中文文本情感分类(基于LSTM和textCNN)
中文新闻数据集
负面文本:
正面文本:
数据文本都是用爬虫从网络上爬取的,由人工进行分类,在使用这些数据之前,需要先对文本进行预处理,预处理包括去除标点符号,停用词过滤和分词等,由于篇幅有限,这里就不放预处理代码了,处理完的数据如下:
使用循环神经网络(LSTM)
我们将应用预训练的词向量和含多个隐藏层的双向循环神经网络,来判断一段不定长的文本序列中包含的是正面还是负面的情绪。
首先导入所需的包或模块。
import collections
import os
import random
import time
import torch
from torch import nn
import torchtext.vocab as Vocab
import torch.utils.data as Data
from sklearn.model_selection import train_test_split
from tqdm import tqdm
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
读取数据
每个样本是一条评论及其对应的标签:1表示“正面”,0表示“负面”。
def load_data():
data = []
sample_num = 25000
with open('./data/positive_process.data', 'r', encoding='utf-8') as f:
sentences = f.readlines()
for sentence in sentences[:sample_num]:
words = [x for x in sentence.strip().split('\t')]
data.append([words, 0])
with open('./data/negative_process.data', 'r', encoding='utf-8') as f:
sentences = f.readlines()
for sentence in sentences[:sample_num]:
words = [x for x in sentence.strip().split('\t')]
data.append([words, 1])
random.shuffle(data)
return data
train_data, test_data = train_test_split(load_data(), test_size=0.2)
预处理数据
根据训练数据创建字典,这里过滤掉了出现次数少于5的词。
def get_vocab(data):
tokenized_data = [words for words, _ in data]
counter = collections.Counter([tk for st in tokenized_data for tk in st])
return Vocab.Vocab(counter, min_freq=5)
vocab = get_vocab(train_data)
print('# words in vocab:', len(vocab))
因为每条评论长度不一致所以不能直接组合成小批量,我们定义preprocess函数将每条文本中的词通过词典转换成词索引,然后通过截断或者补0来将每条文本长度固定成500。
def preprocess(data, vocab):
max_l = 500 # 将每条评论通过截断或者补0,使得长度变成500
def pad(x):
return x[:max_l] if len(x) > max_l else x + [0] * (max_l - len(x))
tokenized_data = [words for words, _ in data]
features = torch.tensor([pad([vocab.stoi[word] for word in words]) for words in tokenized_data])
labels = torch.tensor([score for _, score in data])
return features, labels
创建数据迭代器
现在,我们创建数据迭代器。每次迭代将返回一个小批量的数据。
batch_size = 64
train_set = Data.TensorDataset(*preprocess(train_data, vocab))
test_set = Data.TensorDataset(*preprocess(test_data, vocab))
train_iter = Data.DataLoader(train_set, batch_size, shuffle=True)
test_iter = Data.DataLoader(test_set, batch_size)
打印第一个小批量数据的形状以及训练集中小批量的个数。
for X, y in train_iter:
print('X', X.shape, 'y', y.shape)
break
print('#batches:', len(train_iter))
搭建循环神经网络模型
在这个模型中,每个词先通过嵌入层得到特征向量。然后,我们使用双向循环神经网络对特征序列进一步编码得到序列信息。最后,我们将编码的序列信息通过全连接层变换为输出。
class BiRNN(nn.Module):
def __init__(self, vocab, embed_size, num_hiddens, num_layers):
super(BiRNN, self).__init__()
self.embedding = nn.Embedding(len(vocab), embed_size)
# bidirectional设为True即得到双向循环神经网络
self.encoder = nn.LSTM(input_size=embed_size,
hidden_size=num_hiddens,
num_layers=num_layers,
bidirectional=True)
# 初始时间步和最终时间步的隐藏状态作为全连接层输入
self.decoder = nn.Linear(4 * num_hiddens, 2)
def forward(self, inputs):
# inputs的形状是(批量大小, 词数),因为LSTM需要将序列长度(seq_len)作为第一维,所以将输入转置后
# 再提取词特征,输出形状为(词数, 批量大小, 词向量维度)
embeddings = self.embedding(inputs.permute(1, 0))
# rnn.LSTM只传入输入embeddings,因此只返回最后一层的隐藏层在各时间步的隐藏状态。
# outputs形状是(词数, 批量大小, 2 * 隐藏单元个数)
outputs, _ = self.encoder(embeddings) # output, (h, c)
# 连结初始时间步和最终时间步的隐藏状态作为全连接层输入。它的形状为
# (批量大小, 4 * 隐藏单元个数)。
encoding = torch.cat((outputs[0], outputs[-1]), -1)
outs = self.decoder(encoding)
return outs
创建一个含两个隐藏层的双向循环神经网络。
embed_size, num_hiddens, num_layers = 300, 300, 2
net = BiRNN(vocab, embed_size, num_hiddens, num_layers)
加载预训练的词向量
由于情感分类的训练数据集并不是很大,为应对过拟合,我们将直接使用在更大规模语料上预训练的词向量作为每个词的特征向量。我们使用了由北京师范大学和人民大学的研究者开源的「中文词向量语料库」,这里放上该项目github地址:https://github.com/Embedding/Chinese-Word-Vectors
现在为词典vocab中的每个词加载微博语料数据训练出的300维的词向量。
cache = '.vector_cache'
if not os.path.exists(cache):
os.mkdir(cache)
glove_vocab = Vocab.Vectors(name='./data/sgns.weibo.bigram-char', cache=cache)
然后,我们将用这些词向量作为文本中每个词的特征向量。注意,预训练词向量的维度需要与创建的模型中的嵌入层输出大小embed_size一致。此外,在训练中我们不再更新这些词向量。
def load_pretrained_embedding(words, pretrained_vocab):
"""从预训练好的vocab中提取出words对应的词向量"""
embed = torch.zeros(len(words), pretrained_vocab.vectors[0].shape[0]) # 初始化为0
oov_count = 0 # out of vocabulary
for i, word in enumerate(words):
try:
idx = pretrained_vocab.stoi[word]
embed[i, :] = pretrained_vocab.vectors[idx]
except KeyError:
oov_count += 1
if oov_count > 0:
print("There are %d oov words." % oov_count)
return embed
net.embedding.weight.data.copy_(
load_pretrained_embedding(vocab.itos, glove_vocab))
net.embedding.weight.requires_grad = False # 直接加载预训练好的, 所以不需要更新它
训练并评价模型
def evaluate_accuracy(data_iter, net, device=None): # 测试函数
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
n += y.shape[0]
return acc_sum / n
def train(train_iter, test_iter, net, loss, optimizer, device, num_epochs): # 训练函数
net = net.to(device)
print("training on ", device)
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in tqdm(train_iter):
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
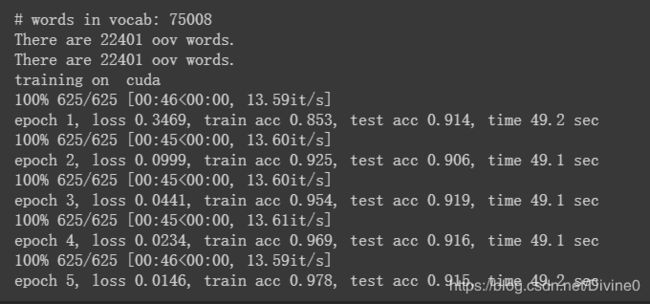
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
lr, num_epochs = 0.01, 5
# 要过滤掉不计算梯度的embedding参数
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, net.parameters()), lr=lr)
loss = nn.CrossEntropyLoss()
train(train_iter, test_iter, net, loss, optimizer, device, num_epochs)
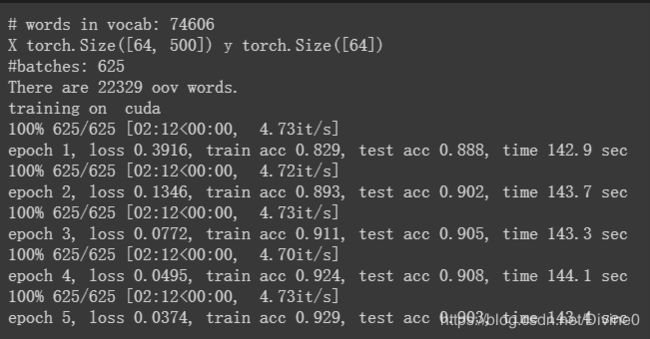
运行结果:
使用卷积神经网络(textCNN)
流程和使用循环神经网络类似,直接给出完整代码:
import collections
import os
import random
import time
import torch
from sklearn.model_selection import train_test_split
from torch import nn
import torchtext.vocab as Vocab
import torch.utils.data as Data
import torch.nn.functional as F
from tqdm import tqdm
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
def load_data():
data = []
sample_num = 25000
with open('./data/positive_process.data', 'r', encoding='utf-8') as f:
sentences = f.readlines()
for sentence in sentences[:sample_num]:
words = [x for x in sentence.strip().split('\t')]
data.append([words, 0])
with open('./data/negative_process.data', 'r', encoding='utf-8') as f:
sentences = f.readlines()
for sentence in sentences[:sample_num]:
words = [x for x in sentence.strip().split('\t')]
data.append([words, 1])
random.shuffle(data)
return data
def get_vocab(data):
tokenized_data = [words for words, _ in data]
counter = collections.Counter([tk for st in tokenized_data for tk in st])
return Vocab.Vocab(counter, min_freq=5)
def preprocess(data, vocab):
max_l = 500 # 将每条评论通过截断或者补0,使得长度变成500
def pad(x):
return x[:max_l] if len(x) > max_l else x + [0] * (max_l - len(x))
tokenized_data = [words for words, _ in data]
features = torch.tensor([pad([vocab.stoi[word] for word in words]) for words in tokenized_data])
labels = torch.tensor([score for _, score in data])
return features, labels
def load_pretrained_embedding(words, pretrained_vocab):
"""从预训练好的vocab中提取出words对应的词向量"""
embed = torch.zeros(len(words), pretrained_vocab.vectors[0].shape[0]) # 初始化为0
oov_count = 0 # out of vocabulary
for i, word in enumerate(words):
try:
idx = pretrained_vocab.stoi[word]
embed[i, :] = pretrained_vocab.vectors[idx]
except KeyError:
oov_count += 1
if oov_count > 0:
print("There are %d oov words." % oov_count)
return embed
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
n += y.shape[0]
return acc_sum / n
def train(train_iter, test_iter, net, loss, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
batch_count = 0
opt_test_acc = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in tqdm(train_iter):
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
batch_size = 64
train_data, test_data = train_test_split(load_data(), test_size=0.2)
vocab = get_vocab(train_data)
print('# words in vocab:', len(vocab))
train_set = Data.TensorDataset(*preprocess(train_data, vocab))
test_set = Data.TensorDataset(*preprocess(test_data, vocab))
train_iter = Data.DataLoader(train_set, batch_size, shuffle=True)
test_iter = Data.DataLoader(test_set, batch_size)
class GlobalMaxPool1d(nn.Module): # 用一维池化层实现时序最大池化层
def __init__(self):
super(GlobalMaxPool1d, self).__init__()
def forward(self, x):
# x shape: (batch_size, channel, seq_len)
# return shape: (batch_size, channel, 1)
return F.max_pool1d(x, kernel_size=x.shape[2])
class TextCNN(nn.Module):
def __init__(self, vocab, embed_size, kernel_sizes, num_channels):
super(TextCNN, self).__init__()
self.embedding = nn.Embedding(len(vocab), embed_size)
# 不参与训练的嵌入层
self.constant_embedding = nn.Embedding(len(vocab), embed_size)
self.dropout = nn.Dropout(0.5)
self.decoder = nn.Linear(sum(num_channels), 2)
# 时序最大池化层没有权重,所以可以共用一个实例
self.pool = GlobalMaxPool1d()
self.convs = nn.ModuleList() # 创建多个一维卷积层
for c, k in zip(num_channels, kernel_sizes):
self.convs.append(nn.Conv1d(in_channels=2 * embed_size,
out_channels=c,
kernel_size=k))
def forward(self, inputs):
# 将两个形状是(批量大小, 词数, 词向量维度)的嵌入层的输出按词向量连结
embeddings = torch.cat((
self.embedding(inputs),
self.constant_embedding(inputs)), dim=2) # (batch, seq_len, 2*embed_size)
# 根据Conv1D要求的输入格式,将词向量维,即一维卷积层的通道维(即词向量那一维),变换到前一维
embeddings = embeddings.permute(0, 2, 1)
# 对于每个一维卷积层,在时序最大池化后会得到一个形状为(批量大小, 通道大小, 1)的
# Tensor。使用flatten函数去掉最后一维,然后在通道维上连结
encoding = torch.cat([self.pool(F.relu(conv(embeddings))).squeeze(-1) for conv in self.convs], dim=1)
# 应用丢弃法后使用全连接层得到输出
outputs = self.decoder(self.dropout(encoding))
return outputs
embed_size, kernel_sizes, nums_channels = 300, [3, 4, 5], [300, 300, 300]
net = TextCNN(vocab, embed_size, kernel_sizes, nums_channels)
cache = '.vector_cache'
if not os.path.exists(cache):
os.mkdir(cache)
glove_vocab = Vocab.Vectors(name='./data/sgns.weibo.bigram-char', cache=cache)
net.embedding.weight.data.copy_(
load_pretrained_embedding(vocab.itos, glove_vocab))
net.constant_embedding.weight.data.copy_(
load_pretrained_embedding(vocab.itos, glove_vocab))
net.constant_embedding.weight.requires_grad = False
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, net.parameters()), lr=lr)
loss = nn.CrossEntropyLoss()
train(train_iter, test_iter, net, loss, optimizer, device, num_epochs)
运行结果: