逆向 C++-- 识别类及其构造函数
逆向 C++
这些年来,逆向工程分析人员一直是凭借着汇编和 C 的知识对大多数软件进行逆向工程的,但是,现在随着越来越多的应用程序和恶意软件转而使用 C++语言进行开发,深入理解 C++ 面向对象方式开发的软件的反汇编技术就显得越发的必要。本文试图通过分析在反汇编时如何手工识别 C++对象,进而讨论如何自动完成这一分析过程最终介绍我们自己开发的自动化 工具,一步一步的帮助读者掌握逆向 C++程序的一些方法。
作者:Paul Vincent Sabanal
Mark Vincent Yason
译者:[email protected]
I.引言和必要性
对于逆向工程分析人员来说,能从一个二进制可执行文件中识别出 C++程序
的结构,并且能标识出各个主要的类,以及这些类之间的关系(继承、派生等)
是非常重要的。为了能做到这一点,逆向工程分析人员就必须要
(1) 能识别出这些类
(2) 能识别出这些类之间的关系
(3) 识别出类中的各个成员
本文就是 要教大家能做到上述三点。首先我们先来讨论如何手工的分析一个 C++程序编译的二进制可执行文件,从中提取出有关的类的信息。然后我们再来讨论如何自动化这一手工分析的过程.
当然,要做到这一点需要你花上不少的功夫学习很多技巧,但是为什么我们要学习并掌握这些东西呢?我认为有下面这三点理由要求我们这么做:
1) 用 C++开发的恶意软件越来越多了
跟据我们分析恶意软件的经验,现在我们要分析的恶意软件中使用 C++开发的恶意软件越来越多了。你知道,把这些恶意软件扔到 IDA 里去进行静态分析的难度会比较大,因为相对于 C 中的直接函数调用而言,静态分析 C++中的虚函数调用就比较困难,因为 C++中的调用虚函数是采用间接调用的方式,有时你甚至都能难确定某个函数是否被调用过。比如臭名昭著的 Agobot 病毒就是用 C++写的,另外我自己的蜜罐里最近也捕获了一些新的 C++写的恶意软件。
2) 用 C++开发的现代的应用程序也越来越多了
随着操作系统和应用程序的规模和复杂度的与日俱增,C++越来越受软件开发人员的青睐。这也导致了在漏洞发掘等逆向工程任务中面对 C++语言编写的软件的可能性也就越来越大。所以逆向分析人员必须要掌握 C++相关的逆向工程技术
3)关于 C++的逆向工程资料极少
我们相信把 C++的逆向工程资料整理成册,提供给逆向工程分析人员是一件功德无量的好事,因为这一方面的资料是在是太少了。(译注:在《黑客反汇编揭密》一书中有部分讨论)
注意:本文中讨论的 C++可执行文件仅限于使用 Microsoft Visual C++编译器编译出的 C++可执行文件.
2.手工方法
这一节, 主要讨论手工分析 C++可执行文件的方法。主要讨论如何识别类及 其成员(变量,函数以及构造函数和析构函数) 以及类与类之间的关系。
A. 识别类及其构造函数
要识别出类的成员及类与类之间的关系,我们首先要把各个类给识别出来,所以我们先来识别类及其构造函数。我们可以通过下列特征从一个可执行文件中 把类和它的构造函数识别出来:
1) 大量的使用 ECX 寄存器(作为 this 指针)。我们应该首先注意到的是在反汇编代码中会大量出现使用 ECX 寄存器(用来传递 this 指针)的情况。如下图,我们看到在给 ECX 寄存器赋值之后,马上调用了一个函数。 
另外,我们在函数中可能会经常看到 ECX 寄存器还没有初始化就直接被使用的情况(如下图),这时我们基本上就可以猜出来:这个函数应该就是某个类的成员函数。

2)调用约定。这一点与 1)有关,类的成员函数在被调用时基本上是把函数的参数压入栈中,而使用 ECX 传递 this 指针。如下面这个例子,在为类新建了一个对象之后,new 返回的指针(该指针指向分配给对象的地址)EAX 的值马上被传给了 ECX,然后就调用了构造函数。 
另外,我们有时还会遇到一些间接函数调用,这很可能是调用类的虚函数,当然,在静态分析的情况下(即不是在调试器中进行动态分析)如果不是事先明确的知道这个虚函数是哪个类的,要深入跟踪这个虚函数还是很困难的。我们考虑下面这个例子:

在这个例子里,我们首先要知道 ClassA 的虚函数表(virtual function table)在哪里,然后才能根据虚函数表来确定虚函数的代码所在的位置。
3)STL(标准模版库 Standard Template Library)中的代码和可执行文件导入的 DLL。另外,如果我们在检查二进制可执行文件时发现这个可执行文件使用了 STL 中的代码,这一点可以通过分析可执行文件要求导入的函数或者通过 IDA 的 FLIRT 之类的库签名识别方法来做到: 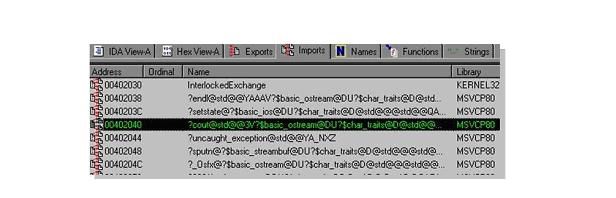
下面是调用 STL 中的代码的情况:
类的实例
在我们进一步深入讨论之前,逆向工程分析人员还应该熟悉对象(或者说一个类的实例)在内存中是个什么样子,说的文绉绉一点就是类在内存中的布局情况。我们先来看一个简单的类:

这个类在内存中是这个样子的:

|
最后一个类的成员变量后面有 3 个字节的填充,这是因为要求 4 字节对齐。 在 Visual C++中,类的成员变量是按照其声明的大小依次排列在内存中的。 看 PPT 里的更清楚一点:

那么怎么才能得到上面这张图呢? 我们可以使用-d1reportAllClassLayout 这个编译开关,它可以让 MSVC 编译器(译注:至少是 MSVC 6.0 以上的版本)生成一个.layout 文件,在该文件中包含有大量的极具价值的类的布局信息,包括基类在派生类中的位置,虚函数表,虚基类表(virtual base class table 我们下面会深入讨论),类的成员变量等信息(实际上我们这些图表都是从.layout文件中取出的)。
那么,如果在一个类中含有虚函数呢?

下面是这个类在内存中的存在形式:

注意指向虚函数表的指针(vfptr)是被添加在最前面的,而在虚函数表里面,各个虚函数是按照其声明的顺序排列的。类 Ex2 的虚函数表如下:
下面这个图是 PPT 里的更清楚一点:
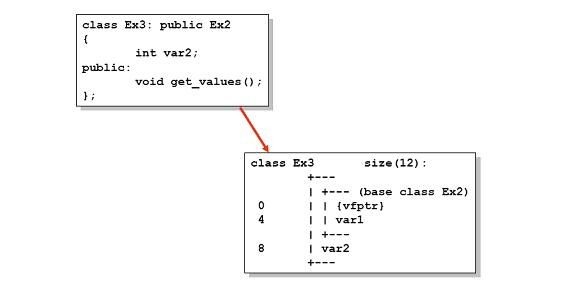
当一个类是继承另一个类的话,情况又会怎么样呢? 下面讨论一个简单的单一继承关系

| 在内存中这个类的情况是这样的: |

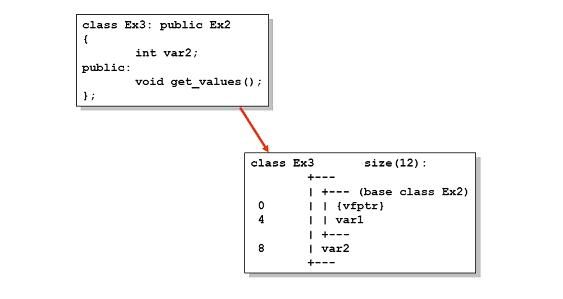





表。但是请注意,第一个基类的虚函数表是被派生类共享的,派生类的虚函数将
会被例在基类虚函数表的后面。另外要注意的是,因为 Ex5 中也有一个和 Ex4
的虚函数同名的 func1(),所以根据 C++的规则,Ex4 虚函数中的 func1()函数的
指针已经被 Ex5 的 func1()的函数指针给替换掉了。