爬取京东淘宝商品销量并可视化处理数据
目的:获取京东和淘宝的同一种手机型号的销量信息,获取三组,对比销量,并将数据可视化处理。
一、京东销量获取
如下面的例子:
京东销量:
data-sku:对应下一个页面的productId
defaultGoodCount:代表销量
commentCount评论数==总销量
fetchJSON_comment98({
"productAttr": null,
"productCommentSummary": {
"skuId": 100011336064,
"defaultGoodCount": 133870,
"defaultGoodCountStr": "13万+",
"commentCount": 193409,
"commentCountStr": "19万+",
"goodCount": 55121,
"goodCountStr": "5.5万+",
},
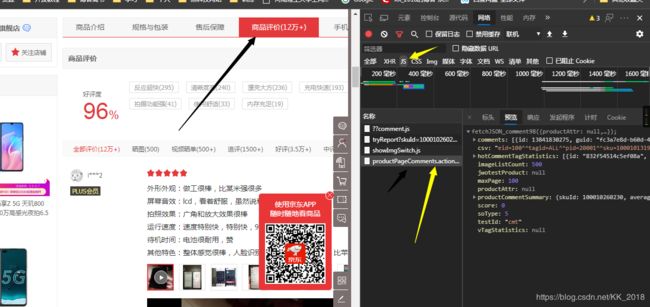
怎么找到上面的信息呢?就拿荣耀V30手机来讲。
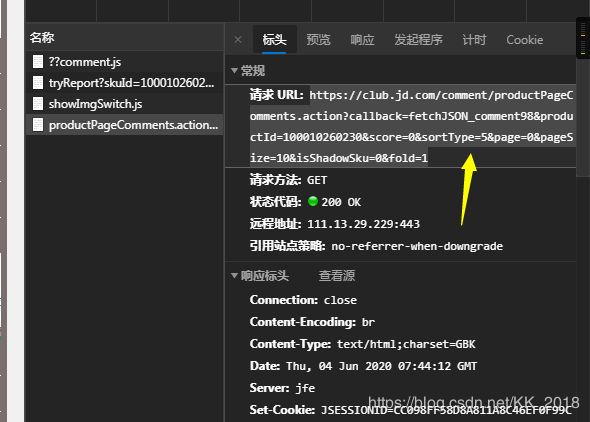
打开开发者工具,点击商品评价,会出现一大堆数据,我们选择JS,然后选择productPageComments.action
OK,在请求头中就能看到我们想要的链接。然后利用正则表达式提取我们想要的信息即可。
二、淘宝销量获取
如下面的例子:
淘宝销量:
1、view_sales
2、setMdskip
({
"defaultModel": {
"sellCountDO": {
"sellCount": "1.5万+",
"success": true
}
}
})
3、comment_count评论数==总销量(我们采用这种方法)那么怎么获取我们想要的信息呢?我们输入商品后,选择销量排序,会得到这样的一个链接
"https://s.taobao.com/search?q=" + "商品名称" + "&sort=sale-desc"
右键查看源代码,即可找到我们想到的信息,即“comment_count”,OK,这样不就好办了吗?直接正则表达式提取即可!
三、代码:
import requests
import re
import csv
from matplotlib import pyplot as plt
import matplotlib as mpl
import numpy as np
list = [] # 列表用来存放商品信息
# 构造淘宝请求头
kv = {
"user-agent":
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36",
"Cookie":
''
}
# 京东请求头
jd = {
"user-agent":
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
# 获取淘宝HTML页面
def getHTMLpages(url):
try:
r = requests.get(url, headers=kv, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 获取京东HTML页面
def getHTMLpages_JD(url):
try:
r = requests.get(url, headers=jd)
# print(r.status_code) # 打印状态码,若为200则正常
page_connent = r.content.decode('gbk') # 设置内容编码格式为gbk
return page_connent
except:
return "异常"
# 将淘宝商品信息存入列表
def getGoodsinfo(list, html, flag):
if flag == 0:
tit = "荣耀v30手机"
elif flag == 1:
tit = "小米10手机"
else:
tit = "vivoS6手机"
sales = re.findall(r'\"comment_count\"\:\"[\d]*?\"', html) # 正则表达式查找总销量
sal = eval(sales[0].split(':')[1]) # eval去掉引号,split(":")[1]表示":"后面的内容
list.append([tit, "淘宝", sal]) # 将信息存进列表
return list
# 将京东商品信息存入列表
def getGoodsinfo_JD(list, html_jd, flag):
if flag == 0:
tit = "荣耀v30手机"
elif flag == 1:
tit = "小米10手机"
else:
tit = "vivoS6手机"
sales = re.findall(r'\"commentCount\"\:[\d]*', html_jd) # 正则表达式查找总销量
sal = eval(sales[0].split(':')[1])
list.append([tit, "京东", sal])
# 从列表中读取商品信息
def printGoodsinfo(list):
form = "{:<10}\t\t{:<10}\t{:<8}"
print(form.format("手机型号", "销售平台", "商品销量", chr(12288)))
for i in list: # i代表一行
print(form.format(i[0], i[1], i[2], chr(12288)))
# 保存数据为csv文件
def saveData(list):
try:
# 创建文件对象
f=open('D:\\GoodsInfo.csv','w',newline='',encoding='gbk')
# newline=''是为了去掉每条数据下面的空行
# 基于文件对象构建csv写入对象
csv_writer = csv.writer(f)
# 构建列表头
csv_writer.writerow(["手机型号", "销售平台", "商品销量"])
# 写入csv文件内容
for i in range(len(list)):
csv_writer.writerow(list[i])
f.close()
print("保存成功!文件为D盘下的GoodsInfo.csv")
except:
print("保存失败!")
# 根据csv文件绘图
def drawData(list):
fig, ax = plt.subplots() # 新建一个fig和axes对象
mpl.rcParams["font.sans-serif"] = ["SimHei"] # 设置字体
mpl.rcParams["axes.unicode_minus"] = False
x = np.arange(3) # x轴下标数量
count_taobao = [] # 构造列表淘宝销量
count_jd = [] # 京东销量
for i in range(len(list)):
if (i % 2 == 0): # 下标0、2、4为淘宝销量
count_taobao.append(int(list[i][2]))
else: # 下标1、3、5为京东销量
count_jd.append(list[i][2])
bar_width = 0.35 # 柱条宽度
tick_label = ["荣耀V30手机", "小米10手机", "vivoS6手机"] # x轴坐标
plt.bar(
x,
count_taobao,
bar_width,
align="center",
color="c",
label="淘宝平台",
alpha=0.5) # alpha表透明度
plt.bar(
x + bar_width,
count_jd,
bar_width,
color="b",
align="center",
label="京东平台",
alpha=0.5)
plt.xlabel("手机型号")
plt.ylabel("平台销量")
ax.set_title("三种型号手机在京东和淘宝销量对比图") # 设置标题
plt.xticks(x + bar_width / 2, tick_label) # 实现并列效果
plt.legend() # 显示图例
plt.savefig('D:\\drawData.png') # 保存图片
plt.show() # 将图片显示出来
if __name__ == "__main__":
print("该程序将自动分别爬取华为荣耀V30、小米10和vivoS6手机在淘宝和京东的销量")
print("程序即将开始执行......")
print("开始爬取华为荣耀V30在淘宝的销量数据...")
# 此链接为按照销量排序的链接
start_url_taobao = "https://s.taobao.com/search?q=" + "荣耀v30" + "&sort=sale-desc"
html = getHTMLpages(start_url_taobao)
getGoodsinfo(list, html, 0)
print("开始爬取华为荣耀V30在京东的销量数据...")
start_url_jd = "https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100010260230&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1"
html_jd = getHTMLpages_JD(start_url_jd)
# print(html_jd)
getGoodsinfo_JD(list, html_jd, 0)
print("开始爬取小米10在淘宝的销量数据...")
start_url_taobao = "https://s.taobao.com/search?q=" + "小米10手机" + "&sort=sale-desc"
html = getHTMLpages(start_url_taobao)
getGoodsinfo(list, html, 1)
print("开始爬取小米10在京东的销量数据...")
start_url_jd = "https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100011336064&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1"
html_jd = getHTMLpages_JD(start_url_jd)
getGoodsinfo_JD(list, html_jd, 1)
print("开始爬取vivoS6在淘宝的销量数据...")
start_url_taobao = "https://s.taobao.com/search?q=" + "vivoS6" + "&sort=sale-desc"
html = getHTMLpages(start_url_taobao)
getGoodsinfo(list, html, 2)
print("开始爬取vivoS6在京东的销量数据...")
start_url_jd = "https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100011924580&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1"
html_jd = getHTMLpages_JD(start_url_jd)
getGoodsinfo_JD(list, html_jd, 2)
print("爬取完毕!结果如下:")
printGoodsinfo(list)
print("现在将数据存入CSV文件中...")
saveData(list)
print("现在将数据可视化展示出来:")
drawData(list)
print("图片保存位置为D盘的drawData.png")