python多任务小总结
文章目录
- 开头
- 一、多任务
- 1.什么是多任务?
- 2.多任务的原理
- 3.多任务的实现
- 二、进程
- 1.什么是进程?
- 2. 创建多进程
- 3. 进程的状态
- 4. 进程之间通讯
- 5.进程池
- 三、线程
- 1、 线程概念
- 2、 进程和线程之间的关系
- 3. 使用threading模块创建线程
- 4. 使用继承方式开启线程
- 5. 线程之间共享全局变量
- 6. 共享全局变量的问题
- 7. 同步异步概念
- 8. 互斥锁
- 9. 死锁
- 10. 线程队列Queue
- 11. 生产者与消费者模型
- 12. GIL全局解释锁
- 四、协程
- 帮助理解三者
- 五、IO模型
- 结尾
开头
一、多任务
1.什么是多任务?
同时做多件事件(做个多个任务),运行多个方法
简单地说,就是操作系统可以同时运行多个任务。 现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行 多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多 任务的呢?
2.多任务的原理
1.并发:假的多任务,时间片的轮转,快速的交替运行任务
实际上就是操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务 2,任务2执行0.01秒,再切换到任务3,执行0.01秒……这样反复执行下去。 表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太 快了,我们感觉就像所有任务都在同时执行一样。
2.并行:真的多任务,一个核处理一个任务
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多 于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核 心上执行。
3.多任务的实现
那么问题来了,多任务是怎么实现的呢?
其实多任务有三种实现方式分别是
进程
线程
协程
二、进程
1.什么是进程?
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
我们想通过QQ音乐听歌,具体的过程应该是先找到QQ音乐,然后双击就会播放音乐。 当我们双击的时候,操作系统将程序装载到内存中,操作系统为它分配资源,然后才能运 行。运行起来的应用程序就称之为进程。也就是说当程序不运行的时候我们称之为程序,当 程序运行起来他就是一个进程。通俗的理解就是不运行的时候是程序,运行起来就是进程。 程序和进程的对应关系是:程序只有一个,但是进程可以有多个。
组成
进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。
特征
动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的。
并发性:任何进程都可以同其他进程一起并发执行
独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位;
异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进
结构特征:进程由程序、数据和进程控制块三部分组成。
多个不同的进程可以包含相同的程序:一个程序在不同的数据集里就构成不同的进程,能得到不同的结果;但是执行过程中,程序不能发生改变。
2. 创建多进程
1.不使用多进程实现控制台先打印唱歌然后在打印跳舞。
import time
def sing():
for i in range(3):
time.sleep(1)
print('唱第{}首歌'.format(i+1))
def dance():
for i in range(3):
time.sleep(1)
print('跳第{}曲舞'.format(i+1))
if __name__ == '__main__':
sing()
dance()
运行花费六秒
2.使用进程让唱歌跳舞一起执行
import time
from multiprocessing import Process
def sing():
for i in range(3):
time.sleep(1)
print("唱%d首歌"%(i+1))
def dance():
for i in range(3):
time.sleep(1)
print("跳%d段舞"%(i+1))
if __name__=='__main__':
p1=Process(target=sing)
p2=Process(target=dance)
p1.start()
p2.start()
运行花费三秒
可以明显感觉到程序的运行效率提高了
程序理解: 主进程从main()开始执行,执行main函数体,当执行到p1.start()时,创建一个子进程,p1 子进程中的代码和主进程相同,只是程序执行的开始是 sing函数体。 主进程执行到p2.start()时,同样复制一份主进程代码从danc函数体开始执行。
3. 进程的状态
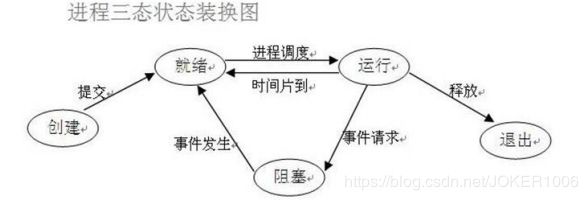
在程序运行的过程中,由于被操作系统的调度算法控制,程序会进入几个状态:就绪,运行 和阻塞。
(1)就绪(Ready)状态
当进程已分配到除CPU以外的所有必要的资源,只要获得处理机便可立即执行,这时的进程 状态称为就绪状态。
(2)执行/运行(Running)状态当进程已获得处理机,其程序正在处理机上执行,此时的 进程状态称为执行状态。 (3)阻塞(Blocked)状态正在执行的进程,由于等待某个事件发生而无法执行时,便放弃处 理机而处于阻塞状态。引起进程阻塞的事件可有多种,例如,等待I/O完成、申请缓冲区不 能满足、等待信件(信号)等。
4. 进程之间通讯
刚才我们说了进程可以理解为复制了一份程序有加载到了内存了,进程之间是独立的,如果 我想两个进程之间进行通讯怎么办呢?我们可以使用Queue 队列,队列是一种先进先出的存 储数据结构,就比如排队上厕所一个道理。 两个进程通讯,就是一个子进程往queue中写内容,另一个进程从queue中取出数据。就实现 了进程间的通讯了。
(1) .queue队列
1.创建 queue队列对象 q = multiprocessing.Queue(3) # 3表示只能存放3个数据 参数 :maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。 返回值q 是队列对象
2. put()方法 ,向队列中存放数据。如果队列已满,此方法将阻塞至有空间可用为止。
3. get()返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。
4. get_nowait(): 不等待,直接抛出异常
5. full()如果q已满,返回为True 6. q.empty() 如果调用此方法时 q为空,返回True。
# from multiprocessing import Queue
import multiprocessing
#1.创建一个列表对象
q=multiprocessing.Queue(3)
#参数 maxsize是队列中允许最大项,如果忽略此函数,则无大小限制
#2.put方法,向队列放数据
q.put('hellp')
q.put(123)
q.put([1,2,3])
print('队列中有多少数据',q.qsize())
# q.get()
# q.put('python')
#get方法,获取数据
print(q.get())
print(q.get())
print(q.get())
print(q.get_nowait())#抛出异常
# print(q.get())
# print('-----------')
#3.q.qsize,获取队列长度(队列中的数据数量)
print('队列中有多少数据',q.qsize())
#4.full() 判断队列中是否存放满了
print(q.full())
#5.empty()判断队列中数据是否空了,True表示空了
print(q.empty())
5.进程池
当需要创建的子进程数量不多时,我们可以直接利用multiporcessing中的Process动态生成 多个进程,但是如果现在有100个任务需要处理,那我们需要多少个子进程呢,如果我们创 建100个子进程也可以实现,但是资源比较浪费。我们也可以创建指定个数个子进程,例如 只创建10个子进程,让着10个子进程重复的执行任务,这样就节约了资源。 就比如我们去景区湖上游玩,游船是重复利用的。
我们可以使用multiprocessing模块提供的Pool类,也就是进程池,可以到达进程重复利 用。泸沽岛 创建进程池对象的时候可以指定一个最大进程数,当有新的请求提交到进程池中,如果池中 的进程数还没有满,那么就会创建一个新的进程用来执行该请求,但是如果池中的进程数满 了,该请求就会等待,知道进程池中的进程有结束的了,才会使用这个结束的进程来执行新 的任务。
join 主进程等待所有子进程执行完毕,必须在close之后。
close 等待所有进程结束才关闭线程池
三、线程
1、 线程概念
线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。
线程是程序中一个单一的顺序控制流程。进程内有一个相对独立的、可调度的执行单元,是系统独立调度和分派CPU的基本单位指令运行时的程序的调度单位。在单个程序中同时运行多个线程完成不同的工作,称为多线程。
由于进程是资源拥有者,创建、撤消与切换存在较大的内存开销,因此需要引入轻型进程 即线程,
进程是资源分配的最小单位,线程是CPU调度的最小单位(程序真正执行的时候调用的是线 程).每一个进程中至少有一个线程。
特点
在多线程OS中,通常是在一个进程中包括多个线程,每个线程都是作为利用CPU的基本单位,是花费最小开销的实体。线程具有以下属性。
(1)轻型实体
线程中的实体基本上不拥有系统资源,只是有一点必不可少的、能保证独立运行的资源。
线程的实体包括程序、数据和TCB。线程是动态概念,它的动态特性由线程控制块TCB(Thread Control Block)描述。TCB包括以下信息:
a. 线程状态。
b. 当线程不运行时,被保存的现场资源。
c. 一组执行堆栈。
d. 存放每个线程的局部变量主存区。
e, 访问同一个进程中的主存和其它资源。
用于指示被执行指令序列的程序计数器、保留局部变量、少数状态参数和返回地址等的一组寄存器和堆栈。
(2)独立调度和分派的基本单位。
在多线程OS中,线程是能独立运行的基本单位,因而也是独立调度和分派的基本单位。由于线程很“轻”,故线程的切换非常迅速且开销小(在同一进程中的)。
(3)可并发执行。
在一个进程中的多个线程之间,可以并发执行,甚至允许在一个进程中所有线程都能并发执行;同样,不同进程中的线程也能并发执行,充分利用和发挥了处理机与外围设备并行工作的能力。
(4)共享进程资源。
在同一进程中的各个线程,都可以共享该进程所拥有的资源,这首先表现在:所有线程都具有相同的地址空间(进程的地址空间),这意味着,线程可以访问该地址空间的每一个虚地址;此外,还可以访问进程所拥有的已打开文件、定时器、信号量机构等。由于同一个进程内的线程共享内存和文件,所以线程之间互相通信不必调用内核。
2、 进程和线程之间的关系

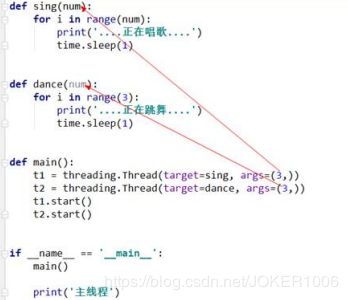
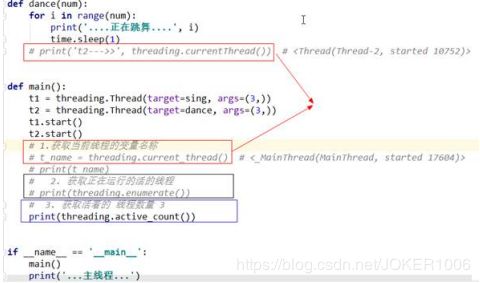
3. 使用threading模块创建线程

执行顺序: 首先程序运行时,程序从上往下走,遇到main()函数然后开始执行,执行mian()函数的函数
此时又创建了两个线程我们称之为子线程,程序运行时的线程我们称之为主线程
然后子线程根据target=xxx 开始执行指定的函数
(等子线程结束后主线程结束,程序结束了)
(1) .传递参数 给函数传递参数,使用线程的关键字 args=()进行传递参数
(2) .join()方法 join()方法功能:当前线程执行完后其他线程才会继续执行。
(3) .setDaemon() 方法 setDaemon()将当前线程设置成守护线程来守护主线程:
-当主线程结束后,守护线程也就结束,不管是否执行完成。
-应用场景:qq 多个聊天窗口,就是守护线程。
注意:需要在子线程开启的时候设置成守护线程,否则无效。

(4) .实例方法 线程对象的一些实例方法,了解即可
- getName(): 获取线程的名称。
- setName(): 设置线程的名称。
- isAlive(): 判断当前线程存活状态。

(5) .threading模块提供的方法 threading.currentThread(): 返回当前的线程变量。 threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、 结束前,不包括启动前和终止后的线程。 threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果
4. 使用继承方式开启线程
1.定义一个类继承threading.Thread类。
2.复写父类的run()方法。
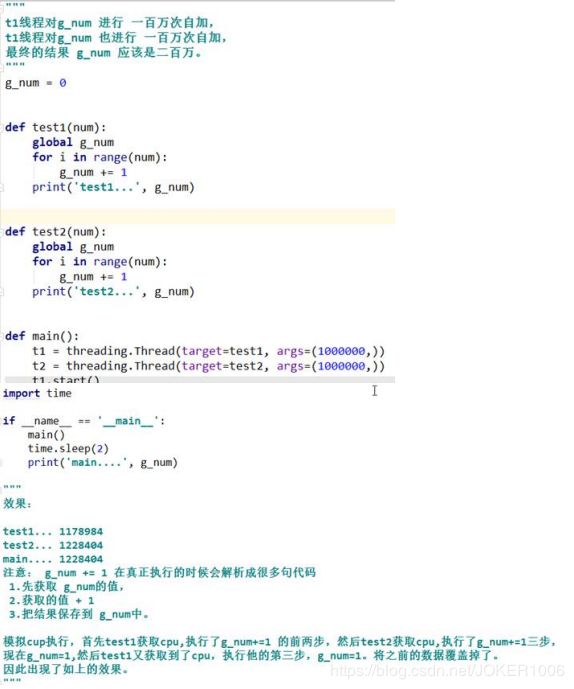
5. 线程之间共享全局变量

6. 共享全局变量的问题
7. 同步异步概念
同步的意思就是协同步调,按预定的先后次序执行。例如你先说完然后我再说。 大家不要将同步理解成一起动作,同步是指协同、协助、互相配合。 例如线程同步,可以理解为线程A和B一块配合工作,A执行到一定程度时要依靠B的某个结 果,于是停下来示意B执行,B执行完将结果给A,然后A继续执行。 A强依赖B(对方),A必须等到B的回复,才能做出下一步响应。即A的操作(行程)是顺序执行 的,中间少了哪一步都不可以,或者说中间哪一步出错都不可以。 举个例子:
你去外地上学(人生地不熟),突然生活费不够了;此时你决定打电话回家,通知家里转生活 费过来,可是当你拨出电话时,对方一直处于待接听状态(即:打不通,联系不上),为了拿 到生活费,你就不停的oncall、等待,最终可能不能及时要到生活费,导致你今天要做的事 都没有完成,而白白花掉了时间。 异步: 异步则相反,A并不强依赖B,A对B响应的时间也不敏感,无论B返回还是不返回,A都能继续 运行;B响应并返回了,A就继续做之前的事情,B没有响应,A就做其他的事情。也就是说A 不存在等待对方的概念。 举个例子: 在你打完电话发现没人接听时,猜想:对方可能在忙,暂时无法接听电话,所以你发了一条 短信(或者语音留言,亦或是其他的方式)通知对方后便忙其他要紧的事了;这时你就不需要 持续不断的拨打电话,还可以做其他事情;待一定时间后,对方看到你的留言便回复响应 你,当然对方可能转钱也可能不转钱。但是整个一天下来,你还做了很多事情。 或者说你 找室友临时借了一笔钱,又开始happy的上学时光了。 对于多线程共享全局变量计算错误的问题,我们可以使用线程同步来进行解决。
8. 互斥锁
当多个线程几乎同时修改一个共享数据的时候,需要进行同步控制,线程同步能够保证多个 线程安全的访问竞争资源(全局内容),最简单的同步机制就是使用互斥锁。 某个线程要更改共享数据时,先将其锁定,此时资源的状态为锁定状态,其他线程就能更 改,直到该线程将资源状态改为非锁定状态,也就是释放资源,其他的线程才能再次锁定资 源。互斥锁保证了每一次只有一个线程进入写入操作。从而保证了多线程下数据的安全性。
9. 死锁
在多个线程共享资源的时候,如果两个线程分别占有一部分资源,并且同时等待对方的资 源,就会造成死锁现象。 如果锁之间相互嵌套,就有可能出现死锁。因此尽量不要出现锁之间的嵌套。
10. 线程队列Queue
队列是一种先进先出(FIFO)的存储数据结构,就比如排队上厕所一个道理。
1.创建一个“队列”对象 import Queue # 导入模块 q = Queue.Queue(maxsize = 10) Queue.Queue类即是一个队列的同步实现。队列长度可为无限或者有限。可通过Queue的构造 函数的可选参数maxsize来设定队列长度。如果maxsize小于1就表示队列长度无限。
2.将一个值放入队列中 q.put(10) 调用队列对象的put()方法在队尾插入一个项目。
3. 将一个值从队列中取出q.get() 从队头删除并返回一个项目。如果取不到数据则一直等待。
4.q.qsize() 返回队列的大小
5.q.empty() 如果队列为空,返回True,反之False
6.q.full() 如果队列满了,返回True,反之False 7.q.put_nowait(item) ,如果取不到不等待,之间抛出异常。 8.q.task_done() 在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一 个信号
9.q.join() 收到q.task_done()信号后再往下执行,否则一直等待。或者最开始时没有放数 据join()不会阻塞。
q.task_done() 和 q.join() 通常一起使用。
11. 生产者与消费者模型
在并发编程中,如果生产者处理速度很快,而消费者处理速度比较慢,那么生产者就必须等 待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那 么消费者就必须等待生产者。为了解决这个等待的问题,就引入了生产者与消费者模型。让 它们之间可以不停的生产和消费
什么是生产者消费者模式
生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据 之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞 队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。 这就像,在餐厅,厨师做好菜,不需要直接和客户交流,而是交给前台,而客户去饭菜也不 需要不找厨师,直接去前台领取即可。
12. GIL全局解释锁
GIL 即 :global interpreter lock 全局解释所。 在进行GIL讲解之前,我们可以先了解一下并行和并发: 并行:多个CPU同时执行多个任务,就好像有两个程序,这两个程序是真的在两个不同的CPU 内同时被执行。 并发:CPU交替处理多个任务,还是有两个程序,但是只有一个CPU,会交替处理这两个程 序,而不是同时执行,只不过因为CPU执行的速度过快,而会使得人们感到是在“同时”执 行,执行的先后取决于各个程序对于时间片资源的争夺. 并行和并发同属于多任务,目的是要提高CPU的使用效率。这里需要注意的是,一个CPU永远 不可能实现并行,即一个CPU不能同时运行多个程序。 Guido van Rossum(吉多·范罗苏姆)创建python时就只考虑到单核cpu,解决多线程之间 数据完整性和状态同步的最简单方法自然就是加锁, 于是有了GIL这把超级大锁。因为 cpython解析只允许拥有GIL全局解析器锁才能运行程序,这样就保证了保证同一个时刻只允 许一个线程可以使用cpu。也就是说多线程并不是真正意义上的同时执行。
四、协程
协程与子例程一样,协程(coroutine)也是一种程序组件。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。协程源自 Simula 和 Modula-2 语言,但也有其他语言支持。
协程不是进程或线程,其执行过程更类似于子例程,或者说不带返回值的函数调用。
协程:协助程序,线程和进程都是抢占式特点,线程和进程的切换我们是不能参与的。 而协程是非抢占式特点,协程也存在着切换,这种切换是由我们用户来控制的。 协程主解决的是IO的操作。
一个程序可以包含多个协程,可以对比与一个进程包含多个线程, 因而下面我们来比较协程和线程。我们知道多个线程相对独立,有自己的上下文,切换受系统控制;而协程也相对独立,有自己的上下文,但是其切换由自己控制,由当前协程切换到其他协程由当前协程来控制。
协程和线程区别:协程避免了无意义的调度,由此可以提高性能,但也因此,程序员必须自己承担调度的责任,同时,协程也失去了标准线程使用多CPU的能力。
优点1: 协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因 此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
优点2: 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中 控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。 因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利 用多核,又充分发挥协程的高效率,可获得极高的性能。
帮助理解三者
1、计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行。
2、假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单个CPU一次只能运行一个任务。
3、进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态
4、一个车间里,可以有很多工人。他们协同完成一个任务。
5、线程就好比车间里的工人。一个进程可以包括多个线程。
6、车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。
7、可是,每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。
8、一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫”互斥锁”(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域。
9、 还有些房间,可以同时容纳n个人,比如厨房。也就是说,如果人数大于n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用。
10、这时的解决方法,就是在门口挂n把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法叫做”信号量”(Semaphore),用来保证多个线程不会互相冲突。
不难看出,mutex是semaphore的一种特殊情况(n=1时)。也就是说,完全可以用后者替代前者。但是,因为mutex较为简单,且效率高,所以在必须保证资源独占的情况下,还是采用这种设计。
11、 操作系统的设计,因此可以归结为三点:
(1)以多进程形式,允许多个任务同时运行;
(2)以多线程形式,允许单个任务分成不同的部分运行;
(3)提供协调机制,一方面防止进程之间和线程之间产生冲突,另一方面允许进程之间和线程之间共享资源。
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。同时,线程适合于在SMP机器上运行,而进程则可以跨机器迁移。
五、IO模型
传统的编程是如下线性模式的: 开始—>代码块A—>代码块B—>代码块C—>代码块D—>…—>结束 每一个代码块里是完成各种各样事情的代码,但编程者知道代码块A,B,C,D…的执行顺序, 唯一能够改变这个流程的是数据。输入不同的数据,根据条件语句判断,流程或许就改为A- -->C—>E…—>结束。每一次程序运行顺序或许都不同,但它的控制流程是由输入数据和 你编写的程序决定的。如果你知道这个程序当前的运行状态(包括输入数据和程序本身), 那你就知道接下来甚至一直到结束它的运行流程。
对于事件驱动型程序模型,它的流程大致如下:
开始—>初始化—>等待
与上面传统编程模式不同,事件驱动程序在启动之后,就在那等待,等待什么呢?等待被事 件触发。传统编程下也有“等待”的时候,比如在代码块D中,你定义了一个input(),需要 用户输入数据。但这与下面的等待不同,传统编程的“等待”,比如input(),你作为程序 编写者是知道或者强制用户输入某个东西的,或许是数字,或许是文件名称,如果用户输入 错误,你还需要提醒他,并请他重新输入。事件驱动程序的等待则是完全不知道,也不强制 用户输入或者干什么。只要某一事件发生,那程序就会做出相应的“反应”。这些事件包 括:输入信息、鼠标、敲击键盘上某个键还有系统内部定时器触发
结尾
文章目录
- 开头
- 一、多任务
- 1.什么是多任务?
- 2.多任务的原理
- 3.多任务的实现
- 二、进程
- 1.什么是进程?
- 2. 创建多进程
- 3. 进程的状态
- 4. 进程之间通讯
- 5.进程池
- 三、线程
- 1、 线程概念
- 2、 进程和线程之间的关系
- 3. 使用threading模块创建线程
- 4. 使用继承方式开启线程
- 5. 线程之间共享全局变量
- 6. 共享全局变量的问题
- 7. 同步异步概念
- 8. 互斥锁
- 9. 死锁
- 10. 线程队列Queue
- 11. 生产者与消费者模型
- 12. GIL全局解释锁
- 四、协程
- 帮助理解三者
- 五、IO模型
- 结尾