AI应用开发基础傻瓜书系列3-损失函数
Copyright © Microsoft Corporation. All rights reserved.
适用于License版权许可
更多微软人工智能学习资源,请见微软人工智能教育与学习共建社区
- Content
- 01.0-神经网络的基本工作原理
- 01.1-基本数学导数公式
- 01.2-Python-Numpy库的点滴
- 02.0-反向传播与梯度下降
- 02.1-线性反向传播
- 02.2-非线性反向传播
- 02.3-梯度下降
- 03.0-损失函数
- 03.1-均方差损失函数
- 03.2-交叉熵损失函数
- 04.0-单入单出单层-单变量线性回归
- 04.1-最小二乘法
- 04.2-梯度下降法
- 04.3-神经网络法
- 04.4-梯度下降的三种形式
- 04.5-实现逻辑非门
- 05.0-多入单出单层-多变量线性回归
- 05.1-正规方程法
- 05.2-神经网络法
- 05.3-样本特征数据的归一化
- 05.4-归一化的后遗症
- 05.5-正确的推理方法
- 05.6-归一化标签值
- 06.0-多入多出单层神经网络-多变量线性分类
- 06.1-二分类原理
- 06.2-线性二分类实现
- 06.3-线性二分类结果可视化
- 06.4-多分类原理
- 06.5-线性多分类实现
- 06.6-线性多分类结果可视化
- 07.0-激活函数
- 07.1-挤压型激活函数
- 07.2-半线性激活函数
- 07.3-用双曲正切函数分类
- 07.4-实现逻辑与门和或门
- 08.0-单入单出双层-万能近似定理
- 08.1-双层拟合网络的原理
- 08.2-双层拟合网络的实现
- 09.0-多入多出双层-双变量非线性分类
- 09.1-实现逻辑异或门
- 09.2-理解二分类的工作原理
- 09.3-非线性多分类
- 09.4-理解多分类的工作原理
- 10.0-调参与优化
- 10.1-权重矩阵初始化
- 10.2-参数调优
- 10.3-搜索最优学习率
- 10.4-梯度下降优化算法
- 10.5-自适应学习率算法
- 11.0-深度学习基础
- 11.1-三层神经网络的实现
- 11.2-验证与测试
- 11.3-梯度检查
- 11.4-手工测试训练效果
- 11.5-搭建深度神经网络框架
- 12.0-卷积神经网络
- 12.1-卷积
- 12.2-池化
- 14.1-神经网络模型概述
- 14.2-Windows模型的部署
- 14.3-Android模型的部署
第三篇:激活函数和损失函数(二)
损失函数
作用
在有监督的学习中,需要衡量神经网络输出和所预期的输出之间的差异大小。这种误差函数需要能够反映出当前网络输出和实际结果之间一种量化之后的不一致程度,也就是说函数值越大,反映出模型预测的结果越不准确。
还是拿练枪的Bob做例子,Bob预期的目标是全部命中靶子的中心,但他现在的命中情况是这个样子的:

最外圈是1分,之后越向靶子中心分数是2,3,4分,正中靶心可以得5分。
那Bob每次射击结果和目标之间的差距是多少呢?在这个例子里面,用得分来衡量的话,就是说Bob得到的反馈结果从差4分,到差3分,到差2分,到差1分,到差0分,这就是用一种量化的结果来表示Bob的射击结果和目标之间差距的方式。也就是误差函数的作用。因为是一次只有一个样本,所以这里采用的是误差函数的称呼。如果一次有多个样本,那么就要称呼这样子衡量不一致程度的函数就要叫做损失函数了。
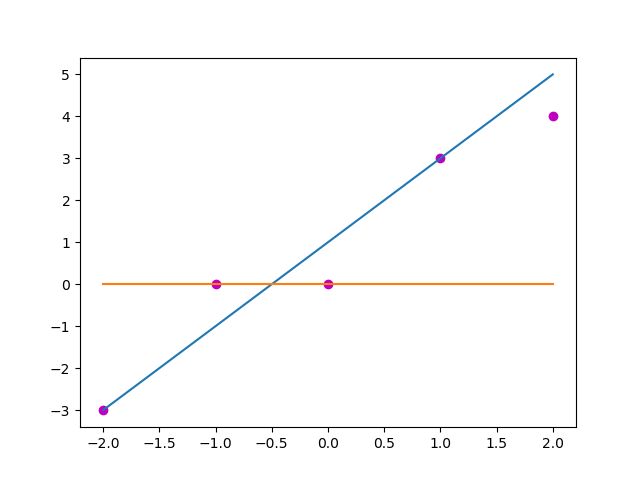
以做线性回归的实际值和预测值为例,若自变量x是[-2, -1, 0, 1, 2]这样5个值,对应的期望值y是[-3, 0, 0, 3, 4]这样的值,目前预测使用的参数是(w, b) = (2, 1), 那么预测得到的值y_ = [-3, -1, 1, 3, 5], 采用均方误差计算这个预测和实际的损失就是 ∑ I = 0 4 ( y [ i ] − y _ [ i ] ) 2 \sum_{I = 0}^{4}(y[i] - y_\_[i])^{2} ∑I=04(y[i]−y_[i])2, 也就是3。那么如果采用的参量是(0, 0),预测出来的值是[0, 0, 0, 0, 0],这是一个显然错误的预测结果,此时的损失大小就是34, 3 < 34 3 < 34 3<34, 那么(2, 1)是一组比(0, 0)要合适的参量。
那么常用的损失函数有哪些呢?
这里先给一些前提,比如神经网络中的一个神经元:

图中 z = ∑ i w i ∗ x i + b i = θ T x z = \sum\limits_{i}w_i*x_i+b_i=\theta^Tx z=i∑wi∗xi+bi=θTx, σ ( z ) \sigma(z) σ(z)是对应的激活函数,也就是说,在反向传播时梯度的链式法则中,
(1) ∂ z ∂ w i = x i \frac{\partial{z}}{\partial{w_i}}=x_i \tag{1} ∂wi∂z=xi(1)
(2) ∂ z ∂ b i = 1 \frac{\partial{z}}{\partial{b_i}}=1 \tag{2} ∂bi∂z=1(2)
(3) ∂ l o s s ∂ w i = ∂ l o s s ∂ σ ( z ) ∂ σ ( z ) ∂ z ∂ z ∂ w i = ∂ l o s s ∂ σ ( z ) ∂ σ ( z ) ∂ z x i \frac{\partial{loss}}{\partial{w_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}}\frac{\partial{z}}{\partial{w_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}}x_i \tag{3} ∂wi∂loss=∂σ(z)∂loss∂z∂σ(z)∂wi∂z=∂σ(z)∂loss∂z∂σ(z)xi(3)
(4) ∂ l o s s ∂ b i = ∂ l o s s ∂ σ ( z ) ∂ σ ( z ) ∂ z ∂ z ∂ b i = ∂ l o s s ∂ σ ( z ) ∂ σ ( z ) ∂ z \frac{\partial{loss}}{\partial{b_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}}\frac{\partial{z}}{\partial{b_i}}=\frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}} \tag{4} ∂bi∂loss=∂σ(z)∂loss∂z∂σ(z)∂bi∂z=∂σ(z)∂loss∂z∂σ(z)(4)
从公式 ( 3 ) , ( 4 ) (3),(4) (3),(4)可以看出,梯度计算中的公共项是 ∂ l o s s ∂ σ ( z ) ∂ σ ( z ) ∂ z = ∂ l o s s ∂ z \frac{\partial{loss}}{\partial{\sigma(z)}}\frac{\partial{\sigma(z)}}{\partial{z}} = \frac{\partial{loss}}{\partial{z}} ∂σ(z)∂loss∂z∂σ(z)=∂z∂loss。
下面我们来探讨 ∂ l o s s ∂ z \frac{\partial{loss}}{\partial{z}} ∂z∂loss的影响。由于梯度的计算和函数的形式是有关系的,所以我们会从常用损失函数入手来逐个说明。
常用损失函数
-
MSE (均方误差函数)
该函数就是最直观的一个损失函数了,计算预测值和真实值之间的欧式距离。预测值和真实值越接近,两者的均方差就越小。
-
想法来源
在给定一些点去拟合直线的时候(比如上面的例子),常采用最小二乘法,使各个训练点到拟合直线的距离尽量小。这样的距离最小在损失函数中的表现就是预测值和真实值的均方差的和。
-
函数形式:
l o s s = 1 2 ∑ i ( y [ i ] − a [ i ] ) 2 loss = \frac{1}{2}\sum_{i}(y[i] - a[i]) ^ 2 loss=21i∑(y[i]−a[i])2,
其中, a a a是网络预测所得到的结果, y y y代表期望得到的结果,也就是数据的标签, i i i是样本的序号。
-
反向传播:
∂ l o s s ∂ z = ∑ i ( y [ i ] − a [ i ] ) ∗ ∂ a [ i ] ∂ z \frac{\partial{loss}}{\partial{z}} = \sum_{i}(y[i] - a[i])*\frac{\partial{a[i]}}{\partial{z}} ∂z∂loss=i∑(y[i]−a[i])∗∂z∂a[i]
-
缺点:
和 ∂ a [ i ] ∂ z \frac{\partial{a[i]}}{\partial{z}} ∂z∂a[i]关系密切,可能会产生收敛速度缓慢的现象,以下图为例(激活函数为sigmoid)
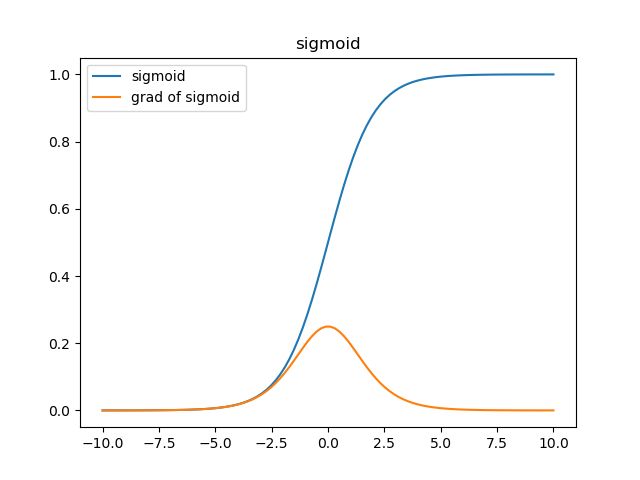
在激活函数的两端,梯度(黄色)都会趋向于0,采取MSE的方法衡量损失,在 a a a趋向于1而 y y y是0的情况下,损失loss是1,而梯度会趋近于0,在误差很大时收敛速度也会非常慢。
在这里我们可以参考activation中关于sigmoid函数求导的例子,假定x保持不变,只有一个输入的一个神经元,权重 w = l n ( 9 ) w = ln(9) w=ln(9), 偏置 b = 0 b = 0 b=0,也就是这样一个神经元:

保持参数统一不变,也就是学习率 η = 0.2 \eta = 0.2 η=0.2,目标输出 y = 0.5 y = 0.5 y=0.5, 此处输入x固定不变为 x = 1 x = 1 x=1,采用MSE作为损失函数计算,一样先做公式推导,
第一步,计算当前误差
l o s s = 1 2 ( a − y ) 2 = 1 2 ( 0.9 − 0.5 ) 2 = 0.08 loss = \frac{1}{2}(a - y)^2 = \frac{1}{2}(0.9 - 0.5)^2 = 0.08 loss=21(a−y)2=21(0.9−0.5)2=0.08
第二步,求出当前梯度
g r a d = ( a − y ) × ∂ a ∂ z ∂ z ∂ w = ( a − y ) × a × ( 1 − a ) × x = ( 0.9 − 0.5 ) × 0.9 × ( 1 − 0.9 ) × 1 = 0.036 grad = (a - y) \times \frac{\partial{a}}{\partial{z}} \frac{\partial{z}}{\partial{w}} = (a - y) \times a \times (1 - a) \times x = (0.9 - 0.5) \times 0.9 \times (1-0.9) \times 1= 0.036 grad=(a−y)×∂z∂a∂w∂z=(a−y)×a×(1−a)×x=(0.9−0.5)×0.9×(1−0.9)×1=0.036
第三步,根据梯度更新当前输入值
w = w − η × g r a d = l n ( 9 ) − 0.2 × 0.036 = 2.161 w = w - \eta \times grad = ln(9) - 0.2 \times 0.036 = 2.161 w=w−η×grad=ln(9)−0.2×0.036=2.161
第四步,计算当前误差是否小于阈值(此处设为0.001)
a = 1 1 + e − w x = 0.8967 a = \frac{1}{1 + e^{-wx}} = 0.8967 a=1+e−wx1=0.8967
l o s s = 1 2 ( a − y ) 2 = 0.07868 loss =\frac{1}{2}(a - y)^2 = 0.07868 loss=21(a−y)2=0.07868
第五步,重复步骤2-4直到误差小于阈值
作出函数图像如图所示:

可以看到函数迭代了287次从才收敛到接近0.5的程度,这比单独使用sigmoid函数还要慢了很多。
- 交叉熵函数
这个损失函数的目的是使得预测得到的概率分布和真实的概率分布尽量的接近。两个分布越接近,那么这个损失函数得到的函数值就越小。怎么去衡量两个分布的接近程度呢?这就要用到香农信息论中的内容了。两个概率分布之间的距离,也叫做KL Divergence,他的定义是这个形式的,给定离散概率分布P(x), Q(x),这两个分布之间的距离是
D K L ( P ∣ ∣ Q ) = − ∑ i P ( i ) l o g ( Q ( i ) P ( i ) ) D_{KL}(P || Q) = - \sum_{i}P(i)log(\frac{Q(i)}{P(i)}) DKL(P∣∣Q)=−i∑P(i)log(P(i)Q(i))
试想如果两个分布完全相同,那么 l o g ( Q ( i ) P ( i ) ) = 0 log(\frac{Q(i)}{P(i)}) = 0 log(P(i)Q(i))=0, 也就是两个分布之间的距离是零,如果两个分布差异很大,比如一个是 P ( 0 ) = 0.9 , P ( 1 ) = 0.1 P(0)=0.9, P(1)=0.1 P(0)=0.9,P(1)=0.1,另一个是 Q ( 0 ) = 0.1 , Q ( 1 ) = 0.9 Q(0)=0.1,Q(1)=0.9 Q(0)=0.1,Q(1)=0.9,那么这两个分布之间的距离就是0.763,如果是 Q ( 0 ) = 0.5 , Q ( 1 ) = 0.5 Q(0)=0.5,Q(1)=0.5 Q(0)=0.5,Q(1)=0.5,那么距离就是0.160,直觉上来说两个分布越接近那么他们之间的距离就是越小的,具体的理论证明参看《信息论基础》,不过为什么要选用这个作为损失函数呢?
-
从最大似然角度开始说
关于最大似然,请参看 https://www.zhihu.com/question/20447622/answer/161722019
将神经网络的参数作为 θ \theta θ,数据的真实分布是 P d a t a ( y ; x ) P_{data}(y;x) Pdata(y;x), 输入数据为 x x x,那么在 θ \theta θ固定情况下,神经网络输出 y y y的概率就是 P ( y ; x , θ ) P(y;x, \theta) P(y;x,θ),构建似然函数,
L = ∑ i l o g ( P ( y i ; x i , θ ) ) L =\sum_{i}log(P(y_i;x_i, \theta)) L=i∑log(P(yi;xi,θ)),
以 θ \theta θ为参数最大化该似然函数,即 θ ∗ = a r g m a x θ L \theta^{*} ={argmax}_{\theta}L θ∗=argmaxθL。
真实分布 P ( x i ) P(x_i) P(xi)对于每一个 ( i , x i , y i ) (i, x_i, y_i) (i,xi,yi)来说均是定值,在确定 x i x_i xi情况下,输出是 y i y_i yi的概率是确定的。在一般的情况下,对于每一个确定的输入,输出某个类别的概率是0或者1,所以可以将真实概率添加到上述式子中而不改变式子本身的意义:
θ ∗ = a r g m a x θ ∑ i P d a t a ( y i ; x i ) l o g ( P ( y i ; x i , θ ) ) \theta^{*} ={argmax}_{\theta}\sum_{i}P_{data}(y_i;x_i)log(P(y_i;x_i, \theta)) θ∗=argmaxθi∑Pdata(yi;xi)log(P(yi;xi,θ))
将 D K L D_{KL} DKL展开,得到,
D K L ( P ∣ ∣ Q ) = − ∑ i P ( i ) l o g ( Q ( i ) P ( i ) ) = ∑ i P ( i ) l o g ( P ( i ) ) − ∑ i P ( i ) l o g ( Q ( i ) ) D_{KL}(P || Q) =- \sum_{i}P(i)log(\frac{Q(i)}{P(i)}) = \sum_{i}P(i)log(P(i)) - \sum_{i}P(i)log(Q(i)) DKL(P∣∣Q)=−i∑P(i)log(P(i)Q(i))=i∑P(i)log(P(i))−i∑P(i)log(Q(i))
P ( i ) P(i) P(i)代表 P d a t a ( y i ; x i ) P_{data}(y_i;x_i) Pdata(yi;xi), Q ( i ) Q(i) Q(i)代表 P ( y i ; x i , θ ) P(y_i;x_i,\theta) P(yi;xi,θ)。
上述右侧式中第一项是和仅真实分布 P ( i ) P(i) P(i)有关的,在最小化 D K L D_{KL} DKL过程中是一个定值,所以最小化 D K L D_{KL} DKL等价于最小化 − ∑ i P ( i ) l o g ( Q ( i ) ) -\sum_{i}P(i)log(Q(i)) −∑iP(i)log(Q(i)),也就是在最大化似然函数。
-
函数形式(以二分类任务为例):
l o s s = ∑ i y ( x i ) l o g ( a ( x i ) ) + ( 1 − y ( x i ) ) l o g ( 1 − a ( x i ) ) loss = \sum_{i}y(x_i)log(a(x_i)) + (1 - y(x_i))log(1- a(x_i)) loss=i∑y(xi)log(a(xi))+(1−y(xi))log(1−a(xi))
其中, y ( x i ) y(x_i) y(xi)是真实分布, a ( x i ) a(x_i) a(xi)是神经网络输出的概率分布
-
反向传播:
∂ l o s s ∂ z = ( − y ( z ) a ( z ) + 1 − y ( z ) 1 − a ( z ) ) ∗ ∂ a ( z ) ∂ z = a ( z ) − y ( z ) a ( z ) ( 1 − y ( z ) ) ∗ ∂ a ( z ) ∂ z \frac{\partial{loss}}{\partial{z}} = (-\frac{y(z)}{a(z)} + \frac{1 - y(z)}{1 - a(z)})*\frac{\partial{a(z)}}{\partial{z}} = \frac{a(z) - y(z)}{a(z)(1-y(z))}*\frac{\partial{a(z)}}{\partial{z}} ∂z∂loss=(−a(z)y(z)+1−a(z)1−y(z))∗∂z∂a(z)=a(z)(1−y(z))a(z)−y(z)∗∂z∂a(z)
在使用sigmoid作为激活函数情况下, ∂ a ( z ) ∂ z = a ( z ) ( 1 − a ( z ) ) \frac{\partial{a(z)}}{\partial{z}} = a(z)(1-a(z)) ∂z∂a(z)=a(z)(1−a(z)),也就是说,sigmoid本身的梯度和分母相互抵消,得到,
∂ l o s s ∂ z = a ( z ) y ( z ) y ( z ) ( 1 − a ( z ) ) ∗ ∂ a ( z ) ∂ z = a ( z ) − y ( z ) \frac{\partial{loss}}{\partial{z}} = \frac{a(z)y(z)}{y(z)(1-a(z))}*\frac{\partial{a(z)}}{\partial{z}} = a(z) - y(z) ∂z∂loss=y(z)(1−a(z))a(z)y(z)∗∂z∂a(z)=a(z)−y(z)
在上述反向传播公式中不再涉及到sigmoid本身的梯度,故不会受到在误差很大时候函数饱和导致的梯度消失的影响。
总的说来,在使用sigmoid作为激活函数时,使用交叉熵计算损失往往比使用均方误差的结果要好上一些。但是,这个也并不是绝对的,需要具体问题具体分析,针对具体应用,有时需要自行设计损失函数来达成目标。
参考资料:
https://www.cnblogs.com/alexanderkun/p/8098781.html
https://www.zhihu.com/question/20447622/answer/161722019
《信息论基础》
点击这里提交问题与建议
联系我们: [email protected]
学习了这么多,还没过瘾怎么办?欢迎加入“微软 AI 应用开发实战交流群”,跟大家一起畅谈AI,答疑解惑。扫描下方二维码,回复“申请入群”,即刻邀请你入群。
