- 1 原子操作
- 2 内存屏障
- 3 spinlock
- 4 信号量semaphore
- 5 Mutex和MCS锁
- 5.1 MCS锁
- 5.2 Mutex锁
- 6 读写锁
- 7 RCU
- 7.1 背景和原理
- 7.2 操作接口
- 7.3 基本概念
- 7.4 Linux实现
- 7.4.1 相关数据结构定义
- 7.4.2 内核启动进行RCU初始化
- 7.4.3 开启一个GP
- 7.4.4 初始化一个GP
- 7.4.5 检测QS
- 7.4.6 GP结束
- 7.4.7 回调函数
- 8 总结
1 原子操作
原子操作保证指令以原子的方式执行(不是代码编写, 而是由于CPU的行为导致, 先加载变量到本地寄存器再操作再写内存). x86的atomic操作通常通过原子指令或lock前缀实现.
2 内存屏障
内存屏障是程序在运行时的实际内存访问顺序和程序代码编写的访问顺序不一致,会导致内存乱序访问。分为编译时编译器优化和运行时多CPU间交互.
- 编译优化使用barrier()防止编译优化
[include/linux/compiler-gcc.h]
#define barrier() __asm__ __volatile__ ("" ::: "memory")"memory"强制gcc编译器假设RAM所有内存单元均被汇编指令修改,这样cpu中的registers和cache中已缓存的内存单元中的数据将作废(!!!)。cpu将不得不在需要的时候重新读取内存中的数据。这就阻止了cpu又将registers,cache中的数据用于去优化指令,而避免去访问内存。目的是防止编译乱序(!!!)。
- x86提供了三个指令: sfence(该指令前的写操作必须在该指令后的写操作前完成), lfence(读操作), mfence(读写操作)
3 spinlock
操作系统中锁的机制分为两类(!!!),一类是忙等待,另一类是睡眠等待。
spinlock主要针对数据操作集合的临界区, 临界区是一个变量, 原子变量可以解决. 抢到锁的进程不能睡眠, 并要快速执行(这是spinlock的设计语义).
"FIFO ticket-based算法":
锁由slock(和
- 获取锁: CPU先领ticket(当前next值), 然后锁的next加1, owner等于ticket, CPU获得锁, 返回, 否则循环忙等待
- 释放锁: 锁的owner加1
获取锁接口(这里只提这两个):
- spin_lock(): 关内核抢占, 循环抢锁, 但来中断(中断会抢占所有)可能导致死锁
- spin_lock_irq(): 关本地中断, 关内核抢占(内核不会主动抢占), 循环抢锁
spin_lock()和raw_spin_lock():
- 在绝对不允许被抢占和睡眠的临界区,使用raw_spin_lock
- Linux实时补丁spin_lock()允许临界区抢占和进程睡眠, 否则spin_lock()直接调用raw_spin_lock()
spin_lock特点:
- 忙等待, 不断尝试
- 同一时刻只能有一个获得
- spinlock临界区尽快完成, 不能睡眠
- 可以在中断上下文使用
4 信号量semaphore
信号量允许进程进入睡眠状态(即睡眠等待), 是计数器, 支持两个操作原语P(down)和V(up)
struct semaphore{
raw_spinlock_t lock; //对count和wait_list的保护
unsigned int count; // 允许持锁数目
struct list_head wait_list; // 没成功获锁的睡眠的进程链表
};初始化: sema_init()
获得锁:
- down(struct semaphore *sem): 失败进入不可中断的睡眠状态
- down_interruptible(struct semaphore *sem): 失败则进入可中断的睡眠状态. ①关闭本地中断(防止中断来导致死锁); ②count大于0, 当前进程获得semaphore, count减1, 退出; ③count小于等于0, 将当前进程加入wait_list链表, 循环: 设置进程TASKINTERRUPTIBLE, 调用schedule_timeout()让出CPU<即睡眠>, 判断被调度到的原因(能走到这儿说明又被调度到了), 如果waiter.up为true, 说明被up操作唤醒, 获得信号量,退出; ④打开本地中断
- 等等
释放锁:
up(struct semaphore *sem): wait_list为空, 说明没有进程等待信号量, count加1, 退出; wait_list不为空, 等待队列是先进先出, 将第一个移出队列, 设置waiter.up为true, wake_up_process()唤醒waiter->task进程
睡眠等待, 任意数量的锁持有者
5 Mutex和MCS锁
5.1 MCS锁
传统自旋等待锁, 在多CPU和NUMA系统, 所有自旋等待锁在同一个共享变量自旋, 对同一个变量修改, 由cache一致性原理(例如MESI)导致参与自旋的CPU中的cache line变的无效, 从而导致CPU高速缓存行颠簸现象(CPU cache line bouncing), 即多个CPU上的cache line反复失效.
MCS减少CPU cache line bouncing, 核心思想是每个锁的申请者只在本地CPU的变量上自旋,而不是全局的变量。
[include/linux/osq_lock.h]
// Per-CPU的, 表示本地CPU节点
struct optimistic_spin_node {
struct optimistic_spin_node *next, *prev; // 双向链表
int locked; /* 1 if lock acquired */ // 加锁状态, 1表明当前能申请
int cpu; /* encoded CPU # + 1 value */ // CPU编号, 0表示没有CPU, 1表示CPU0, 类推
};
// 一个MCS锁一个
struct optimistic_spin_queue {
/*
* Stores an encoded value of the CPU # of the tail node in the queue.
* If the queue is empty, then it's set to OSQ_UNLOCKED_VAL.
*/
atomic_t tail;
};初始化: osq_lock_init()
申请MCS锁: osq_lock()
- 给当前进程所在CPU编号, 将lock->tail设为当前CPU编号, 如果原有tail是0, 表明没有CPU, 那直接申请成功
- 通过原有tail获得前继node, 然后将当前node节点加入MCS链表
- 循环自旋等待, 判断当前node的locked是否是1, 1的话说明前继释放了锁, 申请成功, 退出; 不是1, 判断是否需要重新调度(抢占或调度器要求), 是的话放弃自旋等待, 退出MCS链表, 删除MCS链表节点, 申请失败
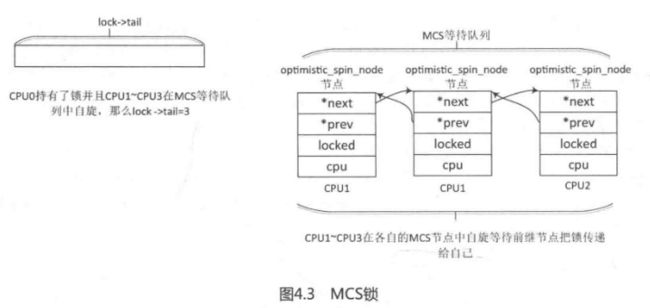
释放MCS锁: osq_unlock()
- lock->tail是当前CPU, 说明没人竞争, 直接设tail为0, 退出
- 当前节点的后继节点存在, 设置后继node的locked为1, 相当于传递锁
5.2 Mutex锁
[include/linux/mutex.h]
struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
// 1表示没人持有锁;0表示锁被持有;负数表示锁被持有且有人在等待队列中等待
atomic_t count;
// 保护wait_list睡眠等待队列
spinlock_t wait_lock;
// 所有在该Mutex上睡眠的进程
struct list_head wait_list;
#if defined(CONFIG_MUTEX_SPIN_ON_OWNER)
// 锁持有者的task_struct
struct task_struct *owner;
#endif
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
// MCS锁
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
};初始化: 静态DEFINE_MUTEX宏, 动态使用mutex_init()函数
申请Mutex锁:
- mutex->count减1等于0, 说明没人持有锁, 直接申请成功, 设置owner为当前进程, 退出
- 申请OSQ锁, 减少CPU cache line bouncing, 会将所有等待Mutex的参与者放入OSQ锁队列, 只有第一个等待者才参与自旋等待
- while循环自旋等待锁持有者释放, 这中间①锁持有者变化 ②锁持有进程被调度出去, 即睡眠(task->on_cpu=0), ③调度器需要调度其他进程(need_resched())都会退出循环, 但不是锁持有者释放了锁(lock->owner不是NULL); 如果是锁持有者释放了锁(lock->owner是NULL), 当前进程获取锁, 设置count为0, 释放OSQ锁, 申请成功, 退出.
- 上面自旋等待获取锁失败, 再尝试一次申请, 不成功的话只能走睡眠唤醒的慢车道.
- 将当前进程的waiter进入mutex等待队列wait_list
- 循环: 获取锁, 失败则让出CPU, 进入睡眠态, 成功则退出循环, 收到异常信号也会退出循环
- 成功获取锁退出循环的话, 设置进程运行态, 从等待队列出列, 如果等待队列为空, 设置lock->count为0(表明锁被人持有且队列无人)
- 设置owner为当前进程
释放Mutex锁:
- 清除owner
- count加1若大于0, 说明队列没人, 成功
- 释放锁, 将count设为1, 然后唤醒队列第一个进程(waiter->task)
从 Mutex实现细节的分析可以知道,Mutex比信号量的实现要高效很多。
- Mutex最先实现自旋等待机制。
- Mutex在睡眠之前尝试获取锁(!!!)。
- Mutex实现MCS锁来避免多个CPU争用锁而导致CPU高速缓存行颠簸现象。
正是因为Mutex的简洁性和高效性,因此Mutex的使用场景比信号量要更严格,使用Mutex需要注意的约束条件如下。
- 同一时刻只有一个线程可以持有Mutex。
- 只有锁持有者可以解锁。不能在一个进程中持有Mutex,而在另外一个进程中释放它。因此Mutex不适合内核同用户空间复杂的同步场景(!!!),信号量和读写信号量比较适合。
- 不允许递归地加锁和解锁。
- 当进程持有Mutex时,进程不可以退出(!!!)。
- Mutex必须使用官方API来初始化。
- Mutex可以睡眠,所以不允许在中断处理程序或者中断下半部中使用,例如tasklet、定时器等。
在实际工程项目中,该如何选择spinlock、信号量和Mutex呢?
在中断上下文中毫不犹豫地使用spinlock, 如果临界区有睡眠、隐含睡眠的动作及内核API,应避免选择spinlock。在信号量和Mutex中该如何选择呢?除非代码场景不符合上述Mutex的约束中有某一条,否则都优先使用Mutex。
6 读写锁
信号量缺点: 没有区分临界区的读写属性
读写锁特点:
- 允许多个读者同时进入临界区,但同一时刻写者不能进入。
- 同一时刻只允许一个写者进入临界区。
- 读者和写者不能同时进入临界区。
读写锁有两种,分别是spinlock类型和信号量类型。分别对应typedef struct rwlock_t和struct rw_semaphore.
读写锁在内核中应用广泛,特别是在内存管理中,全局的mm->mmap_sem读写信号量用于保护进程地址空间的一个读写信号量,还有反向映射RMAP系统中的anon_vma->rwsem,地址空间address_space数据结构中i_mmap_rwsem等。
再次总结读写锁的重要特性。
- down_read(): 如果一个进程持有了读者锁,那么允许继续申请多个读者锁,申请写者锁则要睡眠等待。
- down_write(): 如果一个进程持有了写者锁,那么第二个进程申请该写者锁要自旋等待(配置了CONFIG_RWSEM_SPIN_ON_OWNER选项不睡眠),申请读者锁则要睡眠等待。
- up_write()/up_read():如果等待队列中第一个成员是写者,那么唤醒该写者,否则唤醒排在等待队列中最前面连续的几个读者。
7 RCU
7.1 背景和原理
spinlock、读写信号量和mutex的实现,它们都使用了原子操作指令,即原子地访问内存,多CPU争用共享的变量会让cache一致性变得很糟(!!!),使得性能下降。读写信号量还有一个致命缺点, 只允许多个读者同时存在, 但读者和写者不能同时存在.
RCU实现目标是, 读者线程没有同步开销(不需要额外的锁, 不需要使用原子操作指令和内存屏障); 同步任务交给写者线程, 写者线程等所有读者线程完成把旧数据销毁, 多个写者则需要额外保护机制.
原理: RCU记录所有指向共享数据的指针的使用者, 当修改该共享数据时,首先创建一个副本,在副本中修改。所有读访问线程都离开读临界区之后,指针指向新的修改后副本的指针,并且删除旧数据。
7.2 操作接口
接口如下:
- rcu_read_lock()/rcu_read_unlock(): 组成一个RCU读临界。
- rcu_dereference(): 用于获取被RCU保护的指针(RCU protected pointer),读者线程要访问RCU保护的共享数据,需要使用该函数创建一个新指针(!!!),并且指向RCU被保护的指针。
- rcu_assign_pointer(): 通常用在写者线程。在写者线程完成新数据的修改后,调用该接口可以让被RCU保护的指针指向新创建的数据,用RCU的术语是发布(Publish) 了更新后的数据。
- synchronize_rcu(): 同步等待所有现存的读访问完成。
- call_rcu(): 注册一个回调函数(!!!),当所有现存的读访问完成后,调用这个回调函数销毁旧数据。
[RCU的一个简单例子]
#include
#include
#include
#include
#include
#include
#include
#include
struct foo {
int a;
struct rcu_head rcu;
};
static struct foo *g_ptr;
static void myrcu_reader_thread(void *data) //读者线程
{
struct foo *p = NULL;
while(1){
msleep(200);
// 重点1
rcu_read_lock();
// 重点2
p = rcu_dereference(g_ptr);
if(p)
printk("%s: read a=%d\n", __func__, p->a);
// 重点3
rcu_read_unlock();
}
}
static void myrcu_del(struct rcu_head *rh)
{
struct foo *p = container_of(rh, struct foo, rcu);
printk ("%s: a=%d\n", __func__, p->a);
kfree(p);
}
static void myrcu_writer_thread(void *p) //写者线程
{
struct foo *mew;
struct foo *old;
int value = (unsigned long)p;
while(1){
msleep(400);
struct foo *new_ptr = kmalloc(sizeof(struct foo), GFP_KERNEL);
old = g_ptr;
printk("%s: write to new %d\n", __func__, value);
*new_ptr = *old;
new_ptr->a = value;
// 重点
rcu_assign_pointer(g_ptr, new_ptr);
// 重点
call_rcu(&old->rcu, myrcu_del);
value++;
}
}
static int __init my_test_init(void){
struct task_struct *reader_thread;
struct task_struct *writer_thread ;
int value = 5;
printk("figo: my module init\n");
g_ptr = kzalloc(sizeof (struct foo), GFP_KERNEL);
reader_thread = kthread_run(myrcu_reader_thread, NULL, "rcu_reader");
writer_thread = kthread_run(myrcu_writer_thread, (void *)(unsigned long)value, "rcu_writer")
return 0;
}
static void __exit my_test_exit(void)
{
printk("goodbye\n");
if(g_ptr)
kfree(g_ptr);
}
MODULE_LICENSE("GPL");
module_init(my_test_init); 该例子的目的是通过RCU机制保护my_test_init()分配的共享数据结构g_ptr,另外创建了一个读者线程和一个写者线程来模拟同步场景。
对于读者线程myrcu_reader_thread:
- 通过rcu_read_lock()和rcu_read_unlock()来构建一个读者临界区。
- 调用rcu_dereference()获取被保护数据g_ptr指针的一个副本(!!!),即指针p,这时p和g_ptr都指向旧的被保护数据。
- 读者线程每隔200毫秒读取一次被保护数据。
对于写者线程myrcu_writer_thread:
- 分配一个新的保护数据new_ptr,并修改相应数据。
- rcu_assign_pointer()让g_ptr指向新数据。
- call_rcu()注册一个回调函数(!!!),确保所有对旧数据的引用都执行完成之后,才调用回调函数来删除旧数据old_data。
- 写者线程每隔400毫秒修改被保护数据。
在所有的读访问完成之后,内核可以释放旧数据,对于何时释放旧数据,内核提供了两个API函数(!!!):synchronize_rcu()和 call_rcu().
7.3 基本概念
Grace Period, 宽限期: GP开始到所有读者临界区的CPU离开算一个GP, GP结束调用回调函数
Quiescent State, 静止状态: 一个CPU处于读者临界区, 说明活跃, 离开读者临界区, 静止态
经典RCU使用全局cpumask位图, 每个比特一个CPU. 每个CPU在GP开始设置对应比特, 结束清相应比特. 多CPU会竞争使用, 需要使用spinlock, CPU越多竞争越惨烈.
Tree RCU解决cpumask位图竞争问题.
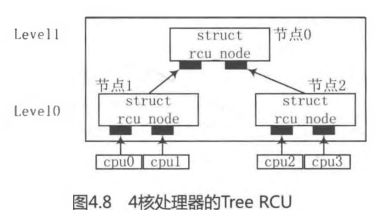
以4核处理器为例,假设Tree RCU把两个CPU分成1个rcu_node节点,这样4个CPU被分配到两个rcu_node节点上,另外还有1个根rcu_node节点来管理这两个rcu_node节点。如图4.8所示,节点1管理cpuO和cpul,节点2管理cpu2和cpu3,而节点0是根节点,管理节点1和节点2。每个节点只需要两个比特位的位图(!!!)就可以管理各自的CPU或者节点,每个节点(!!!)都有各自的spinlock锁(!!!)来保护相应的位图。
注意: CPU不算层次level!!!
假设4个CPU都经历过一个QS状态,那么4个CPU首先在Level 0层级的节点1和节点2上修改位图。对于节点1或者节点2来说,只有两个CPU来竞争锁,这比经典RCU上的锁争用要减少一半。当Level 0上节点1和节点2上位图都被清除干净后(!!!),才会清除上一级节点的位图,并且只有最后清除节点的CPU(!!!)才有机会去尝试清除上一级节点的位图(!!!)。因此对于节点0来说,还是两个CPU来争用锁。整个过程都是只有两个CPU去争用一个锁,比经典RCU实现要减少一半。
7.4 Linux实现
7.4.1 相关数据结构定义
Tree RCU实现, 定义了3个很重要的数据结构,分别是struct rcu_data、struct rcu_node和struct rcu_state,另外还维护了一个比较隐晦的状态机(!!!).
- struct rcu_data数据结构定义成Per-CPU变量. gpnum和completed用于GP状态机的运行状态, 初始两个都等于-300, 新建一个GP, gpnum加1; GP完成, completed加1. passed_quiesce(bool): 当时钟tick检测到rcu_data对应的CPU完成一次Quiescent State, 设这个为true. qs_pending(bool): CPU正等待QS.
- struct rcu_node是Tree RCU中的组成节点,它有根节点(Root Node)和叶节点之分。如果Tree RCU只有一层,那么根节点下面直接管理着一个或多个rcu_data;如果Tree RCU有多层结构,那么根节点管理着多个叶节点,最底层的叶节点管理者一个或多个rcu_data。
- RCU系统支持多个不同类型的RCU状态,使用struct rcu_state数据结构来描述这些状态。每种RCU类型都有独立的层次结构(!!!),即根节点和rcu_data数据结构。也有gpnum和completed.
Tree通过三个维度确定层次关系: 每个叶子的CPU数量(CONFIG_RCU_FANOUT_LEAF), 每层的最多叶子数量(CONFIG_RCU_FANOUT), 最多层数(MAX_RCU_LVLS宏定义, 是4, CPU不算level层次!!!)

在32核处理器中,层次结构分成两层,Level 0包括两个struct rcu_node(!!!),其中每个struct rcu_node管理16个struct rcu_data(!!!)数据结构,分别表示16个CPU的独立struct rcu_data数据结构; 在Level 1层级,有一个struct rcu_node(!!!)节点管理着Level 0层级的两个rcu_node节点,Level 1层级中的rcu_node节点称为根节点,Level 0层级的两个rcu_node节点是叶节点。
如图4.17所示是Tree RCU状态机的运转情况和一些重要数据的变化情况。

7.4.2 内核启动进行RCU初始化

(1) 初始化3个rcu_state, rcu_sched_state(普通进程上下文的RCU)、rcu_bh_state(软中断上下文)和rcu_preempt_state(系统配置了CONFIG_PREEMPT_RCU, 默认使用这个)
(2) 注册一个SoftIRQ回调函数
(3) 初始化每个rcu_state的层次结构和相应的Per-CPU变量rcu_data
(4) 为每个rcu_state初始化一个内核线程, 以rcu_state名字命名, 执行函数是rcu_gp_kthread(), 设置当前rcu_state的GP状态是"reqwait", 睡眠等待, 直到rsp->gp_flags设置为RCU_GP_FLAG_INIT, 即收到初始化一个GP的请求, 被唤醒后, 就会调用rcu_gp_init()去初始化一个GP, 详见下面
7.4.3 开启一个GP
- 写者程序注册RCU回调函数:
RCU写者程序(!!!)通常需要调用call_rcu()、call_rcu_bh()或call_rcu_sched()等函数来通知RCU系统注册一个RCU回调函数(!!!)。对应上面的三种state.
-
参数: rcu_head(每个RCU保护的数据都会内嵌一个), 回调函数指针(GP结束<读者执行完>, 被调用销毁)
-
将rcu_head加入到本地rcu_data的nxttail链表
-
总结: 每次时钟中断处理函数tick_periodic(), 检查本地CPU上所有的rcu_state(!!!)对应的rcu_data成员nxttail链表有没有写者注册的回调函数, 有的话触发一个软中断raise_softirq().
-
软中断处理函数, 针对每一个rcu_state(!!!): 检查rcu_data成员nxttail链表有没有写者注册的回调函数, 有的话, 调整链表, 设置rsp->gp_flags标志位为RCU_GP_FLAG_INIT, rcu_gp_kthread_wake()唤醒rcu_state对应的内核线程(!!!), 现在的状态变成了“newreq”,表示有一个新的GP请求, rcu_gp_kthread_wake()唤醒rcu_state对应的内核线程(!!!)
7.4.4 初始化一个GP
RCU内核线程就会继续执行, 继续上面初始化后的动作, 执行里面的rcu_gp_init(), 去真正初始化一个GP, 这个线程是rcu_state的
(1) 当前rcu_state的rsp->completed和rsp->gpnum不相等, 说明当前已经有一个GP在运行, 不能开启一个新的, 返回
(2) 将rsp->gpnum加1
(3) 遍历所有node, 将所有node的gpnum赋值为rsp->gpnum
(4) 对于当前CPU对应的节点rcu_node,
- 若rdp->completed等于rnp->completed(当前CPU的completed等于对应节点的completed), 说明当前CPU完成一次QS;
- 不相等, 说明要开启一个GP, 将所有节点rcu_node->gpnum赋值为rsp->gpnum, rdp->passed_quiesce值初始化为0, rdp->qs_pending初始化为1, 现在状态变成"newreq->start->cpustart".
(5) 初始化GP后, 进入fswait状态, 继续睡眠等待
7.4.5 检测QS
时钟中断处理函数判断当前CPU是否经过了一个quiescent state, 即退出了RCU临界区, 退出后自下往上清理Tree RCU的qsmask位图, 直到根节点rcu_node->qsmask位图清理后, 唤醒RCU内核线程
7.4.6 GP结束
接着上面的RCU内核线程执行, 由于Tree RCU根节点的rnp->qsmask被清除干净了.
(1) 将所有节点(!!!CPU的不是节点)rcu_node->completed都设置成rsp->gpnum, 当前CPU的rdp->completed赋值为rnp->completed, GP状态"cpuend"
(2) rsp->completed值也设置成与rsp->gpnum一样, 把状态标记为“end”,最后把rsp->fqs_state的状态设置为初始值RCU_GP_IDLE, 一个GP的生命周期真正完成
7.4.7 回调函数
整个GP结束, RCU调用回调函数做一些销毁动作, 还是在RCU软中断中触发.
从代码中的trace功能定义的状态来看,一个GP需要经历的状态转换为: “newreq -> start -> cpustart -> fqswait -> cpuend ->end”。
总结Tree RCU的实现中有如下几点需要大家再仔细体会。
- Tree RCU为了避免修改CPU位图带来的锁争用,巧妙设置了树形的层次结构,rcu_data、rcu_node和rcu_state这 3 个数据结构组成一棵完美的树。
- Tree RCU的实现维护了一个状态机,这个状态机若隐若现,只有把trace功能打开了才能感觉到该状态机的存在,trace函数是trace_rcu_grace_period()。
- 维护了一些以rcu_data->nxttail[]二级指针为首的链表,该链表的实现很巧妙地运用了二级指针的指向功能。
- rcu_data、rcu_node和rcu_state这3个数据结构中的gpnum、completed、grpmask、passed_quiesce、qs_pending、qsmask等成员,正是这些成员的值的变化推动了Tree RCU状态机的运转。
8 总结
Linux中各个锁的特点和使用场景
