AMDP & XLSX Workbench的使用
正文
本文介绍了我和同事通过使用AMDP + XLSX Workbench缩短报表开发周期、分离数据查询处理逻辑和前端展示工作的经验。欢迎讨论。
前言
最近接到了一套人力资源报表的开发需求,需要以EXCEL表格的方式输出,且包含大量sheet页,每个sheet相当于一个独立的报表。
这种情况下,如果让同一个人开发所有内容,将会花费较长的开发周期,因此,要将程序分解成若干个部分,最好每个报表(sheet)都是一个独立的子模块,让不同的人同时开发。
对于这类报表,我们之前的做法是,使用OLE输出EXCEL文件,在report程序中,使用逻辑数据库获取数据,引入常用的OLE方法,为每个sheet创建一个include文件,实现不同sheet的代码分离。
代码类似这样:
REPORT zhr_report .
************************************************************************
* INCLUDES
************************************************************************
INCLUDE zhr_report_top. "//数据定义
INCLUDE zhr_report_s01. "//选择屏幕```````````
INCLUDE z_ole_excel_hr. "//通用EXCEL操作子程序
INCLUDE zhr_report_m01. "//事件
INCLUDE zhr_report_f01. "//通用模块
INCLUDE zhr_report_ex01. "//Sheet1
INCLUDE zhr_report ex02. "//Sheet2
INCLUDE zhr_report_ex03. "//Sheet3
INCLUDE zhr_report_ex04. "//Sheet4
INCLUDE zhr_report_ex05. "//Sheet5
示意图:
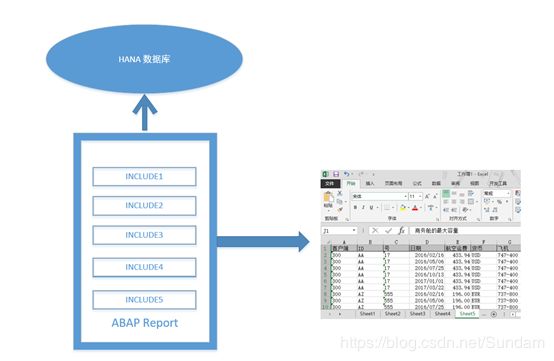
通过将通用的OLE方法封装到一个包含文件中,并使sheet页的处理放到不同的包含文件,可以使对它们的同时编辑成为可能。但是,这种做法也是有问题的:
- 包含文件不是单独的程序,这意味着只要有一个include文件中有语法错误,语法检查时就会给出提示,从而无法激活整个程序。
- 命名空间相同,这意味着定义子程序或FORM名时,很容易发生冲突
- 只能通过增加包含文件实现程序的横向扩展,较难实现程序的纵向扩展。通用部分一旦确定,再想修改会比较困难。
- OLE的性能较差。
为了解决这些问题,我们引入了AMDP + XLSX Workbench的报表开发模式。
改进后的模式示意图:
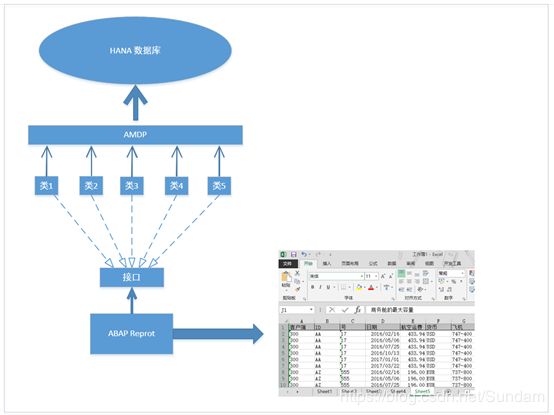
名词解释
AMDP
全称ABAP-Managed Database Procedure,一种ABAP on HANA的实现方式,提供了在ABAP中运行SQL Script的可能,并且与ABAP中的类和数据类型有良好的集成。
XLSX Workbench
一种可视化表单生成工具,相比复杂的OLE,可以用少量代码+一些拖拽和配置来生成EXCEL报表,性能更好。按XLSX Workbench的文档介绍,它有九大特性:
- 无需ABAP编程技能
- 可视化设计方式
- 高性能
- 支持后台处理
- 强大的表单格式特性支持
- 支持公式
- 支持图片
- 支持图表
- 支持树
代码例子
注意,本部分内容会假设读者已经有使用AMDP的XLSX Workbench的初步经验(至少是能输出Hello World的水平)。如果不是这样的话,可能会对其中的某些内容感到困惑。
1,首先,创建一个接口ZIF_XLSX_REPORT。
INTERFACE zif_xlsx_report
PUBLIC .
METHODS get_dataCHANGING
!data TYPE sflight_t
RAISING
cx_amdp_error .
ENDINTERFACE.
接口包含一个get_data方法,方法有一个参数data,它数据类型,即为将要输出给XLSX Workbench表单的的数据类型。
2,为接口创建实现类。
为接口创建一个实现类,在方法ZIF_XLSX_REPORT~GET_DATA中调用AMDP类方法,进行数据处理后,将得到的数据填充进chaging参数data中。
CLASS zcl_xlsx_report1 DEFINITION
PUBLIC
FINAL
CREATE PUBLIC .
PUBLIC SECTION.
INTERFACES zif_xlsx_report .
PROTECTED SECTION.
PRIVATE SECTION.
ENDCLASS.
CLASS ZCL_XLSX_REPORT1 IMPLEMENTATION.
* ---------------------------------------------------------------------------------------+
* | Instance Public Method ZCL_XLSX_REPORT1->ZIF_XLSX_REPORT~GET_DATA
* +-------------------------------------------------------------------------------------------------+
* | [<-->] DATA TYPE SFLIGHT_T
* | [!CX!] CX_AMDP_ERROR
* +--------------------------------------------------------------------------------------
METHOD zif_xlsx_report~get_data.
"调用AMDP类的方法
"数据处理
ENDMETHOD.
ENDCLASS.
3,在report程序中调用各个实现类。
这是关键的一步:在report程序中动态地获取全部实现类,并依次实例化、调用其接口方法。
CONSTANTS: c_interface TYPE seoclsname VALUE 'ZIF_XLSX_REPORT'.
TRY.
DATA(gt_classes) = cl_sic_configuration=>get_classes_for_interface( c_interface ).
CATCH cx_class_not_existent .
ENDTRY.
LOOP AT gt_classes INTO DATA(gs_class).
TRY .
CREATE OBJECT go_ref TYPE (gs_class-clsname).
CATCH cx_sy_create_object_error.
ENDTRY.
IF go_ref IS BOUND.
go_ref->get_data( CHANGING data = g_data_structure ).
ENDIF.
ENDLOOP.
- 由于XLSX Workbench中的一个表单在同一时间只能由一个人编辑,对于多sheet页的表格,无法让两个人并行开发表单。但是,因为表单独立于ABAP 程序,二者只需要通过约定好的内表结构(在示例中是SFLIGHT_T)通信。因此,可以在约定好通信结构的前提下,由一个人进行XLSX Workbench中表单的组件编辑、上下文绑定等工作,另一个(或多个)人进行数据逻辑处理工作。如果在引入了HANA开发人员,还可以把主要逻辑下推至HANA,从而使多人同时在不同层级上开发同一个套表,以提高总体开发速度。
- 将每个sheet页写成一个类,所有类继承同一个接口,在report程序中动态地调用,可以将报表主程序的代码稳定下来,实现程序的解耦。不同的类之间也是个例的,可以方便地进行单独的单元测试,而不会在语法检查时受到其他人的开发内容的干扰。
- 相比于本文开头提到的INCLUDE的方式,使用面向对象的新开发模式不仅提供了更好的横向扩展能力(只要增加新的实现类和结构字段即可实现数据处理逻辑和报表内容的扩展),而且也提供了更好的纵向扩展能力,可以通过面向对象的强大特性——继承——来实现对报表中相似部分进行抽象整合。
注意事项
总结了几点我们在实际开发中的经验,以供参考。
AMDP与SELECT-OPTIONS
细心的读者可能已经注意到上文的示例代码中并未处理选择屏幕这一关键问题。在Open SQL中我们可以很方便地直接使用range table。而在AMDP中使用它话需要一点点额外的代码:
可以通过CL_SHDB_SELTAB=>COMBINE_SELTABS( )来将选择屏幕的输入条件转换为AMDP中的SQL Script中的WHERE条件字符串,并使用APPLY_FILTER函数应用这一条件,具体的例子:

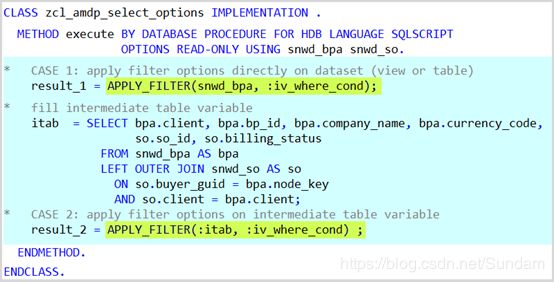
异常处理
在本文介绍的开发模式下,HANA视图、XLSX Workbench表单和ABAP类是可以并行开发的,这意味着开发阶段的HANA视图可能处于不稳定的状态。ABAP开发者应注意在AMDP方法中显式地声明异常、并在调用它时进行处理。不然会很容易遇到程序dump的情况:)
自建结构/表命名
无论是AMDP方法还是XLSX Workbench表单,在实践中都需要自建结构/表来接收数据。在开发内容分离的情况下,作为通信定义的结构/表类型的命名尤其重要。应当有一套合理的规则来为它们以及其中的字段命名。特别是XLSX Workbench表单的参数结构,在表单复杂的情况下,参数结构同样会是复杂的深度结构,而且XLSX Workbench的组件自动生成功能会以ABAP结构名为组件命名。如果命名不当的话,将会给后续的开发和沟通带来相当的负担。
另外,创建XLSX Workbench上下文时,如选择自动创建,则生成的组件名和描述会与数据字典中定义的数据名与描述一致。如果定义时能仔细填入这些信息,对后续的工作很有帮助。
模板处理
上传模板至XLSX Workbench后,建议首先对空模板进行测试输出,确认无误后,再进行context和template的绑定等工作。因为有时导入的模板也许会出现兼容问题,在输出报表时会提示文件错误。较早地发现、解决这种问题,可以避免后期一些无谓的工作。
XLSX Workbench设置
在使用XLSX Workbench的过程中,点击鼠标是一项略显繁琐的工作,建议把在配置选项中将确认弹窗关掉,以减轻手指负担:

大报表的列修改问题
报表中增加列、减少列是常见的需求,在使用XLSX Workbench的时候,如果采取了简单表的输出方式,那么插入或删除新列时,就要把这个新列以右的全部列重新绑定至新位置。
在报表总列数较小的情况下,这很容易做到。但某些报表的列数较多,如我们开发的系统使用情况表,约有167列,需求变更的内容是在第5行新增一列,则意味着要重新绑定162个context value,这是件麻烦的工作。为了避免这种情况的发生,在表单的列数较多时,建议使用动态列或其它动态方式实现对表单内容的填充,以降低变更成本。