前言
这几天看了点PyQt相关的知识,感觉可以结合之前得一些内容做出点什么好玩的东西。
之前做过文本转语音的聊天机器人,昨天又恰好做了关于音频处理的。借此机会,整合一下,来做个有界面的语音文本聊天机器人好了。
先来看看最终的效果图。
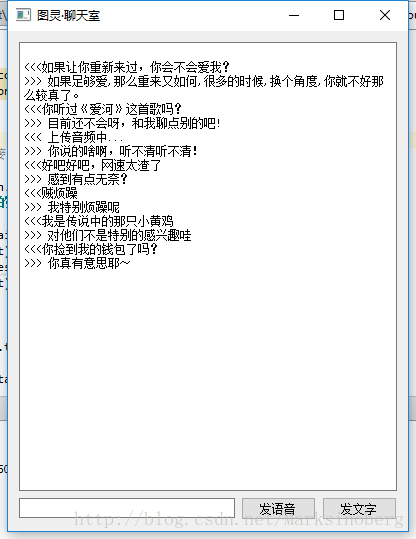
对这些基础内容不是很了解的可以参考我之前的文章。
聊天机器人http://blog.csdn.net/marksinoberg/article/details/52983462
文本转语音:http://blog.csdn.net/marksinoberg/article/details/52137547
音频处理:http://blog.csdn.net/marksinoberg/article/details/71577704
环境
环境搭建是个坑,之前一直在用的pyttsx语音引擎竟然不支持Python36,只能在Python27版本使用。所以无奈只能选用微软的提供的win32com.client了。
本机环境
本机环境如下
- Windows10 64位
- Python36
- PyCharm pro
所需包
所需包一开始我是手动统计的,但是后来觉得版本这块最好还是精确一下,于是使用了pip的一个freeze命令。
pip freeze > requirements.txt
得到了下面的这些所需的库文件(我删除了一些没用到的)。
PyAudio==0.2.11
PyQt5==5.8.2
pyttsx==1.1
pywin32==221
requests==2.13.0
sip==4.19.2
各大模块
下面开始针对各大模块简要的介绍一下。
百度语音接口
百度语音接口是用来处理本地音频到文本内容转换而使用的。需要用到标准库中的wave库,来处理.wav音频文件。
# coding: utf8
# @Author: 郭 璞
# @File: baiduyuyin.py
# @Time: 2017/5/11
# @Contact: [email protected]
# @blog: http://blog.csdn.net/marksinoberg
# @Description: 借助百度语音识别接口实现本地语音解析
import pyaudio
import wave
import requests
import json
class BaiDuYuYin(object):
def __init__(self):
# get the token
self.token = self.gettoken()
def gettoken(self):
try:
apiKey = "Ll0c嘿嘿2ZSGAU"
secretKey = "44c8a这个不能说34936227d4a19dc2"
auth_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=" + apiKey + "&client_secret=" + secretKey
response = requests.get(url=auth_url)
jsondata = response.text
return json.loads(jsondata)['access_token']
except Exception as e:
raise Exception("Cannot get the token, the reason is {}".format(e))
def parse(self, wavefile='local.wav'):
"""
返回音频文件对应的文本内容。
注意返回的是列表类型的数据,待会处理的时候要格外的小心。
:param wavefile:
:return:
"""
try:
fp = wave.open(wavefile, 'rb')
# 已经录好音的音频片段内容
nframes = fp.getnframes()
filelength = nframes * 2
audiodata = fp.readframes(nframes)
# 百度语音接口的产品ID
cuid = '7519663'
server_url = 'http://vop.baidu.com/server_api' + '?cuid={}&token={}'.format(cuid, self.token)
headers = {
'Content-Type': 'audio/pcm; rete=8000',
'Content-Length': '{}'.format(filelength),
}
response = requests.post(url=server_url, headers=headers, data=audiodata)
print(response.text)
data = json.loads(response.text)
if data['err_msg'] == 'success.':
return data['result']
else:
return '你说的啥啊,听不清听不清!'
except Exception as e:
raise Exception("Parsing wave file failed. The reason is {}".format(e))
if __name__ == '__main__':
yuyinclient = BaiDuYuYin()
result = yuyinclient.parse(wavefile='local.wav')
print(result)
图灵机器人接口
然后是图灵机器人接口,这个用于处理文本对话。免费版其实已经够用了。有需要的自己去申请吧。
# coding: utf8
# @Author: 郭 璞
# @File: turing.py
# @Time: 2017/5/11
# @Contact: [email protected]
# @blog: http://blog.csdn.net/marksinoberg
# @Description: 文字对话接口实现
import requests
import json
class TuringRobot(object):
def __init__(self):
self.apikey = '2a220b3哟哟哟b74c54'
self.userid = '产品ID不能说'
self.url = 'http://www.tuling123.com/openapi/api'
def talk(self, text):
payload = {
'key': self.apikey,
'userid': self.userid,
'info': text
}
response = requests.post(url=self.url, data=payload)
return json.loads(response.text)['text']
if __name__ == '__main__':
turing = TuringRobot()
answer = turing.talk('你好吗,我是小黄鸡!')
print(answer)
音频处理
昨天对于音频处理这块做了一点点的研究,今天还是那个套路。默认录音五秒,保存为同一级目录下的local.wav文件。
# coding: utf8
# @Author: 郭 璞
# @File: recorder.py
# @Time: 2017/5/11
# @Contact: [email protected]
# @blog: http://blog.csdn.net/marksinoberg
# @Description: 记录本地录音,默认保存为local.wav, 留作解析引擎备用。
import pyaudio
import wave
class Recorder(object):
def __init__(self):
self.CHUNK = 1024
self.FORMAT = pyaudio.paInt16
self.CHANNELS = 2
self.RATE = 44100
self.RECORD_SECONDS = 5
self.WAVE_OUTPUT_FILENAME = 'local.wav'
self.engine = pyaudio.PyAudio()
def record(self):
try:
# 提示语句可以使用一下语音方式,这里先打印算了。
print("Begin Recoding ...")
stream = self.engine.open(format=self.FORMAT,
channels=self.CHANNELS,
rate=self.RATE,
input=True,
frames_per_buffer=self.CHUNK)
# 记录到的音频总数据帧
frames = []
for i in range(0, int(self.RATE / self.CHUNK * self.RECORD_SECONDS)):
data = stream.read(self.CHUNK)
frames.append(data)
# 音频记录完毕
print('Recording Over!')
# 释放资源,接触阻塞监听。
stream.stop_stream()
stream.close()
self.engine.terminate()
# 并将音频数据保存到本地音频文件中
wf = wave.open(self.WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(self.CHANNELS)
wf.setsampwidth(self.engine.get_sample_size(self.FORMAT))
wf.setframerate(self.RATE)
wf.writeframes(b''.join(frames))
wf.close()
except Exception as e:
raise Exception("Recording failed. The reason is {}".format(e))
if __name__ == '__main__':
recorder = Recorder()
recorder.record()
本地朗读模块
本地语音朗读相当于是一个加分项,之前一直在用的pyttsx这下尴尬了,无奈只能试用第二个方式,不过使用pyttsx的代码我还是留出来吧。万一哪天它支持了Python36,就有更多可选项的丰富功能了。
# coding: utf8
# @Author: 郭 璞
# @File: localvoicer.py
# @Time: 2017/5/11
# @Contact: [email protected]
# @blog: http://blog.csdn.net/marksinoberg
# @Description: 本地语音朗读实现。
import win32com.client
class Reader(object):
"""
尴尬的是pyttsx不支持Python36,要不然还可以有更多可选项。
"""
def __init__(self):
import pyttsx
self.engine = pyttsx.init()
# optional property
self.rate = self.engine.getProperty('rate')
self.voices = self.engine.getProperty('voices')
self.volume = self.engine.getProperty('volume')
def read(self, text="", rate=200, voices="", volume=""):
self.engine.say(text)
self.engine.runAndWait()
class Speaker(object):
def __init__(self):
self.engine = win32com.client.Dispatch("SAPI.SpVoice")
def speak(self, text):
self.engine.Speak(text)
if __name__ == '__main__':
# reader = Reader()
# reader.read(text='Hello World!')
speaker = Speaker()
speaker.speak("hello world! 你好世界")
GUI 模块
做完了前面的部分,就差界面了。测试完毕之后发现,各大模块均能正常工作,虽然音频解析那块特别地依赖于网速,校园网这网速我也是醉了。
下面简单的写个界面来“打包美化”一下吧。
# coding: utf8
# @Author: 郭 璞
# @File: audioui.py
# @Time: 2017/5/11
# @Contact: [email protected]
# @blog: http://blog.csdn.net/marksinoberg
# @Description: 外部界面
from PyQt5 import QtCore, QtGui, QtWidgets
from audiorobot.dispatcher import Dispatcher
from audiorobot.baiduyuyin import BaiDuYuYin
from audiorobot.turing import TuringRobot
from audiorobot.localvoicer import Speaker
class ClientUI(QtWidgets.QWidget):
def __init__(self):
super(ClientUI, self).__init__()
self.dispatcher = Dispatcher()
self.baiduyuyin = BaiDuYuYin()
self.turingrobot = TuringRobot()
self.speaker = Speaker()
self.initui()
def initui(self):
self.setWindowTitle("图灵·聊天室")
self.setGeometry(20, 20, 400, 500)
# 顶部布局
toplayout = QtWidgets.QHBoxLayout()
self.textarea = QtWidgets.QTextBrowser()
toplayout.addWidget(self.textarea)
# 中间布局
centerlayut = QtWidgets.QHBoxLayout()
self.editline = QtWidgets.QLineEdit()
self.voicebutton = QtWidgets.QPushButton("发语音")
self.textbutton = QtWidgets.QPushButton("发文字")
centerlayut.addWidget(self.editline)
centerlayut.addWidget(self.voicebutton)
centerlayut.addWidget(self.textbutton)
mainlayout = QtWidgets.QVBoxLayout()
mainlayout.addLayout(toplayout)
mainlayout.addLayout(centerlayut)
self.setLayout(mainlayout)
# 关于事件处理,交给handler来处理即可
self.eventhandler()
def eventhandler(self):
self.voicebutton.clicked.connect(self.pushvoice)
self.textbutton.clicked.connect(self.pushtext)
def pushvoice(self):
print('voice')
# 先保存到本地,再调用语音接口上传
self.dispatcher.record()
response = self.baiduyuyin.parse()
print('百度语音接口解析到的数据为:{}'.format(response))
self.speaker.speak(text=response)
# 更新一下窗体文本域的内容
text = self.textarea.toPlainText()+"\n"+"<<< "+"上传音频中..."
self.textarea.setText(text)
text = text +"\n>>> " +response
self.textarea.setText(text)
def pushtext(self):
inputtext = self.editline.text()
print(inputtext)
trans = self.turingrobot.talk(text=inputtext)
self.speaker.speak(text=trans)
# 更新文本域内容
text = self.textarea.toPlainText() + "\n<<<"+inputtext
self.textarea.setText(text)
text = self.textarea.toPlainText() + "\n>>> " + trans
self.textarea.setText(text)
self.editline.clear()
if __name__ == '__main__':
import sys
app = QtWidgets.QApplication(sys.argv)
ui = ClientUI()
ui.show()
sys.exit(app.exec_())
演示
好了,大功告成。运行代码的时候仅仅需要下面的这个命令就可以了。
Python audioui.py
文本
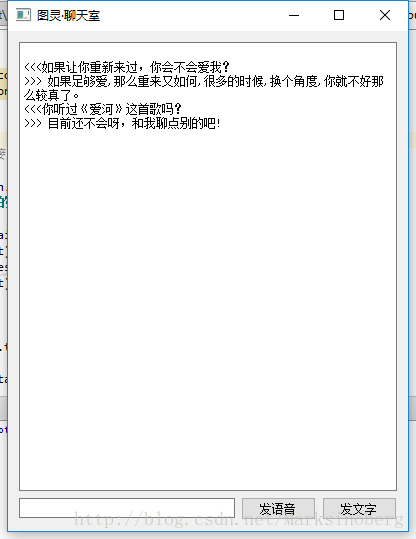
先来看看对于文本的处理,这其实跟之前的聊天机器人没啥区别。仅仅是带了语音朗读罢了。
语音
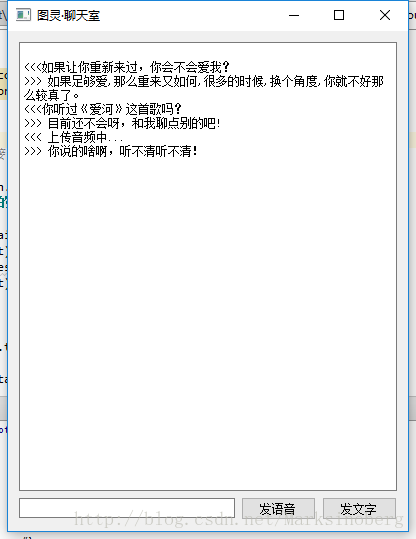
然后是语音测试,我本人在图书馆。所以为了不打扰别人,录音的时候只能假装咳嗽来掩盖测试录音的事实,所以效果不是很好。但是如果是标准的普通话,测试的结果还是差强人意的。
总结
最后还是来总结一下。
本次也算是整合的比较多的内容了。模块内测试都是用的
if __name__ == "__main__":
# testing code
pass
看起来还算不错,单元测试倒是没什么必要,毕竟代码量还很少。集成测试也算是马马虎虎,功能这块倒是还能满足需求,但是以后如果代码量大了的话,还是要好好测测的,以防万一。
已知的缺点就是界面这块。录音的时候要是能加一个statusBar实时提醒录音进度就好了,而且录音的时候是阻塞线程的,不是很优雅。