python3爬虫系列10之使用pymysql+pyecharts读取Mysql数据可视化分析
python3爬虫系列10之使用pymysql+pyecharts读取Mysql数据可视化分析
上一篇文章是python3爬虫系列09之爬虫数据存入MySQL数据库,我们把智联招聘的相关岗位信息存入到了mysql数据库的一张表中去。
1. 前言
上一篇我们爬虫,爬出的数据存到了mysql数据中,然后结果是这样的:
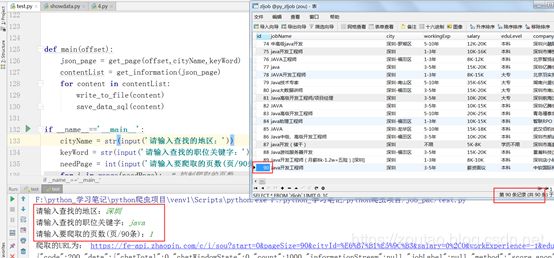
只要输入地区,职位关键字,和爬取的页数。就能快速爬取智联招聘上的数据,存在Mysql数据库中去~
(注意:我使用爬虫的时候,爬取了四个城市,分别是:深圳,成都。重庆,贵阳的java工程师岗位。一个城市90条数据,共360条。)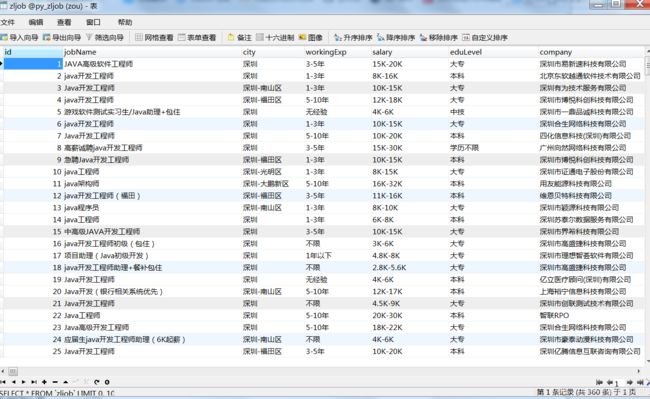
然后现在我们,有爬虫程序,有存入数据,接下来是不是该可视化分析下了?

那么问题来了,python的可视化库?
2. python数据可视化哪家强?
Matplotlib:
Matplotlib是众多 Python 可视化包的鼻祖,也是Python最常用的标准可视化库,其功能非常强大,同时也非常复杂,想要搞明白并非易事。
pandas:
但自从Python进入3.0时代以后,pandas的使用变得更加普及,它的身影经常见于市场分析、爬虫、金融分析以及科学计算中。
作为数据分析工具的集大成者,pandas作者曾说,pandas中的可视化功能比plt更加简便和功能强大。
pandas增强版pyecharts:
目前pyecharts支持的数据类型主要是list,如果不是可能会报异常。
其实在Python中有各种container, iterable. 只要不是无限长的generator,都可以直接list化,自然想到把这些类型的支持也加进去。
pyecharts还可以操作这些:
- 对于二元数据构成的list,希望通过add(name, data, **kwargs)直接绘图。pyecharts提供了方法cast,该方法主要实现:
- 将dict的keys和values分别转为attr和data,也就是x数据和y数据;
- 将形如[{k1: v1}, {k2: v2}]的数据转为两个list;
- 将形如[(k1, v1), (k2, v2)]的由二元tuple构成的list转为两个list。
因此 Pandas 和pyecharts选谁?

开玩笑的了~~~
因为我搞java的时候用过echarts,所以我选择pyecharts。
3. 使用pyecharts 绘图
官网:https://pyecharts.org
值得注意的是!!!
pyecharts 分为 v0.5.X 和 v1 两个大版本,v0.5.X 和 v1 间不兼容,v1 是一个全新的版本。
- v0.5.X 版支持 Python2.7,3.4+ 经开发团队决定,0.5.x 版本将不再进行维护。
- v1.X 版仅支持 Python3.6+ 新版本系列将从 v1.0.0 开始。
所以新版的pyecharts和旧版的区别有点大,使用方式不太一样。很多博客中还是旧版本的。
pyecharts的安装和使用:
pip install pyecharts
如果你需要使用地图类图表的,还需要安装以下地图数据包:
pip install echarts-countries-pypkg
pip install echarts-china-provinces-pypkg
pip install echarts-china-cities-pypkg
pip install echarts-china-counties-pypkg
pip install echarts-china-misc-pypkg
如图:
现在pyecharts已经更新到1.5.0版本,调用饼图所需要的参数已经不同。
我用的1.5.1版本的。
写代码在mysql查询中测试一下SQL语句:
注意,我使用了新版的pyecharts,在新版本中,Pie被放进了charts。
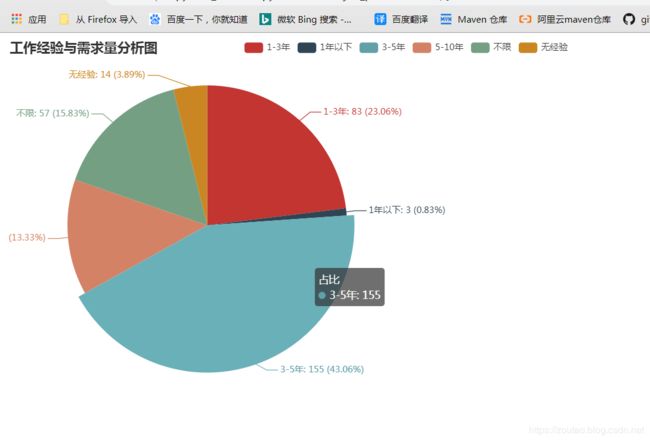
工作经验与需求量分析图:
#!/usr/bin/python3
from pyecharts.charts import Bar,Pie # 注意,新版本中,Pie被放进了charts
from pyecharts import options as opts
from job_pac.utils_mysql import Db_MySQL
# 1.设置连接方式
test = Db_MySQL('localhost', 'root', 'root', 'py_zljob')
# 2.输入sql命令
# 分组查询且分别统计数量
sql = "SELECT workingExp as '工作经验',COUNT(*) as '统计量' FROM zljob GROUP BY `workingExp` with rollup " \
"HAVING (workingExp is not null and workingExp is not null)"
# 3.调用对应的操作
results = test.getAllResult(sql)
# 4.存储结果-多组数据单独存放
namelist = []
numlist = []
for name in results:
namelist.append(name[0])
numlist.append(name[1])
print(namelist)
print(numlist)
# 4.存储结果-多组数据存在一起。
lists = []
for item in results:
for i in range(0, len(item)):
# print('查询到的数据为:', item, type(item), len(item)) # 是数组tuple,
lists.append(item[i])
print('存储:', lists)
## 数据可视化
from pyecharts.globals import ThemeType # 内置主题类型
# 按学历绘制饼图
pie = Pie()
pie.add("占比",
[list(z) for z in zip(namelist,numlist)],
center=["30%", "50%"],
)
pie.set_global_opts(
title_opts=opts.TitleOpts(title="工作经验与需求量分析图"),
legend_opts=opts.LegendOpts(pos_left="35%"),
)
# 设置显示的样子,加入了百分比
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c} ({d}%)"))
pie.render('工作经验与需求量分析图.html')
结果如图:
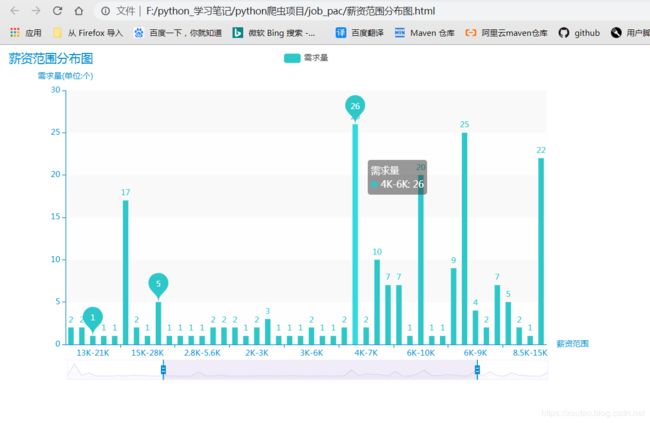
薪资范围分布图:
#!/usr/bin/python3
from pyecharts.charts import Bar,Pie # 注意,新版本中,Pie被放进了charts
from pyecharts import options as opts
from job_pac.utils_mysql import Db_MySQL
# 1.设置连接方式
test = Db_MySQL('localhost', 'root', 'root', 'py_zljob')
# 2.输入sql命令
# 分组查询且分别统计数量
sql = "SELECT salary as '薪资范围',COUNT(*) as '统计量' FROM zljob GROUP BY `salary` with rollup " \
"HAVING (salary is not null and salary is not null)"
# 3.调用对应的操作
results = test.getAllResult(sql)
# 4.存储结果-多组数据单独存放
namelist = []
numlist = []
for name in results:
namelist.append(name[0])
numlist.append(name[1])
print(namelist)
print(numlist)
## 数据可视化
from pyecharts.globals import ThemeType # 内置主题类型
# 柱状图
bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
# x为发布日期,y为客运量 间隔
bar.add_xaxis(namelist)
bar.add_yaxis("需求量", numlist, category_gap="50%")
# 基本设置
bar.set_global_opts(title_opts=opts.TitleOpts(title="薪资范围分布图"),
yaxis_opts=opts.AxisOpts(name="需求量(单位:个)"), # 设置y轴名字,x轴同理
xaxis_opts=opts.AxisOpts(name="薪资范围"),
datazoom_opts=opts.DataZoomOpts() # 设置水平缩放,默认可滑动(*好东西)
)
# 标记峰值
bar.set_series_opts(
label_opts=opts.LabelOpts(is_show=True),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_='max', name='最大值'), # 最大值标记点
opts.MarkPointItem(type_='min', name='最小值'), # 最小值标记点
opts.MarkPointItem(type_='average', name='平均值') # 平均值标记点
]
)
)
bar.render('薪资范围分布图.html') # 输出为html
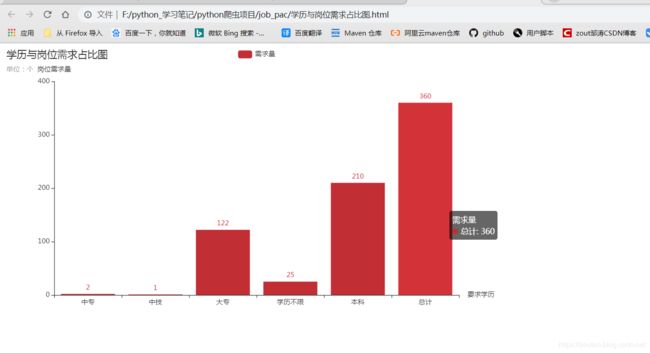
学历与岗位需求占比图:
#!/usr/bin/python3
from pyecharts.charts import Bar,Pie # 注意,新版本中,Pie被放进了charts
from pyecharts import options as opts
from job_pac.utils_mysql import Db_MySQL
# 1.设置连接方式
test = Db_MySQL('localhost', 'root', 'root', 'py_zljob')
# 2.输入sql命令
#sql='select DISTINCT eduLevel from zljob' #查学历分几类-5类
# sql='select COUNT(*) from zljob where eduLevel = "本科"' #查每一类的数量
#sql = input('请输入你的sql语句,回车执行:')
# 分组查询且分别统计数量
sql = "SELECT coalesce(eduLevel,'总计','分类情况'),COUNT(*)'统计量' FROM zljob GROUP BY `eduLevel` with rollup"
# 3.调用对应的操作
results = test.getAllResult(sql)
# 4.存储结果-多组数据单独存放
namelist = []
numlist = []
for name in results:
namelist.append(name[0])
numlist.append(name[1])
print(namelist)
print(numlist)
# 4.存储结果-多组数据存在一起。
lists = []
for item in results:
for i in range(0, len(item)):
# print('查询到的数据为:', item, type(item), len(item)) # 是数组tuple,
lists.append(item[i])
print('存储:', lists)
## 数据可视化
from pyecharts.globals import ThemeType # 内置主题类型
# 按学历绘制柱状图
bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.SHINE))
bar.add_xaxis([list(z) for z in zip(namelist)])
# bar.add_xaxis([namelist[0],namelist[1],namelist[2],namelist[3],namelist[4]])
bar.add_yaxis("需求量", [numlist[0],numlist[1],numlist[2],numlist[3],numlist[4],numlist[5]])
bar.set_global_opts(title_opts=opts.TitleOpts(title="学历与岗位需求占比图",subtitle="单位:个"),
yaxis_opts=opts.AxisOpts(name="岗位需求量"),
xaxis_opts=opts.AxisOpts(name="要求学历"),
)
bar.render('学历与岗位需求占比图.html')
源码:
代码拿走了,点个关注,留下邮箱发项目包,也不过分把? hahaha…谢谢了。
#!/usr/bin/python3
import requests
from urllib.parse import urlencode # 解决编码问题
import json
import pymysql
# 起始页,城市名,岗位词
def get_page(offset,cityName,keyWord):
# 有反爬,添加一下header
headers = {
'User - Agent': 'Mozilla / 5.0(Windows NT 6.1;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 73.0.3683.103Safari / 537.36'
}
# 构建参数组
params = {
'start': offset,
'pageSize': '90',
'cityId': cityName,
'salary': '0,0',
'workExperience': '-1',
'education': '-1',
'companyType': '-1',
'employmentType': '-1',
'jobWelfareTag': '-1',
'kw': keyWord,
'kt': '3',
'_v': '0.12973194',
'x-zp-page-request-id': '9bf58a63b73746ea9fd0cb8bd75560b9-1572848879239-667477',
'x-zp-client-id': '0470c445-5e49-43bc-b918-0330e0ead9ee'
}
base_url = 'https://fe-api.zhaopin.com/c/i/sou?'
url = base_url + urlencode(params) # 拼接url,要进行编码。
print('爬取的URL为:',url)
try:
resp = requests.get(url,headers=headers,timeout=5)
print(resp.text)
if 200 == resp.status_code: # 状态码判断
print(resp.json())
return resp.json()
except requests.ConnectionError:
print('请求出错')
return None
def get_information(json_page):
if json_page.get('data'):
results = json_page.get('data').get('results')
print(results)
for result in results:
yield { #yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。
'number':result.get('number'), # 编号
'jobName': result.get('jobName'), #岗位名称
'city': result.get('city').get('display'), # 城市地区
'company': result.get('company').get('name'), # 公司名字
# 'welfare':result.get('welfare'), #福利信息
'workingExp':result.get('workingExp').get('name'), # 工作经验
'salary':result.get('salary'), #薪资范围
'eduLevel':result.get('eduLevel').get('name')#学历
}
print('success!')
# 本地备份爬取的数据
def write_to_file(content):
#print('dict:',type(content))
with open('result.txt','a',encoding='utf-8') as f:
#print(type(json.dumps(content)))
f.write(json.dumps(content,ensure_ascii=False)+'\n') #将字典或列表转为josn格式的字符串
# 入库Mysql
def save_data_sql(content):
#print(type(content)) # 是生成器generator对象
try:
# 打开数据库连接
conn = pymysql.connect(host='localhost',user='root',password='root',db='py_zljob')
# 使用 cursor() 方法创建一个游标对象 cursor
mycursor = conn.cursor()
print('对应的是:',content['jobName'])
sql = "INSERT INTO zljob(jobName,city,workingExp,salary,eduLevel,company) \
VALUES (%s,%s,%s,%s,%s,%s)"
params = (content['jobName'],content['city'],content['workingExp'],content['salary'],content['eduLevel'],content['company'])
# 调用
mycursor.execute(sql,params)
#sql='select * from zljob'
# 执行sql语句
conn.commit()
# 获取所有记录列表
results = mycursor.fetchall()
for row in results:
print(row)
print('成功插入', mycursor.rowcount, '条数据')
except Exception:
# 发生错误时回滚
conn.rollback()
print('发生异常')
# 关闭数据库连接
mycursor.close()
conn.close()
# 数据可视化--移交到另外一个py文件
def show_sql_data():
pass
def main(offset):
json_page = get_page(offset,cityName,keyWord) # 发送请求,获得json数据
contentList = get_information(json_page) # 提取json数据对应的字段内容
for content in contentList: # 循环持久化
write_to_file(content)
#save_data_sql(content) # 在数据库新建表以后在打开这个
if __name__=='__main__':
cityName = str(input('请输入查找的地区:'))
keyWord = str(input('请输入查找的职位关键字:'))
needPage = int(input('请输入要爬取的页数(页/90条):'))
# 控制爬取的页数
for i in range(needPage):
main(offset=90*i) # 分析url知首页是90开始的,翻页是其倍数。
好了,今天的内容就到这里。
更多爬虫,在后面。