一、诊断内存的消耗
1、spark内存消耗
(1)java对象头:包含一些对象的元信息。
(2)java的String对象,比其内部的原始数据要多出四十多个字节
(3)java集合类型,
(4)元素类型为原始数据类型(如int)的集合
2、判断程序消耗了多少内存
(1)设置RDD的并行度,1:在parallelize()、textFile()等方法中传入第二额参数,设置RDD的task/partition的数量;2:在SparkConf.set()方法中设置一个参数,spark.default.parallelism,统一设置这个application的所有RDD的partitions的数量
(2)将RDD cache到内存中,调用RDD.cache().
(3)观察Driver的log,类似于“INFO BlockManagerMasterActor:Added rdd_0_1 in memory on mbk.local:50311(size:717.5kB,free:332.3MB)”的日志信息,就显示了每个partition占用了多少的内存
(4)将内存信息乘以partition数量,即可得出RDD的内存占用量
二、高性能序列化概述
1、数据序列化概述
spark默认使用了java自身提供的序列化机制,基于ObjectInputStream和OBjectOutputStream的序列化机制,但是性能比较差,速度慢,序列化之后占用空间依旧高
spark还提供了另外一种序列化机制——Kryo序列化机制,快,结果集小10倍,缺点是有些类型及时实现了Seriralizable接口,也不一定能被序列化。如果想要达到最好的性能,Kryo要求在Spark中对所有需要序列化的类型进行注册
2、使用Kryo序列化机制
(1)用SparkConf设置一个参数
new SparkConf().set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
(2)如果不预先注册序列化类的时候,Kryo保存时候都会保存类型的全限定类名名,反而栈不少内存,达不到最佳效果。Spark默认是对Scala中常用的类型自动注册了Kryo的,都在AllScalaRegistry类中。使用外部的自定义类型对象就需要对其进行注册。
(3)注册自定义类型
var counter=new Counter()
Scala版本:
val conf=new SparkConf().setMaster().setAppName()
conf.registerKryoClasses(Array(classOf[Counter]))//对Counter类进行注册
Java版本:
SparkConf conf=new SparkConf().setMaster().setAppName()
conf.registerKryoClasses(Counter.class)//对Counter类进行注册
3、优化Kryo类库的使用
(1)优化缓存大小(默认为2,最大缓存2M对象,必要时调整为10M)
如果自定义的类型本身特别大,比如超过了100个field,就回导致序列化结果对象过大,这时候就需要对Kryo本身记性优化,吟哦iKryo内部的缓存可能不够存放这么大的class对象。调用SparkConf.set()方法,设置spark.kryoserializer.buffer.mb参数的值将其调大
(2)预先注册自定义类型
上边写过的,不注册会导致权限定类名耗费大量内存
4、使用Kryo序列化类库的场景
(1)算子函数使用到了外部的大数据的情况下,如:定义了一个外部封装应用所有配置的对象,定义了一个MyConfiguration对象,包含了100m数据,在算子中用到了这个对象就适合使用该Kryo
三、优化数据结构
优化数据结构,目的是避免java语法特性中导致的额外内存的开销,比如包装类型,基于指针。主要优化算子函数,减少对内存的消耗和占用。
(1)有限使用数组及字符串,而不是集合类。也就是:有限array,而不是ArrayList,LinkedList,HashMap,既减少了额外信息的存储开销,还能使用原始数据类型(int)来存储数据而不是Integer,节省内存
(2)避免使用多层嵌套的对象结构,如:public class teacher{private List
(3)可以的话,尽量用int代替String。!spark应用中,id不要使用常用的uuid,因为无法转换为int,使用自增的id即可
四、对于多次使用的RDD进行持久化或者Checkpoint
(1)持久化
使用cache()或persist()将rdd保存在blockManager中。第二次使用的时候就可以直接从blockManager中获取rdd,而不必重新进行计算
(2)Checkpoint
上述的持久化保存在内存中,也可能有丢失的风险,所以如果为了保证高效能,就可以在第一次计算的时候放弃一些性能,对RDD进行checkpoint,持久化到磁盘中,比如hdfs中
五、使用序列化的持久化级别(先序列化再持久化)
如果RDD持久化使用的内存不是特别充足,可以使用序列化的持久化级别,使用RDD.persist(StorageLevel.MEMORY_ONLY_SER)这样的语法,可以先序列化,数据量减小之后再持久化到磁盘或内存。缺点是获取RDD时候需要反序列化,增大消耗
六、java虚拟机垃圾回收调优
首先,程序所占内存越少,垃圾回收运行次数越少
1、检测垃圾回收
(1)打印脚本(不常用)
在spark-submit脚本中,增加一个配置,--conf "spark.executor.extrajavaOptions=-verbose:gc-XX:+PrintGCDetails -XX:+PrintGCTimeStamps"。
最终会将java虚拟机的垃圾回收相关信息输出到worker日志汇总,不是driver日志中。
(2)webUI查看
当然,还可以通过4040端口观测每个stage垃圾回收情况
2、优化executor内存比例
(1)举个栗子
在默认情况下,Executor的内存空间,有60%都是个RDD进行缓存的,比如我们在执行RDD.cache()的时候,那么这个executor的RDD的partition就回用掉60%的内存来进行缓存。剩下的40%内存空间就分给了Task,存放它在运行期间动态创建的对象。在这种情况下,很可能分配各task运行期间创建的对象的内存比例有些偏小,所以导致创建的对象很快就将内存填满,结果gc就回寻找不再使用的对象进行回收。
所以task内存分配太小,会导致频繁发生gc,导致task工作线程频繁停止,降低spark性能。
解决办法:====》使用
new SparkConf().set("spark.storage.memoryFraction","0.5")即可将task内存比例提升至50%。
3、高级gc调优
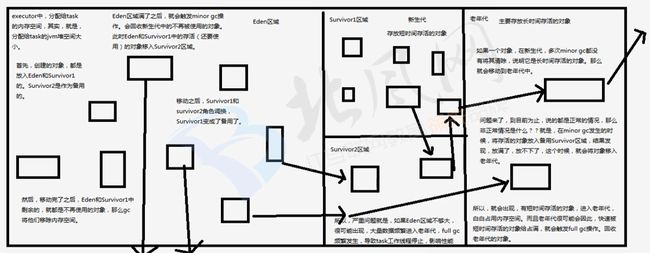
解决办法:
(1)降低spark.storage.memoryFraction的比例,给年轻带更多空间,存放短时间对象
(2)给Eden区域分配更大的空间,使用-Xmn即可,建议给Eden区域预计大小的四分之三
(3)如果使用hdfs文件,加入每个executor有4个task,每个hdfs解压缩是之前的3倍,每个hdfs大小64m,那么edgen区域的预计大小就是4*3*64M
4、对于垃圾回收的调优,尽量调节executor内存比例就可以了,疑问jvm调优非常复杂和敏感的,除非是万不得已并且对jvm技术非常了解,那么可以使用eden的调优。
七、提高并行度
1、原理
如果设置了new SparkConf().set("spark.default.parallelism","5"),所有的RDDpartition都会被设置为 5个,也就是每个RDD的数据都会被分为5分,每个partition都会启动一个task来进行计算,对于所有的算子操作,都只会使用5个task在集群中运行。所以在这个时候,集群中有10个cpucore,也只会使用5个来进行task,剩余空闲。造成资源浪费。
面对10个core,我们可以设置10个甚至20、30个task,因为task之间的执行顺序和时间是不一样的,正好10个也会造成浪费。官方建议并行度设置为core数的2~3倍,可以最高效率使用资源。
2、并行度设置方式
可以手动使用textFile()\parallelize()等方法的第二个参数设置局部并行度,也可以使用spark.default.parallelism来设置全局统一的并行度,应用于所有的RDD。
八、广播共享数据
1、问题背景
假如有一个外部配置文件对象,并且很大。假如某些算子的函数使用到了此外部数据,那么这个外部对象就回被拷贝到每一个task中,就会占用每个节点大量内存,造成大量网络IO。如果共享数据100m,6个task就会使用600M内存。
比如:在spark中仿效mapreduce的map-side join,在每个task运行的时候,吧输入的数据与一个表进行join。我们可以在运行job之前,先把表中的数据读取出来,加载的driver中,存储为ArrayList,然后在算子函数中使用其进行join操作。这种时候使用Broadcast广播,让其在每个节点中一个副本,而不是每个task一个副本。减少节点上的内存占用。
2、Broadcast广播
val broadcastConf=sc.broadcast(RDD)
节点上使用该数据的时候不需要调用RDD,而是调用broadcastConf广播副本,就可以节省内存和网络IO
九、数据本地化
1、背景
数据量巨大的时候,计算时候如果移动数据那么代价很大,所以移动代码到数据所在节点整体要快的多。因此基于数据本地化的原则来构建task调度算法。
2、数据本地化级别(基于数据距离代码的距离)
情况由好到坏:
(1)PROCESS_LOCAL:数据和计算它的代码在同一个JVM进程中
(2)NODE_LOCAL:数据和代码在同一节点上,但是不在一个进程中,比如在不容的executor进程汇总,或者数据在HDFS文件的block中
(3)NO_PREF:数据从哪里过来,最终的性能都是一样的
(4)RACK_LOCAL:数据和代码在同一个机架上
(5)ANY:数据可能在任意地方,比如其他网络环境或者其他机架上
3、数据本地化处理机制
当Task要处理的partition的数据在某一个executor中的时候,TaskSchedulerImpl首先会尽量用最好的本地化级别去启动task,也就是说尽量在哪个包含了要处理的partition的executor中,去启动task。
spark会等待一段时间,等待executor空闲出一个cpuCore,启动task实现最好的本地化级别,如果过了等待时间(该时间可以通过参数设置进行调优)。发现始终没有等待executor的core释放,就会放大一个本地化级别器尝试启动该task。
task会去调用RDD的iterator()方法,通过executor关联的blockManager,尝试获取数据,blockManager底层首先尝试从getLocal()在本地找数据,如果没有找到的话,那么使用getRemote(),通过BlockTransferService连接到有数据的blockManager来获取数据。
也就是说,task会尝试使用最好的本地化策略进行计算,就看在指定的时间里边cpu给不给机会,如果不给就到下一个等级,依次降低。
3、优化参数
设置spark.locality系列参数,来调节Spark等待task进行数据本地化的时间。spark.locality.wait(默认3000毫秒)、spark.locality.wait.node、spark.locality.wait.process、spark.locality.wait.rack,下边三个分别是局部的等待时间调整,node、process、rack可以时间越来越短,rack可以设置为1s
十、reduceByKey和groupByKey
1、问题背景
一般情况下,reduceByKey的操作都是可以使用groupByKey().map()来进行替代操作的。但是 groupByKey不会进行本地聚合,原封不动的将ShuffleMapTask的输出拉渠道ResultTask的内存中。因为reduceByKey首先会在map端进行本地的combine,可以大大减要传输到reduce的数据量,减少网络IO,只有在reduceByKey解决不了类似问题的时候才会使用groupByKey().map()来进行代替。
没了!
十一、Shuffle性能优化
在现实场景中,百分之九十的调优情况都是发生在shuffle阶段,所以此类调优非常重要。
1、consolidation机制(合并)
没有开启consolidation机制的时候,shuffle write的性能比较底下,并且会影响到shuffle read的性能。因为shufflemap创建的磁盘文件太多,导致shufflewrite要耗费大量性能在磁盘文件的创建以及磁盘的io上。对于shuffle read也是一样的。每一个result task可能都需要通过磁盘io读取多个文件的数据,都只是shuffle read,性能可能受到影响。
假如有100个shuffle map task,下一个stage总共有1000个resultTask,导致每个节点上的磁盘文件的数量就是100*1000。
使用new SparkConf().set("spark.shuffle.consolidateFiles",true),开启shuffleblock file的合并,默认为false。
2、consolidation局部调优
开启consolidation机制之后,shufflemap端写磁盘的数量大大减少,上述的例子中假如有10个cpuCore,每个节点的磁盘总数就是10*1000个。此外,result task拉去时候的磁盘io也变少了,每个result task只要从每个节点上拉取cpuCore数量的磁盘文件即可。
上述每次只能拉取指定缓存大小的数据量,拉取完后进行聚合处理,然后在进行继续拉取。如果内存不大的话就可以适当加大,拉取的次数也就会变少。map端的bucket缓存也可以适当的提高大小,这样溢出到磁盘的次数就回变少了。
spark.reducer.maxSizeInFlight:reduce task的拉取缓存,默认48M
spark.shuffle.file.buffer:map task的写磁盘缓存,默认为32k
reduce task拉取数据的时候,坑你会遇到map task那里的executor的jvm正在full gc,此事后就回出现正常工作线程的停止,一段时间之后full gc还没有完成就回导致文件没有拉取到,可以适当调整拉取失败的最大重试次数,以及拉取是被的重试间隔时间。
spark.shuffle.io.maxRetries:拉取失败的最大重试次数,默认3次
spark.shuffle.io.retryWait:拉取失败的重试间隔,默认5s
执行reduce task的executor中,有一部分内存用来汇聚各个reducetask拉取的数据,放入map中进行聚合,如果数据太大就回溢出到磁盘上,可以适当调大溢出比例到0.3~0.4。
spark.shuffle.memoryFraction:用于reduce端聚合的内存比例,默认为0.2,超过比例就回溢出到磁盘上.
很有可能gc没有调优号,每次gc都超过1mine,默认拉取时间3*5=15s之后导致很多数据拉取失败,就会包shuffle output file lost,然后DACScheduler会重试task和stage,甚至会导致application失败。