异步编程原理以及Java实现
说实话多线程和异步是非常容易让人混淆的,好像产生的效果差不多,甚至有人称多线程为异步,实际上这两种技术背后的实现原理是不同的。
-
假设您有2个任务,不涉及任何IO(在多处理器机器上)。在这种情况下,线程优于Async。因为像单线程程序一样的Async按顺序执行你的任务。但是线程可以同时执行这两个任务。
-
假设您有2个任务,涉及IO(在多处理器机器上)。在这种情况下,Async和Threads执行的操作大致相同(性能可能因核心数量,调度,任务过程密集程度等而异)。此外,Async占用的资源更少,开销更低,并且在多线程程序上编程也更简单。
这个怎么运作?线程1执行任务1,因为它正在等待IO,它将被移动到IO等待队列。类似地,线程2执行任务2,因为它也涉及IO,它被移动到IO等待队列。一旦它的IO请求得到解决,它就会被移动到就绪队列,因此调度程序可以安排线程执行。
异步执行任务1而不等待它的IO完成它继续任务2然后它等待任务完成的IO。它按IO完成顺序完成任务。
异步最适合涉及Web服务调用,数据库查询调用等的任务,用于进程密集型任务的线程。
以下视频介绍了Async vs Threaded model何时以及何时使用等
《What Is Async, How Does It Work, and When Should I Use It? (PyCon APAC 2014)》

thread-vs-async
- 编写线程安全的代码非常困难。使用异步代码,您可以准确地知道代码从一个任务转移到另一个任务的位置,因此竞争条件更难实现。
- 线程消耗大量数据,因为每个线程都需要拥有自己的堆栈。使用异步代码,所有代码共享相同的堆栈,并且由于在任务之间不断地展开堆栈,堆栈保持很小。
- 线程是OS结构,因此是平台支持的更多内存。异步任务没有这样的问题。
有两种方法可以创建线程:
同步线程 - 父级创建一个(或多个)子线程,然后必须等待每个子级终止。同步线程通常称为fork-join模型。
异步线程 - 父和子并发/独立运行。多线程服务器通常遵循此模型。
资源 - http://www.amazon.com/Operating-System-Concepts-Abraham-Silberschatz/dp/0470128720
---------------
《In Which We Begin at the Beginning》
第一个模型是单线程同步模型,如下图1所示:
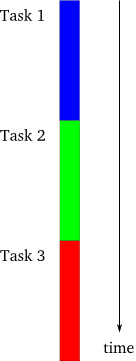
这是最简单的编程风格。每个任务一次执行一个,在完成另一个任务之前完成一个任务。如果任务总是按照确定的顺序执行,则后续任务的实现可以假设所有早期任务都已完成且没有错误,所有输出都可供使用 - 逻辑的明确简化。
我们可以将同步模型与另一个模型进行对比,如图2所示的线程模型:

在此模型中,每个任务都在一个单独的控制线程中执行。线程由操作系统管理,并且可以在具有多个处理器或多个核的系统上真正同时运行,或者可以在单个处理器上交织在一起。关键是,在线程模型中,执行的细节由OS处理,程序员只是根据可以同时运行的独立指令流来思考。虽然图表很简单,但实际上线程程序可能非常复杂,因为线程需要相互协调。线程通信和协调是一个高级编程主题,很难做到正确。
一些程序使用多个进程而不是多个线程来实现并行性。虽然编程细节不同,但就我们的目的而言,它与图2中的模型相同。
现在我们可以在图3中介绍异步模型:

在此模型中,任务彼此交错,但在单个控制线程中。这比线程情况简单,因为程序员总是知道当一个任务执行时,另一个任务不是。虽然在单处理器系统中,线程程序也将以交错模式执行,但使用线程的程序员仍然应该考虑图2,而不是图3,以免程序在移动到多处理器系统时工作不正常。但是,即使在多处理器系统上,单线程异步系统也总是以交错方式执行。
异步和线程模型之间还有另一个区别。在线程系统中,暂停一个线程并执行另一个线程的决定很大程度上超出了程序员的控制范围。相反,它受操作系统的控制,并且程序员必须假设一个线程可以在几乎任何时候被挂起并替换为另一个。相反,在异步模型下,任务将继续运行,直到它明确地将控制权交给其他任务。这是螺纹外壳的进一步简化。
请注意,可以混合异步和线程模型,并在同一系统中使用它们。但是对于大多数这个介绍,我们将坚持使用一个控制线程的“普通的”异步系统。
动机
我们已经看到异步模型比线程模型简单,因为有一个指令流,任务明确放弃控制而不是任意暂停。但是异步模型显然比同步情况更复杂。程序员必须将每个任务组织为一系列间歇性执行的较小步骤。如果一个任务使用另一个任务的输出,则必须编写依赖任务以接受其输入作为一系列的比特而不是一起。由于没有实际的并行性,从我们的图中可以看出异步程序与同步程序执行的时间一样长,可能更长,因为异步程序可能表现出较差的引用局部性。
----
引用局部性,也称为局部性原理,[1]是处理器在短时间内重复访问同一组存储器位置的趋势。[2]引用局部性有两种基本类型 - 时间和空间局部性。时间局部性是指在相对小的持续时间内重用特定数据和/或资源。空间局部性是指在相对较近的存储位置内使用数据元素。顺序局部性是空间局部性的一种特殊情况,当数据元素被线性排列和访问时发生,例如遍历一维阵列中的元素。
局部性只是计算机系统中发生的一种可预测行为。表现出强大的系统访问的局部性是通过使用技术性能优化极大的候选人,如缓存,预取的内存和先进的分支预测的流水线处理器核心的阶段。
----
那你为什么选择使用异步模型呢?至少有两个原因。首先,如果一个或多个任务负责为人类实现接口,则通过将任务交织在一起,系统可以保持响应于用户输入,同时仍然在“后台”中执行其他工作。因此,虽然后台任务可能不会更快地执行,但系统对于使用它的人来说会更愉快。
但是,在整个较短时间内执行所有任务的意义上,异步系统有时会优于同步系统,有时甚至会非常大。当任务被强制等待或阻塞时,这种情况就会成立,如图4所示:

在图中,灰色部分表示特定任务等待(阻塞)的时间段,因此无法取得任何进展。为什么要阻止任务?一个常见的原因是它正在等待执行I / O,向外部设备传输数据或从外部设备传输数据。典型的CPU可以处理比磁盘或网络链路能够维持的数据传输速率快几个数量级的数据传输速率。因此,当磁盘或网络赶上时,执行大量I / O的同步程序将大部分时间被阻止。出于这个原因,这样的同步程序也称为阻塞程序。
请注意,图4是一个阻塞程序,看起来有点像图3,一个异步程序。这不是巧合。异步模型背后的基本思想是,异步程序在面对通常会在同步程序中阻塞的任务时,将执行一些仍然可以取得进展的其他任务。因此,当没有任务可以取得进展时,异步程序只会“阻塞”,因此被称为非阻塞程序。并且每个从一个任务切换到另一个任务对应于第一个任务要么完成要么要到达必须阻止的点。通过大量潜在的阻塞任务,异步程序可以通过减少等待的总时间来优于同步程序,同时将大致相等的时间用于单个任务的实际工作。
与同步模型相比,异步模型在以下情况下表现最佳:
- 有大量任务,因此可能始终至少有一项任务可以取得进展。
- 这些任务执行大量I / O操作,导致同步程序在其他任务可能正在运行时浪费大量时间。
- 这些任务在很大程度上是彼此独立的,因此几乎不需要任务间通信(因此一项任务需要等待另一项任务)。
这些条件几乎完美地表征了客户端 - 服务器环境中的典型繁忙网络服务器(如Web服务器)。每个任务以接收请求和发送回复的形式表示一个带有I / O的客户端请求。客户端请求(主要是读取)在很大程度上是独立的。因此,网络服务器实现是异步模型的主要候选者。
---------------------
并发与多线程与异步编程:解释
同步编程模型 - 在此编程模型中,将一个线程分配给一个任务并开始处理它。任务完成后,它可用于下一个任务。在这个模型中,它不能让执行任务处于中间以承担另一个任务。让我们讨论一下这个模型在单线程和多线程环境中的工作原理。
单线程 - 如果我们要处理几个任务并且当前系统只提供一个线程,那么任务将逐个分配给线程。它可以用图形描绘为

在这里我们可以看到我们有一个线程(线程1)和四个要完成的任务。线程逐个开始处理任务并完成所有任务。(任务将被占用的顺序,不影响执行,我们可以有不同的算法,可以定义任务的优先级)
多线程 - 在这种环境中,我们曾经有多个线程可以处理这些任务并开始研究它。这意味着我们有一个线程池(也可以根据需求和可用资源创建新线程)和一堆任务。所以这些线程可以在这些上工作

在这里我们可以看到我们有四个线程和相同数量的任务要完成。所以每个线程都会占用一个任务并完成它。这是一个理想的场景,但在正常情况下,我们曾经拥有的任务数量多于可用线程数量。因此,无论哪个线程获得自由,都会承担另一项任务。如前所述,每次产生新线程都不是一个选项,因为它需要CPU,内存等系统资源。
现在,让我们来谈谈异步模型以及它在单线程和多线程环境中的表现。
异步编程模型 - 与同步编程模型相反,这里一个线程一旦开始执行一个任务就可以将它保存在中间,保存当前状态并开始执行另一个任务。
![]()
在这里我们可以看到单个线程负责完成所有任务,并且任务相互交错。
如果我们的系统能够拥有多个线程,那么所有线程也可以在异步模型中工作

在这里我们可以看到相同的任务说T4,T5,T6 ..由多个线程处理。这就是这种情况的美妙之处。正如您所看到的,T4首先在线程1中启动并由线程2完成。类似地,T6由线程2,线程3和线程4完成。它显示了线程的最大利用率。
所以到目前为止我们已经讨论过四种情况
- 同步单线程
- 同步多线程
- 异步单线程
- 异步多线程
让我们再讨论一个术语 - 并发。
并发
简单来说,并发意味着一次处理多个请求。我们已经讨论了两个处理多个请求的场景,多线程编程和异步模型(单线程和多线程)。在异步模型的情况下,无论是单线程还是多线程,多个任务一次都在进行中,一些处于保持状态,一些正在执行。它有很多种,但这超出了本文的范围。
如前所述,新时代是异步编程。为什么这么重要?
异步编程的好处
对于任何应用程序而言,有两件事非常重要 - 可用性和性能。可用性因为用户点击按钮来保存一些数据。这需要多个较小的任务,例如在内部对象中读取和填充数据,与SQL建立连接并将其保存在那里等。由于SQL在网络中的另一台机器上运行并在不同的进程下运行,因此可能会耗费时间并且可能需要更长的时间。因此,如果应用程序在单个线程上运行,那么屏幕将处于挂起状态,直到所有任务完成,这是非常糟糕的用户体验。这就是为什么现在许多应用程序和新框架完全依赖于异步模型。
应用程序的性能也非常重要。已经看到,在执行请求时,大约70-80%的时间在等待依赖任务时被浪费。因此,异步编程可以最大限度地利用它,一旦将任务传递给另一个进程(比如SQL),当前线程就会保存状态并可用于执行另一个任务。当SQL任务完成任何空闲的线程时,可以进一步处理它。
每个连接一个线程与多个请求一个线程有什么区别?


----------------------
Future和FutureTask的区别
历史原因
在的Java中创建线程的2种方式,一种是直接继承线程,另外一种就是实现了Runnable接口这2种方式都有一个缺陷就是:在执行完任务之后无法获取执行结果。
需求
在Java中,如果需要获取执行结果,就必须通过共享变量或者使用线程通信的方式来达到效果,这样使用起来就比较麻烦。而自从Java 1.5开始,就提供了Callable和Future,通过它们可以在任务执行完毕之后得到任务执行结果。
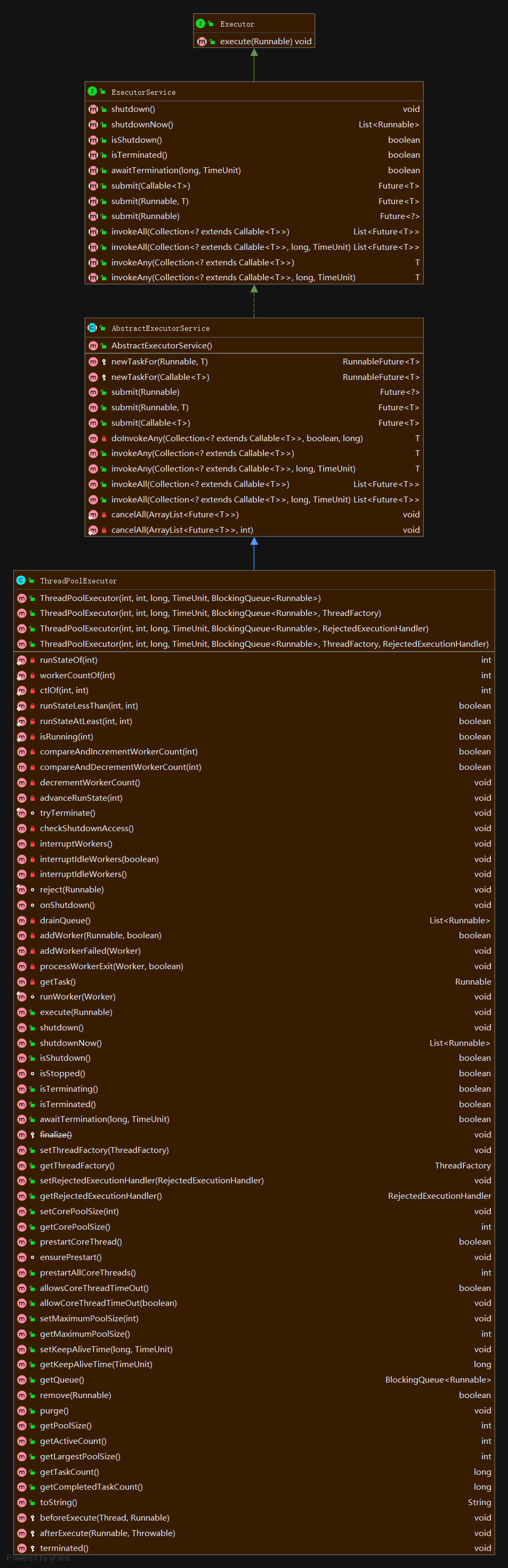
Future和FutureTask类图

方法解析:
V get() :获取异步执行的结果,如果没有结果可用,此方法会阻塞直到异步计算完成。
V get(Long timeout , TimeUnit unit) :获取异步执行结果,如果没有结果可用,此方法会阻塞,但是会有时间限制,如果阻塞时间超过设定的timeout时间,该方法将抛出异常。
boolean isDone() :如果任务执行结束,无论是正常结束或是中途取消还是发生异常,都返回true。
boolean isCanceller() :如果任务完成前被取消,则返回true。
boolean cancel(boolean mayInterruptRunning) :如果任务还没开始,执行cancel(...)方法将返回false;如果任务已经启动,执行cancel(true)方法将以中断执行此任务线程的方式来试图停止任务,如果停止成功,返回true;当任务已经启动,执行cancel(false)方法将不会对正在执行的任务线程产生影响(让线程正常执行到完成),此时返回false;当任务已经完成,执行cancel(...)方法将返回false。mayInterruptRunning参数表示是否中断执行中的线程。
通过方法分析我们也知道实际上Future提供了3种功能:(1)能够中断执行中的任务(2)判断任务是否执行完成(3)获取任务执行完成后的结果。
FutureTask实现了Runnable,因此它既可以通过Thread包装来直接执行,也可以提交给ExecuteService来执行。
FutureTask实现了Futrue可以直接通过get()函数获取执行结果,该函数会阻塞,直到结果返回。
@FunctionalInterface
public interface Runnable {
/**
* When an object implementing interface Runnable is used
* to create a thread, starting the thread causes the object's
* run method to be called in that separately executing
* thread.
*
* The general contract of the method run is that it may
* take any action whatsoever.
*
* @see java.lang.Thread#run()
*/
public abstract void run();
}
@FunctionalInterface
public interface Callable {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
} 一般情况下是配合的ExecutorService来使用的,在ExecutorService的接口中声明了若干个提交方法的重载版本:
先看线程池执行器的实现逻辑

再看完整的方法:
下面通过具体的代码先演示Future
import java.util.concurrent.Callable;
import com.util.www.DateUtil;
class Task implements Callable {
@Override
public Integer call() throws Exception {
System.out.println("子线程在进行计算>"+DateUtil.getNowTimeString());
Thread.sleep(3000);
int sum = 0;
for(int i=0;i<100;i++)
sum += i;
System.out.println("子线程完成计算<"+DateUtil.getNowTimeString());
return sum;
}
} public final class DateUtil {
//返回当前时间
public static String getNowTimeString() {
Date date = new Date();
DateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String time = format.format(date);
return time;
}
//设置日期格式
public static String getNowDayString() {
SimpleDateFormat dfday = new SimpleDateFormat("yyyy-MM-dd");
String nowday = dfday.format(new Date());
return nowday;
}
}package com.current.www;
import com.util.www.DateUtil;
import java.util.concurrent.*;
public class CallableFuture {
public static void main(String[] args) {
ExecutorService executor = Executors.newCachedThreadPool();
Task task = new Task();
Future result = executor.submit(task);
executor.shutdown();
try {
Thread.sleep(1000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
System.out.println("主线程在执行任务>>>"+ DateUtil.getNowTimeString());
//System.out.println("子线程取消任务>>>"+ DateUtil.getNowTimeString());
//result.cancel(true);
try {
System.out.println("task运行结果>>"+result.get()+DateUtil.getNowTimeString());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
catch (CancellationException e) {
System.out.println("子线程已经取消任务"+ DateUtil.getNowTimeString());
}
System.out.println("所有任务执行完毕<<<"+DateUtil.getNowTimeString());
}
}
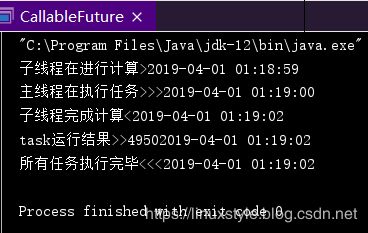
完整的输出:
这里最关键的是问题是Future只是接口,那么result.get()的在那里实现的呢?
先从这里开始:
ExecutorService executor = Executors.newCachedThreadPool();调用class Executors:

再调用class ThreadPoolExecutor extends AbstractExecutorService:

再往下执行:
Future result = executor.submit(task); 
这里实际上实例化了一个FutureTask!

再来看直接用FutureTask
代码参考:Java并发编程:Callable、Future和FutureTask
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.FutureTask;
public class CallableFutureTask {
public static void main(String[] args) {
//第一种方式
ExecutorService executor = Executors.newCachedThreadPool();
Task task = new Task();
FutureTask futureTask = new FutureTask<>(task);
executor.submit(futureTask);
executor.shutdown();
//第二种方式,注意这种方式和第一种方式效果是类似的,只不过一个使用的是ExecutorService,一个使用的是Thread
/*
Task task = new Task();
FutureTask futureTask = new FutureTask<>(task);
Thread thread = new Thread(futureTask);
thread.start();
*/
try {
Thread.sleep(1000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
System.out.println("主线程在执行任务");
try {
System.out.println("task运行结果"+futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println("所有任务执行完毕");
}
}
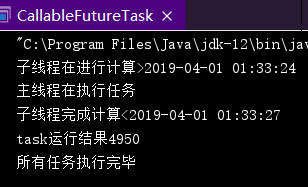
再扩展一下
import com.util.www.DateUtil;
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
public class CallableFutureTaskExt extends FutureTask {
public CallableFutureTaskExt(Callable callable) {
super(callable);
}
@Override
protected void done() {
if(isCancelled()){
System.out.println("子线程完成任务>>>"+ DateUtil.getNowTimeString());
try {
Thread.sleep(1000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
}
}
import com.util.www.DateUtil;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class CallableFutureTaskExtTest {
public static void main(String[] args) {
Task task = new Task();
FutureTask futureTask = new CallableFutureTaskExt(task);
Thread thread = new Thread(futureTask);
thread.start();
try {
Thread.sleep(1000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
System.out.println("主线程在执行任务"+ DateUtil.getNowTimeString());
try {
System.out.println("task运行结果"+futureTask.get()+ DateUtil.getNowTimeString());
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
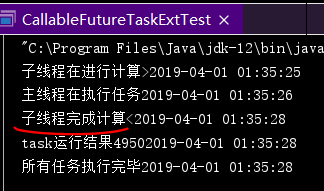
System.out.println("所有任务执行完毕"+ DateUtil.getNowTimeString());
}
}
参考《Java 7并发编程实战手册》

参考《Java多线程编程实战指南 核心篇》

FutureTask用作同步工具:
FutureTask task = new FutureTask(()-> {
System.out.println("Pretend that something complicated is computed");
Thread.sleep(1000);
return 42;
});
Thread t1 = new Thread(()->{
try {
int r = task.get();
System.out.println("Result is " + r);
} catch (InterruptedException | ExecutionException e) {}
});
Thread t2 = new Thread(()->{
try {
int r = task.get();
System.out.println("Result is " + r);
} catch (InterruptedException | ExecutionException e) {}
});
Thread t3 = new Thread(()->{
try {
int r = task.get();
System.out.println("Result is " + r);
} catch (InterruptedException | ExecutionException e) {}
});
System.out.println("Several threads are going to wait until computations is ready");
t1.start();
t2.start();
t3.start();
task.run(); // let the main thread to compute the value 这里,FutureTask用作同步工具,类似CountdownLatch或类似的障碍原语。它可以通过使用CountdownLatch或锁定和条件重新实现; FutureTask只是使它很好地封装,不言自明,优雅,代码更少。
另请注意,必须在任何线程中显式调用FutureTask#run()方法; 没有执行器为你做这件事。在我的代码中,它最终由主线程执行,但是可以修改get()方法以调用run()第一个线程调用get(),因此第一个线程到达get(),它可以是T1,T2或T3中的任何一个,将为所有执行计算剩余的线程。
参考《Java中的Future和FutureTask有什么区别?》
----------------------
《Introduction to CompletableFuture in Java 8》






《带有示例的Java CompletableFuture教程》
《Java CompletableFuture详解》
---------------------
《Java异步技术原理和实践》@小象公开课.阿里 黄健敏 2017.12
面临什么问题
每次打开手机淘宝内容首页都不一样,实时展示个性化的内容。
怎么完成这样的首页设计和技术开发。这个系统非常复杂设计成千上万个系统的。但是目前淘宝又是非常流畅,良好的技术体验会给技术带来很大的挑战。
因为做个性化,所以很多时候是不能缓存的。成千上万个系统协作实时调用。
所以技术上需要解决性能,可用性,可靠性这样的的问题。
广义上的异步也有很多种,有人考虑消息队列,那是更多的从业务级别去解决。
一般是是用消息通知去做解耦。具体方案一般是MQ,消息总线,消息中间件去完成异步。
现在在IO层面去讨论狭义层面的异步模型。
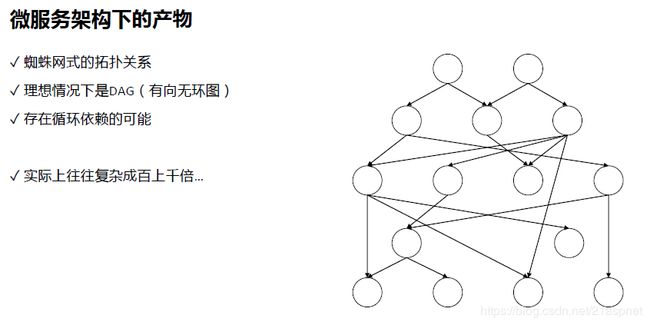
往往达不到理想情况
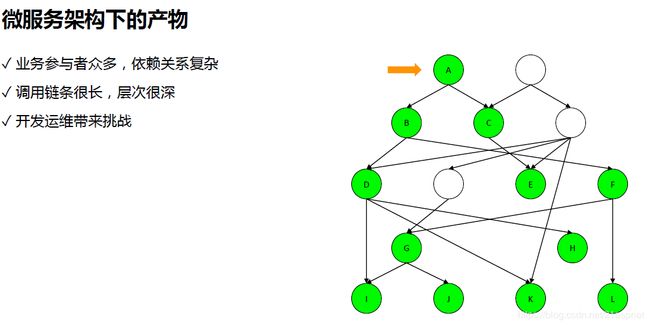
这里是相对简化的模型。实际上存现循环依赖,服务众多。
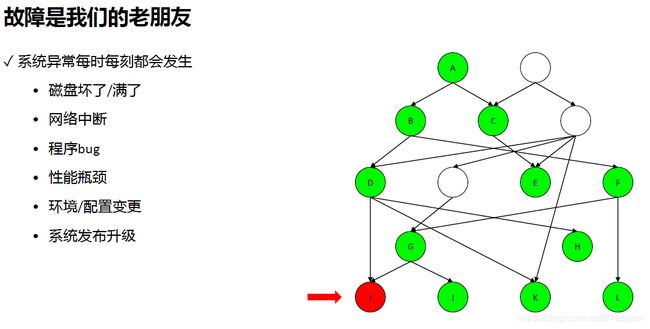

问题根源

频繁的进程切换导致CPU占用很高。
进程阻塞:锁等待,外部IO。
缓存IO:内核态与用户态的数据交换需要借助于page cache。linux会把数据缓存在文件系统的页缓存也就是page cache。
也就是说数据会被先拷贝到操作系统的内核缓冲区,再到应用程序的地址空间。
硬盘数据先预先加载到page cache后续省去对硬盘的寻道时间。缺点是数据会在应用程序的地址空间和内核之间多次拷贝。
这种拷贝会给CPU和内存带来巨大的物理开销。
fd:Linux对文件系统的抽象,包括硬盘内存,可以作为一个管道做数据交换类似的事情。
------------
《Linux系统编程、网络编程》 第9章 高级IO视频课程

标准IO是对文件IO封装得到的,不管文件io还是标准IO,讲的都是如何对文件进行读写数据。
高级IO有哪些?
(1)非阻塞IO(2)记录锁(文件锁)(3)io多路复用(I/O multiplexing)(4)异步IO(5)存储映射
本章所有的内容都与文件的IO有关(数据读写),只要涉及到文件的IO操作,就必然有文件描述符这个东西,
所有的IO高级操作,都是使用fd来实现的。 除了第5个“存储映射”外,其它高级IO操作都必须依赖fcntl函数的支持,fcntl函数很重要。
有关多路IO
(1)多路IO的工作原理
使用多路IO时,不需要多进程、多线程以“多线任务”方式实现,也不需要用到非阻塞,那么多路IO的实现原理又是什么呢?
我们以阻塞读为例,来讲解多路IO的原理。

如果是阻塞写的话,需要将文件描述符加入写集合,不过我们说过对于99%的情况来说,写操作不会阻塞,
所以一般情况下对于写来说,使用多路Io没有意义。
注意:对于多路io来说,只有操作阻塞的fd才有意义,如果文件描述符不是阻塞的,使用多路IO没有意义。
(2)多路IO有什么优势
1)多进程实现
开销太大,绝对不建议这么做。
2)非阻塞方式
cpu空转,耗费cpu资源,不建议。
3)多线程
常用方法,不过“多路IO"也是一个不错的方法。
4)多路IO
使用多路IO时,多路IO机制由于在监听时如果没有动静的话,监听会休眠,因此开销也很低,
相比多进程和非阻塞来说,多路IO机制也是很不错的方式。
异步IO的原理
前面四种方式都是主动的去读,对于read函数来说它并不知道是不是一定有数据,如果有数据就读到数据,
没有数据要么阻塞直到读到数据为止,要么就不阻塞。
异步IO的原理就是,底层把数据准备好后,内核就会给进程发送一个“异步通知的信号”通知进程,表示数据
准备好了,然后调用信号处理函数去读数据,在没有准备好时,进程忙自己的事情。
这就好比我想去澡堂洗澡,我不知道有没有位置,我去了后如果有位置我就立即洗澡(立即读数据),如果没有
位置要么等(阻塞读),要么离开过段时间再来看(非阻塞读)。
比如使用异步IO读鼠标,底层鼠标驱动把数据准备好后,会发一个“SIGIO”(异步通知信号)给进程,进程调
用捕获函数读鼠标,读鼠标的SIGIO捕获函数需要我们自己定义。
------------

读操作经历2阶段,下面4方块是外部设备,例如网络。
首先:1 等待数据准备就绪。数据从网络到操作系统内部,文件到pagecache,内存到pagecache.
2. 内核态的 pagecache 拷贝到用户空间。
反向过程也是类似的。
实际操作层面很少会用到信号驱动IO和异步IO。
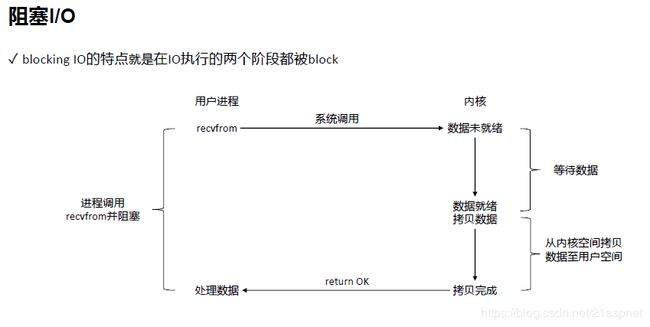
两阶段都被阻塞。 recvfrom理解为商品请求。 经过网络数据是断断续续的,也就是需要的数据不能马上得到。
这个过程只要发起recvfrom调用就会阻塞挂起,内核由于没有收到数据就会等待数据的到位。等待阶段会阻塞用户进程。
再经过某段时间,条件达到,数据回来了,数据就绪,内核把数据从内核态拷贝到用户态。
在这个过程把数据从内核空间拷贝到用户空间也是要等待的,这就是第二阶段。
这2个步骤都完成以后数据可以返回到进程态。这时候进程拿到数据做相关处理,阻塞IO结束。

需要不停的轮询内核数据是否准备好。即使数据准备好也会和阻塞IO一样的阻塞直到完成拷贝数据到用户空间。
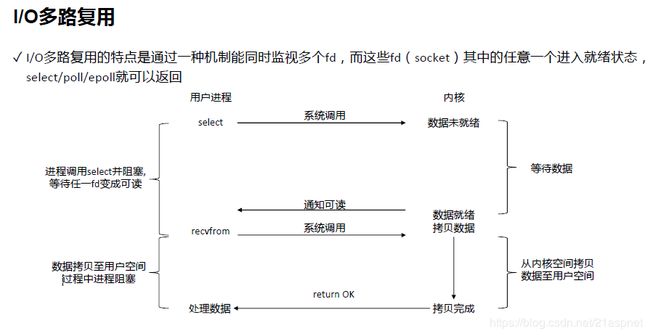
fd:文件/socket。有数据可以读写,内核会返回通知。
recvfrom也会经历阻塞过程 内核态到用户空间拷贝.
只要1-2个线程监听系统调用,可以处理非常多的连接FD,只要有事件通知就事件就绪。给后续线程处理。

蓝底表示一个线程去完成,阻塞IO完成。如果没有数据这个线程会挂起。
如果更多的请求发送读取需要各自占用专用线程。

如果这个系统是其他系统依赖会导致一个系统出问题影响整个系统。
同步模型并不是不好,在正常情况下表现还是很优异的,同步模型质量相对可控。

但是同步模型带来的缺点是当阻塞调用导致系统资源无法释放的时候,整个系统利用率很低。
异步化处理
在做IO阻塞的时候为什么服务质量上不去,整个吞吐比较差,主要也是因为我们在做IO操作尤其是阻塞操作的时候系统资源尤其是线程资源得不到释放,线程占用了资源,但是它读不了更多的请求。

可以借助IO多路复用的这种概念去做,在介绍IO多路复用的时候也提到说线程对调用方来说是线程阻塞的。
所以一般会采取少量的线程对IO多路复用这样的select模型进行阻塞的调用。
关键一点就在于我们的请求发出以及接收都不会占据调用的线程。
比如对请求进行发送的时候不是在真正做阻塞IO调用,而是把数据进行封装,丢到一个任务队列里,由这样一个主要的线程把数据拿出来,然后找一个可用的FD,把数据写在FD里,再进行网络传送。
再由网络传送拿到回来之后,产生对应的事件。去把数据解包到另一个队列里。再通知应用使用方继续处理。
这里只是一个例子,并不是说所有的网络模型或者网络框架都会这样去做,但是一般来说这样做还是比较广泛的。
回到刚才的问题,为什么多路复用可以解决线程占用的问题呢?
主要是通过类似这样的方式来进行解耦,当我把需要发送的数据往队列里放好,实际上对这个线程是可以结束它的当前工作,因为我去下一步就是需要等待数据回来,即使数据没有回来也没有必要在这里等待。线程实际上可以释放出去。
等到我的数据回来了会接收到通知:“数据就绪”,系统再去轮询进行调度等到有效的线程去获取我对应的数据在进行相关的处理。
这是单一请求的一个实例,实际上这两个断开的线程是在处理单一的请求,只是在中间的过程里可以把线程释放出来。
当有更多的请求要去访问的时候,我们可以利用类似的过程把我们的系统的线程资源释放出来。
在最终数据回来的时候两个处理过程否需要由可执行的单元也就是我们可以利用线程来进行我们对应的处理。
但是我们的线程实际上是可以复用的,在另一个请求线程是可以复用的。所以可以把线程当作是CPU资源利用的一个媒介载体。

此图是对刚才的概念的另一个表述方式,即使下游系统出现异常,上游系统的资源可以释放出来,执行其他的任务的。

在刚刚的IO阻塞的例子里,如果当前系统的负载很高,由于下游系统的奔溃导致服务无法响应的时候,其他不相干的请求也会受到拖累,那是因为这个系统资源以及被占用,没有更多的资源去服务。
但是如果我们用这样的IO多路复用模型把阻塞给释放出来,这样系统的资源还有更多的空间处理正常的请求,而其他不相干的服务也不会受影响。

在使用同步的时候,我们往往会比较小心的去设置两个系统的超时设置,如果设置太长可能会在流量高峰的时候会导致系统马上崩溃。超时设置太短,会导致下游系统其实是正常的也会产生一些异常。
用了异步以后可以大胆的把异步的时间设置的长一些,一方面是可以把线程的占用释放出来,不会占用系统太多的调度资源。
主要是把IO的整个阻塞释放出去。 所以允许下游系统的成功率低一点,也不会对上游系统造成太大的影响。
假定当前的系统整个QPS是3000,但是实际上利用的资源实际上是非常高的。
但是我们利用了异步这样的方式我们可以在同等的吞吐之下可以把资源利用的更好,甚至可以把空余的资源利用起来服务其他的请求。

做异步不是为了提高单个请求的响应速度。
同步调用不会涉及线程的上下文切换,也不会涉及更多的资源调度,而做了异步处理都会有这些额外的开销。
异步导致的临时对象会导致JVM内存压力更大,更多的GC导致系统受到额外的影响。
同步就不会在乎TCP层是怎么做的,线程的调度是怎么做的,系统资源加锁,多线程对一些临界资源的同步编程。
做异步的时候会频繁的做线程切换,会把线程抽取出来成为一个计算资源,所以他是公共服务的这样一个过程,所以这里Threadlocal就不可用。
如果要做异步不能简单的把一个方法调用或者把请求丢进线程池回来一个异步的对象就称之为异步的,
如果要做到极致是要对整个系统的调用链进行分析和排查,会找到潜在的问题可以IO异步改造的地方进行异步改造,系统的整个链条都要重构。

以淘宝首页为例它可能是聚合成百上千个接口来完成的,需要很多的外部服务交互,是IO密集型。
如果一个系统是要做科学计算,很消耗系统资源,这时候很难利用异步提高系统性能。
NodeJS也是适合IO密集型,对计算密集型也是无能为力的。
做异步化改造整体吞吐量上去了,当流量高峰来的时候会对下游系统带来很大的冲击,只会使得后端更糟糕。
这时往往需要使用熔断,限流,恢复故障的机制。调用链的跟踪技术也要改造。
一般大型系统都会在请求的时候进行跟踪以方便度量系统,往往这种技术采用的是threadlocal方案,依赖threadlocal传递的信息会变得很困难甚至不可用。
引入异步增大系统开销,所以需要引入一些系统的自我保护,功能降级。
mysql/nosql需要依赖TCP网络的有序性做协议的设计。
mongodb,HTTP2在协议曾增加了对异步的支持,一般会给请求附加一个requestID,允许打乱过程的请求和响应可以匹配的上。
 Spring提供的这种方式实际上也只是在spring框架内部提供给他自己使用的。一般不采用。
Spring提供的这种方式实际上也只是在spring框架内部提供给他自己使用的。一般不采用。

 实际工作中这个使用较多,建议关注。
实际工作中这个使用较多,建议关注。




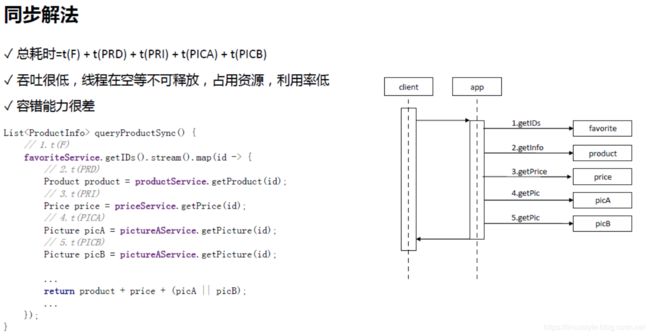
 只要有一个系统崩溃会导致更严重的问题,因为会占用更多的线程去服务单一的请求。
只要有一个系统崩溃会导致更严重的问题,因为会占用更多的线程去服务单一的请求。
