Java超级大火锅
实习换语言到Java,基础很多需要整理,专门为Java开一个大火锅~~
1、事务
事务指的是逻辑上的一组操作,这组操作要么全部成功,要么全部失败。
事务的4大特性:
ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
详见:http://blog.csdn.net/scythe666/article/details/51790655
2、悲观锁和乐观锁
秒懂乐观锁和悲观锁
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。
原文:http://blog.csdn.net/hongchangfirst/article/details/26004335
3、非阻塞同步算法与CAS(Compare and Swap)无锁算法
要实现无锁(lock-free)的非阻塞算法有多种实现方法,其中CAS(比较与交换,Compare and swap)是一种有名的无锁算法。CAS, CPU指令,在大多数处理器架构,包括IA32、Space中采用的都是CAS指令。
CAS的语义是“我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉V的值实际为多少”,CAS是项乐观锁技术。
当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。CAS无锁算法的C实现如下:
int compare_and_swap (int* reg, int oldval, int newval)
{
ATOMIC();
int old_reg_val = *reg;
if (old_reg_val == oldval)
*reg = newval;
END_ATOMIC();
return old_reg_val;
}CAS比较与交换的伪代码可以表示为:
do{
备份旧数据;
基于旧数据构造新数据;
}while(!CAS( 内存地址,备份的旧数据,新数据 )) 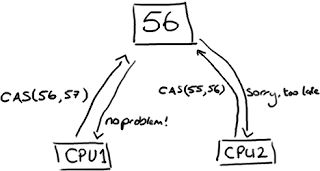
(上图的解释:CPU去更新一个值,但如果想改的值不再是原来的值,操作就失败,因为很明显,有其它操作先改变了这个值。)
就是指当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。容易看出 CAS 操作是基于共享数据不会被修改的假设,采用了类似于数据库的 commit-retry 的模式。当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。
详见:http://www.cnblogs.com/Mainz/p/3546347.html?utm_source=tuicool&utm_medium=referral
4、JVM内存模型
JVM内存模型分区见下图:
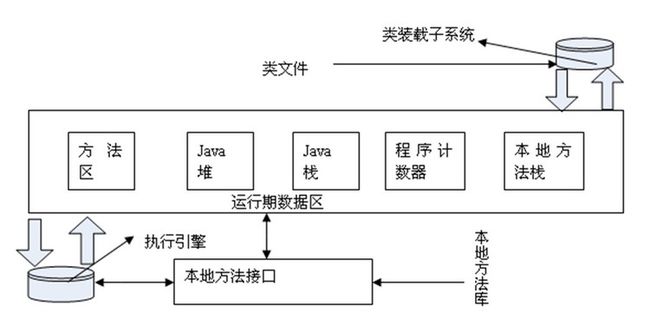
(1)方法区:用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。对于习惯在HotSpot 虚拟机上开发和部署程序的开发者来说,很多人愿意把方法区称为“永久代”(Permanent Generation),本质上两者并不等价。
(2)堆区:Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。由于逃逸分析等分析或优化技术,所有的对象都分配在堆上也渐渐变得不是那么“绝对”了。
Java 堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC 堆”
(3)栈区:与程序计数器一样,Java 虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,它的生命周期与线程相同。栈中主要存放一些基本类型的变量(,int, short, long, byte, float,double, boolean, char)和对象句柄。
(4)程序计数器:程序计数器(Program Counter Register)是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。
由于Java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
(5)本地方法栈:本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java 方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native 方法服务。
详见:http://blog.csdn.net/scythe666/article/details/51700142
5、Java反射机制
一般在开发针对java语言相关的开发工具和框架时使用,比如根据某个类的函数名字,然后执行函数,实现类的动态调用!
java反射就是获取动态对象,并获取其中的属性、方法。不仅可以动态的获取对象,也能动态的创建对象,同时能够访问对象的方法,修改对象的属性值。反射有这样一些常用的用处。
a)反射方式调用方法 动态代理 扩展API,例如sping ioc中的依赖注入。
b)反射可以操作某个类的私有变量和方法
c)反射操作对象更加灵活,例如如上述的例子中只要有了form对象和 property名字就可以利用反射给property赋值和取值 对这类操作 一个方法就可以搞定。
d)运行过程中对未知类进行初始化。
http://blog.csdn.net/scythe666/article/details/51838828
反射实例:
public class test {
private static void testRefect() {
try {
//返回类中的任何可见性的属性(不包括基类)
System.out.println("Declared fileds: ");
Field[] fields = Dog.class.getDeclaredFields();
for (int i = 0; i < fields.length; i++) {
System.out.println(fields[i].getName());
}
//获得类中指定的public属性(包括基类)
System.out.println("public fields: ");
fields = Dog.class.getFields();
for (int i = 0; i < fields.length; i++) {
System.out.println(fields[i].getName());
}
//getMethod()只能调用共有方法,不能反射调用私有方法
Dog dog = new Dog();
dog.setAge(1);
Method method1 = dog.getClass().getMethod("getAge", null);
Object value = method1.invoke(dog);
System.out.println("age: " + value);
//调用基类的private类型方法
/**先实例化一个Animal的对象 */
Animal animal = new Animal();
Class a = animal.getClass();
//Animal中getHeight方法是私有方法,只能使用getDeclaredMethod
Method method2 = a.getDeclaredMethod("getHeight", null);
method2.setAccessible(true);
//java反射无法传入基本类型变量,可以通过如下形式
int param = 12;
Class[] argsClass = new Class[] { int.class };
//Animal中getHeight方法是共有方法,可以使用getMethod
Method method3 = a.getMethod("setHeight", argsClass);
method3.invoke(animal, param);
//Animal中height变量如果声明为static变量,这样在重新实例化一个Animal对象后调用getHeight(),还可以读到height的值
int height = (Integer) method2.invoke(animal);
System.out.println("height: " + height);
/**不用先实例化一个Animal,直接通过反射来获得animal的class对象*/
Class anotherAnimal = Class.forName("test.Animal");
//Animal中getHeight方法是私有方法,只能使用getDeclaredMethod
Method method4 = anotherAnimal.getDeclaredMethod("getHeight", null);
method4.setAccessible(true);
//java反射无法传入基本类型变量,可以通过如下形式
int param2 = 15;
Class[] argsClass2 = new Class[] { int.class };
//Animal中setHeight方法是共有方法,可以使用getMethod
Method method5 = anotherAnimal.getMethod("setHeight", argsClass2);
method5.invoke(anotherAnimal.newInstance(), param2);
//Animal中height变量必须声明为static变量,这样在重新实例化一个Animal对象后调用getHeight()才能读到height的值
// 否则重新实例化一个新的Animal对象,读到的值为初始值
int height2 = (Integer) method4.invoke(anotherAnimal.newInstance());
System.out.println("height:" + height2);
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
}
}
}详见:http://blog.csdn.net/scythe666/article/details/51704809
6、类加载机制
深度好文:http://www.ibm.com/developerworks/cn/java/j-lo-classloader/index.html
类加载器负责加载 Java 类的字节代码到 Java 虚拟机中。

类名.class是什么用法
反射相关知识,类名.class是获得这个类所对应的Class实例
从面向对象的角度上来看,一个类也是对象,它们是类这个类的对象,听起来有些抽象,但是在java中的实现就是所有的加载进来的类在虚拟机中都是一个java.lang.Class类的对象,而“类名.class”就是获得这个类的对象(在同一个ClassLoader中,类对象都是单例的)
当虚拟机载入某个class文件时,首先生成该class文件对应的类的Class对象,用这个对象描述类
http://www.tuicool.com/articles/ZvEvye
7、Reactor和Proactor模式

Reactor读取操作:
(1)应用程序注册读就绪事件和相关联的事件处理器
(2)事件分离器等待事件的发生
(3)当发生读就绪事件的时候,事件分离器调用第一步注册的事件处理器
(4)事件处理器首先执行实际的读取操作,然后根据读取到的内容进行进一步的处理
写入操作类似于读取操作,只不过第一步注册的是写就绪事件。
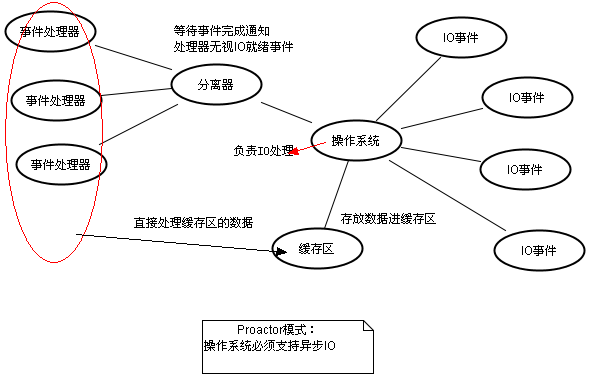
Proactor读取操作:
(1)应用程序初始化一个异步读取操作,然后注册相应的事件处理器,此时事件处理器不关注读取就绪事件,而是关注读取完成事件,这是区别于Reactor的关键。
(2)事件分离器等待读取操作完成事件
(3)在事件分离器等待读取操作完成的时候,操作系统调用内核线程完成读取操作(异步IO都是操作系统负责将数据读写到应用传递进来的缓冲区供应用程序操作,操作系统扮演了重要角色),并将读取的内容放入用户传递过来的缓存区中。这也是区别于Reactor的一点,Proactor中,应用程序需要传递缓存区。
(4)事件分离器捕获到读取完成事件后,激活应用程序注册的事件处理器,事件处理器直接从缓存区读取数据,而不需要进行实际的读取操作。
Proactor中写入操作和读取操作,只不过感兴趣的事件是写入完成事件。
从上面可以看出,Reactor和Proactor模式的主要区别就是真正的读取和写入操作是有谁来完成的:
(1)Reactor中需要应用程序自己读取或者写入数据
(2)而Proactor模式中,应用程序不需要进行实际的读写过程,它只需要从缓存区读取或者写入即可,操作系统会读取缓存区或者写入缓存区到真正的IO设备。
综上所述,同步和异步是相对于应用和内核的交互方式而言的,同步 需要主动去询问,而异步的时候内核在IO事件发生的时候通知应用程序,而阻塞和非阻塞仅仅是系统在调用系统调用的时候函数的实现方式而已。
详见:
http://blog.csdn.net/sshhbb/article/details/6331954
http://blog.csdn.net/scythe666/article/details/51811565
8、长连接 短连接
详情见:http://blog.chinaunix.net/uid-354915-id-3587924.html
(1)长连接就是Client和Server连接建立以后,不断开,直接进行报文的发送和接收。常用于点对点通讯
(2)短连接是每进行一次报文收发交易,才进行通讯连接。交易完毕后立即断开连接。此种方式常用于一点对多点通讯,比如多个Client连接一个Server。
9、线程池
在Executors类里面提供了一些静态工厂,生成一些常用的线程池。
(1)newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
MyThread.java
package threadpool;
/**
* Created by hupo.wh on 2016/7/2.
*/
public class WhThread extends Thread{
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "正在执行...");
}
}
TestSingleThreadExecutor.java
package threadpool;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* Created by hupo.wh on 2016/7/3.
*/
public class TestSingleThreadExecutor {
public static void main(String[] args) {
//创建一个可重用固定线程数的线程池
ExecutorService pool = Executors. newSingleThreadExecutor();
//创建实现了Runnable接口对象,Thread对象当然也实现了Runnable接口
Thread t1 = new WhThread();
Thread t2 = new WhThread();
Thread t3 = new WhThread();
Thread t4 = new WhThread();
Thread t5 = new WhThread();
//将线程放入池中进行执行
pool.execute(t1);
pool.execute(t2);
pool.execute(t3);
pool.execute(t4);
pool.execute(t5);
//关闭线程池
pool.shutdown();
}
}
输出结果:
pool-1-thread-1正在执行…
pool-1-thread-1正在执行…
pool-1-thread-1正在执行…
pool-1-thread-1正在执行…
pool-1-thread-1正在执行…
(2)newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
//创建一个可重用固定线程数的线程池
ExecutorService pool = Executors.newFixedThreadPool(2);(3)newCachedThreadPool
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
//创建一个可重用固定线程数的线程池
ExecutorService pool = Executors.newCachedThreadPool();(4)newScheduledThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
package threadpool;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* Created by hupo.wh on 2016/7/3.
*/
public class TestSingleThreadExecutor {
public static void main(String[] args) {
ScheduledThreadPoolExecutor exec = new ScheduledThreadPoolExecutor(1);
exec.scheduleAtFixedRate(new Runnable() {//每隔一段时间就触发异常
@Override
public void run() {
System.out.println("================");
throw new RuntimeException();
}
}, 1000, 5000, TimeUnit.MILLISECONDS);
exec.scheduleAtFixedRate(new Runnable() {//每隔一段时间打印系统时间,证明两者是互不影响的
@Override
public void run() {
System.out.println(System.nanoTime());
}
}, 1000, 2000, TimeUnit.MILLISECONDS);
}
}
ThreadPoolExecutor构造函数
jvm本身提供的concurrent并发包,提供了高性能稳定方便的线程池,可以直接使用。
ThreadPoolExecutor是核心类,都是由它与3种Queue结合衍生出来的。
BlockingQueue + LinkedBlockingQueue + SynchronousQueue
ThreadPoolExecutor的完整构造方法的签名是:
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) . corePoolSize - 池中所保存的线程数,包括空闲线程。
maximumPoolSize-池中允许的最大线程数。
keepAliveTime - 当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
unit - keepAliveTime 参数的时间单位。
workQueue - 执行前用于保持任务的队列。此队列仅保持由 execute方法提交的 Runnable任务。
threadFactory - 执行程序创建新线程时使用的工厂。
handler - 由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序。
ThreadPoolExecutor是Executors类的底层实现。
在JDK帮助文档中,有如此一段话:
“强烈建议程序员使用较为方便的Executors工厂方法Executors.newCachedThreadPool()(无界线程池,可以进行自动线程回收)、Executors.newFixedThreadPool(int)(固定大小线程池)Executors.newSingleThreadExecutor()(单个后台线程)
线程池实现原理
先从 BlockingQueue 这个入参开始说起。在JDK中,其实已经说得很清楚了,一共有三种类型的queue。
所有BlockingQueue 都可用于传输和保持提交的任务。可以使用此队列与池大小进行交互:
(1)如果运行的线程少于 corePoolSize,则 Executor始终首选添加新的线程,而不进行排队。(如果当前运行的线程小于corePoolSize,则任务根本不会存放,添加到queue中,而是直接抄家伙(thread)开始运行)
(2)如果运行的线程等于或多于 corePoolSize,则 Executor始终首选将请求加入队列,而不添加新的线程。
(3)如果无法将请求加入队列,则创建新的线程,除非创建此线程超出maximumPoolSize,在这种情况下,任务将被拒绝。
线程的状态有 new、runnable、running、waiting、timed_waiting、blocked、dead 一旦线程调用了start 方法,线程就转到Runnable 状态,注意,如果线程处于Runnable状态,它也有可能不在运行,这是因为还有优先级和调度问题。
排队策略
排队有三种通用策略:
(1)直接提交。工作队列的默认选项是 SynchronousQueue,ExecutorService newCachedThreadPool():无界线程池,可以进行自动线程回收,所以我们可以发现maximumPoolSize为big big。
(2)无界队列。使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
(3)有界队列。当使用有限的 maximumPoolSizes时,有界队列(如 ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
keepAliveTime
jdk中的解释是:当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
有点拗口,其实这个不难理解,在使用了“池”的应用中,大多都有类似的参数需要配置。比如数据库连接池,DBCP中的maxIdle,minIdle参数。
什么意思?接着上面的解释,后来向老板派来的工人始终是“借来的”,俗话说“有借就有还”,但这里的问题就是什么时候还了,如果借来的工人刚完成一个任务就还回去,后来发现任务还有,那岂不是又要去借?这一来一往,老板肯定头也大死了。
合理的策略:既然借了,那就多借一会儿。直到“某一段”时间后,发现再也用不到这些工人时,便可以还回去了。这里的某一段时间便是keepAliveTime的含义,TimeUnit为keepAliveTime值的度量。
详参:http://www.oschina.net/question/565065_86540
10、接口中的成员变量
用final定义出来的是常量.如public static final double CM=2.54;
如果楼主在接口定义里看到的是类似如上的定义的话,这是一个常量,可以通过接口继承直接取值.
最后,接口中声明的变量会被编译器和解释器自动当作public static final类型,也就是常量.所以在接口里声明的变量都要初始化
11、Java中的序列化与反序列化
详见:http://blog.csdn.net/scythe666/article/details/51718784
12、spring aop实现
spring 的aop 有两种实现方式,一种是使用的原生jdk的动态代理,一种是使用cglib,spring默认使用jdk的动态代理,对于没有接口的类再使用cglib来代理。
13、Java代理
静态代理:由程序员创建或特定工具自动生成源代码,再对其编译。在程序运行前,代理类的.class文件就已经存在了。
动态代理:在程序运行时,运用反射机制动态创建而成。
详见:http://www.cnblogs.com/jqyp/archive/2010/08/20/1805041.html
14、MySQL行级锁、表级锁、页级锁
页级:引擎 BDB。
表级:引擎 MyISAM , 理解为锁住整个表,可以同时读,写不行
行级:引擎 INNODB , 单独的一行记录加锁
表级,直接锁定整张表,在你锁定期间,其它进程无法对该表进行写操作。如果你是写锁,则其它进程则读也不允许
行级,,仅对指定的记录进行加锁,这样其它进程还是可以对同一个表中的其它记录进行操作。
页级,表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
详见:http://www.jb51.net/article/50047.htm
15、Java集合类
详见:http://www.cnblogs.com/xwdreamer/archive/2012/05/30/2526822.html
16、synchronized
详见:http://www.cnblogs.com/devinzhang/archive/2011/12/14/2287675.html
Java Thread.join()详解:
http://www.open-open.com/lib/view/open1371741636171.html
17、jdk1.6 在线中文文档
http://tool.oschina.net/apidocs/apidoc?api=jdk-zh
18、Java管程
管程 (英语:Moniters,也称为监视器) 是一种程序结构,结构内的多个子程序(对象或模块)形成的多个工作线程互斥访问共享资源。
这些共享资源一般是硬件设备或一群变量。管程实现了在一个时间点,最多只有一个线程在执行管程的某个子程序。
与那些通过修改数据结构实现互斥访问的并发程序设计相比,管程实现很大程度上简化了程序设计。
管程提供了一种机制,线程可以临时放弃互斥访问,等待某些条件得到满足后,重新获得执行权恢复它的互斥访问。
一个管程包含:
(1)多个彼此可以交互并共用资源的线程
(2)多个与资源使用有关的变量
(3)一个互斥锁
(4)一个用来避免竞态条件的不变量
详见:http://my.oschina.net/hosee/blog/485285
19、何谓数据库分库分表
1 基本思想之什么是分库分表?
从字面上简单理解,就是把原本存储于一个库的数据分块存储到多个库上,把原本存储于一个表的数据分块存储到多个表上。
2 基本思想之为什么要分库分表?
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
3 分库分表的实施策略。
分库分表有垂直切分和水平切分两种
3.1 何谓垂直切分,即将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数据库workDB、商品数据库payDB、用户数据库userDB、日志数据库logDB等,分别用于存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
3.2 何谓水平切分,当一个表中的数据量过大时,我们可以把该表的数据按照某种规则,例如userID散列,进行划分,然后存储到多个结构相同的表,和不同的库上。例如,我们的userDB中的用户数据表中,每一个表的数据量都很大,就可以把userDB切分为结构相同的多个userDB:part0DB、part1DB等,再将userDB上的用户数据表userTable,切分为很多userTable:userTable0、userTable1等,然后将这些表按照一定的规则存储到多个userDB上。
3.3 应该使用哪一种方式来实施数据库分库分表,这要看数据库中数据量的瓶颈所在,并综合项目的业务类型进行考虑。
如果数据库是因为表太多而造成海量数据,并且项目的各项业务逻辑划分清晰、低耦合,那么规则简单明了、容易实施的垂直切分必是首选。
而如果数据库中的表并不多,但单表的数据量很大、或数据热度很高,这种情况之下就应该选择水平切分,水平切分比垂直切分要复杂一些,它将原本逻辑上属于一体的数据进行了物理分割,除了在分割时要对分割的粒度做好评估,考虑数据平均和负载平均,后期也将对项目人员及应用程序产生额外的数据管理负担。
在现实项目中,往往是这两种情况兼而有之,这就需要做出权衡,甚至既需要垂直切分,又需要水平切分。我们的游戏项目便综合使用了垂直与水平切分,我们首先对数据库进行垂直切分,然后,再针对一部分表,通常是用户数据表,进行水平切分。
4 分库分表存在的问题。
4.1 事务问题。
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
4.2 跨库跨表的join问题。
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
4.3 额外的数据管理负担和数据运算压力。
额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算,例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位,在进行分表之前,只需一个order by语句就可以搞定,但是在进行分表之后,将需要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。
20、oracle sequence
Oracle提供了sequence对象,由系统提供自增长的序列号,通常用于生成数据库数据记录的自增长主键或序号的地方。
Sequence是数据库系统按照一定规则自动增加的数字序列。这个序列一般作为代理主键(因为不会重复),没有其他任何意义。
Sequence是数据库系统的特性,有的数据库有Sequence,有的没有。比如Oracle、DB2、PostgreSQL数据库有Sequence,MySQL、SQL Server、Sybase等数据库没有Sequence。
Sequence是数据中一个特殊存放等差数列的表,该表受数据库系统控制,任何时候数据库系统都可以根据当前记录数大小加上步长来获取到该表下一条记录应该是多少,这个表没有实际意义,常常用来做主键用,不过很郁闷的各个数据库厂商各有各的一套对Sequence的定义和操作。
详见:http://www.cnblogs.com/hyzhou/archive/2012/04/12/2444158.html
21、jdbc、hibernate、ibatis的区别
(1)jdbc是一套数据库访问标准,提供了一组接口,是JAVA语言访问数据库用到的东西
(2)hibernate是一套ORM映射框架,提供以对象的方式访问数据,但底层还是要把对象映射为JDBC来访问的。
(3)ibatis也是一套数据库访问框架,但它是把SQL语句给抽出来了,这样将来改语句的时候不用修改代码,底层也是JDBC
ibatis入门案例,请见:http://www.cnblogs.com/ycxyyzw/archive/2012/10/13/2722567.html
22、内核态(Kernel Mode)与用户态(User Mode)
内核态: CPU可以访问内存所有数据, 包括外围设备, 例如硬盘, 网卡. CPU也可以将自己从一个程序切换到另一个程序
用户态: 只能受限的访问内存, 且不允许访问外围设备. 占用CPU的能力被剥夺, CPU资源可以被其他程序获取
详见:http://www.cnblogs.com/zemliu/p/3695503.html
23、JVM符号引用
在java中,一个java类将会编译成一个class文件。在编译时,java类并不知道引用类的实际内存地址,因此只能使用符号引用来代替。比如org.simple.People类引用org.simple.Tool类,在编译时People类并不知道Tool类的实际内存地址,因此只能使用符号org.simple.Tool(假设)来表示Tool类的地址。而在类装载器装载People类时,此时可以通过虚拟机获取Tool类 的实际内存地址,因此便可以既将符号org.simple.Tool替换为Tool类的实际内存地址,及直接引用地址。
24、静态语句块
静态语句块,优先对象存在,也就是优先于构造方法存在,我们通常用来做只创建一次对象使用。
Java里静态语句块,类似于单例模式而且执行的顺序是:
父类静态语句块 -> 子类静态语句块 -> 父类构造方法 -> 子类构造方法;
千万别和构造方法搞混了,因为它是静态的,所以优先于构造方法,并且优先于空语句块。
public class Test {
private Test(){}
private static int num;
static {
//可能你的这个类是单例的,外界没办法调用构造方法,而你需要给num赋值,而又不是简单的赋值,需要从数据库中查询再赋值,就可以在这里做了
String sql = "select count(*) from table";
...
num = rs.getInt(1);
}
}25、反射加载类 与 使用类加载器加载类有什么区别
//方式一:反射加载
Class cl = Class.forName("classname");
//方式二: 使用ClassLoader
URLClassLoader loader = new URLClassLoader(urls);
Class cl = loader.loadClass("classname);Class.forname(classname) 会初始化这个类,可能还要加载其它相关类。
ClassLoader.loader(classname) 只是加载这个类
详见:http://bbs.csdn.net/topics/390433054
26、Java中hashmap是如何实现的
HashCode是使用Key通过Hash函数计算出来的,由于不同的Key,通过此Hash函数可能会算的同样的HashCode,所以此时用了拉链法解决冲突,把HashCode相同的Value连成链表. 但是get的时候根据Key又去桶里找。如果链表元素>1说明是冲突的,此时还需要检测Key是否相同
27、Java中哪些集合类线程安全
一些历史类的一般是线程安全的,例如:Vector,HashTable等,jdk1.5 引入的ConcurrentLinkedQueue、ConcurrentHashMap、CopyOnWriteArrayList 和 CopyOnWriteArraySet 也是线程安全的。
在jdk升级后,出现了替代一些集合的类,ArrayList,HashMap等,一般都是线程不安全的。

扩展一点说:
1、线程安全
线程安全就是说多线程访问同一代码,不会产生不确定的结果。
2、List类和Set类
List类和Set类是Collection集合接口的子接口。
Set子接口:无序,不允许重复。
List子接口:有序,可以有重复元素。
Set和List对比:
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
Set和List具体子类:
Set
|————HashSet:以哈希表的形式存放元素,插入删除速度很快。
List
|————ArrayList:动态数组
|————LinkedList:链表、队列、堆栈。
Array和java.util.Vector
Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
3、HashMap和HashTable
a.HashMap去掉了HashTable的contains方法,但是加上了containsValue()和containsKey()方法。
b.HashTable同步的,而HashMap是非同步的,效率上比HashTable要高。
c.HashMap允许空键值,而HashTable不允许。
4、线程安全集合类与非线程安全集合类
LinkedList、ArrayList、HashSet是非线程安全的,Vector是线程安全的;
HashMap是非线程安全的,HashTable是线程安全的;
StringBuilder是非线程安全的,StringBuffer是线程安全的。
5、集合适用场景
对于查找和删除较为频繁,且元素数量较多的应用,Set或Map是更好的选择;
ArrayList适用于通过为位置来读取元素的场景;
LinkedList 适用于要头尾操作或插入指定位置的场景;
Vector 适用于要线程安全的ArrayList的场景;
Stack 适用于线程安全的LIFO场景;
HashSet 适用于对排序没有要求的非重复元素的存放;
TreeSet 适用于要排序的非重复元素的存放;
HashMap 适用于大部分key-value的存取场景;
TreeMap 适用于需排序存放的key-value场景。
28、TLAB(Thread Local Allocation Buffer)
JVM在给对象分配时,如果只是修改一个指针位置,并不线程安全。有两种方案:
(1)对分配内存空间动作进行同步:JVM采用CAS+失败重试
(2)TLAB
Sun Hotspot JVM为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间TLAB(Thread Local Allocation Buffer),其大小由JVM根据运行的情况计算而得,在TLAB上分配对象时不需要加锁,因此JVM在给线程的对象分配内存时会尽量的在TLAB上分配,在这种情况下JVM中分配对象内存的性能和C基本是一样高效的,但如果对象过大的话则仍然是直接使用堆空间分配
TLAB仅作用于新生代的Eden Space,因此在编写Java程序时,通常多个小的对象比大的对象分配起来更加高效。
默认情况下,仅在TLAB或eden上分配,只有两种情况下会在老生代分配:
1、默认情况下,当TLAB、eden上分配都失败时,判断需要分配的内存大小是否 >= eden space的一半大小,如是就直接在老生代上分配;
2、在配置了PretenureSizeThreshold的情况下,对象大小大于此值。
29、full gc的发生时间
除直接调用System.gc外,触发Full GC执行的情况有如下四种
旧生代空间不足
旧生代空间只有在新生代对象转入及创建为大对象、大数组时才会出现不足的现象,当执行Full GC后空间仍然不足,则抛出如下错误:
java.lang.OutOfMemoryError: Java heap space
为避免以上两种状况引起的FullGC,调优时应尽量做到让对象在Minor GC阶段被回收、让对象在新生代多存活一段时间及不要创建过大的对象及数组。Permanet Generation空间满
PermanetGeneration中存放的为一些class的信息等,当系统中要加载的类、反射的类和调用的方法较多时,Permanet Generation可能会被占满,在未配置为采用CMS GC的情况下会执行Full GC。如果经过Full GC仍然回收不了,那么JVM会抛出如下错误信息:
java.lang.OutOfMemoryError: PermGen space
为避免Perm Gen占满造成Full GC现象,可采用的方法为增大Perm Gen空间或转为使用CMS GC。CMS GC时出现promotion failed和concurrent mode failure
对于采用CMS进行旧生代GC的程序而言,尤其要注意GC日志中是否有promotion failed和concurrent mode failure两种状况,当这两种状况出现时可能会触发Full GC。
promotionfailed是在进行Minor GC时,survivor space放不下、对象只能放入旧生代,而此时旧生代也放不下造成的;concurrent mode failure是在执行CMS GC的过程中同时有对象要放入旧生代,而此时旧生代空间不足造成的。
应对措施为:增大survivorspace、旧生代空间或调低触发并发GC的比率,但在JDK 5.0+、6.0+的版本中有可能会由于JDK的bug29导致CMS在remark完毕后很久才触发sweeping动作。对于这种状况,可通过设置-XX:CMSMaxAbortablePrecleanTime=5(单位为ms)来避免。统计得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间
这是一个较为复杂的触发情况,Hotspot为了避免由于新生代对象晋升到旧生代导致旧生代空间不足的现象,在进行Minor GC时,做了一个判断,如果之前统计所得到的Minor GC晋升到旧生代的平均大小大于旧生代的剩余空间,那么就直接触发Full GC。
例如程序第一次触发MinorGC后,有6MB的对象晋升到旧生代,那么当下一次Minor GC发生时,首先检查旧生代的剩余空间是否大于6MB,如果小于6MB,则执行Full GC。
当新生代采用PSGC时,方式稍有不同,PS GC是在Minor GC后也会检查,例如上面的例子中第一次Minor GC后,PS GC会检查此时旧生代的剩余空间是否大于6MB,如小于,则触发对旧生代的回收。
除了以上4种状况外,对于使用RMI来进行RPC或管理的Sun JDK应用而言,默认情况下会一小时执行一次Full GC。可通过在启动时通过- java-Dsun.rmi.dgc.client.gcInterval=3600000来设置Full GC执行的间隔时间或通过-XX:+ DisableExplicitGC来禁止RMI调用System.gc。
30、finalize的用法
31、TLAB
同28
32、线程状态转移图
33、Executor
34、类实例何时分配空间
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定,为对象分配空间的任务等同于把一块确定大小的内存从Java堆中划分出来。
除了如何划分可用空间之外,还有一个需要考虑的问题是对象创建在虚拟机中是非常频繁的行为,即使是仅仅修改一个指针所指向的位置,在并发情况下也不是线程安全的,可能出现正在给对象A分配内存,指针还没来得及修改,对象B又同时使用了原来的指针来分配内存的情况。解决这个问题有两种方案:一种是对分配内存空间的动作进行同步处理——实际上虚拟机采用CAS配上失败重试的方式保证更新操作的原子性
35、反射使用情景
类名字到对象,动态代理,测试,框架,要写一个通用的方法的时候可能也会用到反射
36、concurrenthashmap 在spring中的应用原因
多线程
37、什么是容器
38、依赖注入的起点
IoC就两个起点,如果lazy-init配置为true,那么getBean是起点,否则在容器初始化的时候就发生了依赖注入
详见:http://docs.spring.io/spring/docs/4.3.0.RELEASE/spring-framework-reference/html/beans.html#beans-factory-lazy-init
39、对象头
Mark Word 用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等等。JVM 对象头一般占用两个机器码,在 32-bit JVM 上占用 64bit, 在 64-bit JVM 上占用 128bit 即 16 bytes(暂不考虑开启压缩指针的场景)。另外,如果对象是一个 Java 数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通 Java 对象的元数据信息确定 Java 对象的大小,但是从数组的元数据中无法确定数组的大小。
对象需要存储的运行时数据很多,其实已经超出了32、64位 Bitmap 结构所能记录的限度,但是对象头信息是与对象自身定义的数据无关的额外存储成本,考虑到虚拟机的空间效率,Mark Word 被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。例如在 32 位的HotSpot 虚拟机中对象未被锁定的状态下,Mark Word 的 32个Bits 空间中的 25Bits 用于存储对象哈希码(HashCode),4Bits 用于存储对象分代年龄,2Bits 用于存储锁标志位,1Bit固定为0,在其他状态(轻量级锁定、重量级锁定、GC标记、可偏向)下对象的存储内容如下表所示。

Klass Pointer,即是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
40、各个线程的本地内存中会存放共享变量的副本,因此,各个线程之间共享变量的数据会出现时延?
Volatile+内存模型
41、方法放在方法区?
方法的字节码放在方法区,本地方法指的是native方法
42、classload和forName的区别
(1)Class clazz = whloader.LoadClass("classloader.WhHelloWorld");
(2)Class clazz = Class.forName("classloader.WhHelloWorld");
其实是一样的
43、Class.forName是反射吗
可以理解成反射的一部分
44、反射是什么
一般情况下只知道类名要用这个类
Instanceof
45、关于类对象的识别问题(classloader+类名)
因为有双亲委派模型,所以类对象保证加载的唯一。
46、classpath
47、垃圾收集器有哪些
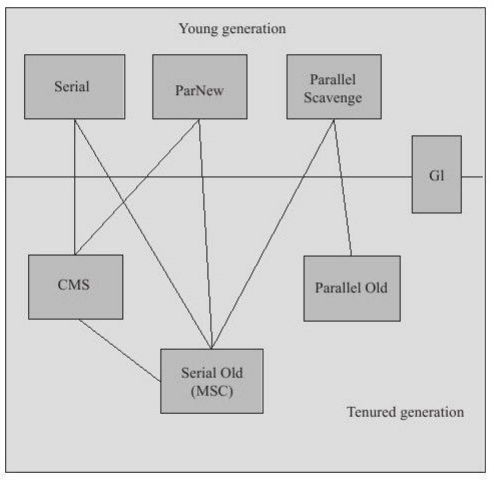
(1)serial
单线程收集,stop the world
(2)parnew
serial的多线程版本
(3)parallel scavenge
关注点不是缩短停顿时间,而是吞吐量(=CPU运行用户代码的时间 / CPU运行总时间)
(4)serial old
serial 老年代版本
(5)parallel old
parallel scavenge 老年代版本,标记整理
(5)CMS(concurrent mark sweep)
最短停顿时间为目标,标记清理算法
分4步:
初始标记(gc root能到达的对象)
并发标记(gc root tracing)
重新标记(修正并发标记,时间比初始标记长,但是比并发标记短)
并发清除
(6)G1
最前沿,划分region
详见:http://blog.csdn.net/scythe666/article/details/51907000
48、为什么分工作内存和主内存
(1)屏蔽硬件和操作系统内存访问差异(通用jvm),定义各个变量访问规则
(2)更好的执行效能
49、工作内存在哪里
工作内存对应于虚拟机栈的部分区域,为了效率,虚拟机可能会让工作内存优先储存于寄存器和高速缓存中
50、写出一个程序,让内存成如下图
51、spring里的事务是如何实现的
52、root tracing
就是追溯是否可达的过程,http://blog.csdn.net/time_hunter/article/details/12405127
53、Java可以手动内存回收吗
调用System.gc() 方法来建议垃圾回收器开始回收垃圾,完全的手动回收是不可能的
54、Java符号引用
在java中,一个java类将会编译成一个class文件。在编译时,java类并不知道引用类的实际内存地址,因此只能使用符号引用来代替。比如org.simple.People类引用org.simple.Tool类,在编译时People类并不知道Tool类的实际内存地址,因此只能使用符号org.simple.Tool(假设)来表示Tool类的地址。而在类装载器装载People类时,此时可以通过虚拟机获取Tool类 的实际内存地址,因此便可以既将符号org.simple.Tool替换为Tool类的实际内存地址,及直接引用地址。
55、垃圾收集策略
对象优先在Eden区分配,当Eden区没有足够空间时,触发一次Minor GC
Minor GC:新生代GC,频繁+速度快
Major GC/Full GC:老年代GC
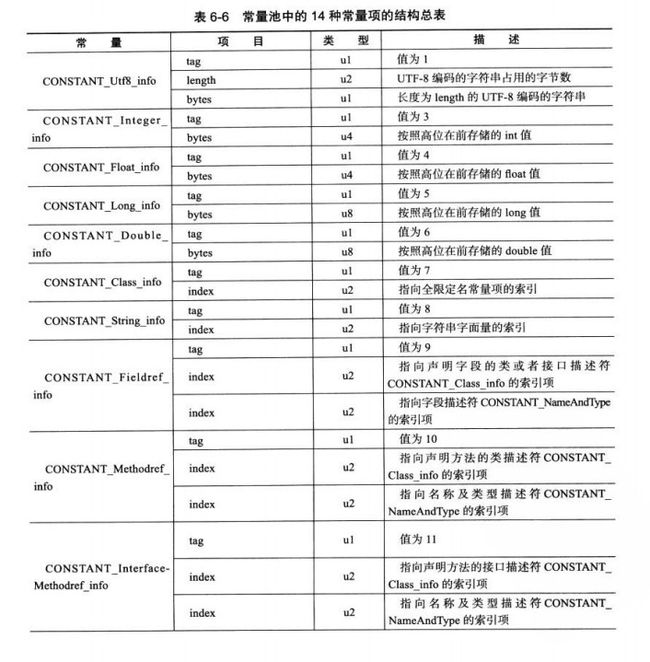
56、class常量池总14种常量项的结构
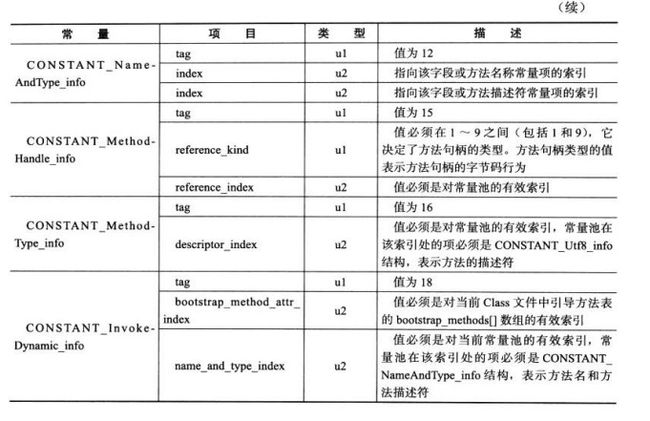
57、class类文件结构有哪些
(1)魔数 4byte
0xCAFEBABE
(2)版本 4byte
5-6字节 次版本号
7-8字节 主版本号
(3)常量池
常量池项目见 56
(4)访问标志 2字节
类或者接口层次访问信息,包括:Class是类还是接口,是否定义为public,是否定义abstract类型,如果是类的话,是否被声明为final等。
(5)类索引(u2)、父类索引(u2)、接口索引集合(u2*n)
确定类的继承关系
(6)字段表集合
描述接口或者类中声明的变量
(7)方法表集合
类似字段表集合,描述方法
(8)属性表集合
Class文件、字段表、方法表都可以携带自己的属性表集合,描述某些场景专有的信息。
58、什么是事件驱动
1.要理解事件驱动和程序,就需要与非事件驱动的程序进行比较。实际上,现代的程序大多是事件驱动的,比如多线程的程序,肯定是事件驱动的。早期则存在许多非事件驱动的程序,这样的程序,在需要等待某个条件触发时,会不断地检查这个条件,直到条件满足,这是很浪费cpu时间的。而事件驱动的程序,则有机会释放cpu从而进入睡眠态(注意是有机会,当然程序也可自行决定不释放cpu),当事件触发时被操作系统唤醒,这样就能更加有效地使用cpu.
2.再说什么是事件驱动的程序。一个典型的事件驱动的程序,就是一个死循环,并以一个线程的形式存在,这个死循环包括两个部分,第一个部分是按照一定的条件接收并选择一个要处理的事件,第二个部分就是事件的处理过程。程序的执行过程就是选择事件和处理事件,而当没有任何事件触发时,程序会因查询事件队列失败而进入睡眠状态,从而释放cpu。
3.事件驱动的程序,必定会直接或者间接拥有一个事件队列,用于存储未能及时处理的事件。
4.事件驱动的程序的行为,完全受外部输入的事件控制,所以,事件驱动的系统中,存在大量这种程序,并以事件作为主要的通信方式。
5.事件驱动的程序,还有一个最大的好处,就是可以按照一定的顺序处理队列中的事件,而这个顺序则是由事件的触发顺序决定的,这一特性往往被用于保证某些过程的原子化。
6.目前windows,linux,nucleus,vxworks都是事件驱动的,只有一些单片机可能是非事件驱动的。
都是手工敲的,很辛苦的。另外,我推荐你看一下维基百科,讲得很清楚,很透彻,直达本质。
59、为什么要有3个classloader
http://stackoverflow.com/questions/28011224/what-is-the-reason-for-having-3-class-loaders-in-java
The reason for having the three basic class loaders (Bootstrap, extension, system) is mostly security.
Prior to version 1.2 of the JVM, there was just one default class loader, which is what is currently called the “Bootstrap” class loader.
The way classes are loaded by class loaders is that each class loader first calls its parent, and if that parent doesn’t find the requested class, the current one is looking for it itself.
A key concept is the fact that the JVM will not grant package access (the access that methods and fields have if you didn’t specifically mention private, public or protected) unless the class that asks for this access comes from the same class loader that loaded the class it wishes to access.
So, suppose a user calls his class java.lang.MyClass. Theoretically, it could get package access to all the fields and methods in the java.lang package and change the way they work. The language itself doesn’t prevent this. But the JVM will block this, because all the real java.lang classes were loaded by bootstrap class loader. Not the same loader = no access.
There are other security features built into the class loaders that make it hard to do certain types of hacking.
So why three class loaders? Because they represent three levels of trust. The classes that are most trusted are the core API classes. Next are installed extensions, and then classes that appear in the classpath, which means they are local to your machine.
For a more extended explanation, refer to Bill Venners’s “Inside the Java Virtual Machine”.
另外,这个帖子没有提到的应该是隔离,java的所有类都是由classloader加载的,不同classloader之间加载的类彼此是不可见的。tomcat加载了log4j,容器里servlet也加载了log4j,servlet是看不见tomcat加载的log4j类的,反之亦然。
60、Java泛型是编译成字节码时确定还是运行时动态确定
