通过 profiling 定位 golang 性能问题 - 内存篇

桔妹导读:线上性能问题的定位和优化是程序员进阶的必经之路,定位问题的方式有多种多样,常见的有观察线程栈、排查日志和做性能分析。性能分析(profile)作为定位性能问题的大杀器,它可以收集程序执行过程中的具体事件,并且对程序进行抽样统计,从而能更精准的定位问题。本文会以 go 语言的 pprof 工具为例,分享两个线上性能故障排查过程,希望能通过本文使大家对性能分析有更深入的理解。
在遇到线上的性能问题时,面对几百个接口、成吨的日志,如何定位具体是哪里的代码导致的问题呢?这篇文章会分享一下 profiling 这个定位性能问题的利器,内容主要有:
如何通过做 profiling 来精准定位故障源头
两个工作中通过 profiling 解决性能问题的实际例子
总结在做 profiling 时如何通过一些简单的现象来快速定位问题的排查方向
日常 golang 编码时要避开的一些坑
部分 golang 源码解析
文章篇幅略长,也可直接翻到下面看经验总结。
1.
profiling是什么
profile 一般被称为 性能分析,词典上的翻译是 概况(名词)或者 描述…的概况(动词)。对于计算机程序来说,它的 profile,就是一个程序在运行时的各种概况信息,包括 cpu 占用情况,内存情况,线程情况,线程阻塞情况等等。知道了程序的这些信息,也就能容易的定位程序中的问题和故障原因。
golang 对于 profiling 支持的比较好,标准库就提供了profile库 "runtime/pprof" 和 "net/http/pprof",而且也提供了很多好用的可视化工具来辅助开发者做 profiling。
2.
两次 profiling 线上实战
纸上得来终觉浅,下面分享两个在工作中实际遇到的线上问题,以及我是如何通过 profiling 一步一步定位到问题的。
▍cpu 占用 99%
某天早上一到公司就收到了线上 cpu 占用率过高的报警。立即去看监控,发现这个故障主要有下面四个特征:
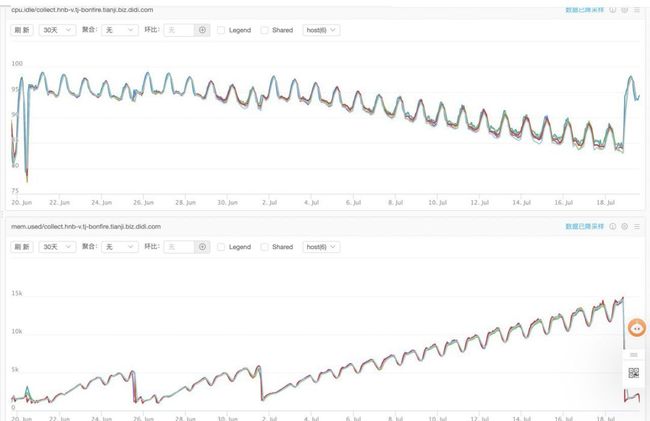
cpu idle 基本掉到了 0% ,内存使用量有小幅度增长但不严重;
故障是偶发的,不是持续存在的;
故障发生时3台机器的 cpu 几乎是同时掉底;
故障发生后,两个小时左右能恢复正常。
现象如图,上为内存,下为cpu idle:
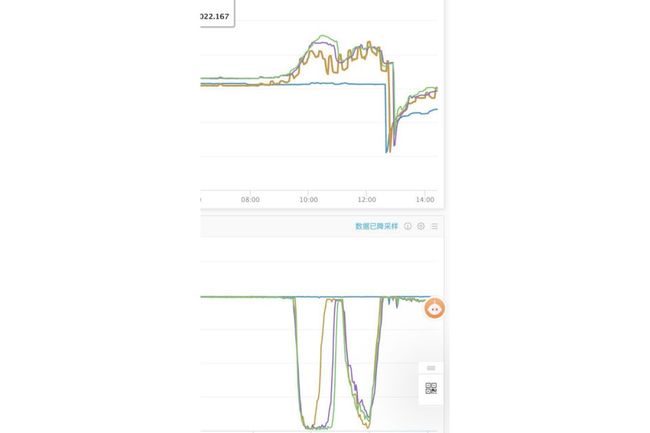
检查完监控之后,立即又去检查了一下有没有影响线上业务。看了一下线上接口返回值和延迟,基本上还都能保持正常使用,就算cpu占用 99% 时接口延时也只比平常多了几十ms。由于不影响线上业务,所以没有选择立即回滚,而是决定在线上定位问题(而且前一天后端也确实没有上线新东西)。
所以给线上环境加上了 pprof,等着这个故障自己复现。代码如下:
import _ "net/http/pprof"
func main() {
go func() {
log.Println(http.ListenAndServe("0.0.0.0:8005", nil))
}()
// ..... 下面业务代码不用动
}
golang 对于 profiling 的支持比较完善,如代码所示,只需要简单的引入 "net/http/pprof" 这个包,然后在 main 函数里启动一个 http server 就相当于给线上服务加上 profiling 了,通过访问 8005 这个 http 端口就可以对程序做采样分析。
服务上开启pprof之后,在本地电脑上使用 go tool pprof 命令,可以对线上程序发起采样请求,golang pprof 工具会把采样结果绘制成一个漂亮的前端页面供人们排查问题。
等到故障再次复现时,我们首先对 cpu 性能进行采样分析:
brew install graphviz # 安装graphviz,只需要安装一次就行了
go tool pprof -http=:1234 http://your-prd-addr:8005/debug/pprof/profile?seconds=30
打开 terminal,输入上面命令,把命令中的 your-prd-addr 改成线上某台机器的地址,然后回车等待30秒后,会自动在浏览器中打开一个页面,这个页面包含了刚刚30秒内对线上cpu占用情况的一个概要分析。点击左上角的 View 选择 Flame graph,会用火焰图(Flame graph)来显示cpu的占用情况:
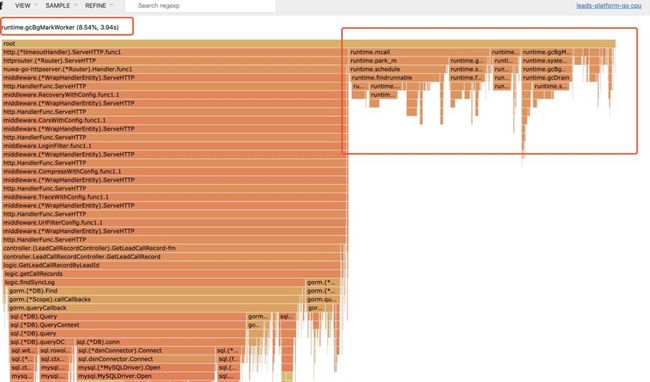
分析此图可以发现,cpu 资源的半壁江山都被 GetLeadCallRecordByLeadId 这个函数占用了,这个函数里占用 cpu 最多的又大多是数据库访问相关的函数调用。由于 GetLeadCallRecordByLeadId 此函数业务逻辑较为复杂,数据库访问较多,不太好具体排查是哪里出的问题,所以我把这个方向的排查先暂时搁置,把注意力放到了右边那另外半壁江山。
在火焰图的右边,有个让我比较在意的点是 runtime.gcBgMarkWorker 函数,这个函数是 golang 垃圾回收相关的函数,用于标记(mark)出所有是垃圾的对象。一般情况下此函数不会占用这么多的 cpu,出现这种情况一般都是内存 gc 问题,但是刚刚的监控上看内存占用只比平常多了几百M,并没有特别高又是为什么呢?原因是影响GC性能的一般都不是内存的占用量,而是对象的数量。举例说明,10个100m的对象和一亿个10字节的对象占用内存几乎一样大,但是回收起来一亿个小对象肯定会被10个大对象要慢很多。
插一段 golang 垃圾回收的知识,golang 使用“三色标记法”作为垃圾回收算法,是“标记-清除法”的一个改进,相比“标记-清除法”优点在于它的标记(mark)的过程是并发的,不会Stop The World。但缺点是对于巨量的小对象处理起来比较不擅长,有可能出现垃圾的产生速度比收集的速度还快的情况。gcMark线程占用高很大几率就是对象产生速度大于垃圾回收速度了。
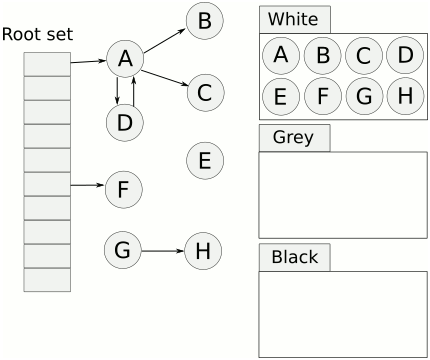
三色标记法
所以转换方向,又对内存做了一下 profiling:
go tool pprof http://your-prd-addr:8005/debug/pprof/heap
然后在浏览器里点击左上角 VIEW-》flame graph,然后点击 SAMPLE-》inuse_objects。
这样显示的是当前的对象数量:
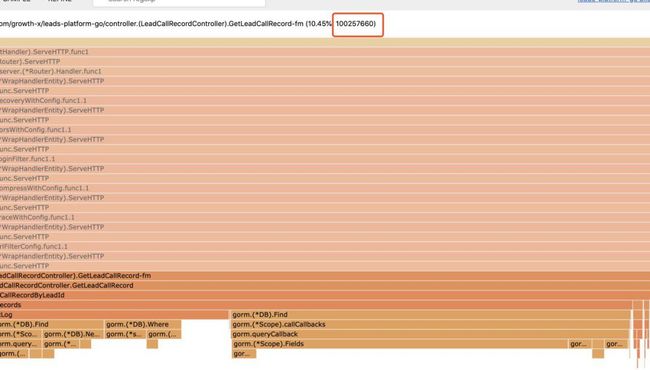
可以看到,还是 GetLeadCallRecordByLeadId 这个函数的问题,它自己就产生了1亿个对象,远超其他函数。所以下一步排查问题的方向确定了是:定位为何此函数产生了如此多的对象。
之后我开始在日志中 grep '/getLeadCallRecord' lead-platform. 来一点一点翻,重点看 cpu 掉底那个时刻附近的日志有没有什么异常。果然发现了一条比较异常的日志:
[net/http.HandlerFunc.ServeHTTP/server.go:1947] _com_request_in||traceid=091d682895eda2fsdffsd0cbe3f9a95||spanid=297b2a9sdfsdfsdfb8bf739||hintCode=||hintContent=||method=GET||host=10.88.128.40:8000||uri=/lp-api/v2/leadCallRecord/getLeadCallRecord||params=leadId={"id":123123}||from=10.0.0.0||proto=HTTP/1.0
注意看 params 那里,leadId 本应该是一个 int,但是前端给传来一个JSON,推测应该是前一天上线带上去的bug。但是还有问题解释不清楚,类型传错应该报错,但是为何会产生这么多对象呢?于是我进代码(已简化)里看了看:
func GetLeadCallRecord(leadId string, bizType int) ([]model.LeadCallRecords, error) { sql := "SELECT record.* FROM lead_call_record AS record " +"where record.lead_id = {{leadId}} and record.biz_type = {{bizType}}" conditions := make(map[string]interface{}, 2) conditions["leadId"] = leadId conditions["bizType"] = bizType cond, val, err := builder.NamedQuery(sql, conditions)
发现很尴尬的是,这段远古代码里对于 leadId 根本没有判断类型,直接用 string 了,前端传什么过来都直接当作 sql 参数了。也不知道为什么 mysql 很抽风的是,虽然 lead_id 字段类型是bigint,在 sql 里条件用 string 类型传参数 WHERE leadId = 'someString' 也能查到数据,而且返回的数据量很大。本身 lead_call_record 就是千万级别的大表,这个查询一下子返回了几十万条数据。又因为此接口后续的查询都是根据这个这个查询返回的数据进行查询的,所以整个请求一下子就产生了上亿个对象。
由于之前传参都是正确的,所以一直没有触发这个问题,正好前一天前端小姐姐上线需求带上了这个bug,一波前后端混合双打造成了这次故障。
到此为止就终于定位到了问题所在,而且最一开始的四个现象也能解释的通了:
cpu idle 基本掉到了 0% ,内存使用量有小幅度增长但不严重;
故障是偶发的,不是持续存在的;
故障发生时3台机器的 cpu 几乎是同时掉底;
故障发生后,两个小时左右能恢复正常。
逐条解释一下:
GetLeadCallRecordByLeadId 函数每次在执行时从数据库取回的数据量过大,大量cpu时间浪费在反序列化构造对象 和 gc 回收对象上。
和前端确认 /lp-api/v2/leadCallRecord/getLeadCallRecord 接口并不是所有请求都会传入json,只在某个页面里才会有这种情况,所以故障是偶发的。
因为接口并没有直接挂掉报错,而是执行的很慢,所以应用前面的负载均衡会超时,负载均衡器会把请求打到另一台机器上,结果每次都会导致三台机器同时爆表。
虽然申请了上亿个对象,但 golang 的垃圾回收器是真滴靠谱,兢兢业业的回收了两个多小时之后,就把几亿个对象全回收回去了,而且奇迹般的没有影响线上业务。几亿个对象都扛得住,只能说厉害了我的go。
最后捋一下整个过程:
cpu占用99% -> 发现GC线程占用率持续异常 -> 怀疑是内存问题 -> 排查对象数量 -> 定位产生对象异常多的接口 -> 定位到某接口 -> 在日志中找到此接口的异常请求 -> 根据异常参数排查代码中的问题 -> 定位到问题
可以发现,有 pprof 工具在手的话,整个排查问题的过程都不会懵逼,基本上一直都照着正确的方向一步一步定位到问题根源。这就是用 profiling 的优点所在。
▍内存占用 90%
第二个例子是某天周会上有同学反馈说项目内存占用达到了15个G之多,看了一下监控现象如下:
cpu占用并不高,最低idle也有85%
内存占用呈锯齿形持续上升,且速度很快,半个月就从2G达到了15G
如果所示:
锯齿是因为昼夜高峰平峰导致的暂时不用管,但持续上涨很明显的是内存泄漏的问题,有对象在持续产生,并且被持续引用着导致释放不掉。于是上了 pprof 然后准备等一晚上再排查,让它先泄露一下再看现象会比较明显。
这次重点看内存的 inuse_space 图,和 inuse_objects 图不同的是,这个图表示的是具体的内存占用而不是对象数,然后VIEW类型也选graph,比火焰图更清晰。
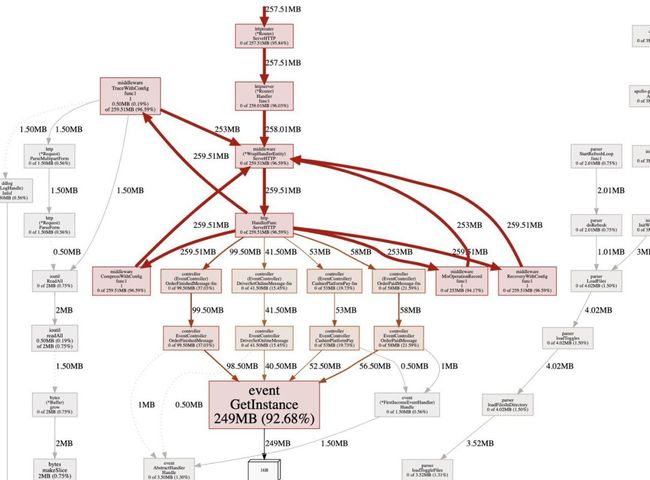
这个图可以明显的看出来程序中92%的对象都是由于 event.GetInstance 产生的。然后令人在意的点是这个函数产生的对象都是一个只有 16 个字节的对象(看图上那个16B)这个是什么原因导致的后面会解释。
先来看这个函数的代码吧:
var ( firstActivationEventHandler FirstActivationEventHandler firstOnlineEventHandler FirstOnlineEventHandler)func GetInstance(eventType string) Handler { if eventType == FirstActivation { firstActivationEventHandler.ChildHandler = firstActivationEventHandlerreturn firstActivationEventHandler } else if eventType == FirstOnline { firstOnlineEventHandler.ChildHandler = firstOnlineEventHandlerreturn firstOnlineEventHandler}// ... 各种类似的判断,略过 return nil}
这个是做一个类似单例模式的功能,根据事件类型返回不同的 Handler。但是这个函数有问题的点有两个:
firstActivationEventHandler.ChildHandler 是一个 interface,在给一个 interface 赋值的时候,如果等号右边是一个 struct,会进行值传递,也就意味着每次赋值都会在堆上复制一个此 struct 的副本。(golang默认都是值传递)
firstActivationEventHandler.ChildHandler = firstActivationEventHandler 是一个自己引用自己循环引用。
两个问题导致了每次 GetInstance 函数在被调用的时候,都会复制一份之前的 firstActivationEventHandler 在堆上,并且让 firstActivationEventHandler.ChildHandler 引用指向到这个副本上。
这就导致人为在内存里创造了一个巨型的链表:
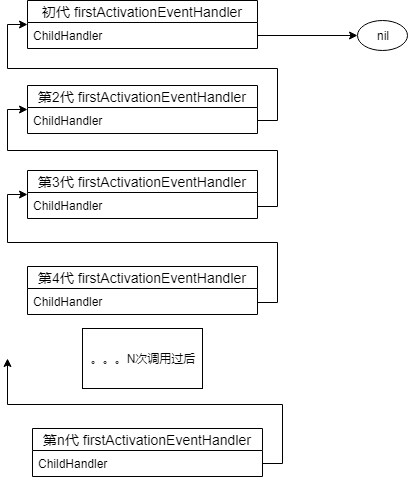
并且这个链表中所有节点都被之后的副本引用着,永远无法被GC当作垃圾释放掉。
所以解决这个问题方案也很简单,单例模式只需要在 init 函数里初始化一次就够了,没必要在每次 GetInstance 的时候做初始化操作:
func init() { firstActivationEventHandler.ChildHandler = &firstActivationEventHandler firstOnlineEventHandler.ChildHandler = &firstOnlineEventHandler// ... 略过}
另外,可以深究一下为什么都是一个 16B 的对象呢?为什么 interface 会复制呢?这里贴一下 golang runtime 关于 interface 部分的源码:
下面分析 golang 源码,不感兴趣可直接略过。
// interface 底层定义
type iface struct {
tab *itab
data unsafe.Pointer
}
// 空 interface 底层定义
type eface struct {
_type *_type
data unsafe.Pointer
}
// 将某变量转换为interface
func convT2I(tab *itab, elem unsafe.Pointer) (i iface) {
t := tab._type
if raceenabled {
raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2I))
}
if msanenabled {
msanread(elem, t.size)
}
x := mallocgc(t.size, t, true)
typedmemmove(t, x, elem)
i.tab = tab
i.data = x
return
}
iface 这个 struct 是 interface 在内存中实际的布局。可以看到,在golang中定义一个interface,实际上在内存中是一个 tab 指针和一个 data 指针,目前的机器都是64位的,一个指针占用8个字节,两个就是16B。
我们的 firstActivationEventHandler 里面只有一个 ChildHandler interface,所以整个 firstActivationEventHandler 占用 16 个字节也就不奇怪了。
另外看代码第 20 行那里,可以看到每次把变量转为 interface 时是会做一次 mallocgc(t.size, t, true) 操作的,这个操作就会在堆上分配一个副本,第 21 行 typedmemmove(t, x, elem) 会进行复制,会复制变量到堆上的副本上。这就解释了开头的问题。
3.
经验总结
在做内存问题相关的 profiling 时:
若 gc 相关函数占用异常,可重点排查对象数量
解决速度问题(CPU占用)时,关注对象数量( --inuse/alloc_objects )指标
解决内存占用问题时,关注分配空间( --inuse/alloc_space )指标
inuse 代表当前时刻的内存情况,alloc 代表从从程序启动到当前时刻累计的内存情况,一般情况下看 inuse 指标更重要一些,但某些时候两张图对比着看也能有些意外发现。
在日常 golang 编码时:
参数类型要检查,尤其是 sql 参数要检查(低级错误)
传递struct尽量使用指针,减少复制和内存占用消耗(尤其对于赋值给interface,会分配到堆上,额外增加gc消耗)
尽量不使用循环引用,除非逻辑真的需要
能在初始化中做的事就不要放到每次调用的时候做
本文作者
▬
张威虎
滴滴 | 高级软件开发工程师
由于Lua游戏脚本误入代码坑,热爱一切能玩的技术。搞过嵌入式,玩过机器人,写过协议栈,调过系统内核。现在专注于服务端开发,在工作中习惯去记录遇到的技术难题和经验启发。最后,猫狗双全。
推荐阅读
▬
更多推荐
▬
滴滴开源 / Open Source
Mpx | Booster | Chameleon | DDMQ | DroidAssist | Rdebug | Doraemonkit | Kemon | Mand Moblie | virtualApk | 获取更多项目
技术干货 / Recommended article
WebPack 如何控制事件执行流 | Android 性能优化之 Activity 启动耗时分析 | HDFS 源码解读:HadoopRPC 实现细节的探究| 阅读更多内容