系统设计题:如何设计一个分布式ID生成器(Distributed ID Generator)?
应用场景(Scenario)
现实中很多业务都有生成唯一ID的需求,例如:
- 用户ID
- 微博ID
- 聊天消息ID
- 帖子ID
- 订单ID
需求(Needs)
这个ID往往会作为数据库主键,所以需要保证全局唯一。数据库会在这个字段上建立聚集索引(Clustered Index,参考 MySQL InnoDB),即该字段会影响各条数据再物理存储上的顺序。
ID还要尽可能短,节省内存,让数据库索引效率更高。基本上64位整数能够满足绝大多数的场景,但是如果能做到比64位更短那就更好了。需要根据具体业务进行分析,预估出ID的最大值,这个最大值通常比64位整数的上限小很多,于是我们可以用更少的bit表示这个ID。
查询的时候,往往有分页或者排序的需求,所以需要给每条数据添加一个时间字段,并在其上建立普通索引(Secondary Index)。但是普通索引的访问效率比聚集索引慢,如果能够让ID按照时间粗略有序,则可以省去这个时间字段。为什么不是按照时间精确有序呢?因为按照时间精确有序是做不到的,除非用一个单机算法,在分布式场景下做到精确有序性能一般很差。
这就引出了ID生成的三大核心需求:
- 全局唯一(unique)
- 按照时间粗略有序(sortable by time)
- 尽可能短
一些方案
Generate IDs in web application
举例,MongoDB对每个document都会自动生成一个ObjectID。实际上它用的是一种UUID算法,生成的ObjectId占12个字节,由以下几个部分组成,
- 4个字节表示的Unix timestamp,
- 3个字节表示的机器的ID
- 2个字节表示的进程ID
- 3个字节表示的计数器
UUID是一类算法的统称,具体有不同的实现。UUID的有点是每台机器可以独立产生ID,理论上保证不会重复,所以天然是分布式的,缺点是生成的ID太长,不仅占用内存,而且索引查询效率低。
注:GUID和UUID的区别
A Globally Unique Identifier (GUID) is an identifier designed to be a unique reference. GUIDs are commonly 128-bit numbers represented as several sequences of hex digits. A Universally Unique Identifier (UUID) actually refers to one particular variant of a GUID, which has several versions; that means UUIDs are a subset of GUIDs, albeit a very large one.
这种方法的好处和坏处(摘自ins技术博客)如下:
Pros:
- Each application thread generates IDs independently, minimizing points of - failure and contention for ID generation
- If you use a timestamp as the first component of the ID, the IDs remain time-sortable.
Cons:
- Generally requires more storage space (96 bits or higher) to make reasonable uniqueness guarantees.
- Some UUID types are completely random and have no natural sort.
Generate IDs through dedicated service
比如 Twitter 有个成熟的开源项目,就是专门生成ID的,Twitter Snowflake 。Snowflake的核心算法如下:
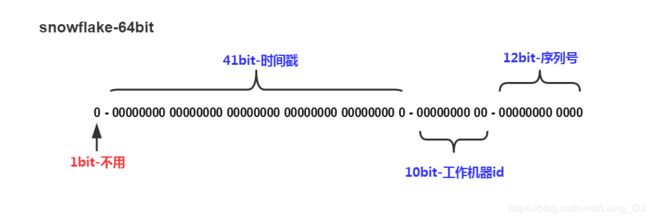
其最高位不用,永远为0,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。
Pros:
- Snowflake IDs are 64-bits, half the size of a UUID
Can use time as first component and remain sortable - Distributed system that can survive nodes dying
Cons:
- Would introduce additional complexity and more ‘moving parts’ (ZooKeeper, Snowflake servers) into our architecture(因为Snowflake用到了Apache ZooKeeper来协调各个节点,然后产生64位的唯一的ID)
DB Ticket Servers
举例,flickr(美国的一个图片网站)。
这里贴上他们的中英版本的技术博客解释,可以对照看一下,解释地很详细了。
英文技术博客
中文翻译
简单来说就是用多台MySQL服务器,组成一个高性能的分布式发号器呢? 怎么做到这点?
假设用8台MySQL服务器协同工作,第一台MySQL初始值是1,每次自增8,第二台MySQL初始值是2,每次自增8,依次类推。前面用一个 round-robin load balancer 挡着,每来一个请求,由 round-robin balancer 随机地将请求发给8台MySQL中的任意一个,然后返回一个ID。
Flickr就是这么做的,仅仅使用了两台MySQL服务器(一个针对奇数处理,一个针对偶数处理)。
Pros:
- DBs are well understood and have pretty predictable scaling factors
Cons:
- Can eventually become a write bottleneck (though Flickr reports that, even at huge scale, it’s not an issue).
- An additional couple of machines (or EC2 instances) to admin
- If using a single DB, becomes single point of failure. If using multiple DBs, can no longer guarantee that they are sortable over time.
INS团队用的方案
其实和Twitter比较像,但不需要用zookeeper来协调各个节点。它用了41位表示时间戳,13位表示shard Id(一个shard Id对应一台PostgreSQL机器), 最低10位表示自增ID。
举个例子来说明下他们的方案:
现在是2011年9月9日下午5点,计算开始时间是2011年1月1日,那到现在有1387263000毫秒。那么id就是如下的数字
id = 1387263000 <<(64-41)
然后,我们根据user id进行切片(shard),有2000个shards,如果现在我们的user id是31341,对其进行2000去模,得到1314。(31341 = 1314(mod 2000))它这个user对应的shard id就是如下的数字:
shard id= 1341 <<(64-41-13)
最后考虑自增序列id,假设现在的自增序列值是5001,那我们对其取1024的模等于7
auto-increment id = 7
那针对这个例子,这个唯一的id就是:
00000000001010010101011111111010000011000(41位,对应1387263000) 0001010010010(13位,对应1341) 0000000111(10位,对应7)
下面贴上参考的资料,都写得很详细,本文只是在这些资料基础上进行参考归纳。有空可以全部看一遍(尤其是前三条)。
参考资料:
- 如何设计一个分布式ID生成器(Distributed ID Generator),并保证ID按时间粗略有序
- Sharding & IDs at Instagram
- Ticket Servers: Distributed Unique Primary Keys on the Cheap
- Ticket 服务: 一种经济的分布式唯一主键生成方案
- Quaro: What is the difference between UUID and GUID?