黑科技: 高性能计算BurstBuffer技术详解


Burst Buffer是什么技术,它跟HPC有什么关系?首先我们一起来了解一个美国超算中心NERSC(国家能源研究科学计算中心),然后通过NERSC超算系统和Burst Buffer应用来说说Burst Buffer技术。
NERSC一直与Cray(克雷)合作,为Cori (Cori 是 NERSC最新的大型计算系统) 的用户和应用提供Burst Buffer技术。 NERSC Burst Buffer是采用Cray DataWarp技术,其本质是使用闪存或SSD技术来显着提高Cori的I/O性能。

NERSC致力于通过高性能计算和数据分析加速美国能源部科学探索,并向科学办公室提供高性能计算服务。NERSC的使命是实现规模的计算科学,需要大量计算和广泛建模。包括光合作用建模,全球气候建模,燃烧建模,磁性融合,天体物理学,计算生物学等等,这些场景都存在浪涌型IO高性能诉求。

为什么需要Burst Buffer
NERSC为了满足用户对更好的I/O性能的要求,已经在多个计算系统采用了Burst Buffer技术。采用Burst Buffer,可以改进两个场景的I/O性能。
1.改善应用程序可用的总带宽。带宽越高,经过优化的应用程序可以在单位时间读取/写入大量数据越多,速度越快。
2.提升文件系统的OPS。HPC场景,有许多应用程序要执行大量的小型I/ O操作,在这种情况下OPS成为性能的限制因素。
另外,Burst Buffer技术通过更快的checkpoint restart提高应用程序可靠性;加快了小块传输和分析的I/O性能;为核心外部应用程序提供快速临时空间;为需要持久快速存储的大量文件输入或耦合模拟分析作业创建暂存区域。
Burst Buffer架构
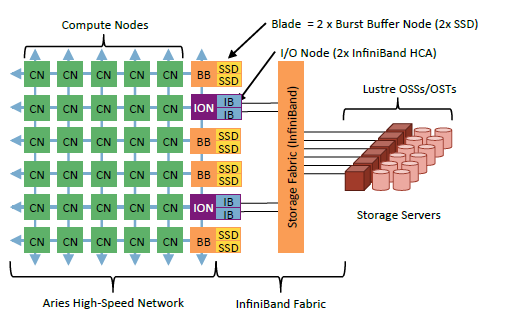
下图说明了Burst Buffer的概念架构。Burst Buffer在物理位置上是处于计算和存储节点之间,本质是一层Flash层。在Cray DataWarp方案中,它承载在专门的XC40计算硬件节点上,它是I/O计算节点(采用Aries互联)和存储Fabric的桥梁。SSD安装在Burst Buffer节点中,通过Scheduler和DataWarp软件堆栈来调动和支持HPC计算作业。
Burst Buffer节点内部的SSD通过PCIe连接,插入到计算刀片XC40中,并通过Aries HPC互连连接。DataWarp支持Lustre、GPFS和PanFS并行文件系统,给FS提供一个全局的Flash缓存层,通过智能调度算法来从下层并行文件系统预取计算数据。
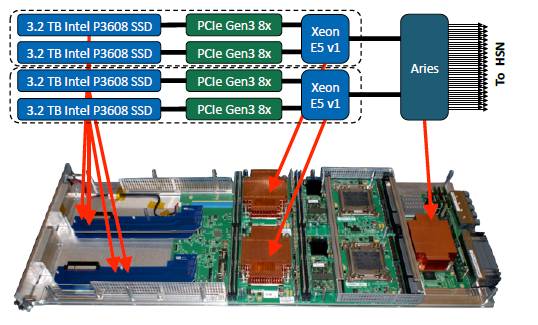
Cray DataWarp(BB)的闪存磁盘连接到XC40节点。每个Brust Buffer节点包含一个至强处理器64 GB DDR3内存,以及两个3.2 TB NAND闪存SSD模块,连接在两个PCIe gen3 x8接口上。 每个Burst Buffer节点通过PCIe Gen3 x16接口连接到Cray Aries网络互连。 每个Burst Buffer节点提供大约6.4 TB的可用容量和大约5.7 GB/s的顺序读写带宽的峰值。

DataWarp的软件堆栈包括:创建挂载点服务、LVM卷,XFS和DataWarp文件系统。DataWarp中的多个SSD设备通过LVM管理起来,然后在创建Brust Buffer时创建XFS组成Brust Buffer空间,DataWarp File System (DWFS)配合安装在计算节点的Client来协调数据在Brust Buffer上换入换出,并且向计算节点提供统一命名空间来进行数据访问。
这种架构提供了许多适合NERSC的科学Workload的特性。在技术上主要体现在以下几个方面。
调度程序集成。对Burst Buffer资源的访问与系统的调度程序集成。 调度程序提供了调配一组用户或作业共享的BurstBuffer资源的功能。它还可以处理自动数据迁移到BurstBuffer,或从BurstBuffer存储迁移到后端存储。
缓存模式。BurstBuffer还可以提供缓存模式,其中闪存资源用作大型Lustre文件系统的缓存层。这种模式对用户程序代码是透明的,无需修改代码便可提供高性能I / O。
过滤分析。允许在BurstBuffer节点上处理和过滤数据。
NERSC的Burst Buffer路标
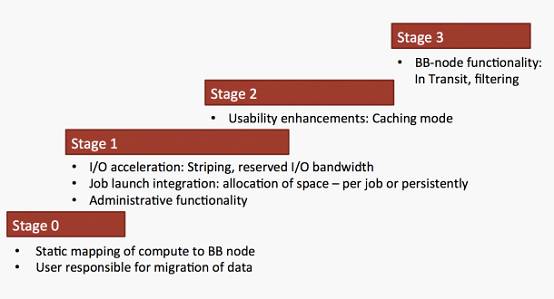
Burst Buffer软件堆栈预计将分四个阶段交付(如下所示):Burst Buffer软件的第一阶段是在2015年秋季与Cori系统的第一阶段一起交付的。
第一阶段,Burst Buffer为每个计算任务分配持久存储预留;
在第二阶段才能实现Cache模式;
到了第三阶段,BurstBuffer才能真正实现基于算法的冷热数据自动换入换出加速。
在2015年8月完成了对Burst Buffer Early Access计划的建议征集。
DataWarp软件在第1阶段提供了使用Burst Buffer的API。用户通常通过批处理系统(即slurm)与此接口以定义突发缓冲区分配,例如大小和访问模式(条带化),并指定预留是否应该是持久的。Burst缓冲区可用于所有Cori用户,BurstBuffer在Cori系统上,可以提供大约1.7 TB/秒的峰值I/O性能,具有28M IOP和大约1.8PB的存储容量。
Cray的HPC方案
Cray也是HPC领域的领头羊,他和DDN、Xyrate和PanaSas等并驾齐驱。Cray的XC40和CS400超级计算机使用Haswell处理器和DataWarp BurstBuffer技术,采用并NVIDIA Tesla GPU加速器和英特尔至强融核协处理器,以带来更强的图形处理能力。

Cray XC系列计算服务器包含XC40计算、XC50 GPU节点和XC40-AC制冷系统,XC40基于Intel Aries ASIC系统连接XC40基本刀片上的计算和I / O节点,使用PCIe Gen3主机接口,所有处理器采用Aries网络都彼此相连。
XC40可以扩展到超过一百万个内核。该架构针对每个计算节点实现两个处理器引擎,每个刀片具有四个计算节点。刀片以8对(16个机箱)堆叠,每个机柜最多可以安装三个机箱,每个机柜384个插座。
CS400集群超级计算机使用行业标准刀片式或机架式服务器,并分别在CS400-AC和CS400-LC系统上提供空气或液体冷却。它们可扩展到11,000个计算节点和40个峰值Peta Float/s。

Cray CS400集群提供两个关键的能力,即可定制的HPC集群软件堆栈和Cray的高级集群引擎(ACE)系统管理软件。

HPC群集软件堆栈包括经过验证和测试的软件工具、操作系统、中间件应用程序和HPC编程工具。这些工具与大多数开源和商业编译器,调试器,调度程序和库兼容。Cray编程环境,Cray科学和数学库以及Cray性能测量和分析工具也可作为软件堆栈的一部分。
Cray Sonexion 3000 scale-out Lustre存储系统提供了Scrach存储空间,用来存储大量初始数据和计算结果数据,DataWarp Brust Buffer是一个应用程序IO加速器,使用PCIe闪存直接连接到XC40计算节点。它从存储中获取数据,满足最糟糕的数据I/O浪涌临时高速缓存需求。
其他的Burst Buffer产品
除了Cray外,DataDirect NetWorks、IBM和EMC都在研究Burst Buffer技术。
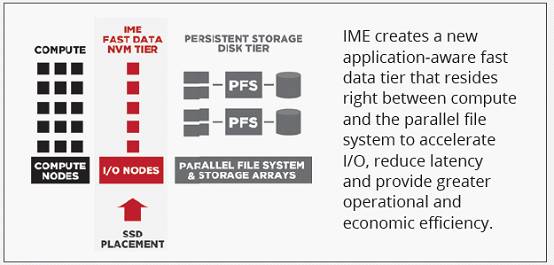
DDN的IME Burst Buffer方案是IME (Infinite Memory Engine)。通过IME设备智能缓存或预读数据,可以提供计算峰值业务负载要求,分离峰值和平稳业务性能需求,降低存储在满足峰值业务诉求的投资。
IME交付方式包含IME14KX、 IME240和纯软件产品和基于存软件方式(DDN提供了一种软件定义防止厂商锁定的交付模式)。
关于EMC,我们知道Isilon一直活跃在HPC和大数据处理领域,推出Isilon All-Flash节点作为其他节点的高速缓存,针对一般的HPC计算已经游刃有余。
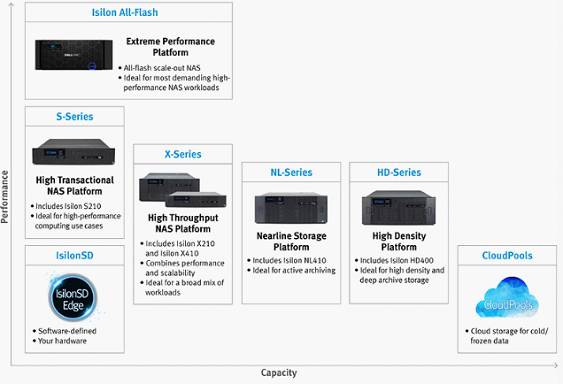
EMC的Burst Buffer方案采用专用硬件设备,叫做Active Burst Buffer Appliance(aBBa),从EMC的测试来看,采用Burst Buffer后,不但均衡分担了系统性能,而且在整体计算性能上可以提升30%。aBBa支持的并行文件系统比较广泛,包括了Lustre, Isilon, PanFS, HDFS和VNX等。

EMC Burst Buffer架构(Fast Forward IO)和Cray DataWarp以及DDN的IME在架构上类似,服务器计算节点安装IO Forwarding Client和aBBa交互,智能的根据算法加速或预取数据,并存储临时计算数据;在aBBa上IO Dispatcher处理数据分布,并且把aBBa上的NVMe磁盘进行管理,由IO Forwarding Server统一呈现给IO Forwarding Client。

在aBBa上需要安装Lustre客户端用来读取并行文件系统上的数据,并根据数据模型和预取算法把数据加速到aBBa,或淘汰数据到后端并行文件系统。
针对浪涌型计算业务,Burst Buffer更好的平衡存储投入成本和性能要求,采用较少的SSD提供高峰时的计算性能,当业务在波谷时,则可以由并行文件系统来提供带宽服务。随着SSD NAS在HPC行业的大规模使用,也预示着SSD除了在OLAP、OLTP数据库、VDI等IOPS型关键业务应用外,也在迅速的渗透到其他水平行业,如带宽型业务,标志着SSD未来在大容量和高性能(IOPS、OPS和带宽等)NAS应用有着广阔的前景。
更多Burst Buffer和HPC技术已经梳理成“高性能计算(HPC)技术、方案和行业全面解析”电子书,请点击“原文链接”查看详情(目录如下)。
第1章 HPC行业和市场概述 1
1.1 HPC主要场景和分类 2
1.2 HPC系统主要组成 11
1.3 HPC IO业务模型 12
1.4 HPC系统架构演变 13
1.5 HPC市场的主流玩家 14
1.5.1 HPC存储厂商分类 15
1.5.2 Burst Buffer介绍 15
1.5.3 Panasas和Seagate介绍 17
1.5.4 主流并行文件系统 17
1.6 HPC对存储的主要诉求 19
1.7 HPC系统的衡量标准 20
1.8 HPC未来的技术趋势 22
第2章 HPC场景的存储形态 23
2.1 HPC为何是NAS存储 23
2.2 本地存储引入的问题 23
2.3 HPC主要的存储形态 25
第3章 Lustre文件系统解析 26
3.1 Lustre文件系统概述 26
3.2 Intel Lustre企业版开源策略 26
3.3 Lustre文件系统架构 27
3.4 Lustre Stripe切片技术 30
3.5 Lustre 的IO性能特征 34
3.5.1 写性能优于读性能 34
3.5.2 大文件性能表现好 35
3.5.3 小文件性能表现差 35
3.6 Lustre小文件优化 36
3.7 Lustre性能优化最佳实践 38
第4章 GPFS文件系统解析 39
4.1 GPFS文件系统概述 39
4.1.1 GPFS文件系统架构 40
4.1.2 GPFS文件系统逻辑架构 41
4.2 GPFS文件系统对象 42
4.2.1 网络共享磁盘NSD 42
4.2.2 集群节点及客户端节点 43
4.2.3 仲裁Node和Tiebreaker磁盘 43
4.3 GPFS集群仲裁机制 43
4.3.1 仲裁节点机制 44
4.3.2 仲裁磁盘机制 44
4.4 GPFS Failure Group失效组 44
4.5 GPFS文件系统伸缩性 45
4.6 GPFS文件系统负载均衡 45
第5章 Spectrum Scale架构详解 46
5.1 Spectrum Scale云集成 48
5.2 Spectrum Scale存储服务 49
5.3 Spectrum Scale交付模型 50
5.4 Spectrum Scale架构分类 51
5.5 Spectrum Scale企业存储特性 52
5.5.1 Spectrum Scale数据分级至云 52
5.5.2 Spectrum Scale RAID技术 53
5.5.3 Spectrum Scale Active文件管理 53
5.5.4 Spectrum Scale快照技术 53
5.5.5 Spectrum Scale Cache加速 54
5.5.6 Spectrum Scale分级存储管理 55
5.5.7 Spectrum Scale文件和对象访问 56
5.5.8 Spectrum Scale加密和销毁 57
5.6 Spectrum Scale虚拟化部署 57
5.7 Spectrum Scale LTFS带库技术 58
5.8 Elastic Storage Server 61
第6章 BeeGFS文件系统解析 62
6.1 ThinkParQ介绍 62
6.2 BeeGFS操作系统兼容性 63
6.3 BeeGFS系统架构 63
6.3.1 管理服务器介绍 64
6.3.2 元数据服务器介绍 65
6.3.3 对象存储服务介绍 66
6.3.4 文件系统客户端 67
6.4 BeeGFS安装和设置 68
6.5 BeeGFS调优和配置 69
6.6 BeeOND Burst Buffer 69
6.7 BeeGFS配额特性 72
6.8 BeeGFS的Buddy镜像 73
6.9 BeeGFS支持API概述 75
6.10 BeeGFS系统配置要求 75
6.10.1 存储服务器配置 76
6.10.2 元数据服务器配置 77
6.10.3 客户端服务器配置 77
6.10.4 管理守护进程配置 78
6.11 BeeGFS支持的网络类型 78
6.12 通过NAS导出BeeGFS 78
6.13 BeeGFS生态和合作 79
第7章 主流HPC产品和解决方案 82
7.1 DDN存储解决方案和产品 82
7.1.1 DDN S2A平台和产品 83
7.1.2 DDN SFA平台和产品 85
7.1.3 DDN WOS平台和产品 86
7.1.4 DDN Scaler系列网关产品 87
7.1.5 Burst Buffer加速产品 91
7.1.6 FlashScale全闪存产品 93
7.2 希捷存储解决方案和产品 96
7.2.1 ClusterStor产品架构 99
7.2.2 ClusterStor Manager介绍 100
7.2.3 ClusterStor配置扩展方式 101
7.2.4 ClusterStor存储软件集成架构 104
第8章 Burst Buffer技术和产品分析 107
8.1 Cray DataWarp技术和产品 107
8.1.1 Burst Buffer场景匹配 109
8.1.2 Burst Buffer技术架构 110
8.1.3 Cray技术演进蓝图 113
8.1.4 Cray HPC方案和产品 114
8.2 DDN Burst Buffer产品 117
8.2.1 IME产品架构 117
8.2.2 IME14KX产品介绍 120
8.2.3 IME240产品介绍 121
8.3 EMC Burst Buffer产品 122
8.3.1 aBBa产品架构 123
8.3.2 aBBa软件堆栈 124
第9章 HPC主流网络和技术分析 126
9.1 InfiniBand技术和基础知识 126
9.1.1 IB技术的发展 126
9.1.2 IB技术的优势 127
9.1.3 IB网络重要概念 129
9.1.4 IB协议堆栈分析 130
9.1.5 IB应用场景分析 134
9.2 InfiniBand技术和架构 135
9.2.1 IB 网络和拓扑组成 135
9.2.2 软件协议栈OFED 139
9.2.3 InfiniBand网络管理 140
9.2.4 并行计算集群能力 141
9.2.5 基于socket网络应用 142
9.2.6 IB对存储协议支持 142
9.2.7 RDMA技术介绍 143
9.3 Mellanox产品分析 143
9.3.1 Infiniband交换机 145
9.3.2 InfiniBand适配器 148
9.3.3 Infiniband路由器和网关设备 149
9.3.4 Infiniband线缆和收发器 150
9.4 InfiniBand和Omni-Path之争 151
9.4.1 Intel True Scale Fabric 软件架构 152
9.4.2 Intel InfiniBand产品家族 154
9.4.3 Intel Omni-Path产品介绍 155
9.4.4 Omni-Path和InfiniBand对比 156
第10章 HPC超算系统排名和评估 160
10.1 TOP500基准介绍和排名规则 162
10.2 Green500基准介绍和排名规则 165
10.3 HPC超算系统其他评估基准 167
10.3.1 GTC-P应用基准 173
10.3.2 Meraculous测试基准 173
10.3.3 MILC测试基准 174
10.3.4 MiniDFT测试基准 174
10.3.5 MiniPIC测试基准 174
10.3.6 PENNANT测试基准 175
10.3.7 SNAP测试基准 175
10.3.8 UMT测试基准 175
10.3.9 Crossroads/N9 DGEMM基准 175
10.3.10 IOR BenchMark基准 176
10.3.11 Mdtest测试基准 176
10.3.12 STREAM测试基准 176
温馨提示:
请识别二维码关注公众号,点击原文链接获取更多高性能计算和BurstBuffer等资料总结。

