Spark存储体系——内存存储MemoryStore
MemoryStore负责将Block存储到内存。Spark通过将广播数据、RDD、Shuffle数据存储到内存,减少了对磁盘I/O的依赖,提高了程序的读写效率。
1 MemoryStore的内存模型
Block在内存中以什么形式存在呢?是将文件直接缓存到内存?Spark将内存中的Block抽象为特质MemoryEntry,其定义如下:
//org.apache.spark.storage.memory.MemoryStore
private sealed trait MemoryEntry[T] {
def size: Long
def memoryMode: MemoryMode
def classTag: ClassTag[T]
}根据上面的代码,MemoryEntry提供了三个接口方法:
- size:当前Block的大小
- memoryMode:Block存入内存的内存模式
- classTag:Block的类型标记
MemoryEntry有两个实现类,它们的实现如下:
//org.apache.spark.storage.memory.MemoryStore
private case class DeserializedMemoryEntry[T](
value: Array[T],
size: Long,
classTag: ClassTag[T]) extends MemoryEntry[T] {
val memoryMode: MemoryMode = MemoryMode.ON_HEAP
}
private case class SerializedMemoryEntry[T](
buffer: ChunkedByteBuffer,
memoryMode: MemoryMode,
classTag: ClassTag[T]) extends MemoryEntry[T] {
def size: Long = buffer.size
}DeserializedMemoryEntry表示反序列化的MemoryEntry,而SerializedMemoryEntry表示序列化后的MemoryEntry。
下面来看看MemoryStore的属性:
//org.apache.spark.storage.memory.MemoryStore
private[spark] class MemoryStore(
conf: SparkConf,
blockInfoManager: BlockInfoManager,
serializerManager: SerializerManager,
memoryManager: MemoryManager,
blockEvictionHandler: BlockEvictionHandler)
extends Logging {
private val entries = new LinkedHashMap[BlockId, MemoryEntry[_]](32, 0.75f, true)
private val onHeapUnrollMemoryMap = mutable.HashMap[Long, Long]()
private val offHeapUnrollMemoryMap = mutable.HashMap[Long, Long]()
private val unrollMemoryThreshold: Long = conf.getLong("spark.storage.unrollMemoryThreshold", 1024 * 1024)
.
.- conf:即SparkConf
- blockInfoManager:即Block信息管理器BlockInfoManager
- serializerManager:即序列化管理器SerializerManager
- memoryManager:即内存管理器MemoryManager。MemoryStore存储Block,使用的就是MemoryManager内的maxOnHeapStorageMemory和maxOffHeapStorageMemory两块内存池
- blockEvictionHandler:Block驱逐处理器。blockEvictionHandler用于将Block从内存中驱逐出去。blockEvictionHandler的类型是BlockEvictionHandler,BlockEvictionHandler定义了将对象从内存中移除的接口,如下:
//org.apache.spark.storage.memory.MemoryStore
private[storage] trait BlockEvictionHandler {
private[storage] def dropFromMemory[T: ClassTag](
blockId: BlockId,
data: () => Either[Array[T], ChunkedByteBuffer]): StorageLevel
}BlockManager实现了特质BlockEvictionHandler,并重写了dropFromMemory方法,BlockManager在构造MemoryStore时,将自身的引用作为blockEvictionHandler参数传递给MemoryStore的构造器,因而BlockEvictionHandler就是BlockManager。
//org.apache.spark.storage.BlockManager
private[spark] val memoryStore =
new MemoryStore(conf, blockInfoManager, serializerManager, memoryManager, this)MemoryStore除了以上属性外,还有一些方法对MemoryStore的模型提供了概念上的描述:
- maxMemory:MemoryStore用于存储Block的最大内存,其实质为MemoryManger的maxOnHeapStorageMemory和maxOffHeapStorageMemory之和。如果MemoryManager为StaticMemoryManager,那么maxMemory的大小是固定的。如果MemoryManager为UnifiedMemoryManager,那么 maxMemory的大小是动态变化的
- memoryUsed:MemoryStore中已经使用的内存大小。其实质为MemoryManager中onHeapStorageMemoryPool已经使用的大小和offHeapStorageMemoryPool已经使用的大小之和
- currentUnrollMemory:MemoryStore用于展开Block使用的内存大小。其实质为onHeapUnrollMemoryMap中的所有用于展开Block所占用的内存大小与offHeapUnrollMemoryMap中所有用于展开Block所占用的内存大小之和
- blocksMemoryUsed:MemoryStore用于存储Block(即MemoryEntry)使用的内存大小,即memoryUsed与currentUnrollMemory的差值
- currentUnrollMemoryForThisTask:当前的任务尝试线程用于展开Block所占用的内存。即onHeapUnrollMemoryMap中缓存的当前任务尝试线程对应的占用大小与offHeapUnrollMemoryMap中缓存的当前 的任务尝试线程对应的占用大小之和
- numTasksUnrolling:当前使用MemoryStore展开Block的任务的数量。其实质为onHeapUnrollMemoryMap的键集合与offHeapUnrollMemoryMap的键集合的并集
基于这些成员的了解,下面来研究一下MemoryStore的内存模型。MemoryStore相比于MemoryManager,提供了一种宏观的内存模型,MemoryManager模型的堆内存和堆外内存在MemoryStore的内存模型中是透明的,UnifiedMemoryManager中存储内存与计算内存的“软”边界在MemoryStore的内存模型中也是透明的
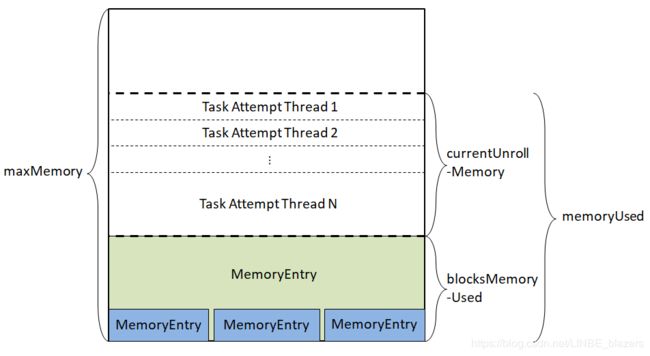
从图中看出,整个MemoryStore的存储分为三块:一块是MemoryStore的entries属性持有的很多MemoryEntry所占据的内存BlocksMemoryUsed;一块是onHeapUnrollMemoryMap或offHeapUnrollMemoryMap中使用展开方式占用的内存currentUnrollMemory。展开Block的行为类似于人们生活中的“占座”,一间教室里有些座位有人,有些则穿着,在座位上放一本书表示有人正在使用,那么别人就不会坐。这样可以防止在向内存真正写入数据时,内存不足发生溢出。blocksMemoryUsed和currentUnrollMemory的空间之和是已经使用的空间,用memoryUsed表示。还有一块没有任何标记,表示未使用。
2 MemoryStore提供的方法
MemoryStore提供了很多方法,便于对Block数据的存储和读取。MemoryStore提供的方法如下:
2.1 getSize
用于获取BlockId对应MemoryEntry(即Block的内存形式)所占用的大小
//org.apache.spark.storage.memory.MemoryStore
def getSize(blockId: BlockId): Long = {
entries.synchronized {
entries.get(blockId).size
}
}2.2 putBytes
将BlockId对应的Block(已经封装为ChunkedByteBuffer)写入内存
def putBytes[T: ClassTag](
blockId: BlockId,
size: Long,
memoryMode: MemoryMode,
_bytes: () => ChunkedByteBuffer): Boolean = {
require(!contains(blockId), s"Block $blockId is already present in the MemoryStore")
if (memoryManager.acquireStorageMemory(blockId, size, memoryMode)) {
// We acquired enough memory for the block, so go ahead and put it
val bytes = _bytes()
assert(bytes.size == size)
val entry = new SerializedMemoryEntry[T](bytes, memoryMode, implicitly[ClassTag[T]])
entries.synchronized {
entries.put(blockId, entry)
}
logInfo("Block %s stored as bytes in memory (estimated size %s, free %s)".format(
blockId, Utils.bytesToString(size), Utils.bytesToString(maxMemory - blocksMemoryUsed)))
true
} else {
false
}
}执行步骤如下:
- 1)从MemoryManager中获取用于存储BlockId对应的Block的逻辑内存。如果获取失败则返回false,否则进入下一步
- 2)调用_bytes函数,获取Block的数据,即ChunkedByteBuffer
- 3)创建Block对应的SerializedMemoryEntry
- 4)将SerializedMemoryEntry放入entries缓存
- 5)返回true
2.3 reserveUnrollMemoryForThisTask
用于为展开尝试执行任务给定的Block保留指定内存模式上指定大小的内存
def reserveUnrollMemoryForThisTask(
blockId: BlockId,
memory: Long,
memoryMode: MemoryMode): Boolean = {
memoryManager.synchronized {
val success = memoryManager.acquireUnrollMemory(blockId, memory, memoryMode)
if (success) {
val taskAttemptId = currentTaskAttemptId()
val unrollMemoryMap = memoryMode match {
case MemoryMode.ON_HEAP => onHeapUnrollMemoryMap
case MemoryMode.OFF_HEAP => offHeapUnrollMemoryMap
}
unrollMemoryMap(taskAttemptId) = unrollMemoryMap.getOrElse(taskAttemptId, 0L) + memory
}
success
}
}其步骤如下:
- 1)调用MemoryManager的acquireUnrollMemory方法获取展开内存
- 2)如果获取内存成功,则更新taskAttemptId与任务尝试线程在堆内存或堆外内存展开的所有Block占用的内存大小之和之间的映射关系
- 3)返回获取成功或失败的状态
2.4 releaseUnrollMemoryForThisTask
用于释放任务尝试线程占用的内存
def releaseUnrollMemoryForThisTask(memoryMode: MemoryMode, memory: Long = Long.MaxValue): Unit = {
val taskAttemptId = currentTaskAttemptId()
memoryManager.synchronized {
val unrollMemoryMap = memoryMode match {
case MemoryMode.ON_HEAP => onHeapUnrollMemoryMap
case MemoryMode.OFF_HEAP => offHeapUnrollMemoryMap
}
if (unrollMemoryMap.contains(taskAttemptId)) {
val memoryToRelease = math.min(memory, unrollMemoryMap(taskAttemptId))//计算要释放的内存
if (memoryToRelease > 0) {//释放展开内存
unrollMemoryMap(taskAttemptId) -= memoryToRelease
memoryManager.releaseUnrollMemory(memoryToRelease, memoryMode)
}
if (unrollMemoryMap(taskAttemptId) == 0) {
unrollMemoryMap.remove(taskAttemptId)//清除taskAttemptId与展开内存大小之间的映射关系
}
}
}- 1)计算实际要释放的内存大小,此大小为指定要释放的大小与任务尝试线程在堆内存或堆外内存实际占有的内存大小之和之间的最小值
- 2)更新taskAttemptId与任务尝试线程在堆内存或堆外内存展开的所有Block占用的内存大小之和之间的映射关系
- 3)调用 MemoryManager 的 releaseUnrollMemory 方法释放内存
- 4)如果任务尝试线程在堆内存或堆外在展开的所有Block占用的内存大小之和为0,则清除此taskAttemptId与任务尝试线程在堆内或堆外内存展开的所有Block占用的内存大小之和之间的映射关系
2.4 putIteratorAsValues
此方法将BlockId对应的Block(已经转换为Iterator)写入内存。有时候放入内存的Block很大,所以一次性将此对象写入内存可能将引发OOM异常。为了避免这种情况的发生,首先需要 将Block转换为Iterator,然后渐进式地展开此Iterator,并且周期性地检查是否有足够的展开内存。此方法涉及很多变量,为了便于理解,这里先解释这些变量的含义,然后再分析方法实现。
- elementsUnrolled:已经展开的元素数量
- keepUnrolling:MemoryStore是否仍然有足够的内存,以便于继续展开Block(即Iterator)
- initialMemoryThreshold:即unrollMemoryThreshold。用来展开任何Block之前,初始请求的内存大小,可以修改属性 spark.storage.unrollMemoryThreshold(默认为1MB)改变大小
- memoryCheckPeriod:检查内存是否有足够的阀值,此值固定为16。字面上有周期的含义,但是此周期并非指时间,而是已经展开的元素的数量 elementsUnrolled。
- memoryThreshold:当前任务用于展开Block所保留的内存
- memoryGrowthFactor:展开内存不充足时,请求增长的因为。此值固定为1.5。
- unrollMemoryUsedByThisBlock:Block已经使用的展开内存大小,初始大小为initialMemoryThreshold
- vector:用于追踪Block(即Iterator)每次迭代的数据。
private[storage] def putIteratorAsValues[T](
blockId: BlockId,
values: Iterator[T],
classTag: ClassTag[T]): Either[PartiallyUnrolledIterator[T], Long] = {
require(!contains(blockId), s"Block $blockId is already present in the MemoryStore")
var elementsUnrolled = 0
var keepUnrolling = true
val initialMemoryThreshold = unrollMemoryThreshold
val memoryCheckPeriod = 16
var memoryThreshold = initialMemoryThreshold
val memoryGrowthFactor = 1.5
var unrollMemoryUsedByThisBlock = 0L
var vector = new SizeTrackingVector[T]()(classTag)
keepUnrolling =
reserveUnrollMemoryForThisTask(blockId, initialMemoryThreshold, MemoryMode.ON_HEAP)
if (!keepUnrolling) {
logWarning(s"Failed to reserve initial memory threshold of " +
s"${Utils.bytesToString(initialMemoryThreshold)} for computing block $blockId in memory.")
} else {
unrollMemoryUsedByThisBlock += initialMemoryThreshold
}
//不断迭代读取Iterator中的数据,将数据放入追踪器vector中
while (values.hasNext && keepUnrolling) {
vector += values.next()
if (elementsUnrolled % memoryCheckPeriod == 0) {//周期性地检查
val currentSize = vector.estimateSize()
if (currentSize >= memoryThreshold) {
val amountToRequest = (currentSize * memoryGrowthFactor - memoryThreshold).toLong
keepUnrolling =
reserveUnrollMemoryForThisTask(blockId, amountToRequest, MemoryMode.ON_HEAP)
if (keepUnrolling) {
unrollMemoryUsedByThisBlock += amountToRequest
}
memoryThreshold += amountToRequest
}
}
elementsUnrolled += 1
}
if (keepUnrolling) {//申请到足够多的展开内存,将数据写入内存
val arrayValues = vector.toArray
vector = null
val entry =
new DeserializedMemoryEntry[T](arrayValues, SizeEstimator.estimate(arrayValues), classTag)
val size = entry.size
def transferUnrollToStorage(amount: Long): Unit = {//将展开Block的内存转换为存储Block的内存
memoryManager.synchronized {
releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP, amount)
val success = memoryManager.acquireStorageMemory(blockId, amount, MemoryMode.ON_HEAP)
assert(success, "transferring unroll memory to storage memory failed")
}
}
val enoughStorageMemory = {
if (unrollMemoryUsedByThisBlock <= size) {
val acquiredExtra =
memoryManager.acquireStorageMemory(
blockId, size - unrollMemoryUsedByThisBlock, MemoryMode.ON_HEAP)
if (acquiredExtra) {
transferUnrollToStorage(unrollMemoryUsedByThisBlock)
}
acquiredExtra
} else {//当unrollMemoryUsedByThisBlock > size,归还多余的展开内存空间
val excessUnrollMemory = unrollMemoryUsedByThisBlock - size
releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP, excessUnrollMemory)
transferUnrollToStorage(size)
true
}
}
if (enoughStorageMemory) {
entries.synchronized {
entries.put(blockId, entry)
}
logInfo("Block %s stored as values in memory (estimated size %s, free %s)".format(
blockId, Utils.bytesToString(size), Utils.bytesToString(maxMemory - blocksMemoryUsed)))
Right(size)
} else {
assert(currentUnrollMemoryForThisTask >= unrollMemoryUsedByThisBlock,
"released too much unroll memory")
Left(new PartiallyUnrolledIterator(
this,
MemoryMode.ON_HEAP,
unrollMemoryUsedByThisBlock,
unrolled = arrayValues.toIterator,
rest = Iterator.empty))
}
} else {
logUnrollFailureMessage(blockId, vector.estimateSize())
Left(new PartiallyUnrolledIterator(
this,
MemoryMode.ON_HEAP,
unrollMemoryUsedByThisBlock,
unrolled = vector.iterator,
rest = values))
}
}- 1)不断迭代读取Iterator中的数据,将数据放入追踪器vector中,并周期性地检查vector中所有数据的估算大小currentSize是否已经超过了memoryThreshold。当发现currentSize超过memoryThreshold,则为当前任务请求新的保留内存(内存大小的计算公式为:currentSize * memoryGrowthFactor - memoryThreshold)。在堆上成功申请到足够的内存后,需要更新unrollMemoryUsedByThisBlock和memoryThreshold的大小。
- 2)如果展开Iterator中所有的数据后,keepUnrolling为true,则说明已经为Block申请到足够多的保留内存,接下来的处理步骤如下:
-
①将vector中的数据封装为DeserializedMemoryEntry,并重新估算vector的大小size
-
②如果unrollMemoryUsedByThisBlock小于或等于size,说明用于展开的内存过多,需要向MemoryManager归还多余的空间。归还的内存大小为unrollMemoryUsedByThisBlock - size。之后调用 transferUnrollToStorage方法将展开Block占用的内存转换为用于存储Block的内存,此转换过程是原子的。
-
③如果有足够的内存存储Block,则将BlockId与DeserializedMemoryEntry的映射关系放入entries并返回Right(size)
-
④如果没有足够的内存存储Block,则创建PartiallyUnrollidIterator并返回Letf
-
3)如果展开Iterator中所有的数据后,keepUnrolling为false,说明没有为Block申请到足够多的保留内存,此时将创建PartiallyUnrolledIterator并返回Left。
2.5 getBytes
从内存中读取BlockId对应的Block(已经封装为ChunkedByteBuffer)
def getBytes(blockId: BlockId): Option[ChunkedByteBuffer] = {
val entry = entries.synchronized { entries.get(blockId) }
entry match {
case null => None
case e: DeserializedMemoryEntry[_] =>
throw new IllegalArgumentException("should only call getBytes on serialized blocks")
case SerializedMemoryEntry(bytes, _, _) => Some(bytes)
}
}getBytes只能获取序列化的Block
2.6 getValues
从内存中读取BlockId对应的Block(已经封装为Iterator)
def getValues(blockId: BlockId): Option[Iterator[_]] = {
val entry = entries.synchronized { entries.get(blockId) }
entry match {
case null => None
case e: SerializedMemoryEntry[_] =>
throw new IllegalArgumentException("should only call getValues on deserialized blocks")
case DeserializedMemoryEntry(values, _, _) =>
val x = Some(values)
x.map(_.iterator)
}
}getValues只能获取没有序列化的Block
2.7 remove
从内存中移除BlockId对应的Block
def remove(blockId: BlockId): Boolean = memoryManager.synchronized {
val entry = entries.synchronized {
entries.remove(blockId)
}
if (entry != null) {
entry match {
case SerializedMemoryEntry(buffer, _, _) => buffer.dispose()
case _ =>
}
memoryManager.releaseStorageMemory(entry.size, entry.memoryMode)
logDebug(s"Block $blockId of size ${entry.size} dropped " +
s"from memory (free ${maxMemory - blocksMemoryUsed})")
true
} else {
false
}
}- 1)将BlockId对应的MemoryEntry从entries中移除,如果entries中存在BlockId对应的MemoryEntry,则进入第2步,否则返回false
- 2)如果MemoryEntry是SerializedMemoryEntry,则还要将对应的ChunkedByteBuffer清理
- 3)调用MemoryManager的releaseStorageMemory方法,释放使用的存储内存
- 4)返回true
2.8 evictBlocksToFreeSpace
用于驱逐Block,以便释放一些空间来存储新的Block。
private[spark] def evictBlocksToFreeSpace(
blockId: Option[BlockId],
space: Long,
memoryMode: MemoryMode): Long = {
assert(space > 0)
memoryManager.synchronized {
var freedMemory = 0L
val rddToAdd = blockId.flatMap(getRddId)
val selectedBlocks = new ArrayBuffer[BlockId]
def blockIsEvictable(blockId: BlockId, entry: MemoryEntry[_]): Boolean = {
entry.memoryMode == memoryMode && (rddToAdd.isEmpty || rddToAdd != getRddId(blockId))
}
entries.synchronized {
val iterator = entries.entrySet().iterator()
while (freedMemory < space && iterator.hasNext) {//选择符合驱逐条件的Block
val pair = iterator.next()
val blockId = pair.getKey
val entry = pair.getValue
if (blockIsEvictable(blockId, entry)) {
if (blockInfoManager.lockForWriting(blockId, blocking = false).isDefined) {
selectedBlocks += blockId
freedMemory += pair.getValue.size
}
}
}
}
def dropBlock[T](blockId: BlockId, entry: MemoryEntry[T]): Unit = {
val data = entry match {
case DeserializedMemoryEntry(values, _, _) => Left(values)
case SerializedMemoryEntry(buffer, _, _) => Right(buffer)
}
val newEffectiveStorageLevel =
blockEvictionHandler.dropFromMemory(blockId, () => data)(entry.classTag)
if (newEffectiveStorageLevel.isValid) {
blockInfoManager.unlock(blockId)
} else {
blockInfoManager.removeBlock(blockId)
}
}
if (freedMemory >= space) { //通过驱逐可以为存储Block提供足够的空间,则进行驱逐
logInfo(s"${selectedBlocks.size} blocks selected for dropping " +
s"(${Utils.bytesToString(freedMemory)} bytes)")
for (blockId <- selectedBlocks) {
val entry = entries.synchronized { entries.get(blockId) }
if (entry != null) {
dropBlock(blockId, entry)
}
}
logInfo(s"After dropping ${selectedBlocks.size} blocks, " +
s"free memory is ${Utils.bytesToString(maxMemory - blocksMemoryUsed)}")
freedMemory
} else {//通过驱逐不能为存储Block提供足够的空间,则释放原本准备要驱逐的各个Block的写锁
blockId.foreach { id =>
logInfo(s"Will not store $id")
}
selectedBlocks.foreach { id =>
blockInfoManager.unlock(id)//释放写锁
}
0L
}
}
}evictBlocksToFreeSparce中定义了一些局部变量:
- blockId:要存储的Block的BlockId
- space:需要驱逐Block所腾出的内存大小
- memoryMode:存储Block所需的内存模式
- freedMemory:已经释放的内存大小
- rddToAdd:将要添加的RDD的RDDBlockId标记。rddToAdd实际是通过对BlockId应用getRddId方法得到的,其代码如下:
private def getRddId(blockId: BlockId): Option[Int] = {
blockId.asRDDId.map(_.rddId)
}上述代码说明首先调用了BlockId的asRDDId方法,将BlockId转换为RDDBlockId,然后获取RDDBlockId的rddId属性
- selectedBlocks:已经选择的用于驱逐的Block的BlockId的数组
有了对变量的理解,现在来看看evictBlocksToFreeSpace的执行步骤:
- 1)当freedMemory小于space时,不断迭代遍历iterator。对于每个entries中的BlockId和MemoryEntry,首先找出其中符合条件的Block(只有符合条件的Block才会被驱逐),然后获取Block的写锁,最后将此Block的BlockId放入selectedBlocks并且将freedMemory增加Block的大小。同时满足以下两个条件:
①MemoryEntry的内存模式与所需的内存模式一致
②BlockId对应的Block不是RDD,或者BlockId与blockId不是同一个RDD
- 2)经过第1步的处理,如果freedMemory大于等于space,这说明通过驱逐一定数据的Block,已经为存储BlockId对应的Block腾出了足够的内存空间,此时需要遍历selectedBlocks中的每个BlockId,并移除每个BlockId对应的Block。如果Block从内存中迁移到其它存储(如DiskStore)中,那么需要调用BlockInfoManager的unlock头痛药当前任务尝试线程获取的被迁移的Block的写锁。如果Block从存储体系中彻底移除,那么需要调用BlockInfoManager的removeBlock方法删除被迁移Block的信息。
- 3)经过第1步的处理,如果freedMemory小于space,这说明即便驱逐内存中所有符合条件的Block,腾出的空间也不足以存储blockId对应的Block,此时需要当前任务尝试线程释放selectedBlocks中每个BlockId对应的Block的写锁。
2.9 contains
用于判断本地MemoryStore中是否包含给定的BlockId所应对的Block文件
def contains(blockId: BlockId): Boolean = {
entries.synchronized { entries.containsKey(blockId) }
}