拉勾网Python爬虫:Selenium+Xpath 反反爬、免登录获取全部职位详情
目录
- 需求描述
- 需求分析
- 实现原理
- 注意问题
- URL示例
- 完整代码
- 运行图示
- 后续优化
- 后记
需求描述
抓取「拉勾网」『北京 数据分析师』30页职位详情数据存入 MySQL 数据库
需求分析
- 拉勾网搜索页面一般都只展示30页、每页15个职位信息,约450条;
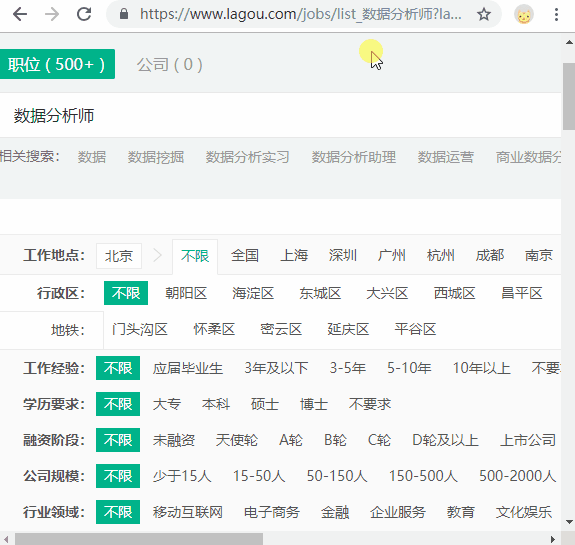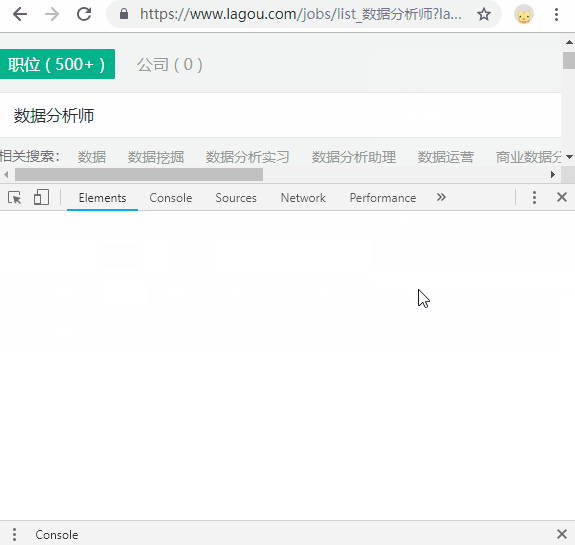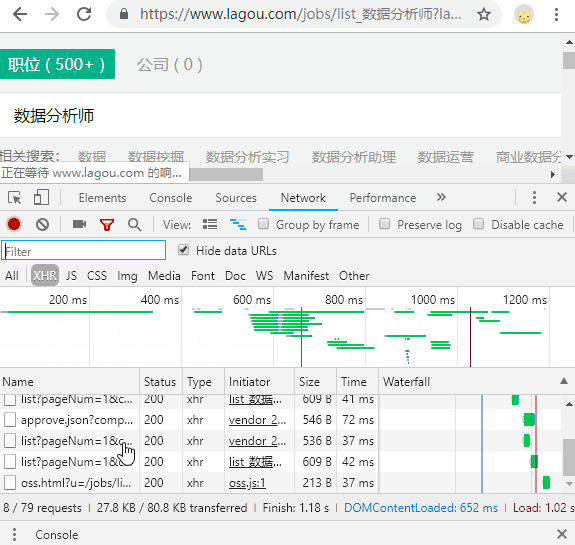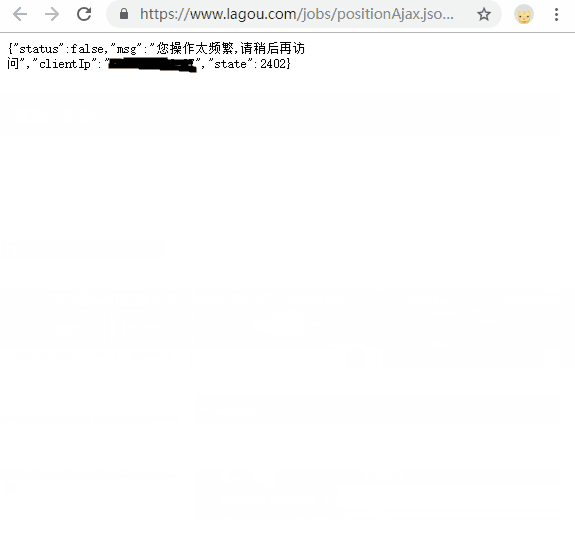
- 拉勾网反爬加强,直接请求 positionAjax.json 无法获得包含职位信息的 json 数据(提示:“msg”:“您操作太频繁,请稍后再访问”),浏览器都无法访问,延长间隔时间也无济于事,转而考虑
selenium来实现。
实现原理
- selenium浏览器自动化测试框架驱动谷歌浏览器,模拟人使用浏览器查看网页的过程获取数据;
- 先请求搜索页面解析得到职位详情页的 url,再进入详情页获取全部所需的详情;
- 不过职位详细信息需要逐一解析html获取(麻烦),不如json数据那般可直接提取(容易)。
注意问题
- 搜索页和详情页请求过快便会跳出来登录页面,需要适当延长间隔时间(尤其是连续请求详情页),尽可能模拟人的行为;
- 连续请求10个详情页就会弹出登录页(实测手动在浏览器中操作也是),每请求10个需要重启一次浏览器(不重启则一直弹出登录);
- 因需要尽可能模拟人在操作浏览器,间隔时间较多、耗时较长,请耐心等待。
- 本文使用的谷歌浏览器,需要提前下载
chromedriver.exe放入工作目录。 - 本例直接生成 sql 文件 以导入MySQL数据库(source xxx.sql),下一篇文章会用 pymysql 模块直接存入数据库 → 看这里。
URL示例
搜索页示例:https://www.lagou.com/jobs/list_数据分析师?city=北京&cl=false&fromSearch=true&labelWords=&suginput=
详情页示例:https://www.lagou.com/jobs/5496895.html
完整代码
"""
抓取拉勾网“北京”“数据分析师”30页职位详情数据存入MySQL数据库
@Author: Newyee
@Python: 3.6.5
@selenium: 3.141.0
@Chrome: 72.0.3626.81
"""
# 导入相关模块(未安装可执行 pip install xxx 命令安装)
from selenium import webdriver
from lxml import etree
import random
import time
# 创建类
class LagouSpider():
def __init__(self):
# 初始化类实例时打开谷歌浏览器(可查看测试过程)
self.driver = webdriver.Chrome()
# 搜索页面的url
self.url = "https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput="
# 存放所有职位详情页的url
self.all_links = []
def run2(self, ten_links):
'''
每次对10个职位详情url请求并解析,保存职位详细信息,退出浏览器
:param ten_links: 10个职位详情页url组成的list
:return:
'''
# 遍历每个detail_url
for link in ten_links:
# 调用request_detail_page请求并解析
self.request_detail_page(link)
# 随机间隔3-6s,避免反爬
time.sleep(random.randint(3, 6))
# 获取10个职位信息后退出浏览器
self.driver.quit()
def run1(self):
'''
打开搜索页面,并循环翻页至最后一页,解析html获得all_detail_links
:return:
'''
# 在当前打开的浏览器中加载页面
self.driver.get(self.url)
# 用于记录当前是第几页
count_page = 1
# 循环翻页直到最后一页
while True:
# 获取当前页的网页源代码
source = self.driver.page_source
# 利用xpath解析source获得detail_links并保存到
self.get_all_detail_links(source)
print('Fetched page %s.' %str(count_page))
# 找到【下一页】按钮所在的节点
next_btn = self.driver.find_element_by_xpath('//div[@class="pager_container"]/span[last()]')
# 判断【下一页】按钮是否可用
if "pager_next_disabled" in next_btn.get_attribute("class"):
# 【下一页】按钮不可用时即达到末页,退出浏览器
self.driver.quit()
# 返回所有职位详情页url列表(去重后的)
return list(set(self.all_links))
else:
# 【下一页】按钮可用则点击翻页
next_btn.click()
count_page += 1
time.sleep(random.randint(2, 4))
time.sleep(random.randint(3, 5))
def get_all_detail_links(self, source):
'''
利用xpath解析source获得detail_links并保存到self.all_links
:param source: 网页源代码html
:return:
'''
html = etree.HTML(source)
links = html.xpath('//a[@class="position_link"]/@href')
self.all_links += links
def request_detail_page(self, url):
'''
请求职位详情页面,并调用parse_detail_page函数
:param url: 职位详情页url
:return:
'''
# 在当前窗口中同步执行javascript
self.driver.execute_script("window.open('%s')" % url) # 执行后打开新页面(句柄追加一个新元素)
# driver.switch_to.window:将焦点切换到指定的窗口
# driver.window_handles:返回当前会话中所有窗口的句柄
self.driver.switch_to.window(self.driver.window_handles[1]) # 切换到新打开的窗口,即第2个--index==1
source = self.driver.page_source
self.parse_detail_page(source)
self.driver.close()
self.driver.switch_to.window(self.driver.window_handles[0]) # 切换到主窗口(否则不能再次打开新窗口)
def parse_detail_page(self, source):
'''
解析详情页,用xpath提取出需要保存的职位详情信息并保存
:param source: 职位详情页的网页源代码html
:return:
'''
# 将source传入lxml.etree.HTML()解析得到etree.HTML文档
html = etree.HTML(source)
# 对html用xpath语法找到职位名称所在节点的文本,即position_name
position_name = html.xpath("//span[@class='name']/text()")[0]
# 对html用xpath语法找到职位id所在的节点,提取获得position_id
position_id = html.xpath("//link[@rel='canonical']/@href")[0].split('/')[-1].replace('.html', '')
# 找到职位标签,依次获取:薪资、城市、年限、受教育程度、全职or兼职
job_request_spans = html.xpath('//dd[@class="job_request"]//span')
salary = job_request_spans[0].xpath('.//text()')[0].strip() # 列表索引0==xpath第1个节点
city = job_request_spans[1].xpath('.//text()')[0].strip().replace("/", "").strip()
work_year = job_request_spans[2].xpath('.//text()')[0].strip("/").strip()
education = job_request_spans[3].xpath('.//text()')[0].strip("/").strip()
# 找到公司标签,获取company_short_name
company_short_name = html.xpath('//dl[@class="job_company"]//em/text()')[0].replace("\n", "").strip()
# 找到公司标签中的industry_field和finance_stage
company_infos = html.xpath('//dl[@class="job_company"]//li') # 注意该节点下的text()索引0和2是空的
industry_field = company_infos[0].xpath('.//text()')[1].replace("\n", "").strip()
finance_stage = company_infos[1].xpath('.//text()')[1].replace("\n", "").strip()
# 找到工作地址所在的区
district = html.xpath('//div[@class="work_addr"]/a[2]/text()')[0].strip()
# 找到职位诱惑,获取position_advantage
position_advantage = html.xpath('//dd[@class="job-advantage"]//p/text()')[0].strip("/").strip().replace(",", ",")
# 找到所有职位标签,用","连接成字符串
position_labels = ",".join(html.xpath('//li[@class="labels"]//text()')).strip()
# 生成MySQL插入语句
sql = "INSERT INTO %s (position_name, work_year, education, finance_stage, company_short_name, " \
"industry_field, city, salary, position_id, position_advantage, district, position_labels " \
") VALUES " \
"('%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s');" % (
table_name,
position_name, work_year, education, finance_stage, company_short_name, industry_field,
city, salary, position_id, position_advantage, district, position_labels)
# 以追加的方式打开table_name.sql文件,写入sql语句
with open('%s.sql' %table_name, 'a', encoding='utf-8') as f:
f.write(sql+'\n')
print('Saved position:', position_id)
if __name__ == "__main__":
# 记录项目开始时间
start_time = time.time()
# 数据库中将要创建的表名,可自行修改
table_name = 'DataAnalyst_Beijing'
# 数据库中创建表语句(字段类型设置请自行调整优化,作者目前在这方面经验不多)
create_table_sql = "CREATE TABLE IF NOT EXISTS %s ( " \
"id INT(5) NOT NULL AUTO_INCREMENT, " \
"position_name VARCHAR(512) DEFAULT NULL, " \
"work_year VARCHAR(64) DEFAULT NULL, " \
"education VARCHAR(64) DEFAULT NULL, " \
"finance_stage VARCHAR(1024) DEFAULT NULL, " \
"company_short_name VARCHAR(64) DEFAULT NULL, " \
"industry_field VARCHAR(1024) DEFAULT NULL, " \
"city VARCHAR(64) DEFAULT NULL, " \
"salary VARCHAR(64) DEFAULT NULL, " \
"position_id VARCHAR(64) DEFAULT NULL, " \
"position_advantage VARCHAR(1024) DEFAULT NULL, " \
"district VARCHAR(64) DEFAULT NULL, " \
"position_labels VARCHAR(1024) DEFAULT NULL, " \
"PRIMARY KEY (id) );" % table_name
# 创建table_name.sql文件,写入建表语句
with open('%s.sql' % table_name, 'w', encoding='utf-8') as f:
f.write(create_table_sql + '\n')
# 实例化LagouSpider类,调用run1方法获取所有职位详情页的url
needed_all_links = LagouSpider().run1()
# 将所有职位详情url以10位单位拆分成嵌套列表
nested_all_links = [needed_all_links[i:i + 10] for i in range(0, len(needed_all_links), 10)]
count = 10
# 连续请求10个详情页就会弹出登录页,故每请求10个重启一次浏览器
for ten_links in nested_all_links:
# 每10个为一组,打开一次浏览器,调用run2方法保存职位详细信息
LagouSpider().run2(ten_links)
# count计数调整间隔时间,请求过多弹出登录
time.sleep(random.randint(6, 12) * (count // 100 + 1))
count += 10
print('-------------------------')
print('Have fetched %s positions.' %str(count))
# 记录项目结束时间
end_time = time.time()
print('\n【项目完成】\n【总共耗时:%.2f分钟】' %((end_time - start_time) / 60))
运行图示
后续优化
- 1.隐藏浏览器运行界面,避免干扰用户进行其他操作(耗时长,每次重启都会弹出)
- 2.将 SearchWord 和 City 作为自定义参数传入 url,便于配置不同需求
- 3.直接用 pymysql 操作数据库,不必生成 sql 文件再手动导入
- 4.等待时间很长,考虑多线程请求详情页 url 加速(10个一组应该很容易实现)
- 5.不显示启动浏览器时的 DevTools listening on ws://xxx/devtools/browser/ 日志(影响整体输出,不爽但又暂时干不掉)
优化更新后的代码会在GitHub上展示,敬请期待
后记
本文的诞生还要多谢 OKOK兄弟 提的需求
第一次发博文,莫名紧张,代码和行文有欠妥之处还请各路大神斧正,Thanks♪