【算法基础总结】算法基础 (算法竞赛,面试...)
算法基础
(By: Skyed_blue 转载注明作者)
文章目录
- 算法基础
- 前言
- dfs(深度优先遍历)
- bfs(广度优先遍历)
- 二分查找(二分枚举)
- 并查集
- 位运算
- 双指针
- 栈(stack)
- 字典树(trie)
- 前缀和
- 初等数论
- 贪心
- 动态规划(dp)
- 结语
前言
本篇为算法基础整合,主要偏向于对基础算法的总结和整理。本篇将会介绍个人刷算法题的一些经验,基础算法的简要描述,基础算法整合的相关题目。因为整理的题目和题解时间都不一样,因此会有代码风格等差别。另外,默认大家都具备数据结构基础和STL函数库的使用,本篇不再讨论这些,虽然这些很重要(建议还没学会STL的可以先学STL,会有质的飞跃)。本篇相关题目在vjudge,leetcode,PTA,蓝桥杯等平台收录。
做算法题的思路:
- 先分析时间复杂度pick掉一部分算法,考虑这个时间复杂度我可以运用到哪些算法。比如说如果复杂度需要在nlogn,可以通过log想到二分,分治,堆,set等等。
- 然后以所求的结果为导向(要求出结果需要做哪些操作),可以通过样例或者自己举例子。比如说我要求C,时间复杂度在xxx,我觉得可以采用A步骤+B步骤。实现A和B都需要控制时间复杂度在xxx,如果我能在这个复杂度里求出A和B,那么这道题你完成一大半了。如果你想的A+B步骤时间复杂度超了,说明两点:这道题触及到你的知识盲区;这道题最佳步骤不是A+B。这时候你可以考虑想别的步骤。如果实在想不到还有什么其他的方法,果断看题解,不要浪费时间了。因为凭借刚才的思路你已经在你的知识和经验储备里尽可能发挥了,再往下想相当于“自己造算法”。如果是比赛,可以这样,也只能这样;如果是平时做题,不要这样。你去看题解,如果这个算法你没学过,那理所当然你做不出;如果这个算法你学过,那必然是你没想到原来可以这样用。前者是你的知识盲区,后者是你的经验不足。这时候,你就会补充你的知识和丰富你的经验。这道题对你的价值就在这里。
- 当你写完这道题并且过了样例之后,别急着提交。你需要冷静的思考:这道题有哪些坑点。你可以将达到这个结果中出现的各种过程造出样例,测试你的代码,你同时也要注意边界条件。比如走迷宫问题,我把地图扩到最大,无任何障碍,分析从左上走到右下的时间复杂度是否会超。总之就是要取一些极端的数据,比如0. 刷leetcode时一个很好的例子就是:int m = arr[0].size(). 这个m想求所给矩阵的列数。但是如果题目本身有arr.size() = 0,你这样做就是超界,直接RE了。这时就需要if(!arr.size()) return… 总的来说就考虑两点:各种过程到达结果是否都正确,适当造一些特例;边界条件是否注意到,数据范围是否会超。其实这两点可以用对拍试出来(不一定能试出来),对拍可以先不学,因为对拍生成数据还是有点麻烦的。
- 经过上面3个步骤,提交一发,依旧不一定能过。因为有一些情况是你自己没考虑到的。而OJ平台不会告诉你哪个样例没过。这时候你可能又会花很长的时间debug,甚至可能一个下午或者一个晚上只能写这一道题而且还不一定写的出来。等最后筋疲力竭,再去搜题解,又得分析别人的代码,然后在自己代码上又改改,最后提交。这整个过程很耗费时间,而且最后你可能会发现因为这道题特有的一种情况自己没考虑到导致自己一天花了大量精力的投入,愣是找不到bug. 这一天你可能几乎什么都没学到。很显然这个性价比很低。但是大家都是这样过来的。这种情况时常发生,看你怎么权衡了。
另外,想的时候可能会比较挣扎,但是不要用力扯头发。
如何学一个新的算法:
首先,学一个算法,理解原理,做例题。
然后,做这个算法相关的变型题,要想明白为什么这道题可以想到用这个算法,它的思路链(树)是怎样的,或者有"这个算法可以这样用,妙哉!"的想法。
最后,总结。总结中要把自己此时理解的思路写下来,确保以后忘记了翻回来看能快速捡起来这个算法。
学算法不一定每个算法都要达到可以自己写出来的程度。有些算法你可以先学到三四成,理解这个算法的原理和应用,以及它的时间复杂度和空间复杂度就可以了,因为ACM是可以带模板的。这样以广度优先学算法才是效率。之后你做某一题,发现这道题和我之前看到的xxx算法有点像,你这时候再去把这个算法模板拿来改改。这样你也成功做出来这道题,而且对这个算法有了更多的印象和经验。这样学才比较有效。
当然,对于基础算法,必须熟练。蓝桥杯,PTA都不能带模板,并且考的也都是一些基础算法。
关于做笔记:
做笔记我认为是非常有必要的。你好不容易学会了一个算法,结果过一个月回头看,发现跟没学一样,只知道这个算法名字了。
对于笔记,我认为有两个方面:算法知识笔记和题解。
算法知识笔记要自己理解了这个算法之后以“总结”的方式写。你的目的是“以后可以快速捡起来该算法”,因此你不能写太多,抓重点写。学这个算法哪个地方你卡住了,你就重点强调这里,方便以后回头看能快速理解这部分。另外,算法总结也要“模块化”。比如学一个算法,我自己做的笔记是:算法应用,算法原理,模板中一些重点难点,容易写错的部分,算法时间空间复杂度,算法题目整合。
关于题解,首先你要明白你自己为什么要写这道题的题解。因为这道题带给你xxx经验,某个点或者思路运用巧妙,自己当时做的时候没想到。你首先得分析为什么可以想到这个思路,然后用启发式的语言一步步写下去,而不是“原来这道题用到了这个方法,标注一下就行了”。看了题解之后你要重新回到自己的思路起点,一步步分析如何想到这个点,然后把这个分析的过程写下来。你在写的过程中,会进行语言组织的表达,思路的整理,仿佛你就是在教别人如何一步步推想到这个方法。这个真的非常重要。因为你写的时候你才会发现自己语言组织能力有多差。如果以后面试问你一道题,你回答出来了,但是当面试官问你“你是怎么想到的?”时,你会支支吾吾。因为你对这个过程没怎么注意。而写题解就是在帮助你理清思绪,整个从起点开始到想到这个方法的逻辑链你都很清晰,你自然就可以很顺畅的表达出来。就像我现在给你们写的这篇前言一样,逻辑清晰,令人信服。我以前写作文都没像现在写的如此丝滑,跟默写代码模板一样。这种清晰的逻辑链也会让你以后在思考一道题目的时候不会发散其他乱七八糟想法中断自己的逻辑,因为你想的每一步都是清晰的。
对于做笔记,个人不推荐写在纸上(这不是废话嘛,代码这么多)
那么,在电脑上如何做笔记呢?
我个人推荐一款软件“Typora”。良心软件,made in China,markdown轻量级文本文件,绝对比在word方便很多!你也可以将笔记写在博客里,分享自己的想(lao)法(sao),写完之后起码会让自己觉得“努力没白费”。因为写笔记和写博客是将自己的成果量化成肉眼可见的东西,算是心里安慰(自慰)吧。
ok,前言就先写到这。下面我会陆续总结基础算法的“简要知识点”和应用,也就是偏向于复习。我的博客:https://blog.csdn.net/Skyed_blue
dfs(深度优先遍历)
dfs,基础暴力搜索算法,关键在于找到每一层所必需的状态,以及能够枚举所有情况的代码。
**基础应用:**求N阶乘,斐波第N项,N个数全排列,枚举子集,组合穷举,遍历树,遍历图,记忆化搜索(备忘录dp),回溯(八皇后),走迷宫(输出路径)…
**高级应用:**图论里的各种Tarjan,欧拉回路(图论进阶可以先不看),floodfill着色法,容斥定理(了解概念,可以先不深究),环检测(dfs和拓扑排序),LCA(最近公共祖先,可以先不看)…
dfs技巧:
状态标记:vis数组,标记某状态已被遍历过,避免重复遍历形成死循环等。
方向数组:dx[4] = {0,0,1,-1},dy[4] = {1,-1,0,0} 可以直接一个for循环走四个方向
剪枝:通过当前状态避免一些不必要的遍历过程,相当于剪掉搜索树的某些枝条。一般分为可行性剪枝(如一个迷宫,问能否从起点到达目标点之类),最优性剪枝(最小步数,求最值,这个很好剪),迭代加深(A*,没怎么了解)适合深度不是很深,但是每次扩展的结点数很多的搜索问题。
【蓝桥杯】2019国赛B组 101串(dfs剪枝)
子集(枚举子集,可状态压缩)
棋盘问题(dfs)
迷宫问题(dfs,bfs)
【leetcode】串联字符串的最大长度(dfs回溯,可状态压缩)
统计封闭岛屿数目(floodfill)
HDU-1796 How many integers can you find (容斥定理+dfs)
【蓝桥杯】发现环(dfs搜环节点)
bfs(广度优先遍历)
bfs,基础暴力搜索算法,用队列(open-close表)实现。每个节点表示一个状态,若一个节点有多个属性,用pair或结构体改造节点。
基础应用:树的层次遍历,图的最短路(无权就是队列,有权就是小顶堆),最短路(最小值),拓扑排序,Floodfill…
高级应用:双向广搜,A*(启发式搜索,估价函数优化队列),差分约束(最短路本质,线性规划),AC自动机(字典树+KMP+BFS)…
bfs技巧:
状态标记,方向数组,和dfs技巧类似。
一般看到最短路问题,请直接选择bfs. 写dfs就是在浪费时间。
迷宫问题(输出路径)
【PTA】喊山(图bfs)
【PTA】7-36 社交网络图中结点的“重要性”计算 (bfs)
跳跃游戏III (基础dfs,bfs)
地图分析 (floodfill)
颜色交替的最短路径 (dfs,bfs, 好题目值得做)
穿过迷宫的最少移动次数(bfs,比较繁琐)
转化为全零矩阵的最少反转次数(dfs,bfs, 有各种优化,好题)
网格中的最短路径(bfs)
八数码(广搜,双广,A*,状态压缩,经典题目,绝对值得做)
二分查找(二分枚举)
二分查找是很常用的优化算法,时间复杂度在logn,前提条件是有序。二分一般应用:二分查找,二分查找下界(lower_bound),二分查找上界(upper_bound),二分枚举。我的这篇博客https://blog.csdn.net/Skyed_blue/article/details/103260295综合了很多题解加上自己的实践总结出,推荐看(0.0)。相关题目也在里面了。
并查集
并查集是一种树型的数据结构,用于处理一些不相交集合的合并(将两个元素所在集合合并成一个集合)及查询(两个元素是否在同一个集合)问题。还有一种理解是将所有元素看成图的一个节点,并把每个节点视为一个集合。此时假设有n个节点就相当于有n个集合,n个连通块。并查集就是查询(两个节点是否在同一连通块)及合并(将两个节点所在的连通块合并成一个连通块)。因此在分析一道题是否需要用到并查集时主要考虑这道题是否和集合或者连通块有关系。
并查集技巧:
路径压缩:return pre[x] = Find(pre[x]); 每查询完一遍,可以将这棵集合树的所有节点指向根节点。
求连通块数:遍历所有节点,若pre[x] = x, cnt++;
加属性:这个可以根据题意灵活运用了。比如说要求每个连通块的节点总数,可以定义一个cnt数组,每次并的时候将cnt累加;同理也可以求每个连通块中的最值,总和等等。这就要求你对整个并查集原理非常熟悉,才能得心应手。
带权并查集:每条边都记录了每个节点到根节点的权值。这里用pre[x]表示x节点的根节点,val[x]表示x到pre[x]的权值和。初始化时pre[x] = x, val[x] = 0; 下面先上模板:
int find(int x){
if(x != pre[x]){
//先记录父节点
int t = pre[x];
//父节点指向根节点(经过这个递归之后父节点的val值更新了)
pre[x] = find(pre[x]);
//加上父结点的val值
val[x] += val[t];
}
return pre[x];
}
void Union(int x, int y, int w){
int rx = find(x), ry = find(y);
//如果x和y在不同的集合
if(rx != ry){
//rx连到ry
pre[rx] = ry;
//要更新rx->ry的val[rx]值,可以看成向量运算
val[rx] = -val[x] + w + val[y];
}
}
先举个样例解释find函数:
1 3 10 3 4 20 4 7 50

我们最终结果应该是:val[1] = 80, val[3] = 70, val[4] = 50, val[7] = 0,pre都指向7.
find如何更新呢?
先是第一组数据:
pre[1] = 3, val[1] += 10 = 10;
第二组数据:
pre[3] = 4, val[3] += 20 = 0+20 = 20;
pre[1] = 4, val[1] += val[3] = 20+10 = 30; (这就是为什么要保存父节点t. 我们先保存父节点t,然后递归下去,之后val[t]就被更新了,于是再更新val[x])
第三组数据:
pre[4] = 7, val[4] += 50 = 0+50 = 50;
pre[3] = 7, val[3] += val[4] = 20+50 = 70;
pre[1] = 7, val[1] += val[3] = 10+70 = 80;
就这样,我们就可以得到每个节点到其根节点的权值和,并且路径同样压缩了。
再举个样例解释Union函数:
1 4 20 3 5 40 1 3 30
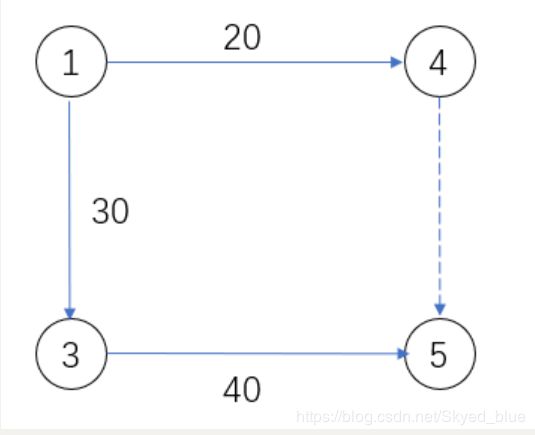
前两组数据没问题。在第三组数据时,先获取rx = find(x) = 4, ry = find(y) = 5;这时候我们用4并到5,即pre[4] = 5. 那么val[4]就应该更新,因为4的根节点已经不再是自己了。如何更新val[4]呢?
可以看上面的图,4到5的连接并不是直接连过去,而是通过4-1-3-5到达。用向量的思维,45 = 41+13+35 = -20+30+40. 因此val[rx] = -val[x] + w + val[y]; val[4] = 50.
等一下,我们似乎还需要更新1对吧?需要pre[1] = 5, val[1] += val[4] = 20+50=70 (这个就是1-3-5的权值和). 那么Union只更新了根节点,这个集合里的其他节点怎么办呢?
我们可以对这些节点再调用一次Find即可。不过我们不需要在Union里操作,也就是不需要每合并一次都要对这些节点调用Find. 首先,我们在Union时会先调用Find,这已经更新了一遍;其次,我们可以先将所有数据都操作完,最后根据情况调用Find,集合森林就已经被完完全全被更新好了。
ok,虽然讲完了带权并查集的原理,但我做题的时候并没怎么遇到带权并查集的题,这里就分享其他人的博客吧。https://blog.csdn.net/yjr3426619/article/details/82315133
并查集例题:
【PTA】朋友圈(并查集求最大连通块中节点总数)
畅通工程(并查集求连通块个数)
【蓝桥杯】合根植物(并查集求连通块个数)
【leetcode】交换字符串中的元素(并查集,偏难)
连通网络的操作次数(并查集,需要一些推理)
位运算
位运算个人认为是很重要的一项技巧。常用的有与(&),或(|),异或(^),左移(<<),右移(>>). 这几种运算符相互组合可以直接通过int在二进制位实现许多功能和算法空间优化。大家可以先看看下面的博客。
【运算符】算法中的逻辑运算技巧总结(这篇把常见的都总结了,可快速入门)
以下是作者@Matrix67原创,将位运算修炼成geek了(建议不要陷进去).
http://www.matrix67.com/blog/archives/263(基础篇)
http://www.matrix67.com/blog/archives/264(进阶1)
http://www.matrix67.com/blog/archives/266(进阶2)
位运算常见应用:
状态压缩:一维bool型矩阵,二维bool型矩阵压缩成一个整数(有31个可用二进制位). 也可以选择string压缩。但是要注意:如果矩阵里的数范围超过10,就无法用string压缩。一般常用的有枚举01情况(选和不选),判断字符是否存在的哈希,以及01矩阵,0~9的矩阵(string)。还有状压dp(了解不多,此处不表)
树状数组,快速幂和快速乘法(后面会提到)。
相关例题:
【蓝桥杯】明码(运算符, 进制转换)
【leetcode】子集(dfs, 状态压缩+位压缩)
【leetcode】串联字符串的最大长度(dfs回溯,位压缩)
【leetcode】子数组异或查询(前缀和+位运算)
【leetcode】或运算的最小反转次数(位运算+贪心)
【leetcode】只出现一次的数字(面试题常考)
【leetcode】转化为全零矩阵的最少反转次数(dfs,bfs, 二维矩阵状态压缩,各种优化,好题)
【leetcode】八数码(广搜,双广,A*,状态压缩,经典题目,绝对值得做)
双指针
双指针个人分成前后指针和左右指针。前后指针就是滑动窗口(尺取法),用来求解一些子区间最值问题上;左右指针就是类似于快排和归并那种。具体的算法可以看我的博客https://blog.csdn.net/Skyed_blue/article/details/103318974,里面有很细致的过程以及相关例题。
栈(stack)
基础数据结构,后进先出。
相关技巧:
对于括号匹配问题,其实栈里只存了左括号,遇到右括号就弹出栈了。于是,我们可以将左括号的下标存进栈中。若遇到右括号,弹出栈顶元素,就可以得到左右括号的区间了。
单调栈:https://www.cnblogs.com/1024th/p/10778050.html 可以看这篇,详解单调栈和单调队列。
**相关应用:**括号匹配,递归,波兰表达式和逆波兰表达式的转换和求值…
【leetcode】有效的括号(括号匹配基础)
【leetcode】最长有效括号(dp, 栈)
【leetcode】检查替换后的词是否有效(隐含栈思想)
【leetcode】反转每对括号间的子串(栈的技巧之一)
【leetcode】移除无效的括号(栈的技巧之一)
【leetcode】删除字符串中的所有相邻重复项 II(双指针,栈)
【leetcode】接雨水(单调栈+规律,还有其他方法,经典题)
【leetcode】表现良好的最长时间段(单调栈)
Largest Rectangle in a Histogram(单调栈,还有其他方法,经典题)
[蓝桥杯-历届试题] 拉马车 (栈与队列)
【PTA】彩虹瓶(装箱问题)
字典树(trie)
字典树有分前缀树和后缀树,这里主要介绍前缀树。字典树原理是边权为一个字
符(一般这个字符是26个英文字母). 字典树一般用二维数组 trie[N][26] 存放,N表示节点数,26表示这个节点的26条出边。 trie[i][j] = k 表示 i 节点到 k节点的字符为 j . 具体可以参考下面两个博客:
https://www.cnblogs.com/TheRoadToTheGold/p/6290732.html
https://www.cnblogs.com/bonelee/p/8830825.html
应用:
查询字符串是否存在,出现频率;查询前缀是否存在,出现次数…
相关例题:
统计难题(查询前缀出现次数,模板代码)
【leetcode】删除子文件夹(带点技巧的字典树)
【leetcode】键值映射(求前缀键值总和)
【leetcode】单词替换(根据前缀替换单词)
【leetcode】dfs+前缀树(偏难)
前缀和
O(n)求出前缀和,之后对于任意区间的查询均可在O(1)实现,一般用于预处理。如果遇到需要查询多次区间和的操作,请考虑前缀和。另外,由前缀和可以引出另一个算法:差分。差分的应用是对区间进行多次修改,最后询问区间和。如果暴力,O(n^2). 运用差分:O(n). 就是这么神奇。下面看一道例题:
给你一串长度为n的数列a1,a2,a3......an,要求对a[L]~a[R]进行m次操作:
操作一:将a[L]~a[R]内的元素都加上P
操作二:将a[L]~a[R]内的元素都减去P
最后再给出一个询问求s[L]-s[R]内的元素之和?
操作一:将a[L]~a[R]内的元素都加上P
操作二:将a[L]~a[R]内的元素都减去P
最后再给出一个询问求s[L]-s[R]内的元素之和?
假设这个数组a为[1,6,8,5,10],我们先令后一个数减去前一个数,得到的数组b为[1,5,2,-3,5].
这时我们将区间 [1,3]都加上2,我们只需要b[1]+=2,b[4]-=2. 此时b数组为[1,7,2,-5,5]. 然后,我们对b求一下前缀和得到sum:[1,8,10,5,10]
我们发现sum居然就是a数组区间[1,3]加上2!是不是很神奇!
那么,原理是怎样的呢?
首先,我们第一步操作令后一个数减去前一个数得到的数组b,对b求前缀和就是原来的数组a. 我们将a转化为b就是想利用前缀和不断累加的性质。
当我们对b[1]+=2,b[4]-=2时,再求前缀和:sum[2]=sum[1]+b[2], sum[3] = sum[2]+b[3],sum[4] = sum[3]+b[4].
发现没有?我们对b[1]+=2后求前缀和,后面的b[3], b[4]…经过前缀和的累加全部都加上了2!那么我们如何停止呢?只需要b[4]-=2即可。经过上面的操作,区间[0,0]是什么都不变的,区间[1,3]继承了b[1]的累加2,区间[4,N]继承了b[1]的累加2和b[4]的累减2,因此区间[4,N]和a数组一致。
明白原理后,我们来说一下差分基本操作:
- 用后一项减前一项得到新数组b (首位不变)
- 若修改区间[L,R],则在b[L]和b[R+1]操作。
- 最后,对b进行前缀和,得到最终数组。
相关例题:
【leetcode】二维区域和检索 - 矩阵不可变 (二维前缀和dp)
【leetcode】构建回文串检测(前缀哈希,偏难)
【leetcode】K 次串联后最大子数组之和 (前缀和,后缀和,分类讨论,偏难)
【leetcode】区间和的个数(典型的前缀和+二分,也可用权值线段树,偏难)
【leetcode】子数组异或查询(前缀和+位运算)
初等数论
有一定的数论基础是很有必要的。对于数论模块本篇只讨论初等数论中的基础。
相关基础知识有:模运算,筛法求素数,分解质因数,最大公因数(gcd),最小公倍数(lcm),快速乘法,快速幂。
其他初等数论知识有:
逆元:a*x = 1(mod p),称x为a的逆元,用于求模除法运算。可通过扩欧或费马小定理+快速幂求得
扩展欧几里得:求解线性同余方程中的一组整数特解,求逆元
中国剩余定理:求解模线性方程组
欧拉函数φ(n):表示在[1,n]内与n互素的数的个数(两个数互素就是gcd(a,b)=1)
欧拉定理:若n,a为正整数,且n,a互素,则: 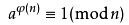
费马小定理: 若p为素数,a为正整数且和p互素,则:![]()
Rabin-Miller:大素数判定
RSA:加密和解密
…
模运算:
a % p(a mod p),表示a除以p的余数。
- 模p加法:(a + b) % p = (a%p + b%p) % p
- 模p减法:(a - b) % p = (a%p - b%p) % p
- 模p乘法:(a * b) % p = ((a % p)*(b % p)) % p
- 幂模p : (a^b) % p = ((a % p)^b) % p
备注:
平时看到的取模mod=100000007(1e9+7),若要算a+b模mod,直接(a+b)%mod即可,因为在int中2*(1e9+7)依然在范围内。
对于模p除法,需要引用到“逆元”。(a/b)%p = a*(b的逆元)%p 转化为模p乘法。
素数筛:
#define ll long long
const int N = 100000; //获取区间[1,N)的素数
int vis[N]; //vis[i]=1表示i不是素数
ll prime[N]; //存放素数
void isPrime() //打素数表
{
t=0;
memset(vis,0,sizeof(vis));
memset(prime,0,sizeof(prime));
for(ll i=2;i这里解释一下为什么 j 可以从i*i开始:
按理说,假设i=5,我们应该令10, 15, 20…为合数才对。为什么从i*i=25开始呢?
这是因为当j = i*k,(k
分解质因数:
算术基本原理:对于每个n,都可以唯一分解成素数的乘积。

例如24可以拆分为:2^3 * 3^1. 通过素数拆分可以求出n的素因子以及每个素因子的幂。
我们可以先用素数筛得到一定范围内的素数,然后不断用素数§试探n. 若n%p==0表示p是n的素因子。这时通过循环n/p并记录除的次数cnt直到n%p!=0。所得到的cnt就是这个素因子的幂。
先上模板:
#define ll long long
const int N = 100000; //获取区间[1,N)的素数
int vis[N]; //vis[i]=1表示i不是素数
ll prime[N]; //存放素数
void isPrime() //打素数表
{
int t=0;
memset(vis,0,sizeof(vis));
memset(prime,0,sizeof(prime));
for(ll i=2;i先稍微解释一下prime[i]*prime[i] <= x问题:可以理解成对于质数p,[2,p*p)这个区间的合数在前面的p中已经被处理过了。比如说p=2时,在区间[2,4)内:2是质数,3是质数。p=3时,在区间[2,9)内:2是质数,3是质数,4被p=2处理了,5是质数,6被p=2处理了,7是质数,8被p=2处理了。
关于最后x!=1的判定问题:因为prime[i]*prime[i] <= x没有处理[2,p*p)里的质数,假设p=7, x = 23, 这个循环也退出了。这里的x!=1就是处理质数的。
gcd和lcm:
int gcd(int a, int b){
if(b==0) return a;
return gcd(b,a%b);
//或者直接写成一行:return b==0?a:gcd(b,a%b);
}
//最小公倍数:a*b除以gcd(a,b). 先除后乘防超界
int lcm(int a, int b){
return a/gcd(a,b)*b;
}
快速乘法:
快速乘法可快速计算a*b%mod的结果并且不会爆long long. 可以用来优化快速幂。
实现原理:乘法分配律
比如说a和10相乘,将10拆成二进制位1010,表达式为2^1+2^3. 那么a*10 = a*(2^1+2^3) = a*2^1 + a*2^3. 因此我们可以将10拆成二进制然后累加结果即可。
#define ll long long
ll q_Mul(ll a, ll b, ll c){
ll ans = 0;
a %= c;
while(b){
if(b&1) ans = (ans+a)%c;
//a保持b位置所对应的值。比如b=1,a=a*2^1;b=2,a=a*2^2
a = (a<<1)%c;
b >>= 1;
}
return ans;
}
快速幂:
可快速计算a^b%mod的结果。
以a的10次方为例子:
首先,将10拆成二进制1010,对应表达式2^1+2^3. 那么a^10 = a^(2^1+2^3) = a^(2^1) * a^(2^3). 和快速乘法一样,我们也可以把10拆成二进制位然后累乘即可。
#define ll long long
ll q_mod(int a, int b, int c){
ll ans = 1;
a %= c;
while(b){
if(b&1) ans = (ans*a)%c; //此处可用快速乘法优化
//a保持b位置所对应的值。比b=1,a`=a^2;b=2,a`=a^4;b=3,a`=a^8
a = a*a%c; //此处可用快速乘法优化
b >>= 1;
}
return ans;
}
贪心
贪心其实是一个做决策的思想,每次选择局部最优解可以推出全局最优解。贪心一般来说没什么固定的模板和套路,硬要说的话倒是可以总结一下做贪心题可能会用到的一些技巧。
相关技巧:
先找准当前最佳状态。
局部最优解是根据对当前最佳状态进行操作的。这个当前最佳状态可能会变也可能不会变。比如说,你要爬19层楼梯,每次你可以爬1层,2层或3层。那么根据现实生活很容易得出每次爬自己能爬的最多层就可以最快到达目的地。这里的当前最佳状态就是爬最多的层。因为整个过程中你都可以选择爬3层,所以这个当前最佳状态是不会变的。这个属于比较简单的贪心。
如果复杂一点的贪心,当前最佳状态会随着当前状态不断改变。比如上面的爬楼梯例子改一下:给你一个数组arr,arr[i] = j 表示在第 i 层可以向上爬[0,j]层,这时候就需要先预估一下爬哪一层可以使自己之后爬的最远,可能还会有无论怎么爬都到不了的情况。这个例子可以参考下面的跳跃游戏和跳跃游戏II.
贪心常用的技巧:堆
为什么会运用到堆呢?因为堆有一个很妙的性质:动态获得最值。这个动态源于堆插入和删除都是O(logn),是一个很优秀的时间复杂度。因为上面提到每次选择当前最佳状态并且这个状态可能会不断改变,这是一个动态过程。而贪心每次只需要获取状态中最佳的那个,不用访问其他的状态,因此堆是最适合的数据结构。一个很好的例子就是哈夫曼树。哈夫曼树每次都要选当前状态中最小和次小的数,相加,所得结果会添加到新的状态(每次都要插入新数据,动态体现在这)。每次当前状态都会发生改变,而且只需要获得最小和次小状态。
相关例题:
【PTA】月饼 (贪心典型题,背包问题)
电影节 (贪心典型题,区间问题)
Stall Reservations (贪心,区间问题,堆优化)
【leetcode】跳跃游戏 (贪心,找当前状态)
【leetcode】跳跃游戏II (难一点的贪心,找当前状态)
【leetcode】灌溉花园的最少水龙头数目(贪心,找当前状态,偏难)
【leetcode】买卖股票的最佳时机II (简单贪心)
【leetcode】优势洗牌 (贪心+二分)
【leetcode】玩筹码 (简单贪心)
【leetcode】分割平衡字符串 (简单贪心)
【leetcode】划分数组为连续数字的集合 (map+贪心 或 堆+贪心)
【leetcode】最多可以参加会议的数目 (预处理+堆+贪心,偏难)
【leetcode】数组大小减半 (贪心)
【leetcode】多次求和构造目标数组 (贪心+堆)
动态规划(dp)
动态规划是一种决策思路,当贪心的局部最优解无法得到全局最优解的时候,动态规划就出现了。动态规划应用于求解最值,方案数,方案可行性,博弈论等。
本人大约做了70道dp题,从入门到现在积累了许多经验,也走了一些弯路。但是每当面对dp题,依然会觉得没把握,因为dp真的可以出的很难。**这里对动态规划入门不做具体说明,只简要介绍。**入门推荐题:数字三角形(学会滚动数组原理),最长上升子序列(经典模型,拓宽思维),最长公共子序列(经典模型,拓宽思维),最长字段和(经典模型),01背包(经典模型,学会滚动数组),完全背包,多重背包(经典模型),最长回文子串(区间dp,经典模型)
基本思想:
问题的最优解如果可以由子问题的最优解推导得到,则可以先求解子问题的最优解,在构造原问题的最优解。
基本原理:
动态规划的本质就是打表。将之前求得的结果保存起来,到下一个状态时其结果可由之前的状态推出。比如说,我们最常见的前缀和其实就是一个动态规划。我们先定义一个状态sum[i] 表示前 i 个数的总和,那么其状态转移方程就是 sum[i] = sum[i-1]+a[i-1](i-1是因为数组下标从0开始). 对于这个方程我们需要有个初始值作底,才能让这个方程递推下去。我们可以发现当 i = 0 时,sum[i] = 0. 于是这个前缀和的dp就写好了。这个过程体现出dp的一个自底向上的思想。我们的底是sum[0] = 0, 由这个底逐渐往上推出其他的解。
其实动态规划入门还是比较麻烦的,因为初学者没适应这种思考的过程,对打表这个概念不重视或者不理解。其实个人认为学动态规划最好的入门方式就是打表。如何打表呢?拿上面的前缀和举例子。
比如说a[3] = {1,2,3}, 方程sum[i] = sum[i-1]+a[i-1]. 初始条件sum[i]=0
i |
0 | 1 | 2 | 3 |
|---|---|---|---|---|
| sum[i] | 0 | 0+1=1 | 1+2=3 | 3+3=6 |
通过打表,你可以很清晰的知道这个状态是怎么由上一个状态推过来的,有助于理解动态规划整个过程。或许我举的这个例子比较简单,大家觉得没必要打表。但我想强调的是,动态规划一定要有一个打表的思维!不要单纯根据什么语言文字就直接写出状态方程,这样的方程你写出来不一定是对的,而且你只单纯这样想根本无法判断自己写的状态方程对不对,这只是你根据日常经验觉得就是这样的。平常你看动态规划的题解,一般都是直接给出以…为状态,状态转移方程是… 题解对这个状态转移方程得来的描述也只是通过简短的文字。对于初学的你,对动态规划没有整个打表的思维,你就只是觉得这个文字描述的对,这样写状态方程就可以得到最终结果了。而等你之后做其他题,你也尝试按这样的思路写,如果最后得到的答案错了,你根本不知道怎么办。因为你不知道最后得到的这个答案是怎么来的。所以,我希望初学者们一开始每做一道动态规划,都要尝试自己打表,培养这种思维,这样才算真正学懂。ok,入门就讲这么多。
基本思路:
做动态规划的基本思路有以下几个步骤:
第一步,找状态
其实这个状态就相当于建模。dp题你做的多了有些状态一看题就秒出了。这里说下找状态需要考虑的一点:这个状态是否能涵盖所有的情况。因为动态规划本质就是枚举和打表。就像用dfs的备忘录写法一样。后面会举例子示范。
第二步,找状态转移方程
找到状态之后,要分析当前状态的结果可以由之前的什么状态的结果推过来,关系是怎么样的。后面举例子示范。
第三步,找初始条件
找到状态转移方程之后,分析这个递推方程的“底”,找初始条件。事实上很多时候都是初始条件出错导致结果出错了。因为状态转移方程找不到你是不会敲代码的,只会去搜题解。因此出错之后第一时间先看自己初始条件有没有问题,如果觉得没问题,再回去看看自己的状态转移方程是否满足所有情况。后面举例子示范。
第四步,写递推方程
写递推方程要分析递推的顺序,如果是O(n^2)的dp,两个for循环写反了就会得到不同的结果。在01背包和完全背包的空间压缩中对于递推顺序的要求也是很讲究的。还是那句话,你有打表的思维,知道数据是怎么样推出来的,你就知道应该写什么顺序。
举例子:
ok,下面拿最长公共子序列举例子。
给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,“ace” 是 “abcde” 的子序列,但 “aec” 不是 “abcde” 的子序列。两个字符串的「公共子序列」是这两个字符串所共同拥有的子序列。
若这两个字符串没有公共子序列,则返回 0。
示例 1:
输入:text1 = “abcde”, text2 = “ace”
输出:3
解释:最长公共子序列是 “ace”,它的长度为 3。
示例 2:
输入:text1 = “abc”, text2 = “abc”
输出:3
解释:最长公共子序列是 “abc”,它的长度为 3。
示例 3:
输入:text1 = “abc”, text2 = “def”
输出:0
解释:两个字符串没有公共子序列,返回 0。
首先,遇到这种两个字符串的dp题,状态很自然就是一个二维数组,令dp[i][j]表示text1前i个字符,text2前j个字符中最长公共子序列长度。根据题意我们需要求dp[text1.length][text2.length]。那么,根据我上面的基本思路对找状态的分析,为什么可以想到是二维数组呢?
我们找的状态是要枚举所有情况的。如果我们按照平常暴力求法,就是把每个子串都比较一遍。比如"ab"和"acb",我们会比较"a","a","a","ac","a","acb"…一个二维数组就可以将上面比较的所有情况涵盖了。
然后,我们开始想状态转移方程。我们需要拿样例或者自己举例子分析一下当前状态的结果和之前哪些状态的结果有关。比如说,就拿上面的"ab"和"acb",对应的是dp[2][3] = 2. "ab"和"acbe"对应的是dp[2][4] = 2. 这里可以发现,“ab"和"acb"因为text[i-1]=text[j-1],所以它的结果是由前面的"a"和"ac”,也就是dp[1][2]所得到的结果+1得来。因此dp[i][j] = dp[i-1][j-1]+1 (text[i-1] == text[j-1]). “ab"和"acbe"的结果其实和"ab”,“acb"是一样的,因此dp[i][j] = dp[i][j-1]. 我们再来举一个例子:“ab"和"dda”. 这种状态的结果其实和"a”,"dda"是一样的,因此dp[i][j] = dp[i-1][j]. 就这样,状态转移方程就出来了。每一个方程都对应着一个决策。我们从这3个决策中选出一个最大值。那么完整的状态转移方程就是:dp[i][j] = dp[i-1][j-1]+1 (text[i-1] == text[j-1]),dp[i][j] = max(dp[i-1][j],dp[i][j-1]).
ok,分析完了状态转移方程,我们需要找初始条件了。这个初始条件可以有两种方法找:日常经验法和方程推断法。对于第一种方法没什么好说的。像上面的情况,如果两个都是空串,很自然dp[0][0] = 0. 如果其中一个是空串,dp[i][0] = 0, dp[0][i] = 0. 当然,你可能会觉得:万一我比较蠢,或者我没什么生活经验,或者我脑子里有浆糊漏了某种情况怎么办呢?不要急,这时候我教你一个办法:方程推断法。哪怕你做题时高烧40度脑子有问题都可以找全。看到上面的状态转移方程了吗?对于dp[i][j],可以由dp[i-1][j-1], dp[i-1][j], dp[i][j-1]推出来。如果 i = 0 或 j = 0 或 i=j=0 时怎么办? 这不就超界了吗?超界是不可能超界的。相信你已经明白了,我们对于这种会超界的特殊情况进行的特判其实就是我们状态转移方程的"底"。你只要保证状态转移方程在任何情况都不会超界就可以了。
ok,我觉得到这,这道题就可以说结束了。当然,Last but not least, 我们要打表。初学dp最重要的就是打表了。随便举个例子,test1 = “abcde”,test2 = “acez”,然后打表。
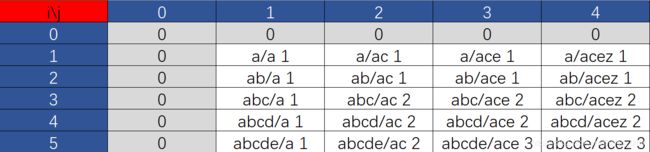
可以发现,灰色部分就是我们的初始状态。对于这道题来说,先行后列推和先列后行推都是可以的。
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
int n = text1.length(), m = text2.length();
int dp[n+2][m+2];
memset(dp,0,sizeof(dp));
for(int i = 1;i <= n;i++)
{
for(int j = 1;j <= m;j++)
{
if(text1[i-1] == text2[j-1])
dp[i][j] = dp[i-1][j-1]+1;
else
dp[i][j] = max(dp[i][j-1], dp[i-1][j]);
// cout<经过上面的练习后,我们再来做一道dp题吧。
停留在原地的方案数
有一个长度为 arrLen 的数组,开始有一个指针在索引 0 处。
每一步操作中,你可以将指针向左或向右移动 1 步,或者停在原地(指针不能被移动到数组范围外)。
给你两个整数 steps 和 arrLen ,请你计算并返回:在恰好执行 steps 次操作以后,指针仍然指向索引 0 处的方案数。
由于答案可能会很大,请返回方案数 模 10^9 + 7 后的结果。
示例 1:
输入:steps = 3, arrLen = 2
输出:4
解释:3 步后,总共有 4 种不同的方法可以停在索引 0 处。
向右,向左,不动
不动,向右,向左
向右,不动,向左
不动,不动,不动
示例 2:
输入:steps = 2, arrLen = 4
输出:2
解释:2 步后,总共有 2 种不同的方法可以停在索引 0 处。
向右,向左
不动,不动
示例 3:
输入:steps = 4, arrLen = 2
输出:8
提示:
1 <= steps <= 500
1 <= arrLen <= 10^6
我就直接说了吧。这道题就是一眼题。扫一眼就知道怎么做了。为什么这么说呢?
首先,状态很明显就是一个二维数组。dp[i][j] 表示走了i步,当前位置在下标j处的最大方案数。很自然的,这个状态所有情况都考虑到了。在恰好执行 steps 次操作以后,指针仍然指向索引 0 处的方案数。那很自然求dp[steps][0]呗。
每一步操作中,你可以将指针向左或向右移动 1 步,或者停在原地(指针不能被移动到数组范围外)。
这就更白痴了,如果说上一题决策需要我们自己举例子推出来,那么这道题决策直接就告诉你了呀!3种情况,3种决策。我高烧40度都可以知道dp[i][j]由dp[i-1][j-1],dp[i-1][j],dp[i-1][j+1] 推出。因为求方案总数,所以是三种情况全部加一起。
-
dp[i][j]+=dp[i-1][j]
由原点状态推出 -
i > 0,
dp[i][j]+=dp[i-1][j-1]若位置不在最左端,可以由左边的点推出
-
i < arrLen,
dp[i][j]+=dp[i-1][j+1].若位置不在在最右端,可以由右边的点推出
开始有一个指针在索引 0 处。
初始状态dp[0][0] = 1(由dp[i-1][j-1]可以知道需要初始化dp[0][0]),其余dp全部为0.
就这样,这道题就这么结束了,加的时候别忘记取模。
当然,这道题有一个陷阱。如果arrLen > steps, arrLen = steps+1. 因为从索引0走step步最多走到索引step,我们可以根据step的数据来减少我们的空间。按照原来的arrLen范围,我们的二维数组必爆。
const int MOD = 1e9+7;
class Solution {
public:
int numWays(int steps, int arrLen) {
int dp[505][505];
memset(dp,0,sizeof(dp));
if(arrLen > steps) arrLen = steps+1;
dp[0][0] = 1;
for(int j = 1;j <= steps;j++)
{
for(int i = 0;i < arrLen;i++)
{
dp[i][j] = dp[i][j-1];
if(i > 0) dp[i][j] = (dp[i-1][j-1]+dp[i][j])%MOD;
if(i < arrLen) dp[i][j] = (dp[i][j]+dp[i+1][j-1])%MOD;
// dp[i][j] = dp[i+1][j-1] + dp[i-1][j-1] + dp[i][j-1];
// cout<当然了,我举例这道题还是别有用心的。首先这道题很直白,很明确,适合初学dp的同学感受我说的四个步骤来完成一道dp题。其次,这道题和上面那道题有一个不同,就是我说的第四步中递推顺序的不同。
我们先来打个表,看看结果究竟是怎么被推出来的。steps=4, arrLen=5
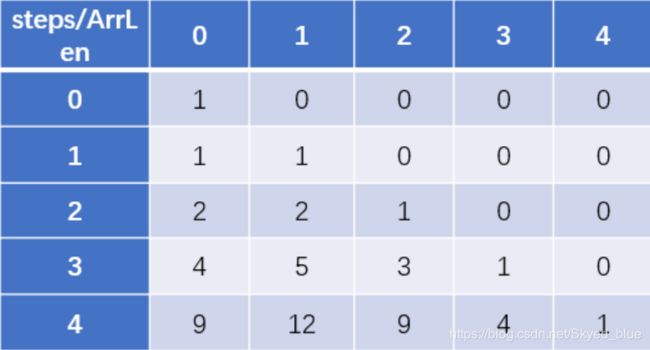
可以看到,最终结果dp[4][0] = 9是由dp[3][0]+dp[3][1]得来。
我们再看一组数据:dp[4][1] = dp[3][0]+dp[3][1]+dp[3][2]. 这表示在前4步走到1位置的结果由前3步的0,1,2位置推出。这就意味着,我们必须先得到前3步的所有结果,才能开始推前4步。所以这里的for循环只能是先行后列。
对于这种情况我喜欢称dp[i][j]中的i为主状态,j为副状态。先更新完当前主状态中所有的值才能更新下一个主状态。
关于滚动数组:
这一道题,当前状态的值只和上一行有关,这道题可以滚动。虽然它有dp[i-1][j-1]和dp[i-1][j+1],但实际上我们可以用一个临时变量记录其中一个状态,一起滚也是可以的(具体参照leetcode对这道题的题解).
对于上一题的最长公共子序列,当前值和左,上,左上有关,也可以滚动,关于左和左上的冲突可以多用一个临时变量跟着滚就好了。不过比较麻烦,能不滚就不滚。滚,乃无奈之举。
而对于有些题,当前状态的结果和之前所有行都可能有关系,或者其他比较复杂的状态转移方程就不太适合滚了(虽然有能滚的可能性)。
ok,关于dp方面就讲这么多了。对于其他的插头dp,树形dp,状压dp,数位dp等等我都没怎么学过,因为光应对比较普通的dp我都感觉很吃力,实在不想费那个脑子折腾了(hhh, 反正也不打ACM了吧)。
关于dp的例题可以看我整理的一些dp题。
https://blog.csdn.net/skyed_blue/category_9540695.html
也可以自己刷leetcode. 个人感觉leetcode的dp题挺友好,相对来说比较基础,模板题多(反正我的dp也是刷leetcode的)。
结语
终于可以写结语了。本来这篇算法基础只想随便写点方便以后复习的,没想到越写越得劲。每写一个算法都会让我回想起当初学这个算法时那个一脸懵逼和妙哉妙哉的自己。仔细回想了一下这一年多刷题的日子,其实个人感觉还是比较懒的。相对于ACM那种每天近乎8-10小时的训练,单纯靠我自己的自制力我真的做不到。而且我还比较恐慌,害怕全部身心投入进去成了打水漂,也害怕自己的脑子不够用,毕竟这是竞赛呀!而且,不得不面对现实问题:二本院校竞赛氛围不是很浓,甚至找齐队友都难。不过呢,如果真的热爱算法,乐此不疲的那种,干就完了。青春无论怎么走都会有遗憾的(说得我想恋爱了),等到以后回想起来这段日子,还会感慨一下,挺好。而且从现实角度来说,搞算法是进大厂的敲门砖。笔试,面试都会考到算法,难度范围在leetcode的easy和medium,要求手写代码,bug-free. Google面试的算法那真的就ACM比较吃香了。
我记得,当时学的第一个算法就是dfs,简直了,妙哉!之后看到各种术语:贪心,动态规划… 那时候经常在百度上搜这些名词,看百度百科,还挺激动的。每学一个算法都在感叹其妙哉!有一说一,我敲代码的样子贼帅,就是WA了或者找bug的时趴桌上挠头发的样子比较狼狈。
总之呢,洋洋洒洒写了1w多的字,算是我写过的最长的一篇blog,文章。花了大概一周多的时间。喜欢这篇blog可以关注我的博客(虽然我之后可能不会怎么更新了).https://blog.csdn.net/skyed_blue
算法生涯大概到这就结束了吧。以后就刷刷leetcode周赛步入老年生活了。
–end–