kaggle房价预测(House Prices: Advanced Regression Techniques)数据分析(二)
这是上一篇的数据分析笔记https://blog.csdn.net/Nyte2018/article/details/90045166
kernel中有许多很好的分析,最好多看几篇学习,这次的看的kernel是Stacked Regressions : Top 4% on LeaderBoard
1、准备工作
各种库的导入:
#import some necessary librairies
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
%matplotlib inline
import matplotlib.pyplot as plt # Matlab-style plotting
import seaborn as sns
color = sns.color_palette()
sns.set_style('darkgrid')
import warnings
def ignore_warn(*args, **kwargs):
pass
warnings.warn = ignore_warn #ignore annoying warning (from sklearn and seaborn)
from scipy import stats
from scipy.stats import norm, skew #for some statistics
pd.set_option('display.float_format', lambda x: '{:.3f}'.format(x)) #Limiting floats output to 3 decimal points
import os
print(os.listdir('./data'))#check the files available in the directory
注:sns.color_palette()返回定义调色板的颜色列表。set_style()有5个seaborn的主题:darkgrid(灰色网格),whitegrid(白色网格),dark(黑色),white(白色),ticks(十字叉)。这里显示文件目录下的文件用了os方法,因为我之前运行的时候一直报错,说找不到文件。用这个方法显示也是可以的,问题不大。
['data_description.doc', 'data_description.txt', 'sample_submission.csv', 'test.csv', 'train.csv']
然后就可以导入文件:
#Now let's import and put the train and test datasets in pandas dataframe
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
显示训练集上前五行数据:
##display the first five rows of the train dataset.
train.head(5)

显示测试集上前五行数据:
##display the first five rows of the test dataset.
test.head(5)

删除id那一列,并显示前后的数据大小:
#check the numbers of samples and features
print("The train data size before dropping Id feature is : {} ".format(train.shape))
print("The test data size before dropping Id feature is : {} ".format(test.shape))
#Save the 'Id' column
train_ID = train['Id']
test_ID = test['Id']
#Now drop the 'Id' colum since it's unnecessary for the prediction process.
train.drop("Id", axis = 1, inplace = True)
test.drop("Id", axis = 1, inplace = True)
#check again the data size after dropping the 'Id' variable
print("\nThe train data size after dropping Id feature is : {} ".format(train.shape))
print("The test data size after dropping Id feature is : {} ".format(test.shape))
The train data size before dropping Id feature is : (1460, 81)
The test data size before dropping Id feature is : (1459, 80)
The train data size after dropping Id feature is : (1460, 80)
The test data size after dropping Id feature is : (1459, 79)
2、数据处理
离群值
先来看GrLivArea(地面上生活面积)和SalePrice的散点图:
fig, ax = plt.subplots()
ax.scatter(x = train['GrLivArea'], y = train['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
plt.show()

可以看出,在底部的最右边有两个GrLivArea很大的值,但价格很低,可以判断是离群值而删除。
删除离群值并再检查一遍:
#Deleting outliers
train = train.drop(train[(train['GrLivArea']>4000) & (train['SalePrice']<300000)].index)
#Check the graphic again
fig, ax = plt.subplots()
ax.scatter(train['GrLivArea'], train['SalePrice'])
plt.ylabel('SalePrice', fontsize=13)
plt.xlabel('GrLivArea', fontsize=13)
plt.show()

SalePrice分析
sns.distplot(train['SalePrice'] , fit=norm);
#Get the fitted parameters used by the function
(mu, sigma) = norm.fit(train['SalePrice'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
#Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
#Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(train['SalePrice'], plot=plt)
plt.show()

可以看出SalePrice是右偏态,因为线性模型更喜欢正态分布的数据,所以需要log转变这些数据:
#We use the numpy fuction log1p which applies log(1+x) to all elements of the column
train["SalePrice"] = np.log1p(train["SalePrice"])
#Check the new distribution
sns.distplot(train['SalePrice'] , fit=norm);
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(train['SalePrice'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
#Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
#Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(train['SalePrice'], plot=plt)
plt.show()

特征工程
首先将训练集和数据集连接到一个dataframe中:
ntrain = train.shape[0]
ntest = test.shape[0]
y_train = train.SalePrice.values
all_data = pd.concat((train, test)).reset_index(drop=True)
all_data.drop(['SalePrice'], axis=1, inplace=True)
print("all_data size is : {}".format(all_data.shape))
注:DataFrame.reset_index可以重置index为默认,drop = True 代表把新生成的index列 ( 原来的index ) 删掉。
all_data size is : (2917, 79)
缺失值
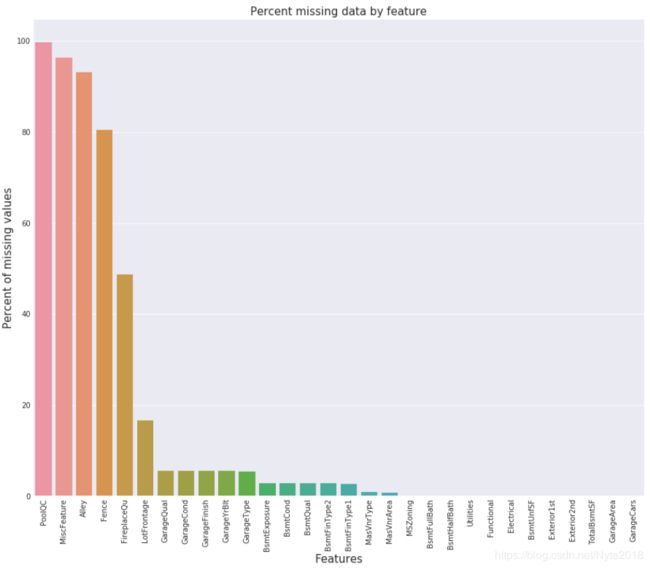
显示前20个有缺失值的变量和比率:
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
all_data_na = all_data_na.drop(all_data_na[all_data_na == 0].index).sort_values(ascending=False)[:30]
missing_data = pd.DataFrame({'Missing Ratio' :all_data_na})
missing_data.head(20)

用条形图来表示上述信息:
f, ax = plt.subplots(figsize=(15, 12))
plt.xticks(rotation='90')
sns.barplot(x=all_data_na.index, y=all_data_na)
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)
Text(0.5, 1.0, 'Percent missing data by feature')
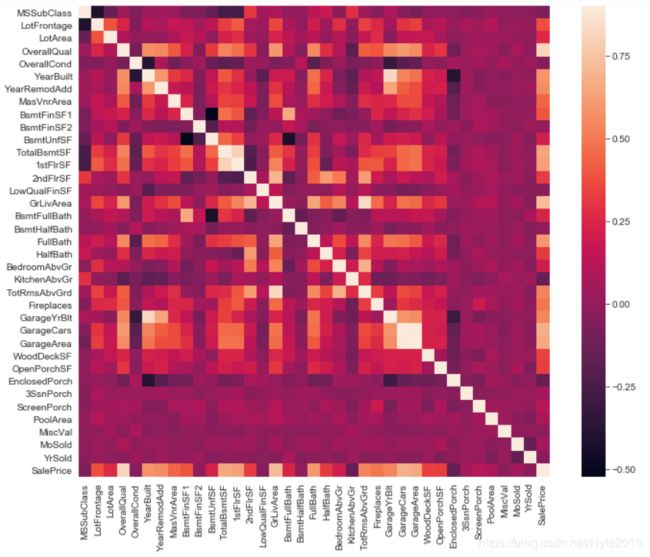
数据相关性:
用热力图显示训练集中变量的相关性:
输入缺失值:
我们通过依次处理缺失值的特征来输入它们:
(1)PoolQC:游泳池质量。NA表示没有游泳池。而有99%以上的缺失值说明大多数房屋都没有游泳池。
all_data["PoolQC"] = all_data["PoolQC"].fillna("None")
注:fillna表示用特殊值填充NA值。
(2)MiscFeature:其他类别未涵盖的其他功能。NA表示没有其它特征。
all_data["MiscFeature"] = all_data["MiscFeature"].fillna("None")
(3)Alley:连接房屋的胡同道路类型。NA表示没有胡同。
all_data["Alley"] = all_data["Alley"].fillna("None")
(4)Fence :围栏质量。NA表示没有围栏。
all_data["Fence"] = all_data["Fence"].fillna("None")
(5)FireplaceQu:壁炉质量。NA表示没有壁炉。
all_data["FireplaceQu"] = all_data["FireplaceQu"].fillna("None")
(6)LotFrontage:与房屋相连的街道的延长英尺,就是街道的长度。由于与房产相连的每条街道的面积很可能与连接的附近其他房屋的面积相似,我们可以用邻近房屋的中值来填充缺失值。
#Group by neighborhood and fill in missing value by the median LotFrontage of all the neighborhood
all_data["LotFrontage"] = all_data.groupby("Neighborhood")["LotFrontage"].transform(
lambda x: x.fillna(x.median()))
(7)GarageType, GarageFinish, GarageQual and GarageCond:车库位置,车库内部完成度,车库质量和车库情况。NA表示没有车库。
for col in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'):
all_data[col] = all_data[col].fillna('None')
(8)GarageYrBlt, GarageArea and GarageCars:车库建成年份,车库面积,车库车位数量。用0来代替缺失值,因为没有车库就等于没有车位。
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
all_data[col] = all_data[col].fillna(0)
(9)BsmtFinSF1, BsmtFinSF2, BsmtUnfSF, TotalBsmtSF, BsmtFullBath and BsmtHalfBath:地下室完工面积,地下室完工等级2的面积,未完工地下室面积, 地下室全套浴室,地下室半套浴室。缺失值用0表示没有地下室。
for col in ('BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath'):
all_data[col] = all_data[col].fillna(0)
(10)BsmtQual, BsmtCond, BsmtExposure, BsmtFinType1 and BsmtFinType2:地下室高度,地下室总体情况,地下室裸露情况,地下室完工面积等级, 地下室完工面积等级(如果有多种类型)。NaN表示没有地下室。
for col in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
all_data[col] = all_data[col].fillna('None')
(11)MasVnrArea and MasVnrType : 砖石饰面面积和砖石饰面类型。NA表示没有砖石饰面。
all_data["MasVnrType"] = all_data["MasVnrType"].fillna("None")
all_data["MasVnrArea"] = all_data["MasVnrArea"].fillna(0)
(12)MSZoning (The general zoning classification):房屋销售分类。RL(低密度住宅)是最常见的值,所以可以用来代替缺失值。
all_data['MSZoning'] = all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0])
注:mode()获取数组中的众数。
(13)Utilities:设施类型。除了一个NoSeWa和2个NA其它都是AllPub。由于NoSewa是在训练集中,对预测模型没有帮助。所以直接把这个变量删除。
all_data = all_data.drop(['Utilities'], axis=1)
(14)Functional : 家庭功能(假设是典型的),NA代表典型的。
all_data["Functional"] = all_data["Functional"].fillna("Typ")
(15)Electrical:电力系统。有一个NA值,因为这个变量大多数值为SBrkr,可以把缺失值设为这个。
all_data['Electrical'] = all_data['Electrical'].fillna(all_data['Electrical'].mode()[0])
(16)KitchenQual:厨房质量。只有一个NA值,处理方法和Electrical一样。
all_data['KitchenQual'] = all_data['KitchenQual'].fillna(all_data['KitchenQual'].mode()[0])
(17)Exterior1st and Exterior2nd:房屋外部遮盖物。也只有一个缺失值,所以也是上述的处理方法。
all_data['Exterior1st'] = all_data['Exterior1st'].fillna(all_data['Exterior1st'].mode()[0])
all_data['Exterior2nd'] = all_data['Exterior2nd'].fillna(all_data['Exterior2nd'].mode()[0])
(18)SaleType:销售类型。一样的处理方法。
all_data['SaleType'] = all_data['SaleType'].fillna(all_data['SaleType'].mode()[0])
(19)MSSubClass:建筑物类型。NA表示没有建筑物类型,用None表示。
all_data['MSSubClass'] = all_data['MSSubClass'].fillna("None")
现在来看看还有缺失值吗?
#Check remaining missing values if any
all_data_na = (all_data.isnull().sum() / len(all_data)) * 100
all_data_na = all_data_na.drop(all_data_na[all_data_na == 0].index).sort_values(ascending=False)
missing_data = pd.DataFrame({'Missing Ratio' :all_data_na})
missing_data.head()
![]()
只有这个,说明没有缺失值了。
数字变量转为分类变量
#MSSubClass=The building class
all_data['MSSubClass'] = all_data['MSSubClass'].apply(str)
#Changing OverallCond into a categorical variable
all_data['OverallCond'] = all_data['OverallCond'].astype(str)
#Year and month sold are transformed into categorical features.
all_data['YrSold'] = all_data['YrSold'].astype(str)
all_data['MoSold'] = all_data['MoSold'].astype(str)
对某些分类变量进行标签编码,可能包含信息
from sklearn.preprocessing import LabelEncoder
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
#process columns, apply LabelEncoder to categorical features
for c in cols:
lbl = LabelEncoder()
lbl.fit(list(all_data[c].values))
all_data[c] = lbl.transform(list(all_data[c].values))
#shape
print('Shape all_data: {}'.format(all_data.shape))
Shape all_data: (2917, 78)
增加一个更重要的特征
面积和房价有很重要的关系,因此我们增加一个特征来代表地下室,一二层楼的总面积。
#Adding total sqfootage feature
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF']
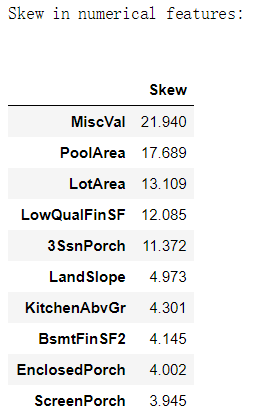
偏的特征
查看前10个变量的偏度:
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
#Check the skew of all numerical features
skewed_feats = all_data[numeric_feats].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
print("\nSkew in numerical features: \n")
skewness = pd.DataFrame({'Skew' :skewed_feats})
skewness.head(10)
高偏度特征的Box Cox变换
对偏度的绝对值大于0.75的变量进行Box Cox变换。设置λ=0,boxcox1p。
skewness = skewness[abs(skewness) > 0.75]
print("There are {} skewed numerical features to Box Cox transform".format(skewness.shape[0]))
from scipy.special import boxcox1p
skewed_features = skewness.index
lam = 0.15
for feat in skewed_features:
#all_data[feat] += 1
all_data[feat] = boxcox1p(all_data[feat], lam)
#all_data[skewed_features] = np.log1p(all_data[skewed_features])
There are 59 skewed numerical features to Box Cox transform
获得虚拟分类特征
all_data = pd.get_dummies(all_data)
print(all_data.shape)
(2917, 220)
获得新的训练集和测试集:
train = all_data[:ntrain]
test = all_data[ntrain:]
3、建立模型
首先导入各种库:
from sklearn.linear_model import ElasticNet, Lasso, BayesianRidge, LassoLarsIC
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.kernel_ridge import KernelRidge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone
from sklearn.model_selection import KFold, cross_val_score, train_test_split
from sklearn.metrics import mean_squared_error
import xgboost as xgb
import lightgbm as lgb
定义交叉验证方法:
#Validation function
n_folds = 5
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values)
rmse= np.sqrt(-cross_val_score(model, train.values, y_train, scoring="neg_mean_squared_error", cv = kf))
return(rmse)
注:在交叉验证中,第一个参数n_splits表示将数据集分成几份,每次用其中一个子集当作验证集,剩下的n_splits-1个作为训练集,进行n_splits次训练和测试,得到n_splits个结果。shuffle指是否对数据洗牌,random_state为随机种子。get_n_splits函数就是获取n_splits值。
基本模型
(1)LASSO 回归:这个模型对离群值很敏感,所以需要使它们更具有鲁棒性,可以在pipeline中使用sklearn中Robustscaler() 函数。
lasso = make_pipeline(RobustScaler(), Lasso(alpha =0.0005, random_state=1))
注:pipeline的目的就是当设置不同的参数时组合几个可以一起交叉验证的步骤。make_pipeline函数是Pipeline类的简单实现,只需传入每个step的类实例即可。 Lasso的最优目标函数是:

(2)弹性网络回归:
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.9, random_state=3))
注:l1_ratio表示L1-norm和L2-norm的比例,取值范围是0到1的浮点数。ElasticNet是Lasso和Ridge Regression技术的混合体。 它使用L1和L2正则化来考虑两种技术的影响。
(3)KRR,核脊回归:
KRR = KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5)
(4)梯度提升回归,GBR:
GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state =5)
(5)XGBoost,极端梯度提升:
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = -1)
(6)LightGBM
model_lgb = lgb.LGBMRegressor(objective='regression',num_leaves=5,
learning_rate=0.05, n_estimators=720,
max_bin = 55, bagging_fraction = 0.8,
bagging_freq = 5, feature_fraction = 0.2319,
feature_fraction_seed=9, bagging_seed=9,
min_data_in_leaf =6, min_sum_hessian_in_leaf = 11)
各个模型得分
通过计算交叉验证rmsle误差来看这些模型的能力,输出平均值和标准差:
(1)lasso:
score = rmsle_cv(lasso)
print("\nLasso score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
Lasso score: 0.1128 (0.0069)
(2)Elastic Net Regression:
score = rmsle_cv(ENet)
print("ElasticNet score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
ElasticNet score: 0.1129 (0.0070)
(3)Kernel Ridge Regression:
score = rmsle_cv(KRR)
print("Kernel Ridge score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
Kernel Ridge score: 0.8589 (0.2879)
(4)GBoost:
score = rmsle_cv(GBoost)
print("Gradient Boosting score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
Gradient Boosting score: 0.1177 (0.0079)
(5)Xgboost:
score = rmsle_cv(model_xgb)
print("Xgboost score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
Xgboost score: 0.1153 (0.0068)
(6)LightGBM :
score = rmsle_cv(model_lgb)
print("LGBM score: {:.4f} ({:.4f})\n" .format(score.mean(), score.std()))
LGBM score: 0.1143 (0.0068)
4、堆叠模型
最简单的堆叠方法:平均基本模型。我们构建了一个新的类来扩展我们的模型中的scikit-learn,还可以扩展封装和代码重用。
平均的基本模型类别:
class AveragingModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, models):
self.models = models
#we define clones of the original models to fit the data in
def fit(self, X, y):
self.models_ = [clone(x) for x in self.models]
#Train cloned base models
for model in self.models_:
model.fit(X, y)
return self
#Now we do the predictions for cloned models and average them
def predict(self, X):
predictions = np.column_stack([
model.predict(X) for model in self.models_
])
return np.mean(predictions, axis=1)
我们平均了四个模型:ENet, GBoost, KRR and lasso。
averaged_models = AveragingModels(models = (ENet, GBoost, KRR, lasso))
score = rmsle_cv(averaged_models)
print(" Averaged base models score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
Averaged base models score: 0.1091 (0.0075)
另外一种方法:增加一个元模型
即在平均基本模型中,增加一个元模型,并使用折迭预测。训练部分的处理有以下四个部分:
(1)将总训练集拆分为两个不相交集(这里是train和.holdout)
(2)在第一部分(train)中训练多个基本模型
(3)在第二部分测试这些基本模型
(4)使用3中的预测作为输入,正确的反应(目标变量)作为训练更高层次学习者的输出,称为元模型。
前三个步骤是迭代完成的,如果我们以5倍叠加为例,我们首先将训练数据拆分为5份。然后我们将进行5次迭代。在每次迭代中,我们将每个基础模型训练在4份上,并对剩余一份进行预测。所以我们能确定,在5次迭代后,整个数据用于得到折叠预测,然后我们将在步骤4中使用这些预测作为新特性来训练我们的元模型。在预测部分,我们平均了在测试集上所有模型的预测,并作为元模型的特征。这些特征是作为元模型上最后的预测。
class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model, n_folds=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_folds = n_folds
#We again fit the data on clones of the original models
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models]
self.meta_model_ = clone(self.meta_model)
kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156)
#Train cloned base models then create out-of-fold predictions
#that are needed to train the cloned meta-model
out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, holdout_index in kfold.split(X, y):
instance = clone(model)
self.base_models_[i].append(instance)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[holdout_index])
out_of_fold_predictions[holdout_index, i] = y_pred
#Now train the cloned meta-model using the out-of-fold predictions as new feature
self.meta_model_.fit(out_of_fold_predictions, y)
return self
#Do the predictions of all base models on the test data and use the averaged predictions as
#meta-features for the final prediction which is done by the meta-model
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X) for model in base_models]).mean(axis=1)
for base_models in self.base_models_ ])
return self.meta_model_.predict(meta_features)
为了使这两个方法能比较,我们只平均了 Enet KRR和Gboost,然后增加lasso为元模型:
stacked_averaged_models = StackingAveragedModels(base_models = (ENet, GBoost, KRR),
meta_model = lasso)
score = rmsle_cv(stacked_averaged_models)
print("Stacking Averaged models score: {:.4f} ({:.4f})".format(score.mean(), score.std()))
Stacking Averaged models score: 0.1089 (0.0070)
模型融合
我们添加XGBoost和LightGBM到之前定义好的堆叠模型。
首先定义一个 rmsle估计函数:
def rmsle(y, y_pred):
return np.sqrt(mean_squared_error(y, y_pred))
堆叠回归器:
stacked_averaged_models.fit(train.values, y_train)
stacked_train_pred = stacked_averaged_models.predict(train.values)
stacked_pred = np.expm1(stacked_averaged_models.predict(test.values))
print(rmsle(y_train, stacked_train_pred))
0.07677076839772774
XGBoost:
model_xgb.fit(train, y_train)
xgb_train_pred = model_xgb.predict(train)
xgb_pred = np.expm1(model_xgb.predict(test))
print(rmsle(y_train, xgb_train_pred))
0.07908047957366829
LightGBM:
model_lgb.fit(train, y_train)
lgb_train_pred = model_lgb.predict(train)
lgb_pred = np.expm1(model_lgb.predict(test.values))
print(rmsle(y_train, lgb_train_pred))
0.07330664831275281
'''RMSE on the entire Train data when averaging'''
print('RMSLE score on train data:')
print(rmsle(y_train,stacked_train_pred*0.70 +
xgb_train_pred*0.15 + lgb_train_pred*0.15 ))
RMSLE score on train data:
0.07458741510040136
集成预测:
ensemble = stacked_pred*0.70 + xgb_pred*0.15 + lgb_pred*0.15
生成提交文件:
sub = pd.DataFrame()
sub['Id'] = test_ID
sub['SalePrice'] = ensemble
sub.to_csv('submission.csv',index=False)
最后提交后,排名650多。再接再厉。。。。。