。但本文尽量集中到词法分析,语法分析上,而不
关注,优化,算法,过多的涉及,往往没有以专注的地方。例如这个文法
表达式存储可采用一些算法来存储,以方便以后的遍历寻找,如采用散列
存储,或者用堆存储,这些算法请参考MIT的算法导论那门课程。可在
MIT openCourse上下载教学视频。
程序完整程序:
typedef struct grammer
{
char *expr;
}GrammarType;
GrammarType grammarTable[10];
int index=0;
char lexemes[1024];
int pos=0;
int getToken()
{
int c=getchar();
while(c==' '||c=='/t')
{
c=getchar();
}
return c;
}
int getGrammar()
{
char local[16];
int p=0;
int c=getToken();
if(c=='#') return -1;
if(c>='A'&&c<='Z')local[p++]=c;
else {printf("the left of grammar must be UpperCase");exit(1);}
c=getToken();
if(c!='-'){printf("there must be - symbol");exit(1);}
local[p++]=c;
c=getToken();
if(c!='>'){printf("there must be > symbol");exit(1);}
local[p++]=c;
c=getToken();
if(c!='/n')local[p++]=c;
else {printf("the right of grammar is null");exit(1);}
c=getToken();
while(c!='/n')
{if(c=='|')
{
local[p++]='/0';
grammarTable[index].expr=&lexemes[pos];
strcpy(&lexemes[pos],local);
pos+=strlen(local)+1;
index++;
p=3;
}
else local[p++]=c;
c=getToken();
}
local[p]='/0';
grammarTable[index].expr=&lexemes[pos];
strcpy(&lexemes[pos],local);
pos+=strlen(local)+1;
index++;
return index;
}
void lex()
{
while(getGrammar()!=-1);
}
int main()
{
int i;
lex();
printf("/nthe input Context-free grammar:/n")
for(i=0;iprintf("%s/n",grammarTable[i].expr);
return 0;
}
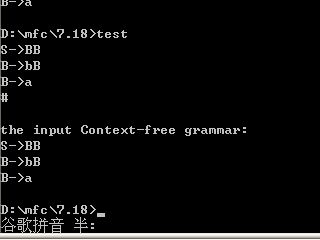
程序结果:
chap1 词法语法语义的实现
绪论
根据输入Context-free Grammar(上下文无关法)构建分析器,
实现类似于yacc,lex的功能。
例如输入:
S'->S
S->BB
B->bB|a
下面说明,可选择阅读,是构建分析器的主线。
首先构建词法分析器,识别文法,然后把文法储存在文法表中,
然后利用Canonical LR(规范LR)算法,构建项目集,用现有的项目集
构建分析表。前端分析完成。
读者最好知道语法分析,词法分析,语义分析。理论的东西
请参考龙书<<编译原理>>,实践的也可参考虎书
<<现代编译原理 -C语言实现>>
电子版,可在http:://ebook.00083.com
http://www.netyi.net下载,搜索一下就有。推荐
龙书,有详尽的叙述,虽然有很多pascal代码。
还有一本<<现代编译程序设计>>(Modern complier design)
偏重实践,只不过内容有点凌乱。龙书虎书有很多很好的习题,
只是没有答案,有点遗憾,现代编译程序设计,有答案,只不过
很难读进去。
国内的教材,清华编译原理的偏重理论,并且一些理论还不健全,
缺乏实践。国防科大的陈火旺<<现代编译原理>>,惨不忍睹,读完
以首抢地,血流如注,不知所云。科大陈意云,完全抄袭龙书,
稍微改了一些示例程序的代码中的符号,并且翻译的很差,很重要的
必须理解的东西一笔带过,适合读完龙书,然后利用这本书来温习。
别的教材不甚了了。
小弟主修空间物理,毕业后在家卧床养病两年,前途无望,无所事事,
每日坐在樟树下,数数蚂蚁而已。有空写点编译原理的东西,如果有
高洁之士,请不吝指教。zh291@mail.ustc.edu.cn
$1 词法分析
词法分析,有两种实现方法,一个是利用正规表达式构建DFA,
再根据DFA实现程序,一个是预测分析,利用输入符号,用一系列
的case和if判断语句,来构建函数。手工第二种方法较多,第一种
方法多用于词法分析工具构造如lex;
本文构建一个yacc类似程序的读取文法表达式的词法分析器。
读取合法的context-free文法。
下篇根据这个程序构建语法分析;
词法分析,可以从控制台输入中一个一个读取,调用getchar()
读取一个word,然后分析这个读取的word,也可以一次性读取所有输入,
例如控制台输入,文件输入,然后将读取的date存储在一个全局数组中。
例如:这是一个简单函数,没有优化的。
char buffer[1024];
void read()
{
FILE *f;
int index=0;
char c;
f=fopen("date.dat");
while((c=fread(f))!=EOF)buffer[index++]=c;
}
词法分析首先读入字符。首先构建读入date函数。
本文的词法分析,采用读取控制台输入,每次读入一个字符,如果字符
是backspace,tab(' ','/t'),则忽略。因为是空白分隔符。构建读取控制台
输入函数;
char getToken()
{
char c=getchar();
while(c==' '||c=='/t')//如果读入字符是空白符,则忽略读取下一个
//字符,'/n'不忽略的原因是因为,当读入'/n'
//本程序约定则表示一个文法表达式结束。开始
//构建下一个文法表达式。
c=getchar();
return c;
}
本文约定两个符号,'/n'表示一个文法表达式结束,’#‘表示一个文法结束。
如:
S->BB
B->a
#
当输入'#'时,表示文法符号输入结束。
读入字符后,分析字符,构建文法表,用数组表示。
源程序如下:稍后分析。
typedef struct item{
char *expr;/*left指向一个读入的文法符号数组,如指向"Z->S";
这个Struct只有一个字符指针,可以在添加一些
member,如
int index; index是第几个文法表达式。
struct item *next; 指向下一个文法表达式;
struct item *backward; 指向上一个文法表达式;
*/
}GrammarType;
GrammarType grammarTable[10];
int index=0; //index 为grammarTable[index],表示正要读入的表达式。
char lexemes[1024]; //lexemes[1024]读入的数据存储数组,pos,下一个数组可存储的
//地方;
int pos=0;
//读取文法表达式
int getGrammar()
{
char local[16];
int p=0;
char c=getToken(); //读取字符
if(c=='#') return -1; //如果读取'#'表示文法结束,返回-1;
if(c>='A'&&c<='Z')local[p++]=c;
/*
分析一个文法表达式,如S->BB
由于Context-free文法第一个符号S必须是
非终结符属于Vn中,非终结符用大写字母表示
如果第一个字符不是大写字母如A..Z等,则
这个文法出错。local[p]用于存储读入的字符,
读入的表达式,临时存储在local字符数组中,
如果读取一个表达式完毕,再将这个字符数组
copy到字符表中,如果第一个字符不是大写字母,
exit(1);
*/
else {printf("the left of grammar must be UpperCase");exit(1);}
c=getToken(); //读取下两个字符'->';
if(c!='-'){printf("there must be - symbol");exit(1);}
local[p++]=c;
c=getToken();
if(c!='>'){printf("there must be > symbol");exit(1);}
local[p++]=c;
c=getToken();//读取'->'右边第一个字符,如果是'/n'代表表达式结束
//右边没有字符,则出错,exit(1);
if(c!='/n')local[p++]=c;
else {printf("the right of grammar is null");exit(1);}
c=getToken(); //读取'->'右边继第一个字符之后的后续字符。直到'/n'结束;
while(c!='/n')
{ //如果表达式是B->bB|a,则必须分解成B->bB,B->a两个表达式;
//所以如果读入的字符为’|‘,构建两个表达式;
if(c=='|')
{
local[p++]='/0'; //将'|'左边的字符存储为一个表达式,并将开始符号
//与后续字符构建另一个表达式,如B->bB|a;
//将左边B->bB构建一个表达式,并让lolal存储’B->‘
//以构建B->a;
strcpy(&lexemes[pos],local);//将读入的字符存储到lexems,的date存储地方。
grammarTable[index].left=&lexemes[pos];
pos+=strlen(local)+1; //pos指向下个date数组lexemes可用处。
index++;
p=3;
}
else local[p++]=c;
c=getToken();
}
local[p]='/0';
grammarTable.left=&lexemes[pos];
strcpy(&lexemes[pos],local);
pos+=strlen(local)+1;
index++;
return index;
}
文法表达式,(Vn,Vt,P,S);
非终结符用大写字母表示,所以第一个字符必须是大写字母,然后读取余下字母,直到'/n',读取
表达式结束。如果第一个字母是'#'时,表示输入结束,返回。
程序采用全局数组存储符号表grammarTable,然后读取形如B->bB|ad的表达式,并将字符存储在
局部变量local中,当确定是一个表达式时,再将表达式复制到全局数组存储符号表grammarTable中,
grammarTable,是一个文法表, 每个读取的文法表达式如S->BB就存储在
文法表中,如S->BB存储在grammarTable[i]中;它是一个大小固定为10的表达式,
只能接受10个表达式,这是静态的。由于这是一个示范程序,所以定义全局变量grammarTable[10],
程序比较简单。
如果像取消这个限制,能够接受任意多的文法表达式,可以采用动态分配数组的方式。
当采用这种动态分配方式时,必须要增加GrammarType结构,方便遍历整个表达式。
typedef struct item
{
char *expr;
struct item *next;
struct item *backward;
}GrammarType;
例如读取S->BB完成,假设S->BB存储在expr中
并且全局只存在一个GrammarType *start;指向第
一个表达式,GrammatType *input;指向现在正要
读取的表达式。
GrammarType *start,*input;
int index=0; //表示已读入几个表达式;
void f(...)
{
...
char expr[10];
expr="S->BB";
int length=strlen(expr)+1;
//length包括'/0'这个字符
GrammarType *temp=malloc(sizeof(GrammarType));
temp->expr=malloc(sizeof(char)*length);
strcpy(temp.expr,expr);
if(index==0)
{start=temp;//当读取的是第一个表达式时
input=temp; //input=start=temp;temp没有
temp->backward=null; //next,backward,所以为null
temp->next=null ;
}else
{
input->next=temp;
temp->foward=input;
input=temp;
}
index++;
...
}
上面采用动态分配方式。
构建一个驱动程序即main()来驱动一下。
void lex()
{
while(getGrammar()!=-1);
}
int main()
{
int i;
lex();
for(i=0;i
return 0;
}
这个词法分析程序很简单,但下面关于这个收到的词法进行语法分析,
语义分析,有点难度。但本文尽量集中到词法分析,语法分析上,而不
关注,优化,算法,过多的涉及,往往没有以专注的地方。例如这个文法
表达式存储可采用一些算法来存储,以方便以后的遍历寻找,如采用散列
存储,或者用堆存储,这些算法请参考MIT的算法导论那门课程。可在
MIT openCourse上下载教学视频。
程序完整程序:
typedef struct grammer
{
char *expr;
}GrammarType;
GrammarType grammarTable[10];
int index=0;
char lexemes[1024];
int pos=0;
int getToken()
{
int c=getchar();
while(c==' '||c=='/t')
{
c=getchar();
}
return c;
}
int getGrammar()
{
char local[16];
int p=0;
int c=getToken();
if(c=='#') return -1;
if(c>='A'&&c<='Z')local[p++]=c;
else {printf("the left of grammar must be UpperCase");exit(1);}
c=getToken();
if(c!='-'){printf("there must be - symbol");exit(1);}
local[p++]=c;
c=getToken();
if(c!='>'){printf("there must be > symbol");exit(1);}
local[p++]=c;
c=getToken();
if(c!='/n')local[p++]=c;
else {printf("the right of grammar is null");exit(1);}
c=getToken();
while(c!='/n')
{if(c=='|')
{
local[p++]='/0';
grammarTable[index].expr=&lexemes[pos];
strcpy(&lexemes[pos],local);
pos+=strlen(local)+1;
index++;
p=3;
}
else local[p++]=c;
c=getToken();
}
local[p]='/0';
grammarTable[index].expr=&lexemes[pos];
strcpy(&lexemes[pos],local);
pos+=strlen(local)+1;
index++;
return index;
}
void lex()
{
while(getGrammar()!=-1);
}
int main()
{
int i;
lex();
printf("/nthe input Context-free grammar:/n")
for(i=0;i
return 0;
}
程序结果: