前端修炼——Node.js(一)
最近在学习 Node,看的是朴灵老师编著的《深入浅出Node.js》。这本书和我看过的其他技术类书籍有些不同,书中不仅讲解了 Node 的历史,发展,特点,应用场景等等。还说明了很多原理,让我有一种“我靠~原来是这样实现的啊!”,恍然大悟的感觉。作为一名前端程序猿,也经常使用比如 webpack、gulp、vue-cli …这些自动化的前端工具,他们的开发或环境也是基于 node啊,通过这本书理解了很多之前并不是很理解的问题。Node 的横空出世也将前端推上了巅峰,感谢朴灵老师和其他本书的支持者,能让我更好的学习 Node!

因为我本身是一名前端开发人员,所以对 Node 学习和理解,基本是从前端角度去理解的,如果有错误或误解的地方,欢迎各位及时指出更正。
Node 给 JavaScript 带来的意义
我们知道浏览器中除了 V8 作为 JavaScript 的引擎外,还有一个 WebKit 布局引擎(这个还不太清楚),HTML5的发展中,定义了更多更丰富的 API ,浏览器提供了越来越多的功能暴露给 JavaScript 和 HTML 标签。但长久以来,JavaScript 被限制在浏览器的沙箱中运行,它的能力取决于浏览器的中间层提供的支持有多少。也就是一直受浏览器限制,做不了啥“大事”,不能访问本地文件,不能操作数据库。
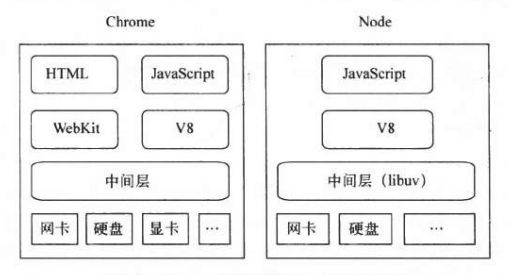
但是在 Node 中,JavaScript 可以随心所欲的访问本地文件,搭建服务器端,连接数据库。而且 Node 的语法和 JavaScript 的语法是一样的,也就是说 JS 代码,可以实现后端的一些功能,这就牛X了有没有。
Node 的特点
Node 的特点有三个:
- 异步 I/O
- 事件与回调函数
- 单线程
其实了解了这三个特点后,你会觉得这三个差不多是一个特点,只是不同阶段的不同特征。
异步 I/O
作为前端工程师,对于异步的理解可以说的小菜一碟了,例如我们和 Ajax 基本是抬头不见低头见了:
$.post('url',{title:'深入浅出Node.js'},function(data){
console.log(111);
});
console.log(222);
前端开发的肯定知道,“111”是在“222”之后输出的。在 Ajax 执行以后,是直接向下执行“222”的,并不会等待 Ajax 执行完,只知道“111”会在请求成功之后才执行,但具体时间未知。这就是一个典型的异步 I/O 操作。
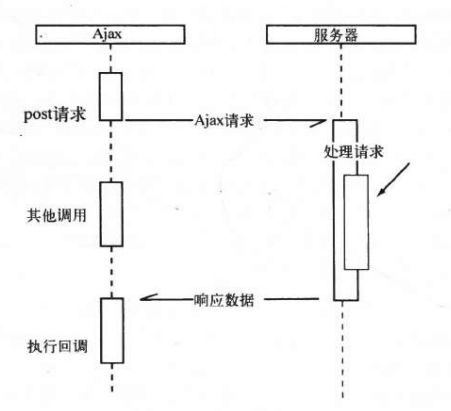
在 Node 中异步调用和 Ajax 基本差不多,以读取文件为例:
var fs = require('fs');
fs.readFile('path',function(err,file){
console.log(111);
});
console.log(222);
这里的**“111”也是在“222”**之后输出的。

在 Node 中绝大多数的操作都是异步调用的,这样极大的提升了效率。
事件与回调函数
前端开发中,回调函数无处不在,Node 中也是如此。从上面的例子可以看出,Ajax 中 success 就是回调。除了异步和事件外,回调也是 Node 的一大特色。
单线程
Node 保留了 JavaScript 在浏览器中单线程的特点。单线程的最大好处是不用担心多线程中的状态同步的问题,Node 中没有死锁的存在,也没有线程上下文交换带来性能上的开销。
但是单线程也有缺点:
- 无法利用多核 CPU
- 错误会引起整个应用崩溃,健壮性不足
- 大量计算占用 CPU 无法继续调用异步 I/O
后面,书中也讲解了如何避免这些弱点,更高效的使用 Node.js。
Node 应用场景
说到应用只有两种结果,适合与不适合。探讨较多的就是 I/O 密集型和 CPU 密集型。
I/O 密集型自然不用多说,Node 对 I/O 的处理能力还是很6的。至于计算方面的 CPU 密集型,有两种方法:
- 通过编写 C/C++ 扩展模块,充分利用 CPU
- 通过子进程方式分担计算任务
这里有一句精华:CPU 密集不可怕,如何合理调度是诀窍!
上面的内容是从大体上了解 Node,它的特点和应用场景。下面将会从各个相关模块,来深入认识 Node,以及各方面的实现原理。

模块机制
CommonJS 规范
CommonJS 规范为 JavaScript 制定了一个美好的愿景——希望 JavaScript 能在任何地方运行。
CommonJS 规范的提出,主要是为了弥补后端 JavaScript 没有标准的缺陷,已达到像 Python,Ruby 和 Java 具备开发大型应用的基础能力,而不是停留在小脚本程序的阶段。让它不仅可以开发客户端应用,还可以开发:
- 服务器端 JavaScript 应用程序
- 命令行工具
- 桌面图形应用程序
- 混合应用
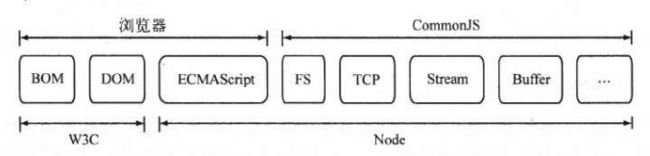
CommonJS模块规范
主要分为:模块引用,模块定义,模块标识 3个部分。
require('moduleName')引入模块。
exports.moduleNameexports 对象用于到处当前模块的方法或变量,是唯一的导出出口。
模块标识就是传递给 require()方法的参数,它必须是小驼峰命名的字符串,或者相对路径,或绝对路径,可以省略 .js 后缀。
每个模块具有独立的空间,块之间互不干扰。
require 的寻找机制,是沿路径向上逐级递归,直到根目录下的 node_modules 目录。
文件扩展名分析
require 在分析标识符的过程中,如果没写上文件扩展名,Node 会按 .js .node .json 的顺序依次尝试。
在尝试的过程中,需要调用 fs 模块同步阻塞地判断文件存不存在,这样会引起性能问题。小诀窍就是:如果是 .node 或 .json 结尾的文件,引入时名称就不要省略后缀了,加上就 OK 啦。
目录分析和包
如果 require() 引入时,写的不是文件名,是目录名,此时 Node 会把目录当做是一个包来处理,然后在当前目录下查找 package.json 文件,通过JSON.parse()解析出包描述对象,从 main 属性指定的文件名进行定位。
如果连 package.json 文件都没有,Node 会将文件名默认为 index ,依次查找 index.js ,index.node ,index.json 文件。
如果找了一圈这些也没找着,那 Node 可就不乐意了,就该给你扔个错误出来了(not found module…)。

JavaScript模块的编译
有几个疑惑点,每个模块里都存在 require,exports,module 这3个变量,但是在模块中并没有定义,他们从何而来?
还有在 Node 的 API 文档中,每个模块还有 __filename,__dirname 这两个变量,他们又从哪来的?
原因是,在编译过程中,Node 对获取的 JavaScript 文件内容进行了头尾包装。在头部添加了“(function(exports,require,module,__filename,__dirname){\n”,在尾部添加了“\n})”。
(function(exports,require,module,__filename,__dirname){
var math = require('math');
exports.area = function(radius){
return Math.PI * radius * radius;
};
});
也就是 Node 把引入的 js 文件内容包在了一个函数里,这样就形成了一个封闭作用域,不会对其他模块造成污染,这就是 Node 对 CommonJS 规范的实现。
还有就是为何存在 exports,也存在 module.exports,给 exports 赋值却失败的情况。
exports = function(){
// 这样是不行的
};
原因在于,exports 对象是通过形参方式传入的,直接赋值会改变形参的作用,但并不能改变作用域外的值。
var change = function(a){
// 直接使用exports.a更改相当于在这里改a的值,改不了外面的a
a = 100;
console.log(a); // 100
};
// 使用module.export.a 就可以改这个a的值
var a = 10;
change(a);
console.log(a); // 10
核心模块
Node 自带的模块就是核心模块。
核心模块分为 C/C++ 编写 和 JavaScript 编写 两部分。由 C/C++ 编写的模块也叫做内建模块。
在编译 C/C++ 文件之前,会把 JavaScript 模块文件编译成 C/C++ 代码,将所有内置的 JavaScript 代码转换成 C++ 里的数组,JavaScript 代码以字符串形式存储在 node 命名空间中。(此时是不可执行的)
Node 执行时,JavaScript 核心模块,经过 头尾包装 后导出,得以引入。(此时是可执行的)
内建模块会编译成二进制文件,一旦 Node 执行,它们会直接加载进内存当中,直接就可执行。
在 Node 所有的模块类型中,存在着一种依赖关系,即文件模块可能依赖核心模块,核心模块可能依赖内建模块。 (文件模块即第三方自己下载的模块)

通常,文件模块不推荐直接调用内建模块。如需调用,直接调用核心模块即可。
Node 在启动时,会生成一个全局变量 process,并提供 Binding() 方法来协助加载来加载内建模块。所以核心模块中基本都封装了内建模块。
核心模块引入流程
为了符合 CommonJS 模块规范,从 JavaScript 到 C/C++ 的过程是很复杂的,它要经历 C/C++ 层面的内建模块定义、(JavaScript)核心模块的定义和引入、(JavaScript)文件模块层面的引入。
但是使用 require()就十分简洁、友好了。
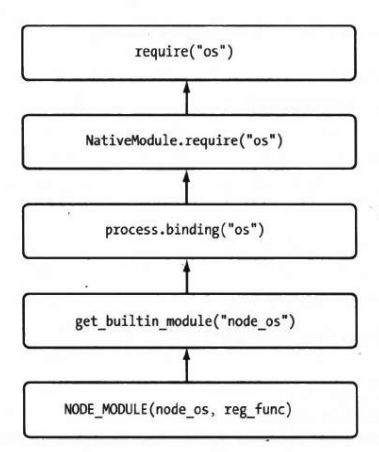
编写核心模块
本人功力还不到火候,这一节就直接跳过了,有能力的朋友可自行研究啦。

模块调用栈
C/C++ 内建模块属于最底层模块,它属于核心模块,主要提供 API 给 JavaScript 核心模块和第三方的文件模块调用。
JavaScript 核心模块主要有两个职责:
- 作为C/C++ 内建模块的封装层和桥接层,供文件模块调用
- 纯粹的功能模块
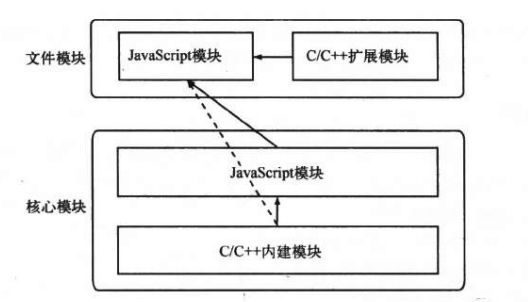
文件模块就是第三方模块,自己编写的模块,不要被它搞晕呦。
包与NPM
Node 有自带的模块,但是开发中肯定不够用啊!所以有世界各地大牛们自己开发了很多的包,但是第三方的包是分散在世界各地的,相互不能引用。这时候,包和NPM就发挥作用了,它就是将模块联系起来的一种机制。

CommonJS 的包规范有两个部分:
- 包结构:组织包中的各种文件

- 包描述文件:包的相关信息(就是那个package.json文件)
NPM 常用功能
我经常使用的就是npm install 包名称 -S下载一些包,npm run dev 执行一些命令,具体其他更多功能可以百度一下啦(太懒了太懒了)。
Node 通过 CommonJS 规范,组织了自身的原生模块,弥补 JavaScript 弱结构问题,形成了稳定的结构,并向外提供服务。
NPM 组织了第三方模块,使项目开发中的依赖问题得到解决,借助第三方开源力量,也发展了自己,形成一个良性的生态系统。
未完待续。。。。。。
文章只是本人学习 Node 过程中,按自己的理解总结的一些笔记,若有错误之处,欢迎各位及时指出,一起探讨。

微信搜索公众号:前端很忙
做一个喜欢分享的前端开发者!
获取更多干货分享,欢迎来搞!