MySQL数据库开发
一、初识数据库
1.数据库的由来
基于以前的知识,应用程序对数据的管理往往是保存在文件中,存在以下几个问题:
- 程序所有的组件就不可能运行在一台机器上(性能受限)
- 数据安全问题,多台计算机本地文件进行修改并不能同步到其他计算机上;或者文件存放于同一台电脑上存在多个终端修改文件加锁处理
解决方案:
1、将文件单独存放在一台计算机上(数据库服务器),其他计算机通过socket访问数据
2、单独写一个数据管理程序实现以下功能:
a. 远程连接(支持并发) b. 打开文件 c. 读写文件(加锁)d.关闭文件
我们在编写任何程序之前,都需要事先写好基于网络操作一台主机上文件的程序(socket服务端与客户端程序),于是有人将此类程序写成一个专门的处理软件,这就是mysql等数据库管理软件的由来,但mysql解决的不仅仅是数据共享的问题,还有查询效率,安全性等一系列问题
2.数据库相关概念
- 1、数据库服务器:运行数据库管理软件的计算机
- 2、数据库管理软件:mysql,oracle,db2,slqserver
- 3、库:文件夹(将文件进行分类管理)
- 4、表:文件(将记录的数据通过字段(类似key)和值(类似value)和数据类型一一匹配存入文件)
- 5、记录:事物一系列典型的特征(单一数据无法体现对象的特征):egon,male,18,oldgirl
- 6、数据:描述事物特征的符号:性别=男
3.MySQL安装与基本管理
3.1 MySQL是什么?
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下公司。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一
MySQL就是一个基于socket编写的C/S架构的软件
客户端软件
mysql自带:如mysql命令,mysqldump命令等
python模块:如pymysql(在python环境下去调用功能)
数据库管理软件分类
- 分两大类:
关系型:如sqllite,db2,oracle,access,sql server,MySQL,注意:sql语句通用
非关系型:mongodb,redis,memcache - 可以简单的理解为:
关系型数据库需要有表结构
非关系型数据库是key-value存储的,没有表结构
3.2 下载安装
- Linux版本
#二进制rpm包安装
yum -y install mysql-server mysql
源码安装见:http://www.cnblogs.com/linhaifeng/articles/7126847.html
- Window版本
1、下载:MySQL Community Server 5.7.16
http://dev.mysql.com/downloads/mysql/
2、解压
如果想要让MySQL安装在指定目录,那么就将解压后的文件夹移动到指定目录,如:C:\mysql-5.7.16-winx64
3、添加环境变量
【右键计算机】–》【属性】–》【高级系统设置】–》【高级】–》【环境变量】–》【在第二个内容框中找到 变量名为Path 的一行,双击】 --> 【将MySQL的bin目录路径追加到变值值中,用 ; 分割】
4、初始化
mysqld --initialize-insecure
5、启动MySQL服务
mysqld # 启动MySQL服务
6、启动MySQL客户端并连接MySQL服务
mysql -u root -p # 连接MySQL服务器
上一步解决了一些问题,但不够彻底,因为在执行【mysqd】启动MySQL服务器时,当前终端会被hang住,那么做一下设置即可解决此问题,即将MySQL服务制作成windows服务
注意:–install前,必须用mysql启动命令的绝对路径
制作MySQL的Windows服务,在终端执行此命令:(做成系统服务)
“c:\mysql-5.7.16-winx64\bin\mysqld” --install
移除MySQL的Windows服务,在终端执行此命令:
“c:\mysql-5.7.16-winx64\bin\mysqld” --remove
注册成服务之后,以后再启动和关闭MySQL服务时,仅需执行如下命令:
启动MySQL服务
net start mysql
关闭MySQL服务
net stop mysql
3.3 登录设置密码
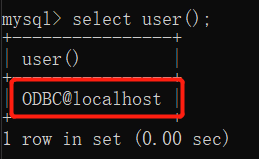
1. 查看当前登录账号:select user();
2. 使用其他账号登录:mysql -uroot -p
mysql -u用户名 -p密码,root账号密码默认为空,回车后输密码(无密码直接回车)
![]()
3. 修改账号密码:mysqladmin -uroot -pabc password"123"
mysqladmin -u用户名 -p旧密码 password"新密码"

4. 破解密码
做成系统服务后,可以通过net start(stop) MySQL启动或暂停mysql服务

第一步:重新打开mysqld(服务端),用非一般的登陆方式:mysqld --skip-grant-tables(跳过授权表)

第二步:打开mysql,mysql -uroot -p(无需密码)

第三步:修改root账户密码:
先update mysql.user set password=password(“111”) where user=“root” and host=“localhost”;
再flush privileges
解读:更新mysql.user这个数据表设置密码等于password(“111”)(调用mysql内置password方法)限定用户名等于root,账号是本地账号,再刷新授权

第四步:杀死mysqld(服务端)进程,因为现在还是skip grant模式打开

5. 连接远程服务端,输入IP端口
mysql -uroot -p111 -h 127.0.0.1 -P 3306(IP默认本地IP,端口默认3306)

4. 统一字符编码
mysql有读文件写文件操作,如果字符编码不统一会导致乱码的情况
第一步:登陆mysql,输入\s查看字符编码

第二步:在mysql根目录(bin同级)下创建my.ini文件,复制以下配置信息进去
[mysqld]
character-set-server=utf8
collation-server=utf8_general_ci
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
如果是mysqld(服务端)登陆读取第一个section配置,如果是mysql(客户端)登陆读取第三个section配置,如果是其他Java等端口登陆读取clien这个section
第三步:重启mysqld(服务端)再用\s查看

5. 初识sql语句
SQL(Structured Query Language 即结构化查询语言)分为三种
- DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
- DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT
- DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
当前语句出现错误,可以通过\c取消当前语句输入


5.1 操作文件夹(库)
1. 增
create database db1 charset utf8;
创建文件夹名字叫db1,字符编码为utf-8

创建的文件夹在mysql安装目录下的data文件夹内
2. 查
show create database db1;
查看刚刚创建的数据库参数信息

show databases;
查看所有的数据库,包含自带的数据库

3. 改(修改字符编码)
alter database db1 charset gbk;
4. 删
drop database db1;
5. 切换文件夹
use db1;
6. 显示当前文件夹
select database();
5.2 操作文件(表)
1. 增
create table t1(id int,name char);
创建表,名字叫t1,其中含有id字段1(整数int类型),还有name字段2(字符char类型)

2. 查
show create table t1;

show tables;查看所有表格
desc t1;
描述(describe)t1这张表结构

3. 改(改字段)
alter table t1 modify name char(6); #修改字段的值
修改表t1,调整字段name的值为字符且宽度为6
alter table t1 change name Name char(7); #既修改字段名,又修改字段值
修改表t1,改变原本叫name的字段为Name,并且值改为char(7)
4. 删
drop table t1;
5.3 操作文件内容(记录)
1. 增
insert t1(id,name) values(1,“egon1”),(2,“egon2”);
insert 表名(字段1,字段2) 值(id值1,name值1),(id值2,name值2)
- 可以不加字段insert t1 values(1,“egon1”),(2,“egon2”);
- 可以互换字段顺序,同时值也要互换顺序insert t1(name,id) values(“egon1”,1),(“egon2”,2);
2. 查
select id,name from db1.t1;
- 当字段过多可以select * from db1.t1;
- 也可以只查id一个字段
- 如果已经在表的当前文件夹就可以改db1.t1为t1

3. 改
update db1.t1 set name=“SB” #将所有id的名字都从egon改为SB
update db1.t1 set name=“SB” where id=2; #只改id为2的名字改为SB
4. 删
delete from t1; #删除所有记录
delete from t1 where id=2; #只删除id=2的记录
二、库操作
1. 系统数据库
- information_schema: 虚拟库,不占用磁盘空间(加载到内存中),存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等
- performance_schema: MySQL 5.5开始新增一个数据库:主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象
- mysql: 授权库,主要存储系统用户的权限信息
- test: MySQL数据库系统自动创建的测试数据库
2. 数据库命名规则
可以由字母、数字、下划线、@、#、$
区分大小写
唯一性
不能使用关键字如 create select
不能单独使用数字
最长128位
3. 数据库相关操作
查看数据库
show databases;
show create database db1;
select database();
选择数据库
USE 数据库名
删除数据库
DROP DATABASE 数据库名;
修改数据库
alter database db1 charset utf8;
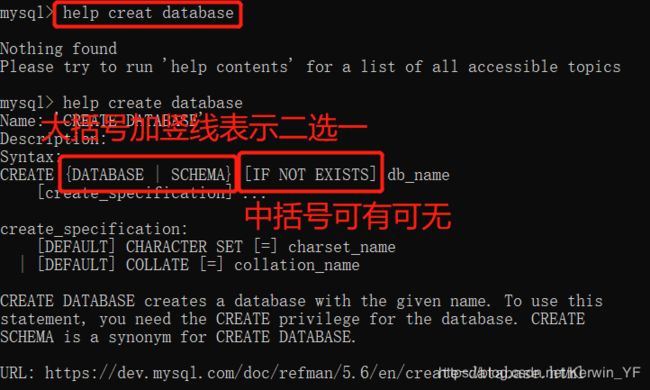
4. help帮助
当你忘记sql语句时可以用help方法提供帮助:

三、表操作
1. 存储引擎介绍
1.1 什么是存储引擎
常规情况下我们操作不同类型的文件会用不同的打开方式,例如mp4格式用暴风影音,jpg格式用美图等,MySQL中不同类型的文件都叫做表,那么处理不同类型的表就会使用不同的存储机制,所以存储引擎就是表的类型
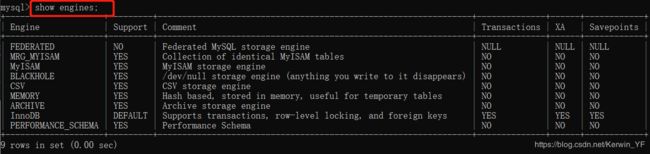
1.2 查看MySQL支持的存储引擎
show engines; #查看所有支持的存储引擎
show variables like ‘storage_engine’; #查看正在使用的存储引擎
1.3 指定存储引擎(表类型)
#创建四个表类型
create table t1(id int)engine=innodb; #最常用的存储引擎
create table t2(id int)engine=memory; #数据都存储在内存
create table t3(id int)engine=blackhole; #数据丢进去全都没有了,适合处理垃圾
create table t4(id int)engine=myisam; #支持全文索引

- t1有两个文件:表结构和表数据
- t2有一个文件:表结构,表数据存储在内存中
- t3有一个文件:表结构,表数据没有了
- t4有三个文件:表结构,MYD就是myisam的data文件,MYI就是myisam的索引文件
#给四种表类型插入参数
insert into t1 values(1);
insert into t2 values(1);
insert into t3 values(1);
insert into t4 values(1);
#通过select * from t;查询数据 - t1和t4都有插入数据,t3黑洞模式没有插入
- t2查看数据有,但是关闭mysql重启后就没有了,因为数据存储在内存中
2. 表的增删改查
2.1 表介绍
表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段

id,name,qq,age称为字段,其余的,一行内容称为一条记录
2.2 创建表
语法:#中括号内可写可不写,每个values中间加逗号,最后一个加分号;
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
);
#注意:
- 在同一张表中,字段名是不能相同
- 宽度和约束条件可选
- 字段名和类型是必须的
2.3 查看表
查看表结构(字段):desc t1;
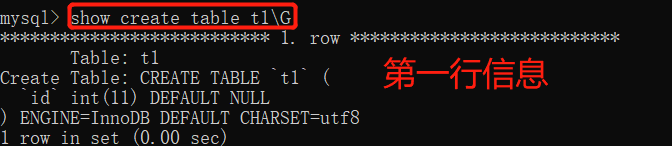
查看表的详细信息:show create t1;

当查看表过长显示不完全,可以以每行展示的方式show:show create table t1\G(不加分号)
2.4 修改表(结构、字段)
语法:#只是修改表的名字,字段(数据类型),不包括修改记录
1. 修改表名 #不区分大小写
ALTER TABLE 表名
>>> RENAME 新表名;
2. 增加字段
- ALTER TABLE 表名
ADD 字段名 数据类型 [完整性约束条件…],
>>>ADD 字段名 数据类型 [完整性约束条件…]; - ALTER TABLE 表名 #放在第一个字段
>>> ADD 字段名 数据类型 [完整性约束条件…] FIRST; - ALTER TABLE 表名 #放在哪个字段之后
>>>ADD 字段名 数据类型 [完整性约束条件…] AFTER 字段名;
3. 删除字段
ALTER TABLE 表名 DROP 字段名;
4. 修改字段
ALTER TABLE 表名
MODIFY 字段名 数据类型 [完整性约束条件…];
ALTER TABLE 表名
CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件…];
示范:
1.修改存储引擎
mysql> alter table service
-> engine=innodb;
2.添加字段
mysql> alter table student10
-> add name varchar(20) not null,
-> add age int(3) not null default 22;
mysql> alter table student10
-> add stu_num varchar(10) not null after name; //添加name字段之后
mysql> alter table student10
-> add sex enum(‘male’,‘female’) default ‘male’ first; //添加到最前面
3.删除字段
mysql> alter table student10
-> drop sex;
mysql> alter table service
-> drop mac;
4.修改字段类型modify
mysql> alter table student10
-> modify age int(3);
mysql> alter table student10
-> modify id int(11) not null primary key auto_increment; //修改为主键
5.增加约束(针对已有的主键增加auto_increment)
mysql> alter table student10 modify id int(11) not null primary key auto_increment;
ERROR 1068 (42000): Multiple primary key defined
mysql> alter table student10 modify id int(11) not null auto_increment;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
6.对已经存在的表增加复合主键
mysql> alter table service2
-> add primary key(host_ip,port);
7.增加主键
mysql> alter table student1
-> modify name varchar(10) not null primary key;
8.增加主键和自动增长
mysql> alter table student1
-> modify id int not null primary key auto_increment;
9.删除主键
a. 删除自增约束
mysql> alter table student10 modify id int(11) not null;
b. 删除主键
mysql> alter table student10
-> drop primary key;
2.5 复制表
复制表结构(字段)+记录:
create table t2 select * from t1;
只想复制字段id和name的话:create table t2 select id,name from t1;
解析:
执行select * from t1;命令会将结果打印到屏幕,当跟在create table t2后面会将结果传给创建的表t2达到复制的效果
只复制表结构,不复制记录:
create table t2 select id,name from t1 where 1>2;
解析:
1>2是一个False条件,查询不到任何记录,所以不会有记录复制过来,但字段仍然会复制
create table t2 like t1;
解析:
将t1的所有表结构复制过来,但不会复制记录
四、数据类型
1. 数值类型
1.1 整数类型
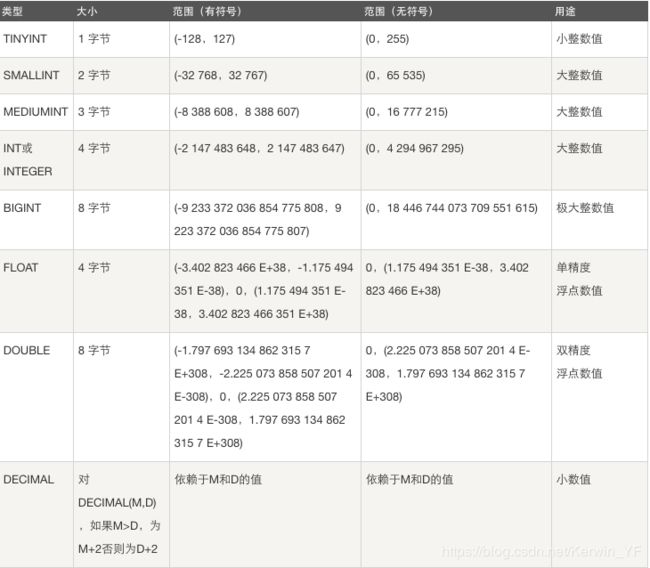
以tinyint举例,它有符号的数值范围是(-128,127),无符号范围是(0,255)
- 因为它的数据存储只有1个字节,也就是8个bit,可表示数值只有2的8次方
- 默认为有符号显示,若要设置为无符号需要增加限制条件unsigned
- 当插入数据大于这个范围时只会显示最大(小)值

- 整数类型指定宽度create table t1(id int(5));
这里的int(5)指的是设定显示宽度为5,并不影响存储宽度(int的存储宽度还是为4个字节,最大数据2**32)
当数据只有2位例如13时,达不到显示宽度5可以用zerofill体现出来,超过显示宽度会正常显示
所以!整形类型,其实没有必要指定显示宽度,使用默认的就ok

为什么int unsigned默认宽度为10,int默认宽度为11:
因为int unsigned不带符号最大数4294967295是10位
int带符号最小数-2147483648加上负号共11位
1.2 浮点型
浮点型的精度:FLOAT ====================================== 定义: 有符号: 精确度: ====================================== 定义: 有符号: 无符号: 精确度: ====================================== 定义: 精确度: datetime与timestamp的区别(一般用datetime) 1.DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。 char类型:定长,简单粗暴,浪费空间,存取速度快 检索: varchar类型:变长,精准,节省空间,存取速度慢 检索: char(5)和varchar(5)中的5都是指字符的个数 char_length(name)是mysql自带计算字符数的函数,name是参数,length(name)是查看字节数函数 通过设置char的参数让取出的时候不去除空格:set sql_mode = “pad_char_to_full_length”; 为什么char模式会存进去在后面自动补全空格,取出来的时候又去掉呢? char以固定长度存储和读取,varchar需要先制作数据头(记录真实数据长度)再进行存储和读取,所以char速度更快 如果char(5),当很多数据都是2个或3个长度时,定长耗费空间,而varchar更节省空间 字段的值只能在给定范围中选择,如单选框,多选框 约束条件与数据类型的宽度一样,都是可选参数 not null代表非空 限制字段的值是唯一的,不能重复 例如socket连接的IP可以相同,PORT可以相同,但是IP+PORT不可能同时相同,这样意味着同时连接一个电脑的同一个软件 create table t1( 将多个字段作为主键 我们常设置id为主键,那么我们每次插入记录时都id都按照123的顺序插入,这时可以设置id为auto_increment参数,每次插入自动加1,(有个前提:该字段必须是一个key) delete from t1; 用来建立表之间的关系 第一步:先建立被关联的表,并且保证被关联的字段唯一(可以primary key或者unique) 第一步:先往被关联表插入记录(否则报错) foreign key实现了表之间的强耦合,会在操作删除更新时非常麻烦,所以我们写代码应该在应用程序实现表之间的逻辑关系,尽量减少foreign key的使用,有利于长期的代码扩展 分析步骤: 总结: 关联方式:foreign key 左边对右边是多对一,右边对左边也是多对一,双向的多对一关系就是多对多 创建第三张表专门存储两张表之间的互相对应关系 关联方式:foreign key+unique 从逻辑来说应该是先属于潜在客户,再发展为学生,所以应该由学生映射到客户表,在学生表创建FK,但要确保唯一可以设置customer_id唯一unique 用select搜索出来的值返回给insert update 表名 set 字段1=值1,字段2=值2 where 条件; 根据条件删除:delete from 表名 where 条件 例: 先创建员工信息表: 把月薪自动转化为年薪 where字句中可以使用: 单条件查询 多条件查询 关键字BETWEEN AND,可以配合not使用 SELECT name,salary FROM employee 关键字IN集合查询,可以合并多个OR,也可以与not搭配使用 SELECT name,salary FROM employee SELECT name,salary FROM employee 关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS),可与not搭配使用 SELECT name,post_comment FROM employee SELECT name,post_comment FROM employee 关键字LIKE模糊查询 通配符’%’ #代表后面加任意长度字符 通配符’_’ #代表后面只能加一个长度字符(但多个__可以代表多个字符) 设置group by为严格模式(只能查分组的字段):set global sql_mode=‘ONLY_FULL_GROUP_BY’; 由于group by post只能查询post字段,当你想要查询属于这个部门员工的其他信息时,可以使用聚合函数: 求最大值:max() 求最小值:min() 求平均值:avg() 求和:sun() 计数:count() select post,count(id) as employee_count from employee group by post; #as是命名 select post,max(salary) from employee group by post; concat实际就是字符拼接,group_concat(name)可以帮助将每个分组中的姓名拼接在一起 having与where的却别: 例如: 按单列排序: 按多列排序: 作用:用来限制最终打印到屏幕上的条数 简单的设置打印条数 实现分页功能 select * from employee,department; 简单粗暴,将两张表所有记录都打印出来 内连接:只取两张表的共同部分(匹配的行) 左连接:在内连接的基础上保留左表的记录 右连接:在内连接的基础上保留右表的记录 全外连接:在内连接的基础上保留左右两表没有对应关系的记录 语法顺序 执行顺序 带IN关键字的子查询 带比较运算的子查询 带exist和not exist关键字的子查询 子查询可以通过括号加as+自定义表名在内存中创建一张虚拟表供其他表连接或者查询 本地账号 远程账号 根据权限等级分为: Navicat——提供了可视化工具,以图形界面的形式操作MySQL数据库 本质上是连接mysql服务端的套接字软件 在MySQL服务端创建一个账号并授权: grant all on . to ‘root’@’%’ identified by ‘123’; #给任意IP地址的root用户授所有权限 查询服务端本地IP: 在客户端中写python代码查询数据库信息(模拟用户登录查询账号密码) 上述示例用户登录认证调用数据库user_info中的sql语句拼接有个致命问题: 根本原理:就根据程序的字符串拼接name=’%s’,我们输入一个xxx’ – haha,用我们输入的xxx加’在程序中拼接成一个判断条件name='xxx’ – haha’ 在拿游标中设置: cursor.scroll类似于文件中的f.seek(),将当前光标移动到指定位置 cursor.lastrowid 视图就是把你sql语句查询出来的虚拟表给保存下来 update course_view set cname=‘xxx’; #更新视图中的数据 alter view teacher_view as select * from course where cid>3; #通过where缩小查询范围 DROP VIEW teacher_view 使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询 触发器的语法: 示例: 存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql(类似MySQL的封装函数) 存储过程的参数有三类: in 仅用于传入参数用 out 仅用于返回值用 inout 既可以传入又可以当作返回值 MySQL中调用p2() python中调用 删除存储过程:drop procedure p1; 方式一: 方式二: 方式三: 事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性 语法: 函数与存储过程的区别: 流程控制了解一下if判断和循环语句 索引就是加快查询数据速度的功能 InnoDB存储引擎表示索引组织表,在建立表的时候就默认以索引方式来组织数据,建立索引结构。它会自动找一个主键 #如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引。 #如果没有这样的列,InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引。 聚集索引的叶子节点存储的是表的一整行数据 辅助索引的叶子节点只存储该字段的值,以及这个字段指向主键的引用 索引能够加快查询的几种情况: 准备 在没有索引的前提下测试查询速度 在表中已经存在大量数据的前提下,为某个字段段建立索引,建立索引的速度会很慢 在索引建立完毕后,以该字段为查询条件时,查询速度提升明显 根据没有加索引的字段查询,速度依然很慢
#FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
-3.402823466E+38 to -1.175494351E-38,
1.175494351E-38 to 3.402823466E+38
无符号:
1.175494351E-38 to 3.402823466E+38
**** 随着小数的增多,精度变得不准确 ****
#DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。m最大值为255,d最大值为30
-1.7976931348623157E+308 to -2.2250738585072014E-308
2.2250738585072014E-308 to 1.7976931348623157E+308
2.2250738585072014E-308 to 1.7976931348623157E+308
****随着小数的增多,精度比float要高,但也会变得不准确 ****
decimal[(m[,d])] [unsigned] [zerofill]
准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
**** 随着小数的增多,精度始终准确 ****
对于精确数值计算时需要用此类型
decaimal能够存储精确值的原因在于其内部按照字符串存储。

2. 日期类型
YYYY(1901/2155)
YYYY-MM-DD(1000-01-01/9999-12-31)
HH:MM:SS(’-838:59:59’/‘838:59:59’)
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y)
YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
在实际应用的很多场景中,MySQL的这两种日期类型都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。
下面就来总结一下两种日期类型的区别。
2.DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器,操作系统以及客户端连接都有时区的设置。
3.DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。
4.DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP),如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
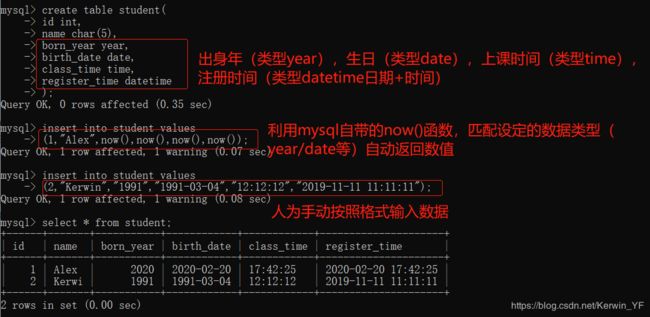
3. 字符类型
字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
存储:
存储char类型的值时,会往右填充空格来满足长度
例如:指定长度为10,存>10个字符则报错,存<10个字符则用空格填充直到凑够10个字符存储
在检索或者说查询时,查出的结果会自动删除尾部的空格,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = ‘PAD_CHAR_TO_FULL_LENGTH’;)
字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8
存储:
varchar类型存储数据的真实内容,不会用空格填充,如果’ab ',尾部的空格也会被存起来
强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用)
如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 28最大表示的数字为255)
如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 216最大表示的数字为65535)
尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容

解析:
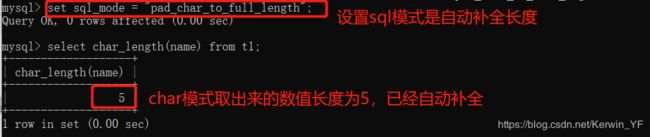
因为当查询where条件时,char和varchar不管怎么存,在取得时候只会按照值进行评算,不会管后面的空格(但是前面的空格无法躲避),这个方法对等于“=”有效,对like无效(like要求一模一样,包括后面几个空格)

总结:4. 枚举类型与集合类型
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3…)

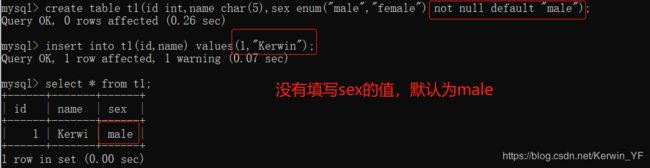
5. 约束条件
作用:用于保证数据的完整性和一致性5.1 not null与default
default代表默认值
5.2 unique key
单列唯一:同一字段需要唯一
方式一:定义字段时限制unique

方式二:定义完成所有字段再限制唯一
create table department(id int,name char(6),unique(id),unique(name));多列唯一(联合唯一):不同字段不可以同时相同
create table services(
id int unique, #id需要唯一
IP char(15),
PORT int,
unique(IP,PORT) #联合唯一,IP和PORT不可以同时相同
);

5.3 primary key

单列主键
id int primary key, #约束主键
name char(6)
);

id字段不为空且唯一,当不传id参数时默认为0,但第二次传入的时候会因0重复而报错复合主键
create table services(
IP char(15),
PORT int,
primary key(IP,PORT)
);

5.4 auto_increment(自增长)
create table t1(
id int primary key auto_increment, #设置主键、设置自增长
name char(6)
);
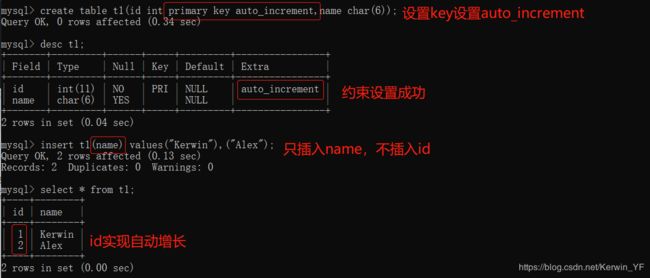

查询auto_increment 的变量:show variables like “auto_incr%” #%代表模糊查找
步长auto_increment_increment默认为1
起始偏移量auto_increment_offset默认为1
设置参数:
set session auto_increment_incremen=5; #绘画级别意味着只在本次连接有效,这次连接退出后无效
set global auto_increment_incremen=5; #全局级别以为这其他连接都会生效,前提是其他连接退出重新加载
set session auto_increment_offset=3; #强调起始偏移量<=步长(5)清空表
这种删除方法只会清空记录,但auto_increment的自增长记录还是会按照上一次递增
建议配合where条件使用
truncate table t1;
这种删除方法是将文件从头清空,一并将自增长记录清除
建议用此方式删除

5.5 foreign key(外键)

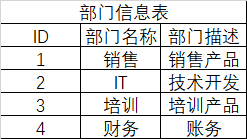
如上员工信息表中Alex和Egon的部门都是IT,当过多的重复部门信息就会重复写多行,占据内存,并且需要修改部门信息时(例如修改IT为开发部)就会涉及修改多行信息,所以采用外键单独创建部门信息表连接过去建立表关系foreign key
create table 部门信息表(
ID int primary key, #一定要设置被关联的字段唯一
部门名称 char(6),
部门描述 char(50));
第二步:再创建关联的表
create table 员工信息表(
ID int primary key,
姓名 char(5),
性别 enum(“男”,“女”),
部门ID int,
foreign key(部门ID) references 部门信息表(ID)
);
解析:foreign key(部门ID) references 部门信息表(ID)
设置当前表(员工信息表)的部门ID字段与关联表(部门信息表)的ID字段关联

插入数据
insert into 部门信息表 values(1,“销售”,“销售产品”),(2,“IT”,“技术开发”),(3,“培训”,“培训产品”),(4,“财务”,“账务”);
第二步:再往关联表插入记录
insert into 员工信息表 values(1,“杨飞”,“男”,1);

删除数据
第一步:先删除关联表(员工信息表)中部门为IT的员工数据
delete from 员工信息表 where 部门ID=2;
第二步:在删除被关联表(部门信息表)中的部门IT记录
delete from 部门信息表 where ID=2;
在创建关联表(员工信息表)的时候就设置随着被关联表同步删除或更新
create table 员工信息表(
ID int primary key,
姓名 char(5),
性别 enum(“男”,“女”),
部门ID int,
foreign key(部门ID) references 部门信息表(ID) on delete cascade on update cascade
);
on delete cascade是删除同步;on update cascade是更新同步
这样一旦部门信息表产生删除或更新行为,员工信息表会同步删除或更新总结
6. 两张表之间的关系
6.1 如何找出两张表之间的关系
是否左表的多条记录可以对应右表的一条记录,如果是,则证明左表的一个字段foreign key 右表一个字段(通常是id)
是否右表的多条记录可以对应左表的一条记录,如果是,则证明右表的一个字段foreign key 左表一个字段(通常是id)
如果只有步骤1成立,则是左表多对一右表
如果只有步骤2成立,则是右表多对一左表
如果步骤1和2同时成立,则证明这两张表时一个双向的多对一,即多对多,需要定义一个这两张表的关系表来专门存放二者的关系
如果1和2都不成立,而是左表的一条记录唯一对应右表的一条记录,反之亦然。这种情况很简单,就是在左表foreign key右表的基础上,将左表的外键字段设置成unique即可6.2 多对一
举例:出版社——书之间的关系
从左边多个出版社不可能出同一本书,从右边多个书可能由一个出版社出版,所以它是多对一关系

6.3 多对多
这样的表格无法通过foreign key创建,因为foreign key的逻辑需要在创建关联表之前先创建被关联表,双向的矛盾在于无法创建对方的表实现方法


constraint fk_author 是命名这个外键的名字为fk_author

6.3 一对一
培训机构组织活动招募客户,再发展成为学生

实现方法
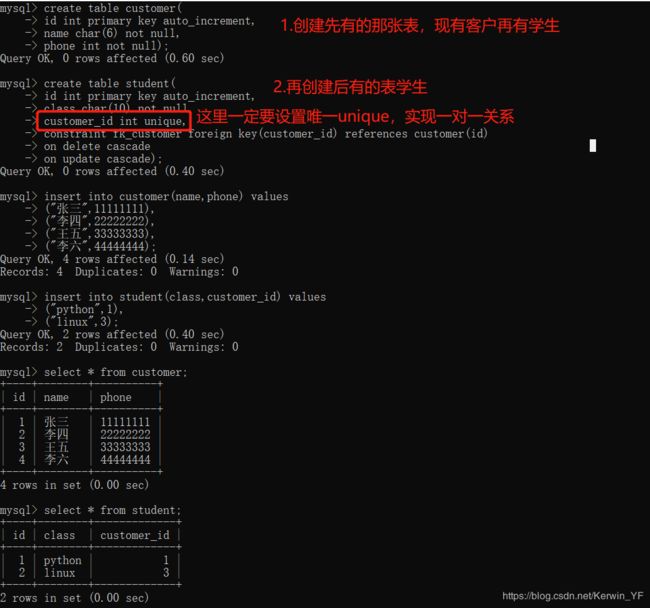
五、数据操作
1. 记录的增删改
1.1 插入数据insert
insert into 表一(字段1,字段2…) select 字段1,字段2 from 表二 where 条件;
insert into 表一(字段1,字段2…) select * from 表二;
![]()
1.2 更新数据update
![]()
1.3 删除数据delete和truncate
清空表:truncate table 表名(delete from表名无法清空auto_increment)

2. 单表查询
2.1 关键字的执行优先级(重点)
select distinct 字段1,字段2,字段3 from 库.表
where 条件
group by 分组条件
having 过滤
order by 排序字段
limit n;
2.2 简单查询

2.2.1 简单查询
SELECT id,name,sex,age,hire_date,post,post_comment,salary,office,depart_id FROM employee;
SELECT * FROM employee;
SELECT name,salary FROM employee;
2.2.2 避免重复DISTINCT查询
SELECT DISTINCT post FROM employee;

2.2.3 通过四则运算查询
SELECT name, salary*12 FROM employee;
SELECT name, salary*12 AS Annual_salary FROM employee; 可以修改字段名
SELECT name, salary*12 Annual_salary FROM employee; 跟上面一条一样的效果,省略as


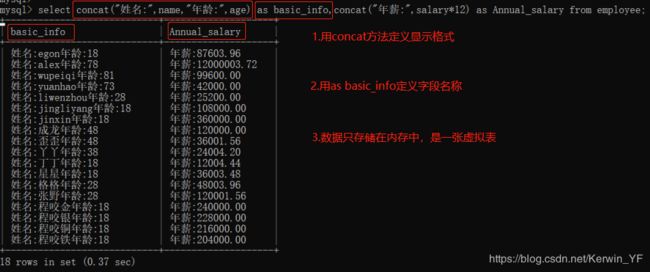
四则运算的查询数据只是存在于内存中的一张表2.2.4 自定义显示格式(concat()方法)
CONCAT() ——函数用于连接字符串,类似print(a,b)
SELECT CONCAT('姓名: ',name,' 年薪: ', salary*12) AS Annual_salary
FROM employee;
CONCAT_WS() ——用分隔符分割所有数据,第一个参数为分隔符
SELECT CONCAT_WS(':',name,salary*12) AS Annual_salary
FROM employee;
2.3 where约束条件
pattern(模式)可以是%或_,
%表示任意多字符
_表示一个字符
SELECT name FROM employee WHERE post=‘sale’;
SELECT name,salary FROM employee WHERE post=‘teacher’ AND salary>10000;
SELECT name,salary FROM employee
WHERE salary BETWEEN 10000 AND 20000;
WHERE salary NOT BETWEEN 10000 AND 20000;
SELECT name,salary FROM employee
WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ;
WHERE salary IN (3000,3500,4000,9000) ;
WHERE salary NOT IN (3000,3500,4000,9000) ;
SELECT name,post_comment FROM employee
WHERE post_comment=’’; 注意’'是空字符串,不是null,null是特殊的数据类型不等于空字符串
WHERE post_comment IS NULL;
WHERE post_comment IS NOT NULL;
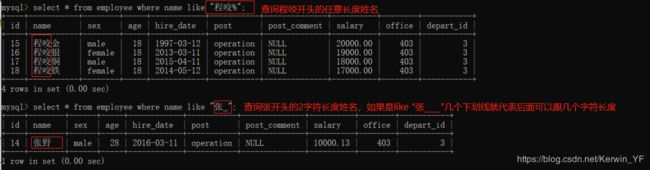
SELECT * FROM employee WHERE name LIKE ‘eg%’;
SELECT * FROM employee WHERE name LIKE ‘al__’;
2.4 分组查询:group by
什么是分组?为什么要分组?
取每个部门的最高工资
取每个部门的员工数
取男人数和女人数
小窍门:‘每’这个字后面的字段,就是我们分组的依据
如果我们用unique的字段作为分组的依据,则每一条记录自成一组,这种分组没有意义
多条记录之间的某个字段值相同,该字段通常用来作为分组的依据
如果没有分组,那么表格整体默认为一组ONLY_FULL_GROUP_BY
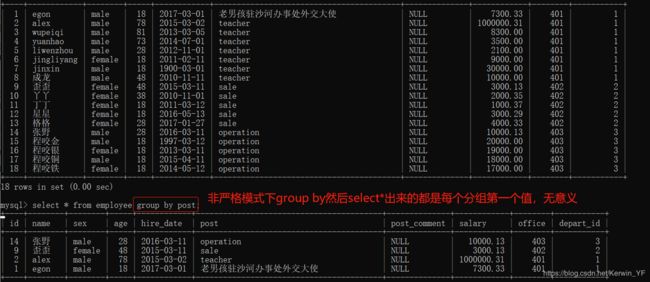

聚合函数
聚合函数只能在逻辑上分组之后再调用!!!
例如:
查每个部门的各有多少人
查每个部门最大工资

GROUP_CONCAT()
查询每个部门内员工的姓名:
select post,group_concat(name) from employee group by post;

2.5 过滤条件:having
查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数
select post,group_concat(name),count(id) from employee group by post having count(id) < 2;
查询各岗位平均薪资大于10000的岗位名、平均工资
select post,avg(salary) from employee group by post having avg(salary) > 10000;
查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资
select post,avg(salary) from employee group by post having avg(salary) between 10000 and 20000;
2.6 查询排序:order by
select * from employee order by salary; #按照薪资排序(默认为升序)
select * from employee order by salary asc; #按照薪资升序排列,asc是升序
select * from employee order by salary desc; #按照薪资降序排列,desc是降序
select * from employee order by age asc,salary desc; #先按照年龄升序,再按照薪资降序
2.7 限制查询的记录数:limit
select * from employee order by salary desc limit 1; #看工资最高的人信息
select * from employee limit 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条
select * from employee limit 5,10; #从第5开始,即先查询出第6条,然后包含这一条在内往后查5条
2.8 正则查询(regexp)
select * from employee where name like "程%";
select * from employee where name regexp"^程"; #效果与上一条like相同,都是以程结尾
select * from employee where name regexp"^程.*(金|银)$"; #匹配程开头,金或银结尾
3. 多表查询
创建2张关联表:department和employee
create table department(
id int,
name varchar(20)
);
create table employee(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);

3.1 多表连接查询
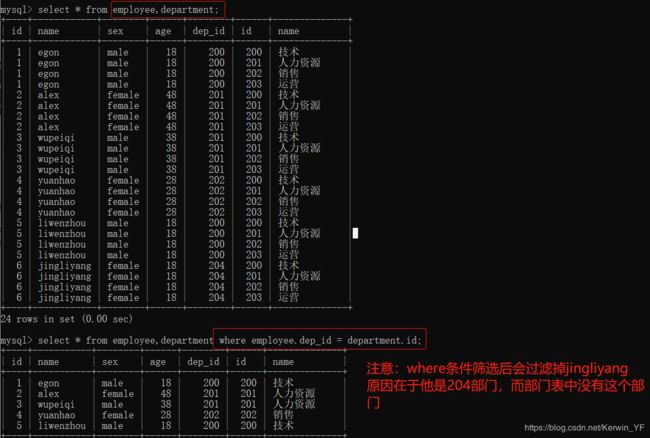
交叉连接:不适用任何匹配条件。生成笛卡尔积
select * from employee,department where employee.dep_id = department.id; 通过where条件筛选对应行类似于for i in list1:
for k in list 2:
其他连接的方式都是基于笛卡尔积上再进行筛选的四种连接操作
select * from employee inner join department on employee.dep_id = department.id;
inner join内连接,on后面加条件

select * from employee left join department on employee.dep_id = department.id;

select * from employee right join department on employee.dep_id = department.id;

注意:mysql不支持全外连接 full join
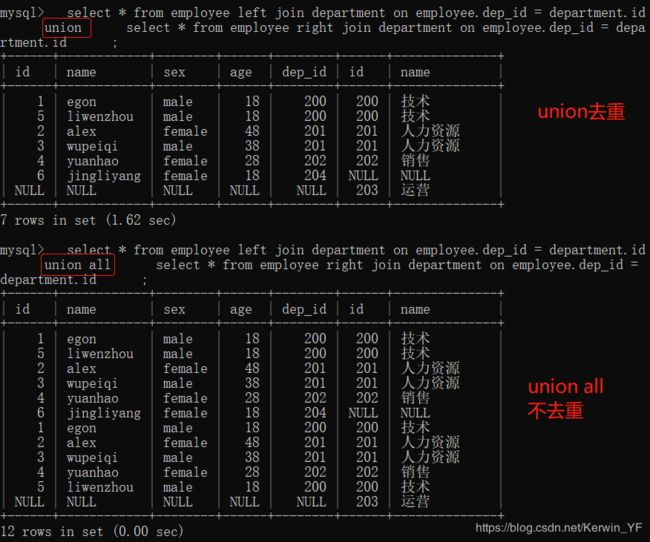
mysql可以使用union结合左连接和右连接的数据进行去重得到查询结果
union与union all的区别:union会去掉相同的纪录
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id
;
符合条件连接查询
查询平均年龄大于30岁的部门名
1、年龄在employee,部门在department,所以from两张表
2、join的方式应该是inner,因为互相无对应的数据是无意义的
3、group by应该是部门名,因为查询是按照部门查询的
4、过滤应该用having,因为平均年龄是在分组好部门以后过滤的
语句如下:
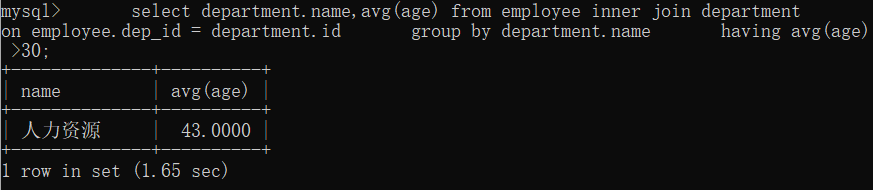
select department.name,avg(age) from employee inner join department
on employee.dep_id = department.id
group by department.name
having avg(age) >30;
3.2 (重点)select语句关键字执行优先级
SELECT DISTINCT 执行顺序 执行语句
(7) SELECT
(8) DISTINCT 3.3 子查询
#1:子查询是将一个查询语句嵌套在另一个查询语句中。
#2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
#3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
#4:还可以包含比较运算符:= 、 !=、> 、<等
1、 查询平均年龄大于25岁部门名
select name from department where id in #查询id在后面范围内的部门名称
(select dep_id from employee group by dep_id having avg(age) > 25); #取得平均年龄大于25的部门分组:返回201,202
2、查看技术部门员工姓名
select name from employee where dep_id =
(select id from department where name = "技术”);
3、查看不足1人的部门名
查询大于所有人平均年龄的员工名与年龄
select name,age from employee where age >
(select avg(age) from employee);
exist用于判断子查询是否有结果,有结果则为True,无结果则为False,前面加where条件判断是否执行主查询select * from employee
where exists #判断子查询是否有结果,有就执行上面一条语句
(select id from department where id=200);
select * from
(select id,name,sex from employee) as test_table; #只存在内存中,下次调用就没用了
#查询每个部门最新入职的那名员工
select t1.post,t1.name,t1.hire_date from employee as t1 inner join # 将所有信息表t1与t2连接
(select post,max(hire_date) as max_hire_date from employee group by post) as t2 #创建虚拟表t2,返回每个部门最新的入职日期(只包含部门名和入职日期)
on t1.hire_date = t2.max_hire_date; #连接依据是所有员工中的入职日期与t2中最新入职日期一致
4. 权限管理
4.1 创建账号
create user "alex"@"localhost" identified by "123"; #localhost也可以改为127.0.0.1,123代表密码
创建完成后可以用mysql -ualex -p123登陆了
create user "alex"@"192.168.1.1" identified by "123"; #192.168.1.1代表客户端IP地址
创建完成后可以用mysql -ualex -p123 -h 服务端IP #要填写服务端IP
#该方法指定用户必须使用192.168.1.1的机器登陆
如果要指定用户在某一个客户端网段登陆服务端,如下:
create user "alex"@"192.168.1.%" identified by "123";
如果指定用户任意一台机器都可以登陆:
create user "alex"@"%" identified by "123";
4.2 授权账号
创建权限后输入select * from myql.user\G(\G是按行展示数据)可以查看到有名为alex的账户,但在user权限下都没有开通,但其实在下等级权限中有开通的功能

输入select * from mysql.db\G查看db权限

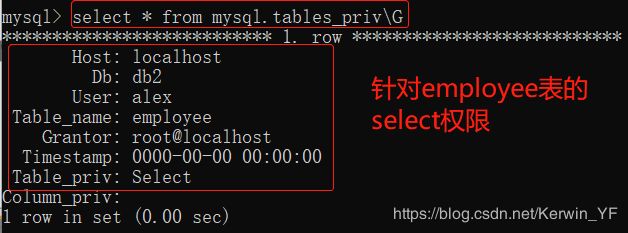
输入select * from mysql.tables_priv;查看表权限
授权语句
1、授权与收回user级别权限
#授权user权限
grant all on *.* to "alex"@"localhost"; #授权给alex账号user权限(即*.*对所有文件夹下所有表)所有的权限(all)
它与root权限的区别在如grant权限没有,也可以指定权限,如select:
grant select on *.* to "alex"@"localhost";
#收回user权限
revoke all on *.* from "alex"@"localhost";
2、授权db级别权限
#授权db权限
grant select on db1.* to "alex"@"localhost"; #授权给alex关于db1文件夹下所有表的所有权限
#收回db级别权限
revoke select on db1.* from "alex"@"localhost";
3、授权tables_priv级别权限
#授权tables_priv权限
grant all on db1.t1 to "alex"@"localhost";
revoke all on db1.t1 from "alex"@"localhost";
4、授权columns_priv级别权限
#授权columns_priv权限
grant select(id,name),update(age) on db1.t2 to "alex"@"localhost"; #授权给alex关于db1下的t2表中查询id,name和修改age的权限
六、Navicat工具与pymql模块
1. Navicat工具的使用
官网下载:https://www.navicat.com/en/products/navicat-for-mysql
网盘下载:https://pan.baidu.com/s/1bpo5mqj七、pymysql模块
1. 链接、执行sql、关闭(游标)
flush privileges; #立刻刷新到配置
cmd中运行ipconfig——192.168.50.253import pymysql
#第一步:输入用户名密码
username = input("username:").strip()
password = input("password:").strip()
#第二步:建立链接对象
conn = pymysql.connect(
host = "192.168.50.253", #服务器IP
port = 3306, #服务器端口,mysql默认3306
user = "root", #用户名
password = "123", #密码
db = "db4", #查询哪个数据库
charset = "uft8" #数据库字符编码,utf8中间没有-
)
#第三步:拿到游标(就是cmd中mysql界面每次输入sql语句前面的mysql>,这是一个输入接口)
cursor = conn.cursor()
#第四步:为游标提交命令,执行sql语句
sql = "select * from user_info where username = '%s' and password = '%s'"%(username,password) #user_info是数据库中在db4中存着的用户信息
rows = cursor.execute(sql) #rows是执行完sql语句受影响的行数
cursor.close() #关闭游标
conn.close() #关闭连接
#第五步:进行用户名密码判断判断
if rows: #如果查询到记录
print("登陆成功")
else:
print("登陆失败")
2. execute()之sql注入
sql语句中"- - ssss"杠杠空格后面的ssss是被注释掉的,没有任何意义

注意:符号–会注释掉它之后的sql,正确的语法:–后至少有一个任意字符最后那一个空格,在一条sql语句中如果遇到select * from t1 where id > 3 -- and name='egon';则--之后的条件被注释掉了
#1、sql注入之:用户存在,绕过密码
egon' -- 任意字符
#2、sql注入之:用户不存在,绕过用户与密码
xxx' or 1=1 -- 任意字符



解决办法:# 原来是我们对sql进行字符串拼接
# sql="select * from userinfo where name='%s' and password='%s'" %(user,pwd)
# print(sql)
# res=cursor.execute(sql)
#改写为(execute帮我们做字符串拼接,我们无需且一定不能再为%s加引号了)
sql="select * from userinfo where name=%s and password=%s" #!!!注意%s需要去掉引号,因为pymysql会自动为我 们加上
res=cursor.execute(sql,(username,password)) #pymysql模块自动帮我们解决sql注入的问题,只要我们按照pymysql的规矩来.
3. pymysql模块增删改
import pymysql
conn = pymysql.connect(
host="192.168.50.253",
port=3306,
user="root",
password="123",
db="db4",
charset="uft8"
)
cursor = conn.cursor()
sql = "insert into user_info(username,password) values(%s,%s)"
#插入单个记录
rows_1 = cursor.execute(sql,("Kerwin","123"))
#插入多条记录
rows_2=cursor.executemany(sql,[('yxx','123'),('egon1','111'),('egon2','2222')])
conn.commit() #修改数据后一定要提交
cursor.close()
conn.close()
可以进行多条记录插入,只需要以元组的形式组合成列表4. pymysql模块查
4.1 fetchone,fetchmany,fetchall
sql = "select * from user_info"
rows = cursor.execute(sql)
print(rows) #返回查询到数据的行数,并不显示数据内容
print(cursor.fetchone()) #打印查询到的第一行
print(cursor.fetchone()) #打印查询到的第二行,以此类推
print(cursor.fetchmany(5)) #自定义查询5行
print(cursor.fetchall()) #查询出的所有值
4.2 pymysql.cursors.DictCursor将查询数据加上字段以字典返回
cursor = conn.cursor(pymysql.cursors.DictCursor)
原本查询到的数据以value组成元组,设置后以字典形式字段:values
例如:
{'id':1,'username':'alex','password':'123'}
4.3 cursor.scroll
分为两种模式:
从头开始往后数3行
从当前位置往后数3行4.4 获取插入的最后一条数据的自增ID
sql = "insert into user_info(username,password) values(%s,%s)"
rows_2=cursor.executemany(sql,[('yxx','123'),('egon1','111'),('egon2','2222')])
print(cursor.lastrowid) #在插入语句后查看
八、MySQL内置功能
1. 视图
1.1 创建视图
create view teacher_view as select tid from teacher where tname=‘李平老师’;1.2 使用视图
insert into course_view values(5,‘yyy’,2); #往视图中插入数据
视图是方便查询多张表时避免过多的sql语句重复,但不可以进行修改,因为一旦修改可能涉及视图中关联的多张表数据的改动1.3 修改视图(只修改查询的部分)
1.4 删除视图
2. 触发器
例如:插入员工信息时,自动将员工工服尺码插入到另一张工服表中2.1 创建触发器
create trigger 触发器名字 before insert on 表名字 for each row
#插入前
CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW
BEGIN
…(触发行为的代码)
END
#插入后
CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW
BEGIN
…(触发行为的代码)
END
#删除前
CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW
BEGIN
…(触发行为的代码)
END
#删除后
CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW
BEGIN
…(触发行为的代码)
END
#更新前
CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW
BEGIN
…(触发行为的代码)
END
#更新后
CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW
BEGIN
…(触发行为的代码)
END

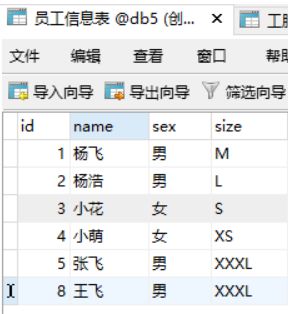
创建以上员工信息表和工服表,要想设置在员工信息表插入时就自动将尺码插入工服表中,创建触发器即可
-> delimiter // #delimiter将默认执行的分号;修改为双斜杠执行
-> create trigger tri_after_insert_员工信息表 after insert on 员工信息表 for each row
-> begin
-> insert into 工服表(name,uniform_size) values(New.name,New.size);
-> end // #这里//现在是执行的意思
-> delimiter ; #将执行符号换回分号;2.2 使用和删除触发器
3. 存储过程
1.用于替代程序写的SQL语句,实现程序与sql解耦
2.基于网络传输,传别名的数据量小,而直接传sql数据量大
程序员扩展功能不方便,因为存储过程存储在数据库中3.1 创建简单的存储过程(无参)
delimiter // #delimiter将默认执行的分号;修改为双斜杠执行
create procedure p1() #p1是存储过程名字
BEGIN
select * from db7.teacher; #自定义的执行代码
END //
delimiter ;
输入sql语句call p1();# 拿游标
cursor=conn.cursor()
# 执行sql
cursor.callproc('p1')
print(cursor.fetchall())
3.2 创建存储过程(有参)
delimiter //
create procedure p2(in n1 int,in n2 int,out res int) #in n1 int代表传入类参数n1是int类型
BEGIN
select * from db7.teacher where tid > n1 and tid < n2;
set res = 1; #设置res等于1
END //
delimiter ;
set @x=0 #先设定@x为o
call p2(2,4,@x); #将@x作为res传入p2,执行中被修改为1
select @x; #查看是否被修改,修改则成功执行# 执行sql
cursor.callproc('p2',(2,4,0)) #传参以元组形式传入,0相当于set @res=0
#callproc过程中会设置3个参数:@_p2_0=2,@_p2_1=4,@_p2_2=0
print(cursor.fetchall())
cursor.execute('select @_p2_2') #查询res的值
print(cursor.fetchone())
3.3 应用程序与数据库的存储过程结合使用
Python:调用存储过程
MySQL:编写存储过程
适用于sql语句过长,可以存储在mysql中
Python:编写纯生SQL
MySQL:
可扩展性强,不需要数据库开发人员的帮助,但效率低,sql语句编写麻烦
Python:类和对象,即ORM(本质还是纯SQL语句)
MySQL:
运行效率不如方式二,因为方式二直接编写sql语句,而方式三是转换成sql语句后使用,但方式三开发效率更高4. 事务
事务是将一堆sql语句放到一起,这些语句要么同时执行成功,要么一个都别想执行
start transaction; #开启事务
执行sql语句1
执行sql语句1
commit; #执行commit代表将执行结果存储进去,否则并不会真正执行sql语句1和2
rollback; #如果没有commit,一旦执行rollback里立马回复到开启事务前的状态


5. 函数与流程控制
DATE_FORMAT(date,format) 根据format字符串格式化date值
mysql> SELECT DATE_FORMAT(‘2009-10-04 22:23:00’, ‘%W %M %Y’);
-> ‘Sunday October 2009’
mysql> SELECT DATE_FORMAT(‘2007-10-04 22:23:00’, ‘%H:%i:%s’);
-> ‘22:23:00’九、索引原理
有约束的字段一定自带索引,具备索引特征
对于无法约束的字段,可以通过加普通索引加速查询
参考资料:https://www.cnblogs.com/linhaifeng/articles/7274563.html
索引在MySQL里又叫做键,primary key unique key都属于索引,Index是普通索引
索引类似书的目录,通过不断地缩小想要获取数据的范围来筛选出最终想要的结果
索引是一种特殊的数据结构,帮你在IO过程中尽可能减少查询次数,加快效率1. 索引的数据结构(B+树)
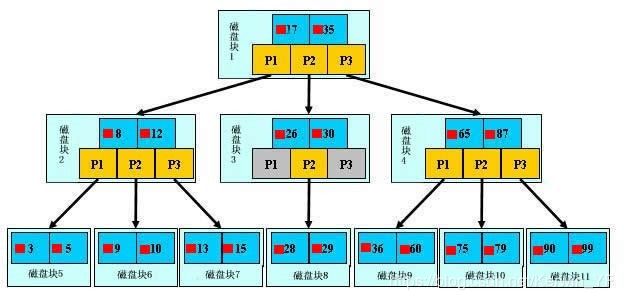
上图分为三层:根节点、树杈节点、叶子节点
浅蓝色:磁盘块
深蓝色:数据项
黄色:指针
解析:
2. 聚集索引与辅助索引
2.1 聚集索引(主键)
如果设置id字段为主键,当where id > 10查询速度加快,但当where age >20查询就不会加快,因为age没有索引,因此需要为age添加辅助索引2.2 辅助索引(为其他字段添加索引)
比如主键为id,name为辅助索引,当查询name=alex时,会有一个引用指向alex所属的id
3. 创建/删除索引的语法
create table t1(
id int,
name char,
age int,
sex enum(‘male’,‘female’),
unique key uni_id(id),
index ix_name(name) #index没有key
);
create index ix_age on t1(age);
alter table t1 add index ix_sex(sex);4. 测试索引
#1. 准备表
create table s1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
#2. 创建存储过程,实现批量插入记录
delimiter $$ #声明存储过程的结束符号为$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<3000000)do
insert into s1 values(i,'egon','male',concat('egon',i,'@oldboy'));
set i=i+1;
end while;
END$$ #$$结束
delimiter ; #重新声明分号为结束符号
#3. 查看存储过程
show create procedure auto_insert1\G
#4. 调用存储过程
call auto_insert1();
无索引:mysql根本就不知道到底是否存在id等于333333333的记录,只能把数据表从头到尾扫描一遍,此时有多少个磁盘块就需要进行多少IO操作,所以查询速度很慢
mysql> select * from s1 where id=333333333;
Empty set (0.33 sec)

![]()
