ACL 2019论文分享: 让机器有自主意识地和人类对话
ACL 2019 收录论文分享:《Proactive Human-Machine Coversation with Explicit Conversation Goals》。

一、动机
(对人机对话技术不是很了解的读者,建议先阅读此前的一篇公众号内容“一文看懂人机对话”)
人机对话是人工智能的一项基本挑战,涉及语言理解、对话控制和语言生成等关键技术,受到了学术界和工业界的广泛关注。但目前的人机对话普遍存在以下问题:
-
机器大多是被动对话形式,即机器的回复是用于响应用户的输入,无法像人一样进行充分的信息交互
-
机器的对话漫无目的,缺乏像人一样的自主意识
因此,我们提出了主动对话任务:
-
给机器设定对话目标
-
让机器根据给定的知识图谱信息主动引领对话进程,完成对话目标
-
达到信息充分交互,实现机器具备自主意识的目的
二、主动对话任务设置
我们给机器设置的对话目标是从当前话题跳转到目标话题上,由于目标话题和当前话题存在相关和不相关两种情况,因此我们在对话目标设定上同时考虑这两种情况,如图1左下所示,首先让机器从当前话题(Start)跳转到任意目标话题A(红海行动),然后进一步跳转到和话题A相关的另一目标话题B(林超贤)上。
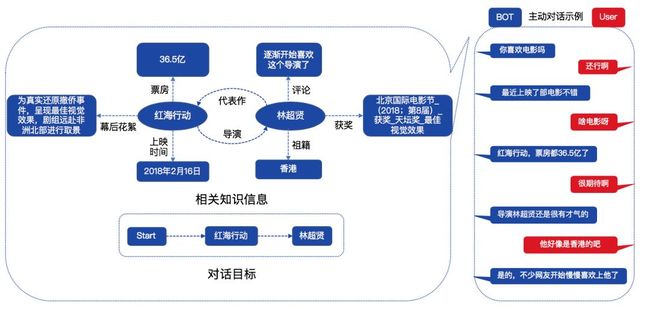
图1 主动对话示例
如图1左上部分所示,给机器提供的知识图谱信息是目标话题A和B相关的子图信息。图1右侧为主动对话示例,机器主动发起对话,根据知识图谱信息主动引领对话进程,自然流畅的实现话题的迁移目标。
三、数据集建设
目前已有的对话数据集不适用于我们提出的主动对话任务,因此我们通过人工标注方式在电影和娱乐人物领域建设了一个新的对话数据集(DuConv),用于主动对话技术的研究。整个数据集建设经过了知识挖掘、图谱建设、对话目标设定和语料众包标注四个阶段。
1、知识挖掘
我们在时光网(www.mtime.com)上挖掘了电影和娱乐人物相关的结构化和非结构化知识信息,如电影的票房、导演、评论,相关人物的祖籍、代表作和评论等。我们根据网上挖掘的这些静态知识进一步计算出动态知识以丰富知识内容,比如根据票房信息计算出电影之间的票房排行,根据评分信息离散化得到电影或人物的口碑信息等。经过数据清洗后总共得到约14万实体360万条知识的数据,每条知识以三元组<实体,属性,值>的形式组织,经过抽样评估,我们挖掘的知识准确率为97%。
2、图谱建设
类似于传统的图谱建设,我们以挖据的三元组知识中的实体和值为节点,属性为边建立一阶图谱关系,除此之外,我们对有相同属性和值的两个实体建立二阶关系,如“红海行动”和“湄公河行动”的导演都是林超贤,这两个实体则存在二阶关联关系。
3、对话目标设定
如图1所示,每组对话都有对话目标和关联的知识信息,我们从图谱中提取任意两个关联的实体作为对话目标中的目标话题A和B,包括一阶关系和二阶关系的关联实体。然后进一步提取关联实体所在的知识子图作为目标话题A和B的附加知识信息。
4、语料众包标注
不同于self-play一人扮演对话双方的标注方式,我们在众包平台test.baidu.com上随机挑选两个标注人员模拟真实对话的双方标注出每组对话数据。为保证至少有两个标注人员同时进入对话标注任务,我们安排多个外包团队进入标注平台开展对话标注。标注时,每组对话随机挑选两个标注人员标注,其中之一扮演机器角色根据提供的知识子图信息主动引领对话进程完成设定的对话目标,另一个标注人员扮演真实用户角色响应机器角色的对话即可。由此共标注了约3万组含有27万对话句子的语料,详细统计信息如下:
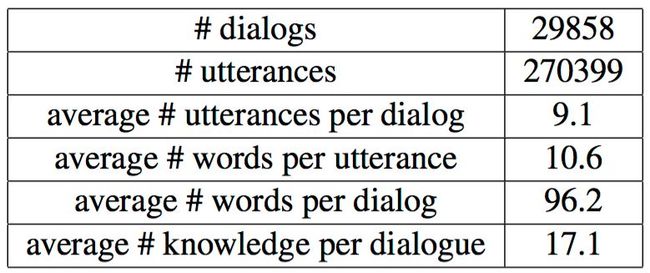
图2 标注语料统计
四、基线模型建设
目前人机对话任务主要有检索和生成两种主流的技术方向,我们在这两个方向上都建立了主动对话的基线模型。
1、检索模型
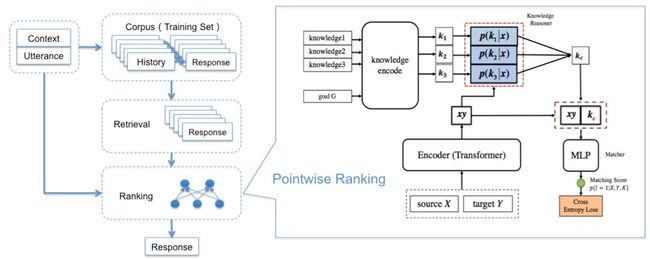
图3 检索模型
检索模型借鉴信息检索的方法从对话语料库中检索候选回复,然后使用排序模型对候选回复进行排序,再选取高相关性的回复进行输出,如图3左侧所示。
我们的候选回复是从训练集中相同对话目标类型(如“Start”->[Movie]->[Person], “Start”->[Movie]->[Movie]等)相同轮次的机器回复中随机选取的,并对候选回复中的知识根据属性名称替换成当前对话的相应知识,减少知识冲突现象。
排序阶段,使用二分类方法判断每个候选回复Y属于正确回复的概率,如图3右侧所示,首先将候选回复Y和对话历史X(包括当前轮的用户输入)使用分隔符拼接成一串字符序列,然后使用Transformer方法进行编码表示,再联合attention方法选取的相关知识信息通过softmax层进行二分类判断。为了简便,该方法中将对话目标Goal作为知识信息的一部分使用。
2、生成模型
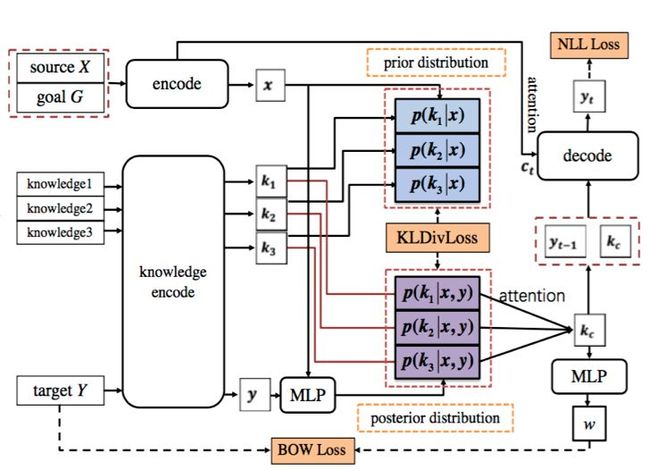
图4 后验生成模型
生成模型借鉴最早用于机器翻译的Seq2Seq模型,将输入的对话历史X使用encoder编码表示,然后使用decoder逐步解码出回复的每个字符。如图4所示,我们在Seq2Seq框架基础上使用Memory Network方法表示知识信息,通过attention方式选择输出回复需要使用的知识信息,并引入decoder中。我们发现:通过输出回复的loss信息再经decoder的长距离梯度回传很难有效指导模型进行知识选择。
因此我们提出了一种新的解决方法(使用该方法的模型称为后验生成模型):
在训练阶段使用标准回复Y中的后验知识信息指导模型进行先验知识选择,即让先验知识分布p(ki|x)拟合后验知识分布p(ki|x,y),训练时将这两个分布向量的KL散度作为Loss的一部分。KL散度计算方法如下:
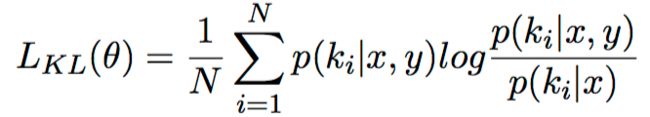
为避免在计算后验知识分布时存在严重信息损失,借鉴自编码的思想,训练阶段让标准回复计算的后验知识分布能解码出标准回复本身,即用后验分布预测标准回复的每个词,预测结果的BOW Loss也作为整体Loss的一部分,BOW Loss计算如下:
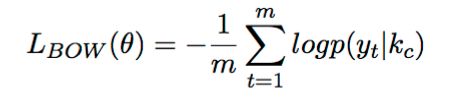
该方法中对话目标Goal作为输入信息的一部分共同参与知识信息的选择和回复的解码。
五、实验及结果
实验中使用的模型除了上文介绍的检索模型(retrieval)和后验生成模型(generation)外,增加了Seq2Seq模型进行对比,该模型只有encoder和decoder,语料中的对话历史、知识信息和对话目标拼接成一个字符串作为模型的输入。
我们使用百度的深度学习平台飞桨(PaddlePaddle)实现所有的基线模型,每个模型都使用预训练的word2vec词表进行热启动,词表大小为3万,隐层维度为300,训练阶段使用Adam方式对模型进行优化,生成模型中使用大小为10的beamsize进行解码。
由于对话的开放性,对话效果的自动评估仍然是一个难题,因此我们在自动评估的基础上进一步使用人工评估的方式来衡量对话的效果。
1、自动评估
由于无法自动生成用户的回复,因此自动评估只能进行单轮评估,即给定对话历史(包括当前用户输入)时,评估系统输出的机器回复。评估指标上既有检索相关的指标Hits@k又有生成相关的PPL、F1、BLEU和DISTINCT指标,同时使用准确召回指标衡量回复中的知识使用情况。评估估结果如下:
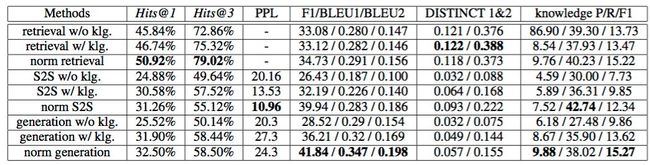
图5 自动评估结果
结论:
(1)为了观察知识的作用,每个模型都做了引入知识(w/)和不引入知识(w/o)的对比,从实验结果中可以看出引入知识能有效提升系统的效果,尤其是生成模型。
(2)由于知识本身具有稀疏性,尤其是知识中的实体名称,因此我们进一步对知识进行了归一化处理(normalization,简写成norm),将语料中的实体名称槽位化,回复输出前再将槽位替换为相应的实体名称,从实验结果可以看到三个模型做了知识归一化处理后可以有效提升模型的泛化能力,效果提升非常显著。
(3)从表中还可以看到后验生成模型要显著优于Seq2Seq模型,可见后验信息能够有效指导模型进行知识选择。
(4)通过自动评估指标很难判断检索模型和生成模型的优劣,检索模型在检索指标上Hits@k要显著优于生成模型,而生成模型在生成指标F1/BLEU上要显著优于检索模型,推测这和两种模型各自的优化指标有关。知识使用上两种模型无显著区别。
2、人工评估
我们进一步对自动评估中效果最好的三个norm模型进行人工评估,分别从单轮或多轮两个层级进行评估。多轮评估时使用类似于数据标注的方法先生成多轮评估数据,不同的是将数据标注时扮演机器角色的标注专员替换成候选模型。每个模型生成100组评估数据,然后使用三个评估专员共同评估。多轮评估指标有Goal完成度和多轮一致性coherence两个维度。Goal完成度有三档,评估标准如下:
(1)0档,表示Goal未完成,即没有按Goal设定完成话题迁移目标。
(2)1档,表示Goal完成,但没有充分利用知识信息,整个多轮对话中使用的知识信息少于3条。
(3)2档,表示Goal完成,而且充分利用知识信息,整个多轮对话中使用的知识信息大于等于3条。
Coherence是根据多轮对话中每个机器回复是否存在句内流畅性和句间一致性问题统计的,每个句内问题记0.5分,每个句间问题记1分,然后根据整体计分将coherence划分为四档:>2分表示存在大量的问题,为0档;[1.5, 2]为1档;[0.5, 1]为2档;0分表示没有任何问题,标记为第3档。多轮的评估结果如图6:

图6 多轮评估结果
结论:
(1)从人工评估指标可以看出生成模型要优于检索模型,结合图7的case可以发现,这主要是由于检索模型检索出的回复虽然经过了归一化处理,但仍然存在残余知识信息与当前对话中的知识信息冲突的情况。
(2)单轮指标上Seq2Seq模型在流畅性(fluency)和上下文一致性(coherence)要优于后验生成模型,但是在信息丰富度上(informativeness)要远远差于后验生成模型,这与Seq2Seq的安全回复问题有关,从图7中的case可以发现Seq2Seq倾向于安全的不含知识信息的回复,因此在衡量是否能主动提及新知识的主动性(proactivity)指标上也略逊于后验生成模型。
(3)多轮指标上后验生成模型在Goal完成度上明显好于Seq2Seq模型,因为后验生成模型能更加充分利用知识信息完成Goal设定的话题转移,而且能保持句子的流畅性和上下文一致性(coherence)。从Goal完成度和coherence目前的效果可以看出主动对话模型还有很大的提升空间。
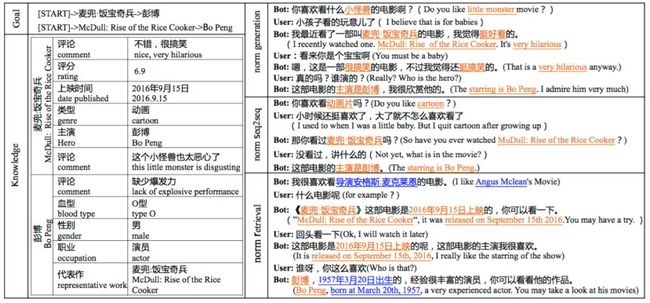
图7 不同模型生成的主动人机对话示例
六、开源
我们建设的数据集DuConv以及相应的基线系统已经在PaddleNLP开源:
(1) 数据集:
http://ai.baidu.com/broad/subordinate?dataset=dureader
(2)基线系统:
https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/Research/ACL2019-DuConv
PaddleNLP(nlp.baidu.com/homepage/nlptools/)是基于飞桨(PaddlePaddle)深度学习框架打造的领先、全面、易用的NLP开源工具集与预训练模型集。PaddleNLP开源内容覆盖了工业应用和学术研究;为开发者提供了多种业内效果领先的NLP应⽤任务模型和前沿的论文、代码、数据,让开发者能以超低门槛获取多种顶尖NLP能力;为研究者提供百度NLP前沿研究成果的代码与数据等,让研究者们可以快速复现实验,并据此开展新的研究。
PaddleNLP-研究版:开源了NLP领域最新研究成果的代码及数据,包括领域权威会议ACL、NAACL、IJCAI等,权威竞赛MRQA、SemEval等,可以帮助研究者快速了解百度NLP的前瞻研究成果,并在此基础上开展研究。
七、竞赛
为了鼓励更多的研究人员参与主动人机对话技术的研究,我们使用建设的数据集DuConv在中国计算机学会、中国中文信息学会和百度公司联合举办的“2019语言与智能技术竞赛”上设立了知识驱动对话竞赛任务,目前竞赛已经结束,共收到了1536支队伍报名,其中有178支队伍提交了结果。竞赛分为三阶段:
第一阶段通过自动评估指标在小测试集上自由打榜进行模型优化,历时一个半月;
第二阶段通过自动评估指标在最终测试集上正式打榜进行效果排名,历时一周;
第三阶段通过人工评估方法对上阶段Top10队伍的模型进行多轮评估确立获奖名单,多轮评估的方法和指标同上文介绍的Goal完成度和Coherence一致,历时一周。
最终的榜单如图8所示,效果最好的模型相比于基线系统相对提升了37%。详细信息参见比赛官网:http://lic2019.ccf.org.cn/talk
为了供研究人员持续打榜,我们在数据集开放页面上也设置了榜单:
https://ai.baidu.com/broad/leaderboard?dataset=duconv
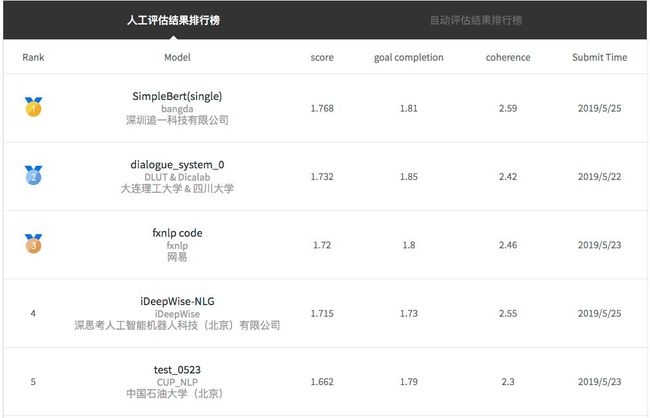
图8 知识驱动对话竞赛Top 5
八、总结
我们针对目前人机对话中普遍存在的无意识被动对话问题,提出了主动对话任务,给机器设定了对话目标,让机器根据提供的知识图谱信息主动引领对话进程完成对话目标,使机器具备有自主意识的对话能力。为此我们建设了一个有3万组对话27万个句子的对话语料DuConv以及两个主动对话基线模型,并已经开放数据集、开源基线模型。同时为鼓励更多研究人员参与主动对话技术的研究,使用DuConv数据集开展了一届对话竞赛任务,影响广泛,效果提升也明显。目前的主动对话技术还有很大的提升空间,期待更多的研究人员共同参与研究。
至此,《Proactive Human-Machine Coversation with Explicit Conversation Goals》论文的分享到此结束,敬请期待2019百度被ACL收录的其他论文。
最后给大家推荐一个GPU福利 - Tesla V100免费算力!配合PaddleHub能让模型原地起飞~ 扫码下方二维码申请~

