Tesseract-OCR 4.1 LSTM训练方法
曾参考此处->:https://blog.csdn.net/qq_30110069/article/details/98742701
Tesseract-OCR 4.1 LSTM训练流程 (win10环境)
一、配置tesseract 4.1版本
可通过自行编译源码或者下载安装文件安装tesseract。最新的tesseract 4.1 LSTM版无法找到安装文件,通过编译源码生成如下目录:

下载源码VS2017自行编译tesseract 4.1教程: https://blog.csdn.net/kds0714/article/details/90755691
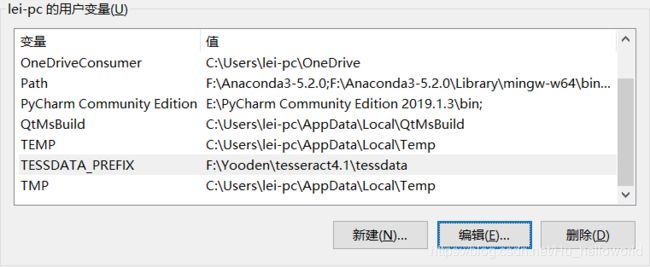
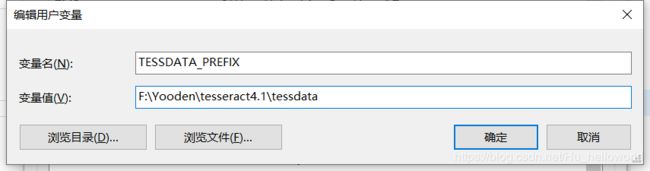
配置环境变量
1、将bin目录加到系统变量Path
2、将tessdata(训练的字库文件) 加到管理员用户变量,变量名TESSDATA_PREFIX,变量值为tessdata目录的路径
测试环境:
Win+R 分别输入:
tesseract --version
tesseract --list-langs
查看版本和当前含有的语言库,有返回值即可
二、训练流程
基本流程:
(1) jTessBoxEditor将样本合成tif文件
(2) 用已有的库识别tif文件,产生记录着数字内容,左上角坐标,宽高的.box文件。已有的库可以是下载的,也可以是自己训练出的
(3) 用jTessBoxEditor工具标注样本,调整.box文件数字内容和位置
(4) 在已有库的基础上训练样本,合成训练文件。
(5) 将合成后的文件放在tessdata文件夹中,通过代码调用来识别,测试识别率。
训练可迭代:如用eng为基础,训练样本生成nml,nml仍含有eng的效果,但按理说效果可能会减弱些。所以可以加上不同种类的样本训练成一个大字库。
准备:
训练目录下,至少应含有合成的.tif文件。需要作为基础字库的原.traineddata文件,如eng.traineddata
以官方下载的eng为例,训练nml.num.exp0
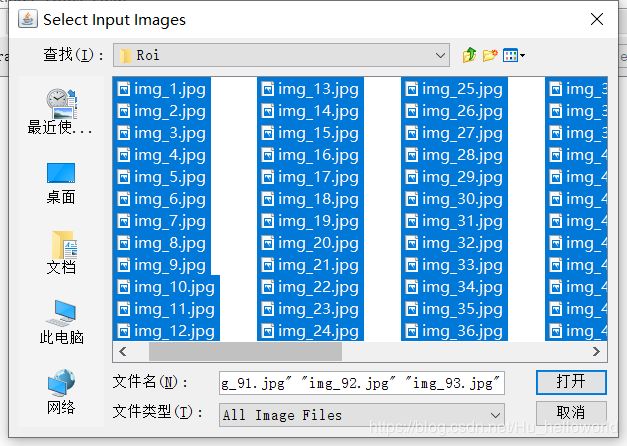
1、用jTessBoxEditor工具,将样本文件合并成.tif文件。规定如下命名格式:[lang].[fontname].exp[num].tif
如nml.num.exp0.tif,nml是语言名,num是字体名,exp0是版本号。训练过程应保持这种命名习惯
jTessBoxEditor工具的使用:

Tools -> Merge TIFF,选择文件类型为all the images,选中所有图片 -> 命名为***.tif 合并为.tif文件


2、在训练目录下打开cmd,用现有的字体库识别.tif文件,生成对应的.box文件。比如,用eng库识别样本,生成.box文件:
tesseract nml.num.exp0.tif nml.num.exp0 -l eng --psm 6 batch.nochop makebox
输入命令后,会生成nml.um.exp0.box文件。
其中命令参数含义:
nml.num.exp0.tif 上一步生成的.tif 格式的文件
nml.num.exp0 指明要生成的.box文件的名称
-l eng表示识别使用的语言是eng,
–psm表示采用的识别模式,通常6比较好。可通过tesseract --help-psm查看所有的识别模式。6指的是假设去识别一个单一的文本块。
3、jTessBoxEditor调整.box文件

Box Editor -> Open打开.tif文件,会关联同名的.box文件。调整数字时对应修改.box文件。

4、利用.tif和.box文件,生成.lstmf文件用于lstm训练
tesseract nml.num.exp0.tif nml.num.exp0 -l eng --psm 6 lstm.train
其中每个参数的意义为
nml.num.exp0.tif 上一步生成的.tif 格式的文件
nml.num.exp0 指明要生成的.lstmf文件的名称
运行后会多出一个nml.num.exp0.lstmf文件
5、用已有的或官方下载的.traineddata文件中提取.lstm文件
https://github.com/tesseract-ocr/tessdata_best 从该链接中下载所需语言的.traineddata文件
注:一定要用从上述链接中下载的.traineddata文件,其他的.traineddata文件中提取.lstm文件无法进行训练。
将下载好的.traineddata文件拷贝到训练文件夹下
combine_tessdata -e eng.traineddata eng.lstm
运行上述代码,会从.traineddata文件中提取出eng.lstm 文件
6. 创建文件,里边的内容为.lstmf文件的路径地址
7、进行训练
lstmtraining --model_output="F:\Test\AMyWork\ImgSampleLib\nomal\samples\CTCCB24\output\output" --continue_from=F:\Test\AMyWork\ImgSampleLib\nomal\samples\CTCCB24\eng.lstm"
--train_listfile="F:\Test\AMyWork\ImgSampleLib\nomal\samples\CTCCB24\eng.training_files.txt" --traineddata="F:\Test\AMyWork\ImgSampleLib\nomal\samples\CTCCB24\eng.traineddata"
--debug_interval -1 --max_iterations 2000
各个参数的意义:
–model_output 模型训练输出的路径,命令中我的训练目录是CTCCB24,新建output\output存放训练阶段文件和最终的字库
–continue_from 训练从哪里开始,这里指定从第4步中提取的eng.lstm文件。也可从之前训练生成的阶段文件output_checkpoint开始。
–train_listfile 指定上一步创建的eng.training_files.txt文件路径
–traineddata 第4步中下载的.traineddata文件的路径
–debug_interval 当值为-1时,训练结束,会显示训练的一些结果参数
–max_iterations 指明训练遍历次数。最好使用这个参数:–target_error_rate 0.01 训练至错误率低于0.01
训练结束后,在output文件夹中会生成一个output_checkpoint文件和多个类似output0.012_3.checkpoint的.checkpoint文件
8、将checkpoint文件和.traineddata文件合并成新的.traineddata文件
lstmtraining --stop_training --continue_from="F:\Test\AMyWork\ImgSampleLib\nomal\samples\CTCCB24\output\output_checkpoint"
--traineddata="F:\Test\AMyWork\ImgSampleLib\nomal\samples\CTCCB24\eng.traineddata" --model_output="F:\Test\AMyWork\ImgSampleLib\nomal\samples\CTCCB24\output\nml.traineddata"
各个参数的意义:
–stop_training 默认要有
–continue_from 上一步生成的output_checkpoint文件路径
–traineddata 第4步中下载的已有.traineddata文件的路径
–model_output zth.traineddata 输出的路径
9、将新生成的nml.traineddata文件拷贝到tessdata文件夹下,通过代码进行识别
注意:VS项目要配置好tesseract4.1的头文件、库目录,指定tessdata目录
一些质量不好的图片可能仍然需要二值化、滤波等预处理操作
bozhu不是大佬,各位看官可以结合其他博客使用。。。
项目过去了就没有及时复盘…有时间定会继续研究。
当然每人的问题可能跟环境等都有问题,当时是自己用VS2017编译的源码,后期会提供编译后文件。
当时调用时遇到过奇怪的问题:
当时是因为在自己电脑上编译,在硬件垃圾的服务器上调用。
出现 应用程序无法运行0xc000001d的问题,查找issues找到原因:编译tesseract时makefile文件默认开启cpu的AVX2指令集加速。但调用时若不支持AVX2指令集,就会报这个错误。
只有3代以上cpu才支持AVX2指令集
若有这种问题请移步:
https://blog.csdn.net/Hu_helloworld/article/details/102612794
有问题建议先查找issues,总能找到答案:
https://github.com/tesseract-ocr/tesseract/issues