OpenCV-Python (官方)中文教程(部分一)
官网链接(英文版):https://docs.opencv.org/4.1.1/d6/d00/tutorial_py_root.html
第一章. OpenCV简介
了解如何在计算机上设置OpenCV-Python!
1.OpenCV-Python教程简介
1.1 OpenCV
OpenCV是由Gary Bradsky于1999年在Intel公司创建的,第一次发布是在2000年。瓦迪姆·皮萨列夫斯基(Vadim Pisarevsky)加入加里·布拉斯基(Gary Bradsky),管理英特尔俄罗斯软件OpenCV团队。2005年,OpenCV被用于Stanley,这款车赢得了美国国防部高级研究计划局2005年的重大挑战。后来,在Gary Bradsky和Vadim Pisarevsky领导的柳树车库的支持下,项目继续积极发展。OpenCV现在支持大量与计算机视觉和机器学习相关的算法,并且正在日益扩展。
OpenCV支持多种编程语言,如c++、Python、Java等,并且可以在不同的平台上使用,包括Windows、Linux、OS X、Android和iOS。基于CUDA和OpenCL的高速GPU操作接口也在积极开发中。
OpenCV-Python是OpenCV的Python API,结合了OpenCV c++ API和Python语言的最佳特性。
1.2 OpenCV-Python
OpenCV-Python是一个用于解决计算机视觉问题的Python绑定库。
Python是由Guido van Rossum开发的一种通用编程语言,由于其简单性和代码可读性,它很快就变得非常流行。它使程序员能够在不降低可读性的情况下用更少的代码行来表达思想。
与C/ c++这样的语言相比,Python要慢一些。也就是说,使用C/ c++可以轻松地扩展Python,这允许我们用C/ c++编写计算密集型代码,并创建可以用作Python模块的Python包装器。这给了我们两个好处:首先,代码和原始的C/ c++代码一样快(因为它是在后台工作的实际c++代码);其次,用Python编写代码比用C/ c++更容易。OpenCV-Python是原始OpenCV c++实现的Python包装器。
OpenCV-Python使用Numpy,它是一个高度优化的库,用于使用matlab风格的语法进行数值操作。所有的OpenCV数组结构都被转换为Numpy数组和从Numpy数组转换而来。这也使得与其他使用Numpy(如SciPy和Matplotlib)的库集成更加容易。
1.3 OpenCV-Python教程
OpenCV引入了一组新的教程,将指导您了解OpenCV- python中可用的各种函数。本指南主要关注OpenCV 3.x版本(尽管大多数教程也适用于OpenCV 2.x)。
建议您具备Python和Numpy的基础知识,因为本指南不涉及它们。要使用OpenCV-Python编写优化代码,必须精通Numpy。
本教程最初由Abid Rahman K.发起,是Alexander Mordvintsev指导下的谷歌Summer of Code 2013项目的一部分。
由于OpenCV是一个开源项目,所以欢迎所有人对这个库、文档和教程做出贡献。如果您在本教程中发现任何错误(从一个小的拼写错误到代码或概念上的严重错误),请随意通过在GitHub中克隆OpenCV并提交pull请求来纠正它。OpenCV开发人员将检查你的拉请求,给你重要的反馈(一旦它通过审查员的批准),它将被合并到OpenCV中,您将成为一个开源贡献者。
随着OpenCV-Python中添加了新的模块,本教程将不得不进行扩展。如果您熟悉某个特定的算法,并且能够编写一个教程,包括算法的基本理论和显示示例用法的代码,请这样做。记住,我们一起可以使这个项目取得巨大的成功!!
1.4附加资源
- A Quick guide to Python - A Byte of Python
- Basic Numpy Tutorials
- Numpy Examples List
- OpenCV Documentation
- OpenCV Forum
2.在Windows中安装OpenCV-Python
https://docs.opencv.org/3.4/d5/de5/tutorial_py_setup_in_windows.html
3.在Fedora中安装OpenCV-Python
https://docs.opencv.org/3.4/dd/dd5/tutorial_py_setup_in_fedora.html
4.在Ubuntu中安装OpenCV-Python
OpenCV-Python只需要Numpy(以及其他依赖项,稍后我们将看到)。但是在本教程中,我们还使用Matplotlib来实现一些简单和良好的绘图目的(与OpenCV相比,我感觉好多了)。Matplotlib是可选的,但强烈推荐使用。类似地,我们还将看到交互式Python终端IPython,这也是强烈推荐的。
4.1从预先构建的二进制文件安装OpenCV-Python
这种方法最适合只用于编程和开发OpenCV应用程序。
在终端(作为根用户)使用以下命令安装python-opencv包。
$ sudo apt-get install python-opencv在Python终端中打开Python IDLE(或IPython)并输入以下代码。
import cv2 as cv
print(cv.__version__)如果结果打印出来没有任何错误,恭喜!!您已经成功安装了OpenCV-Python。
这很容易。但这里有个问题。Apt存储库可能不总是包含OpenCV的最新版本。例如,在编写本教程时,apt存储库包含2.4.8,而最新的OpenCV版本是3.x。对于Python API,最新版本总是包含更好的支持和最新的bug修复。
因此,获取最新的源代码是下一个方法,即从源代码编译。同样,在某个时候,如果你想为OpenCV做贡献,你需要这个。
4.2从源代码构建OpenCV
从源代码编译一开始可能有点复杂,但是一旦您成功了,就没有什么复杂的了。
首先,我们将安装一些依赖项。有些是必需的,有些是可选的。如果不需要,可以跳过可选的依赖项。
(1).需要建立依赖关系
我们需要CMake来配置安装,GCC用于编译,Python-devel和Numpy用于构建Python绑定等等。
sudo apt-get install cmake
sudo apt-get install gcc g++
支持python2:
sudo apt-get install python-dev python-numpy
支持python3:
sudo apt-get install python3-dev python3-numpy接下来我们需要GTK支持的GUI功能,相机支持(v4l),媒体支持(ffmpeg, gstreamer)等。
sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install libgstreamer-plugins-base1.0-dev libgstreamer1.0-dev
支持gtk2:
sudo apt-get install libgtk2.0-dev
支持gtk3:
sudo apt-get install libgtk-3-dev(2).可选依赖关系
以上的附件足以在你的Ubuntu机器上安装OpenCV。但是根据您的需求,您可能需要一些额外的依赖项。下面给出了这些可选依赖项的列表。
OpenCV支持PNG、JPEG、JPEG2000、TIFF、WebP等图像格式。但它可能有点旧了。如果希望获得最新的库,可以安装这些格式的系统库的开发文件。
sudo apt-get install libpng-dev
sudo apt-get install libjpeg-dev
sudo apt-get install libopenexr-dev
sudo apt-get install libtiff-dev
sudo apt-get install libwebp-dev注意:如果你使用Ubuntu 16.04,你也可以安装libjasper-dev来增加对JPEG2000格式的系统级支持。
(3).下载OpenCV
从OpenCV的GitHub库下载最新的源代码。(如果你想为OpenCV做贡献,选择这个。为此,您需要首先安装Git)
$ sudo apt-get install git
$ git clone https://github.com/opencv/opencv.git它将在当前目录中创建一个文件夹“opencv”。克隆可能需要一些时间取决于你的互联网连接。
现在打开一个终端窗口并导航到下载的“opencv”文件夹。创建一个新的“构建”文件夹并导航到它。
$ mkdir build
$ cd build(4).配置和安装
现在我们有了所有需要的依赖项,让我们安装OpenCV。安装必须配置CMake。它指定要安装哪些模块、安装路径、要使用哪些附加库、是否要编译文档和示例等。大部分工作都是使用配置良好的默认参数自动完成的。
下面的命令通常用于配置OpenCV库构建(从build文件夹执行):
$ cmake ../
OpenCV默认假定“Release”构建类型和安装路径是“/usr/local”。有关CMake选项的更多信息,请参考OpenCV c++
编译指南:
你应该看到这些行在你的CMake输出(他们意味着Python是正确的发现):
-- Python 2:
-- Interpreter: /usr/bin/python2.7 (ver 2.7.6)
-- Libraries: /usr/lib/x86_64-linux-gnu/libpython2.7.so (ver 2.7.6)
-- numpy: /usr/lib/python2.7/dist-packages/numpy/core/include (ver 1.8.2)
-- packages path: lib/python2.7/dist-packages
--
-- Python 3:
-- Interpreter: /usr/bin/python3.4 (ver 3.4.3)
-- Libraries: /usr/lib/x86_64-linux-gnu/libpython3.4m.so (ver 3.4.3)
-- numpy: /usr/lib/python3/dist-packages/numpy/core/include (ver 1.8.2)
-- packages path: lib/python3.4/dist-packages
现在使用“make”命令构建文件,并使用“make install”命令安装文件。
$ make
# sudo make install安装结束。所有文件都安装在“/usr/local/”文件夹中。打开终端并尝试导入“cv2”。
import cv2 as cv
print(cv.__version__)第二章. OpenCV 中的 Gui 特性
5.图片
5.1读入图像
使用函数 cv2.imread() 读入图像。这幅图像应该在此程序的工作路径(相对路径), 或者给函数提供完整路径,第二个参数是要告诉函数应该如何读取这幅图片。
• cv2.IMREAD_COLOR:读入一副彩色图像.图像的透明度会被忽略,这是默认参数.
• cv2.IMREAD_GRAYSCALE:以灰度模式读入图像.
• cv2.IMREAD_UNCHANGED:读入一幅图像,并且包括图像的 alpha.
import cv2
img = cv2.imread('messi5.jpg',0)警告:就算图像的路径是错的,OpenCV 也不会提醒你的,但是当你使用命令print(img)时得到的结果是None。
5.2显示图像
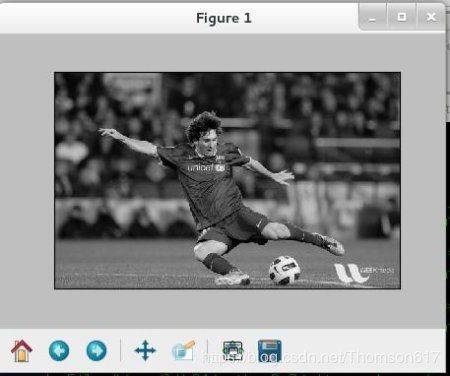
使用函数 cv2.imshow() 显示图像。窗口会自动调整为图像大小。第一 个参数是窗口的名字,其次才是我们的图像。你可以创建多个窗口,只要你喜欢,但是必须给他们不同的名字。
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()窗口屏幕截图将会像以下的样子 (in Fedora-Gnome machine):

cv2.waitKey() 是一个键盘绑定函数。需要指出的是它的时间尺度是毫秒级。函数等待特定的几毫秒,看是否有键盘输入。特定的几毫秒之内,如果按下任意键,这个函数会返回按键的 ASCII 码值,程序将会继续运行;如果没有键盘输入,返回值为 -1;如果我们设置这个函数的参数为 0,那它将会无限期的等待键盘输入。它也可以被用来检测特定键是否被按下,例如按键 a 是否被按下。
cv2.destroyAllWindows() 可以轻易删除任何我们建立的窗口。如果 你想删除特定的窗口可以使用 cv2.destroyWindow(),在括号内输入你想删 除的窗口名。
建 议:一种特殊的情况是,你也可以先创建一个窗口,之后再加载图像。这种情况下,你可以决定窗口是否可以调整大小。使用的函数是cv2.namedWindow()。初始设定函数标签是cv2.WINDOW_AUTOSIZE。但是如果你把标签改成cv2.WINDOW_NORMAL,你就可以调整窗口大小了。当图像维度太大,或者要添加轨迹条时,调整窗口大小将会很有用。
代码如下:
cv2.namedWindow('image', cv.WINDOW_NORMAL)
cv2.imshow('image',img)
cv2.waitKey(0)
cv2.destroyAllWindows()5.3保存图像
使用函数 cv2.imwrite() 来保存一个图像。首先需要一个文件名,之后才是你要保存的图像。
cv2.imwrite('messigray.png',img)总结:
下面的程序将会加载一个灰度图,显示图片,按下’s’键保存后退出,或者 按下 ESC 键退出不保存。
import cv2
img = cv2.imread('messi5.jpg', 0)
cv2.imshow('image', img)
k = cv2.waitKey(0)
if k == 27: # wait for ESC key to exit
cv2.destroyAllWindows()
elif k == ord('s'): # wait for 's' key to save and exit
cv2.imwrite('messigray.png', img)
cv2.destroyAllWindows()警告:如果是Windows64 位系统,需将 k = cv2.waitKey(0) 这行改成k = cv2.waitKey(0)&0xFF
5.4使用 Matplotlib
Matplotib 是 python 的一个绘图库,里头有各种各样的绘图方法。之后 会陆续了解到。现在,你可以学习怎样用 Matplotib 显示图像。你可以放大,保存图像等等。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg',0)
plt.imshow(img, cmap = 'gray', interpolation = 'bicubic')
plt.xticks([]), plt.yticks([]) # to hide tick values on X and Y axis
plt.show()窗口截屏如下:
参见:Matplotib 有多种绘图选择。具体可以参见 Matplotib docs。我们也会陆续了解一些
注意:彩色图像使用 OpenCV 加载时是 BGR 模式。但是 Matplotib 是 RGB 模式。所以彩色图像如果已经被 OpenCV 读取,那它将不会被 Matplotib 正 确显示。具体细节请看练习
更多资源:Matplotlib Plotting Styles and Features
当你用 OpenCV 加载一个彩色图像,并用 Matplotib 显示它时会遇 到一些困难。请阅读this discussion并且尝试理解它。
6.视频
6.1用摄像头捕获视频
我们经常需要使用摄像头捕获实时图像。OpenCV 为这中应用提供了一个非常简单的接口。让我们使用摄像头来捕获一段视频,并把它转换成灰度视频 显示出来。从这个简单的任务开始吧。
为了获取视频,你应该创建一个 VideoCapture 对象。他的参数可以是设备的索引号,或者是一个视频文件。设备索引号就是在指定要使用的摄像头。 一般的笔记本电脑都有内置摄像头。所以参数就是 0。你可以通过设置成 1 或 者其他的来选择别的USB摄像头。之后你就可以一帧一帧的捕获视频了。但是最后别忘了停止捕获视频。
import cv2
cap = cv2.VideoCapture(0)
while (cap.isOpened()):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()cap.read() 返回一个布尔值(True/False)。如果帧能够正确读取, 就是 True。所以最后你可以通过检查返回值来查看视频文件是否已经到了结尾。
有时 cap 可能不能成功的初始化摄像头设备。这种情况下上面的代码会报错。你可以使用 cap.isOpened(),来检查是否成功初始化了。如果返回值是 True,那就没有问题。否则就要使用函数 cap.open()。
你可以使用函数 cap.get(propId) 来获得视频的一些参数信息。 这里 propId 有很多可选整数值(见源码)。每一个数代表视频的一个属性,部分值如下所示:
CAP_PROP_POS_MSEC = 0 #视频文件的当前位置(毫秒)
CAP_PROP_POS_FRAMES = 1 #基于帧的索引,下一步解码/捕获。
CAP_PROP_POS_AVI_RATIO = 2 #视频文件的相对位置:0 -开始,1 -结束
CAP_PROP_FRAME_WIDTH = 3 #视频流中帧的宽度
CAP_PROP_FRAME_HEIGHT = 4 #视频流中帧的高度
CAP_PROP_FPS = 5 #帧频
CAP_PROP_FOURCC = 6 #编解码器的四字符代码
CAP_PROP_FRAME_COUNT = 7 #视频文件中的帧数
CAP_PROP_FORMAT = 8 #retrieve()返回的Mat对象的格式
CAP_PROP_MODE = 9 #后端特定值,指示当前捕获模式
CAP_PROP_BRIGHTNESS = 10 #图像亮度(仅适用于相机)
CAP_PROP_CONTRAST = 11 #图像的对比度(仅适用于相机)
CAP_PROP_SATURATION = 12 #图像饱和度(仅适用于相机)
CAP_PROP_HUE = 13 #图像色调(仅供相机使用)
CAP_PROP_GAIN = 14 #图像的增益(仅适用于相机)
CAP_PROP_EXPOSURE = 15 #曝光(仅对相机)
CAP_PROP_CONVERT_RGB = 16 #布尔标志,指示图像是否应该转换为RGB
CAP_PROP_WHITE_BALANCE_BLUE_U = 17 #目前不支持的
CAP_PROP_RECTIFICATION = 18 #立体声摄像机校正标志(注意:目前仅支持DC1394 v2.x后端)
...其中的一些值可以用 cap.set(propId,value) 来修改,value 就是你想要设置的新值。
例如,使用 cap.get(3) 和 cap.get(4) 来查看每一帧的宽和高。 默认情况下得到的值是 640X480。但是我可以使用 ret=cap.set(3,320) 和 ret=cap.set(4,240) 来把宽和高改成 320X240。
注意:当你的程序报错时,你首先应该检查的是你的摄像头是否能够在其他程序中正常工作(比如 linux 下的 Cheese)。
6.2从文件中播放视频
与从摄像头中捕获一样,你只需要把设备索引号改成视频文件的名字。在播放每一帧时,使用 cv2.waiKey() 设置适当的持续时间。如果太低视频就会播放的非常快,如果太高就会播放的很慢(可以使用这种方法控制视频的播放速度)。通常情况下25 毫秒就可以了。
注意:你应该确保你已经装了合适版本的 ffmpeg 或者 gstreamer。
6.3保存视频
在我们捕获视频,并对每一帧都进行加工之后我们想要保存这个视频。对于图片很简单,只需要使用 cv2.imwrite()。但对于视频来说就要多做点工 作。
这次我们要创建一个 VideoWriter 的对象。我们应该确定一个输出文件 的名字。接下来指定 FourCC 编码(下面会介绍)。播放频率和帧的大小也都 需要确定。最后一个是 isColor 标签。如果是True,每一帧就是彩色图,否则就是灰度图。
FourCC 就是一个 4 字节码,用来确定视频的编码格式。可用的编码列表可以从fourcc.org查到。这是平台依赖的。下面是一些常用的编码器:
- In Fedora: DIVX, XVID, MJPG, X264, WMV1, WMV2. (XVID和WMV1更可取。MJPG的结果是大尺寸的视频。X264提供非常小的视频)
- In Windows: DIVX (更多有待测试和添加)
- In OSX :
FourCC 码以下面的格式传给程序,以 MJPG 为例:
cv2.VideoWriter_fourcc(*'MJPG') 或 cv2.cv.FOURCC('M','J','P','G') 或 cv2.cv.FOURCC(*'MJPG')。
下面的代码是从摄像头中捕获视频,沿水平方向旋转每一帧并保存它:
import cv2
cap = cv2.VideoCapture(0)
# Define the codec and create VideoWriter object
fourcc = cv2.VideoWriter_fourcc(*'XVID')
out = cv2.VideoWriter('output.avi', fourcc, 20.0, (640, 480))
while (cap.isOpened()):
ret, frame = cap.read()
if ret == True:
frame = cv2.flip(frame, 0)
# write the flipped frame
out.write(frame)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
break
cap.release() # Release everything if job is finished
out.release()
cv2.destroyAllWindows()注意:使用XVID保存avi视频时播放无法显示时间,只能播放不能快进倒退等操作;但用WMV1保存wmv视频时可快进倒退(在Windows10及Ubuntu系统中亲测有效)
7.OpenCV中的绘图函数
• 学习使用 OpenCV 绘制不同几何图形
• 你将会学习到这些函数:
cv2.line(),cv2.circle(),cv2.rectangle(),cv2.ellipse(),cv2.putText() 等。
上面所有的这些绘图函数需要设置下面这些参数:
• img:你想要绘制图形的那幅图像。
• color:形状的颜色。以 RGB 为例,需要传入一个元组,例如:(255,0,0)代表蓝色。对于灰度图只需要传入灰度值。
• thickness:线条的粗细。如果给一个闭合图形设置为 -1,那么这个图形 就会被填充。默认值是 1.
• linetype:线条的类型,8 连接,抗锯齿等。默认情况是 8 连接。cv2.LINE_AA为抗锯齿,这样看起来会非常平滑。
7.1画线
要画一条线,你只需要告诉函数这条线的起点和终点。我们下面会画一条 从左上方到右下角的蓝色线段。
import numpy as np
import cv2 as cv
# Create a black image
img = np.zeros((512,512,3), np.uint8)
# Draw a diagonal blue line with thickness of 5 px
cv.line(img,(0,0),(511,511),(255,0,0),5)7.2画矩形
要画一个矩形,你需要告诉函数的左上角顶点和右下角顶点的坐标。这次我们会在图像的右上角话一个绿色的矩形:
cv2.rectangle(img,(384,0),(510,128),(0,255,0),3)7.3画圆
只需要指定圆的中心点坐标和半径大小。我们在上面的矩形中画一个圆:
cv2.circle(img,(447,63),63,(0,0,255),-1)7.4画椭圆
画椭圆比较复杂,我们要多输入几个参数。一个参数是中心点的位置坐标。 下一个参数是长轴和短轴的长度。椭圆沿逆时针方向旋转的角度。椭圆弧演 顺时针方向起始的角度和结束角度,如果是 0 或 360,就是整个椭圆。查看 cv2.ellipse() 可以得到更多信息。下面的例子是在图片的中心绘制半个椭圆。
cv2.ellipse(img,(256,256),(100,50),0,0,180,255,-1)椭圆函数中的角度不是我们的圆形角度。更多细节请查看讨论
7.5画多边形
画多边形,需要指点每个顶点的坐标。用这些点的坐标构建一个大小等于行数 X1X2 的数组,行数就是点的数目。这个数组的数据类型必须为 int32。 这里画一个黄色的具有四个顶点的多边形。
pts=np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)
# 这里 reshape 的第一个参数为-1, 表明这一维的长度是根据后面的维度计算出来的。
pts=pts.reshape((-1,1,2))注意:如果第三个参数是 False,我们得到的多边形是不闭合的(首尾不相 连)。
cv2.polylines() 可以被用来画很多条线。只需要把要画的线放在一 个列表中,将这个列表传给函数就可以了。每条线都会被独立绘制。这会比用 cv2.line() 一条一条的绘制要快一些。
7.6在图片上添加文字
转存失败重新上传取消
![]()
要在图片上绘制文字,你需要设置下列参数:
• 你要绘制的文字
• 你要绘制的位置坐标
• 字体类型(通过查看 cv2.putText() 的文档找到支持的字体)
• 字体的大小
• 文字的一般属性如颜色,粗细,线条的类型等.为了更好看一点推荐使用
linetype=cv2.LINE_AA.在图像上绘制白色的OpenCV.
font=cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,'OpenCV',(10,500), font, 4,(255,255,255),2)警 告:所有的绘图函数的返回值都是None,所以不能使用 img = cv2.line(img,(0,0),(511,511),(255,0,0),5)。
下面就是最终结果了,通过你前面几节学到的知识把它显示出来吧:

8.把鼠标当画笔
使用 OpenCV 处理鼠标事件,你将要学习的函数是:cv2.setMouseCallback()
这里我们来创建一个简单的程序,它会在图片中双击过的位置绘制一个 圆圈。
首先创建一个鼠标事件回调函数,但鼠标事件发生时它就会被执行。 鼠标事件可以是鼠标上的任何动作,比如左键按下,左键松开,左键双击等。 我们可以通过鼠标事件获得与鼠标对应的图片上的坐标。根据这些信息我们可以做任何想做的事。你可以通过执行下列代码查看所有被支持的鼠标事件:
import cv2
events = [i for i in dir(cv2) if 'EVENT' in i]
print( events )所有的鼠标事件回调函数都有一个统一的格式,他们所不同的地方仅仅是被调用后的功能。我们的鼠标事件回调函数只用做一件事:在双击过的地方绘制一个圆圈。下面是代码:
import cv2
import numpy as np
#mouse callback function
def draw_circle(event,x,y,flags,param):
if event==cv2.EVENT_LBUTTONDBLCLK: # 双击
cv2.circle(img,(x,y),100,(255,0,0),-1) # 创建图像与窗口并将窗口与回调函数绑定
img=np.zeros((720, 1280, 3),np.uint8)
cv2.namedWindow('image')
cv2.setMouseCallback('image',draw_circle)
while(1):
cv2.imshow('image',img)
if cv2.waitKey(20)&0xFF==27:
break
cv2.destroyAllWindows()现在我们来创建一个更好的程序。这次我们的程序要完成的任务是根据我们选择的模式在拖动鼠标时绘制矩形或者是圆圈(就像画图程序中一样)。所以我们的回调函数包含两部分,一部分画矩形,一部分画圆圈。这是一个典型的例子,它可以帮助我们更好理解与构建人机交互式程序,比如物体跟踪,图像分割等。
import cv2
import numpy as np
# 当鼠标按下时变为 True
drawing=False
# 如果 mode 为 true 绘制矩形。按下'm' 变成绘制曲线。
mode=True
ix,iy=-1,-1
# 创建回调函数
def draw_circle(event,x,y,flags,param):
global ix,iy,drawing,mode
# 当按下左键是返回起始位置坐标
if event==cv2.EVENT_LBUTTONDOWN:
drawing=True
ix,iy=x,y
elif event==cv2.EVENT_LBUTTONDBLCLK: # 双击
cv2.circle(img,(x,y),50,(255,0,0),-1)
# 当鼠标左键按下并移动是绘制图形。event 可以查看移动,flag 查看是否按下
elif event==cv2.EVENT_MOUSEMOVE and flags==cv2.EVENT_FLAG_LBUTTON:
if drawing==True:
if mode==True:
cv2.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)
else:# 绘制圆圈,小圆点连在一起就成了线,3 代表了笔画的粗细
cv2.circle(img,(x,y),3,(0,0,255),-1)
# 下面注释掉的代码是起始点为圆心,起点到终点为半径的
# r=int(np.sqrt((x-ix)**2+(y-iy)**2))
# cv2.circle(img,(x,y),r,(0,0,255),-1)
# 当鼠标松开停止绘画。
elif event==cv2.EVENT_LBUTTONUP:
drawing==False下面我们要把这个回调函数与 OpenCV 窗口绑定在一起。在主循环中我们需要将键盘上的“m”键与模式转换绑定在一起。
img=np.zeros((720,1280,3),np.uint8)
cv2.namedWindow('image')
cv2.setMouseCallback('image',draw_circle)
while(1):
cv2.imshow('image',img)
k=cv2.waitKey(1)&0xFF
if k==ord('m'):
mode=not mode
elif k==27:
break9.用滚动条做调色板
现在我们来创建一个简单的程序:通过调节滚动条来设定画板颜色。我们要创建一个窗口来显示显色,还有三个滚动条来设置 B(Blue),G(Green),R(Red) 的颜色。当我们滑动滚动条时窗口的颜色也会发生相应改变。默认情况下窗口的起始颜色为黑。
cv2.getTrackbarPos() 函数的一个参数是滑动条的名字;第二个参数是滑动条被放置窗口的名字;第三个参数是滑动条的默认位置;第四个参数是滑动条的最大值;第五个函数是回调函数,每次滑动条的滑动都会调用回调函数。回调函数通常都会含有一个默认参数,就是滑动条的位置。在本例中这个函数不用做任何事情,我们只需要pass 就可以了。
滑动条的另外一个重要应用就是用作转换按钮。默认情况下 OpenCV 本 身不带有按钮函数。所以我们使用滑动条来代替。在我们的程序中,我们要创 建一个转换按钮,只有当装换按钮指向 ON 时,滑动条的滑动才有用,否则窗 户口都是黑的。
import cv2
import numpy as np
def nothing(x):
pass
# 创建一副黑色图像
img=np.zeros((300,512,3),np.uint8)
cv2.namedWindow('image')
cv2.createTrackbar('R','image',0,255,nothing)
# cv2.createTrackbar('R','image',0,255, lambda x: None)
cv2.createTrackbar('G','image',0,255,nothing)
cv2.createTrackbar('B','image',0,255,nothing)
switch='0:OFF\n1:ON'
cv2.createTrackbar(switch,'image',0,1,nothing)
while(1):
cv2.imshow('image',img)
k=cv2.waitKey(1)&0xFF
if k==27:
break
r=cv2.getTrackbarPos('R','image')
g=cv2.getTrackbarPos('G','image')
b=cv2.getTrackbarPos('B','image')
s=cv2.getTrackbarPos(switch,'image')
if s==0:
img[:]=0
else:
img[:]=[b,g,r]
cv2.destroyAllWindows()程序运行效果如下:
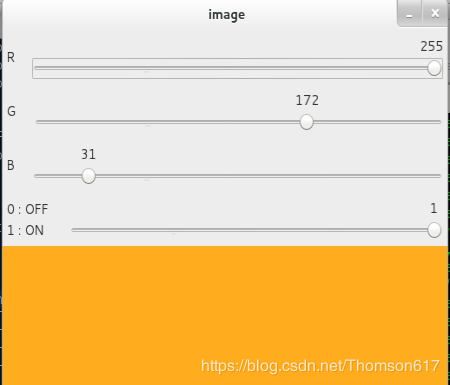
创建一个画板,可以自选各种颜色的画笔绘画各种图形:
import cv2
import numpy as np
def nothing(x):
pass
drawing=False # 当鼠标按下时变为 True
mode=True # 如果 mode 为 true 绘制矩形。按下'm' 变成绘制曲线
ix,iy=-1,-1
# 创建回调函数
def draw_circle(event,x,y,flags,param):
r=cv2.getTrackbarPos('R','image')
g=cv2.getTrackbarPos('G','image')
b=cv2.getTrackbarPos('B','image')
color=(b,g,r)
global ix,iy,drawing,mode
# 当按下左键是返回起始位置坐标
if event==cv2.EVENT_LBUTTONDOWN:
drawing=True
ix,iy=x,y
elif event==cv2.EVENT_LBUTTONDBLCLK: # 双击
cv2.circle(img,(x,y),50,color,-1)
# 当鼠标左键按下并移动是绘制图形。event 可以查看移动,flag 查看是否按下
elif event==cv2.EVENT_MOUSEMOVE and flags==cv2.EVENT_FLAG_LBUTTON:
if drawing==True:
if mode==True:
cv2.rectangle(img,(ix,iy),(x,y),color,-1)
else:
# 绘制圆圈,小圆点连在一起就成了线,3 代表了笔画的粗细
cv2.circle(img,(x,y),3,color,-1)
# 当鼠标松开停止绘画。
elif event==cv2.EVENT_LBUTTONUP:
drawing==False
img=np.zeros((720,1280,3),np.uint8)
cv2.namedWindow('image')
cv2.createTrackbar('R','image',0,255,nothing)
cv2.createTrackbar('G','image',0,255,nothing)
cv2.createTrackbar('B','image',0,255,nothing)
cv2.setMouseCallback('image',draw_circle)
while(1):
cv2.imshow('image',img)
k=cv2.waitKey(1)&0xFF
if k==ord('m'):
mode=not mode
elif k==27:
break
第三章.核心操作
10.图像的基础操作
几乎所有这些操作与 Numpy 的关系都比与 OpenCV 的关系更加紧密,因此熟练 Numpy 可以帮助我们写出性能更好的代码。
(示例将会在 Python 终端中展示,因为他们大部分都只有一行代码)
10.1获取并修改像素值
首先我们需要读入一幅图像:
import numpy as np
import cv2
img = cv2.imread('messi5.jpg')你可以根据像素的行和列的坐标获取他的像素值。对 BGR 图像而言,返回值为 B,G,R 的值。对灰度图像而言,会返回他的灰度值(亮度?intensity)
import cv2
img=cv2.imread('./images/roi.jpg')
px=img[100,100]
print (px)
blue=img[100,100,0]
print (blue)
## [57 63 68]
## 57你可以以类似的方式修改像素值。
import cv2
img=cv2.imread('./images/roi.jpg')
img[100,100]=[255,255,255]
print (img[100,100])
## [255 255 255]警告:Numpy 是经过优化了的进行快速矩阵运算的软件包。所以我们不推荐逐个获取像素值并修改,这样会很慢,能有矩阵运算就不要用循环。
注意:上面提到的方法被用来选取矩阵的一个区域,比如说前 5 行的后 3 列。 对于获取每一个像素值, 也许使用 Numpy 的 array.item() 和 ar- ray.itemset() 会更好。但是返回值是标量。如果你想获得所有 B,G,R 的 值,你需要使用 array.item() 分割他们。
获取像素值及修改的更好方法。
import cv2
import numpy as np
img=cv2.imread('./images/roi.jpg')
print (img.item(10,10,2))
img.itemset((10,10,2),100)
print (img.item(10,10,2))
## 50
## 10010.2获取图像属性
图像的属性包括:行(高)、列(宽)、通道、图像数据类型、像素数目等。
img.shape 获取图像的形状。返回值是一个包含行数,列数,通道数的元组。
img.size 获取图像的像素数目( 宽*高*通道数,即shape元素的乘积 )。
img.dtype 获取图像的数据类型.
import cv2
img=cv2.imread('./images/roi.jpg')
print (img.shape)
print (img.shape[:2][::-1])
print (img.size)
print (img.dtype)
## (280, 450, 3)
## (450, 280)
## 378000
## uint8注意:如果图像是灰度图,返回值仅有行数和列数。所以通过检查这个返回值 就可以知道加载的是灰度图还是彩色图。
在调试(debug)时 img.dtype 非常重要。因为在 OpenCV- Python代码中经常出现数据类型的不一致。
10.3图像 ROI
有时你需要对一幅图像的特定区域进行操作。例如我们要检测一副图像中眼睛的位置,我们首先应该在图像中找到脸,再在脸的区域中找眼睛,而不是直接在一幅图像中搜索。这样会提高程序的准确性和性能。
ROI 也是使用 Numpy 索引来获得的。现在我们选择球的部分并把他拷贝到图像的其他区域。
import cv2
img=cv2.imread('./images/roi.jpg')
ball=img[280:340,330:390]
img[273:333,100:160]=bal看看结果吧:

10.4拆分及合并图像通道
有时我们需要对 BGR 三个通道分别进行操作。这时你就需要把 BGR 拆分成单个通道。有时你需要把独立通道的图片合并成一个 BGR 图像。你可以 这样做:
import cv2
img=cv2.imread('./images/roi.jpg')
b,g,r=cv2.split(img)
#b=img[:,:,0]
img=cv2.merge(b,g,r)假如你想使所有像素的红色通道值都为 0,你不必先拆分再赋值。你可以 直接使用 Numpy 索引,这会更快。
img[:,:,2]=0警告:cv2.split() 是一个比较耗时的操作。只有真正需要时才用它,能用Numpy 索引就尽量用。
10.5为图像扩边(填充)
如果你想在图像周围创建一个边,就像相框一样,你可以使用 cv2.copyMakeBorder()
函数。这经常在卷积运算或 0 填充时被用到。这个函数包括如下参数:
• src 输入图像
• top, bottom, left, right 对应边界的像素数目.
• borderType 要添加那种类型的边界,类型如下
– cv2.BORDER_CONSTANT 添加有颜色的常数值边界,还需要 下一个参数.
– cv2.BORDER_REFLECT 边界元素的镜像.
例如: fedcba|abcde- fgh|hgfedcb
– cv2.BORDER_REFLECT_101 or cv2.BORDER_DEFAULT跟上面一样,但稍作改动。例如: gfedcb|abcdefgh|gfedcba
– cv2.BORDER_REPLICATE 重复最后一个元素。
例如: aaaaaa| abcdefgh|hhhhhhh
– cv2.BORDER_WRAP 例如: cdefgh| abcdefgh|abcdefg
• value 边界颜色,如果边界的类型是 cv2.BORDER_CONSTANT
为了更好的理解这几种类型请看下面的演示程序。
import cv2
from matplotlib import pyplot as plt
BLUE=[255,0,0]
img1=cv2.imread('opencv_logo.png')
replicate = cv2.copyMakeBorder(img1,10,10,10,10,cv2.BORDER_REPLICATE)
reflect = cv2.copyMakeBorder(img1,10,10,10,10,cv2.BORDER_REFLECT)
reflect101 = cv2.copyMakeBorder(img1,10,10,10,10,cv2.BORDER_REFLECT_101)
wrap = cv2.copyMakeBorder(img1,10,10,10,10,cv2.BORDER_WRAP)
constant= cv2.copyMakeBorder(img1,10,10,10,10,cv2.BORDER_CONSTANT,value=BLUE)
plt.subplot(231),plt.imshow(img1,'gray'),plt.title('ORIGINAL')
plt.subplot(232),plt.imshow(replicate,'gray'),plt.title('REPLICATE')
plt.subplot(233),plt.imshow(reflect,'gray'),plt.title('REFLECT')
plt.subplot(234),plt.imshow(reflect101,'gray'),plt.title('REFLECT_101')
plt.subplot(235),plt.imshow(wrap,'gray'),plt.title('WRAP')
plt.subplot(236),plt.imshow(constant,'gray'),plt.title('CONSTANT')
plt.show()结果如下(由于是使用 matplotlib 绘制, 所以交换 R 和 B 的位置,
OpenCV 中是按 BGR,matplotlib 中是按 RGB 排列):

11.图像上的算术运算
11.1图像加法
你可以使用函数 cv2.add() 将两幅图像进行加法运算,当然也可以直接使用 numpy,res=img1+img。两幅图像的大小,类型必须一致,或者第二个图像可以使一个简单的标量值。
注意:OpenCV 中的加法与 Numpy 的加法是有所不同的。OpenCV 的加法 是一种饱和操作,而 Numpy 的加法是一种模操作。
例如下面的两个例子:
import cv2
import numpy as np
x = np.uint8([250])
y = np.uint8([10])
print (cv2.add(x,y)) # 250+10 = 260 => 255
[[255]]
print (x+y) # 250+10 = 260 % 256 = 4
[4]这种差别在你对两幅图像进行加法时会更加明显。OpenCV 的结果会更好 一点。所以我们尽量使用 OpenCV 中的函数。
11.2图像混合
这其实也是加法,但是不同的是两幅图像的权重不同,这就会给人一种混 合或者透明的感觉。图像混合的计算公式如下:
g (x) = (1 − α) f0 (x) + αf1 (x)
通过修改 α 的值(0 → 1),可以实现非常酷的混合。 现在我们把两幅图混合在一起。第一幅图的权重是 0.7,第二幅图的权重是 0.3。函数 cv2.addWeighted() 可以按下面的公式对图片进行混合操作。
dst = α · img1 + β · img2 + γ
这里 γ 的取值为 0。
import cv2
img1=cv2.imread('ml.png')
img2=cv2.imread('opencv_logo.jpg')
dst=cv2.addWeighted(img1,0.7,img2,0.3,0)
cv2.imshow('dst',dst)
cv2.waitKey(0)
cv2.destroyAllWindow()下面就是结果:

11.3按位运算
这里包括的按位操作有:AND,OR,NOT,XOR 等。当我们提取图像的 一部分,选择非矩形 ROI 时这些操作会很有用(下一章你就会明白)。下面的 例子就是教给我们如何改变一幅图的特定区域。
我想把 OpenCV 的标志放到另一幅图像上。如果使用加法,颜色会改变,如果使用混合,会得到透明效果,但是我不想要透明。如果它是矩形可以和上一章一样使用 ROI。但是它不是矩形。但是我们可以通过下面的按位运 算实现:
import cv2
# 加载图像
img1 = cv2.imread('roi.jpg')
img2 = cv2.imread('opencv_logo.png')
# I want to put logo on top-left corner, So I create a ROI
rows,cols,channels = img2.shape
roi = img1[0:rows, 0:cols ]
# Now create a mask of logo and create its inverse mask also
img2gray = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(img2gray, 175, 255, cv2.THRESH_BINARY)
mask_inv = cv2.bitwise_not(mask)
# Now black-out the area of logo in ROI
# 取roi 中与mask中不为零的值对应的像素的值,其他值为0
# 注意这里必须有mask=mask或者mask=mask_inv,其中的'mask='不能忽略
img1_bg = cv2.bitwise_and(roi,roi,mask = mask)
# 取 roi 中与 mask_inv 中不为零的值对应的像素的值,其他值为0。
# Take only region of logo from logo image.
img2_fg = cv2.bitwise_and(img2,img2,mask = mask_inv)
# Put logo in ROI and modify the main image
dst = cv2.add(img1_bg,img2_fg)
img1[0:rows, 0:cols ] = dst
cv2.imshow('res',img1)
cv2.waitKey(0)
cv2.destroyAllWindows()结果如下。左面的图像是我们创建的掩码。右边的是最终结果。为了帮助大 家理解我把上面程序的中间结果也显示了出来,特别是 img1_bg 和 img2_fg。

12.程序性能检测及优化
在图像处理中你每秒钟都要做大量的运算,所以你的程序不仅要能给出正 确的结果,同时还必须要快。所以这节我们将要学习:
• 检测程序的效率.
• 一些能够提高程序效率的技巧.
• 你要学到的函数有:cv2.getTickCount,cv2.getTickFrequency 等。
除了 OpenCV,Python 也提供了一个叫 time 的的模块,你可以用它来计算程序的运行时间。另外一个叫做 profile 的模块会帮你得到一份关于你的程序的详细报告,其中包含了代码中每个函数运行需要的时间,以及每个函数被调用的次数。如果你正在使用 IPython 的话,所有这些特点都被以一种用户友好的方式整合在一起了。我们会学习几个重要的,要想学到更加详细的知识就打 开更多资源中的链接吧。
12.1使用OpenCV检测程序效率
cv2.getTickCount 函数返回从参考点到这个函数被执行的时钟数。所以当你在一个函数执行前后都调用它的话,你就会得到这个函数的执行时间(时钟数)。
cv2.getTickFrequency 返回时钟频率,或者说每秒钟的时钟数。所以 你可以按照下面的方式得到一个函数运行了多少秒:
import cv2
e1 = cv2.getTickCount()
e2 = cv2.getTickCount()
time = (e2 - e1)/ cv2.getTickFrequency()我们将会用下面的例子演示。下面的例子是用窗口大小不同(5,7,9)的 核函数来做中值滤波:
import cv2
img1 = cv2.imread('roi.jpg')
e1 = cv2.getTickCount()
for i in range(5, 49, 2):
img1 = cv2.medianBlur(img1, i)
e2 = cv2.getTickCount()
t = (e2 - e1) / cv2.getTickFrequency()
print(t)
# Result I got is 0.521107655 seconds注 意: 你 也 可 以 中 time 模 块 实 现 上 面 的 功 能。 但 是 要 用 的 函 数 是 time.time() 而不是 cv2.getTickCount。 比较一下这两个结果的差别 吧。
12.2 OpenCV中的默认优化
OpenCV 中的很多函数都被优化过(使用 SSE2,AVX 等)。也包含一些 没有被优化的代码。如果我们的系统支持优化的话要尽量利用只一点。在编译时 优化是被默认开启的。因此 OpenCV 运行的就是优化后的代码,如果你把优化 关闭的话就只能执行低效的代码了。你可以使用函数 cv2.useOptimized() 来查看优化是否被开启了,使用函数 cv2.setUseOptimized() 来开启优化。
# check if optimization is enabled
In [5]: cv.useOptimized()
Out[5]: True
In [6]: %timeit res = cv.medianBlur(img,49)
10 loops, best of 3: 34.9 ms per loop
# Disable it
In [7]: cv.setUseOptimized(False)
In [8]: cv.useOptimized()
Out[8]: False
In [9]: %timeit res = cv.medianBlur(img,49)
10 loops, best of 3: 64.1 ms per loop
看见了吗,优化后中值滤波的速度是原来的两倍。如果你查看源代码的话, 你会发现中值滤波是被 SIMD优化的。所以你可以在代码的开始处开启优化(优化是默认开启的)。
12.3在IPython中检测程序效率
有时你需要比较两个相似操作的效率,这时你可以使用 IPython 为你提供 的魔法命令%time。他会让代码运行好几次从而得到一个准确的(运行)时 间。它也可以被用来测试单行代码的。
例如,你知道下面这同一个数学运算用哪种行式的代码会执行的更快吗?
x = 5; y = x ∗ ∗2
x = 5; y = x ∗ x
x = np.uint([5]); y = x ∗ x y = np.squre(x)
我们可以在 IPython 的 Shell 中使用魔法命令找到答案。
In [10]: x = 5
In [11]: %timeit y=x**2
10000000 loops, best of 3: 73 ns per loop
In [12]: %timeit y=x*x
10000000 loops, best of 3: 58.3 ns per loop
In [15]: z = np.uint8([5])
In [17]: %timeit y=z*z
1000000 loops, best of 3: 1.25 us per loop
In [19]: %timeit y=np.square(z)
1000000 loops, best of 3: 1.16 us per loop
竟然是第一种写法,它居然比 Nump 快了 20 倍。如果考虑到数组构建的 话,能达到 100 倍的差。
注意:Python 的标量计算比 Nump 的标量计算要快。对于仅包含一两个 元素的操作 Python 标量比 Numpy 的数组要快。但是当数组稍微大一点时 Numpy 就会胜出了。
我 们 来 比 较 一 下 cv2.countNonZero() 和np.count_nonzero()。
In [35]: %timeit z = cv.countNonZero(img)
100000 loops, best of 3: 15.8 us per loop
In [36]: %timeit z = np.count_nonzero(img)
1000 loops, best of 3: 370 us per loop
看见了吧,OpenCV 的函数是 Numpy 函数的 25 倍。
注意:一般情况下 OpenCV 的函数要比 Numpy 函数快。所以对于相同的操 作最好使用 OpenCV 的函数。当然也有例外,尤其是当使用 Numpy 对视图(而非复制)进行操作时。
12.4效率优化技术
有些技术和编程方法可以让我们最大的发挥 Python 和 Numpy 的威力。 我们这里仅仅提一下相关的,你可以通过超链接查找更多详细信息。我们要说 的最重要的一点是:首先用简单的方式实现你的算法(结果正确最重要),当结 果正确后,再使用上面的提到的方法找到程序的瓶颈来优化它。
1. 尽量避免使用循环,尤其双层三层循环,它们天生就是非常慢的。
2. 算法中尽量使用向量操作,因为 Numpy 和 OpenCV 都对向量操作进行了优化。
3. 利用高速缓存一致性。
4. 没有必要的话就不要复制数组。使用视图来代替复制。数组复制非常浪费资源。
就算进行了上述优化,如果你的程序还是很慢,或者说大的训话不可避免的话, 你你应该尝试使用其他的包,比如说 Cython,来加速你的程序。
还有几个魔法命令可以用来检测程序的效率,profiling,line profiling, 内存使用等。他们都有完善的文档。所以这里只提供了超链接。感兴趣的可以 自己学习一下。
更多资源
- Python Optimization Techniques
- Timing and Profiling in IPython
- Scipy Lecture Notes - Advanced Numpy
第四章.图像处理
13.颜色空间转换
13.1转换颜色空间
在 OpenCV 中有超过 150种进行颜色空间转换的方法。但是你会发现我们经常用到的也就两种:BGR↔Gray 和 BGR↔HSV。
要用到的函数是:cv2.cvtColor(input_image,flag),其中flag就是转换类型。
对于 BGR↔Gray 的转换,我们要使用的 flag 就是 cv2.COLOR_BGR2GRAY。 同样对于 BGR↔HSV 的转换,我们用的 flag 就是 cv2.COLOR_BGR2HSV。 你还可以通过下面的命令得到所有可用的 flag。
import cv2
flags=[i for i in dir(cv2) if i.startswith('COLOR_')]
print (flags)注意:在 OpenCV 的 HSV 格式中,H(色彩/色度)的取值范围是 [0,179], S(饱和度)的取值范围 [0,255],V(亮度)的取值范围 [0,255]。但是不同的软件使用的值可能不同。所以当你需要拿OpenCV的HSV值与其他软件的 HSV 值进行对比时,一定要记得归一化。
13.2物体跟踪
现在我们知道怎样将一幅图像从 BGR 转换到 HSV 了,我们可以利用这 一点来提取带有某个特定颜色的物体。在 HSV 颜色空间中要比在 BGR 空间中更容易表示一个特定颜色。在我们的程序中,我们要提取的是一个蓝色的物体。下面就是我们要做的几步:
• 从视频中获取每一帧图像
• 将图像转换到 HSV 空间
• 设置 HSV 阈值到蓝色范围。
• 获取蓝色物体,当然还可以做其他任何想做的事,比如:在蓝色物体周围画一个圈。
下面就是我们的代码:
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while (1):
# 获取每一帧
ret, frame = cap.read()
# 转换到 HSV
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
# 设定蓝色的阈值,其他阀值范围参见 https://blog.csdn.net/taily_duan/article/details/51506776
lower_blue = np.array([100, 43, 46])
upper_blue = np.array([124, 255, 255])
# 根据阈值构建掩模
mask = cv2.inRange(hsv, lower_blue, upper_blue)
# 计算图像中目标的轮廓
img,contours, _= cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
if cv2.contourArea(c) > 1000:
(x, y, w, h) = cv2.boundingRect(c) # 该函数计算矩形的边界框
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255), 2)
cv2.imshow('frame', frame)
cv2.imshow('mask', mask)
# 对原图像和掩模进行位运算
res = cv2.bitwise_and(frame, frame, mask=mask)
cv2.imshow('res', res)
k = cv2.waitKey(5) & 0xFF
if k == 27:
break
# 关闭窗口
cv2.destroyAllWindows()下图显示了追踪蓝色物体的结果:

注意:图像中仍然有一些噪音,我们会在后面的章节中介绍如何消减噪音。这是物体跟踪中最简单的方法。当你学习了轮廓之后,你就会学到更多相关知识,那是你就可以找到物体的重心,并根据重心来跟踪物体,仅仅在摄像头前挥挥手就可以画出同的图形,或者其他更有趣的事。
13.3怎样找到要跟踪对象的HSV值?
这是我在stackoverflow.com上遇到的最普遍的问题。其实这真的很简单, 函数 cv2.cvtColor() 也可以用到这里。但是现在你要传入的参数是(你想要的)BGR 值而不是一副图。例如,我们要找到绿色的 HSV 值,我们只需在终 端输入以下命令:
import cv2
import numpy as np
green=np.uint8([0,255,0])
hsv_green=cv2.cvtColor(green,cv2.COLOR_BGR2HSV)
error: /builddir/build/BUILD/opencv-2.4.6.1/
modules/imgproc/src/color.cpp:3541:
error: (-215) (scn == 3 || scn == 4) && (depth == CV_8U || depth == CV_32F)
in function cvtColor
#scn (the number of channels of the source), i.e. self.img.channels(), is neither 3 nor 4.
#depth (of the source), i.e. self.img.depth(), is neither CV_8U nor CV_32F.
# 所以不能用 [0,255,0],而要用 [[[0,255,0]]]
# 这里的三层括号应该分别对应于 cvArray,cvMat,IplImage
green=np.uint8([[[0,255,0]]])
hsv_green=cv2.cvtColor(green,cv2.COLOR_BGR2HSV)
print (hsv_green) ## [[[60 255 255]]]现在你可以分别用 [H-100,100,100] 和 [H+100,255,255] 做上 下阈值。除了这个方法之外,你可以使用任何其他图像编辑软件(例如 GIMP) 或者在线转换软件找到相应的 HSV 值,但是最后别忘了调节 HSV 的范围。
14.几何变换
OpenCV 提供了两个变换函数:cv2.warpAffine 和 cv2.warpPerspective,使用这两个函数你可以实现所有类型的变换。cv2.warpAffine 接收的参数是2 × 3 的变换矩阵,而 cv2.warpPerspective 接收的参数是 3 × 3 的变换矩阵。
14.1扩展缩放
扩展缩放只是改变图像的尺寸大小。OpenCV 提供的函数 cv2.resize() 可以实现这个功能。图像的尺寸可以自己手动设置,也可以指定缩放因子。我 们可以选择使用不同的插值方法。在缩放时推荐使用 cv2.INTER_AREA,在扩展时推荐使用 cv2.INTER_CUBIC(慢) 和 cv2.INTER_LINEAR。 默认情况下所有改变图像尺寸大小的操作使用的插值方法都是 cv2.INTER_LINEAR。 你可以使用下面任意一种方法改变图像的尺寸:
import cv2
img=cv2.imread('messi5.jpg')
# 下面的None本应该是输出图像的尺寸,但是因为后边我们设置了缩放因子,因此这里为None
res=cv2.resize(img,None,fx=2,fy=2,interpolation=cv2.INTER_CUBIC)
# 这里呢,我们直接设置输出图像的尺寸,所以不用设置缩放因子
height,width=img.shape[:2]
res=cv2.resize(img,(2*width,2*height),interpolation=cv2.INTER_CUBIC)
while(1):
cv2.imshow('res',res)
cv2.imshow('img',img)
if cv2.waitKey(1) & 0xFF == 27:
break
cv2.destroyAllWindows()Resize(src, dst, interpolation=CV_INTER_LINEAR)
14.2平移
平移就是将对象换一个位置。如果你要沿(x,y)方向移动,移动的距离是(tx,ty),你可以按照下面的方式构建移动矩阵:
![]()
你可以使用 Numpy 数组构建这个矩阵(数据类型是 np.float32),然后把它传给函数 cv2.warpAffine()。 看看下面这个例子吧, 它被移动了(100,50)个像素。
import cv2 as cv
import numpy as np
img = cv.imread('messi5.jpg', 0)
rows, cols = img.shape
M = np.float32([[1, 0, 100], [0, 1, 50]])
dst = cv.warpAffine(img, M, (cols, rows))
cv.imshow('img', dst)
cv.waitKey(0)
cv.destroyAllWindows()警告:函数 cv2.warpAffine() 的第三个参数的是输出图像的大小,它的格式 应该是图像的(宽,高)。应该记住的是图像的宽对应的是列数,高对应的是行 数。
下面就是结果:

14.3旋转
对一个图像旋转角度 θ, 需要使用到下面形式的旋转矩阵。
![]()
但是 OpenCV 允许你在任意地方进行旋转,但是旋转矩阵的形式应该修改为:
![]()
其中:
α = scale · cos θ
β = scale · sin θ
为了构建这个旋转矩阵,OpenCV 提供了一个函数:cv2.getRotationMatrix2D。 下面的例子是在不缩放的情况下将图像旋转 90 度。
import cv2
img=cv2.imread('messi5.jpg',0)
rows,cols=img.shape[:2]
# 这里的第一个参数为旋转中心,第二个为旋转角度,第三个为旋转后的缩放因子
# 可以通过设置旋转中心,缩放因子,以及窗口大小来防止旋转后超出边界的问题
M=cv2.getRotationMatrix2D((cols/2,rows/2),45,0.6) # 第三个参数是输出图像的尺寸中心
dst=cv2.warpAffine(img,M,(2*cols,2*rows))
while(1):
cv2.imshow('img',dst)
if cv2.waitKey(1)&0xFF==27:
break
cv2.destroyAllWindows()下面是结果:

14.4仿射变换
在仿射变换中,原图中所有的平行线在结果图像中同样平行。为了创建这个矩阵我们需要从原图像中找到三个点以及他们在输出图像中的位置。然后 cv2.getAffineTransform 会创建一个 2x3 的矩阵,最后这个矩阵会被传给函数 cv2.warpAffine。
来看看下面的例子,以及我选择的点(被标记为绿色的点)
import cv2
import numpy as np
from matplotlib import pyplot as plt
img=cv2.imread('drawing.png')
rows,cols,ch=img.shape
pts1=np.float32([[50,50],[200,50],[50,200]])
pts2=np.float32([[10,100],[200,50],[100,250]])
M=cv2.getAffineTransform(pts1,pts2)
dst=cv2.warpAffine(img,M,(cols,rows))
plt.subplot(121,plt.imshow(img),plt.title('Input'))
plt.subplot(121,plt.imshow(img),plt.title('Output'))
plt.show()下面是结果:
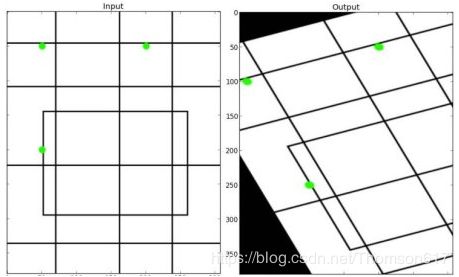
14.5透视变换
对于视角变换,我们需要一个 3x3 变换矩阵。在变换前后直线还是直线。 要构建这个变换矩阵,你需要在输入图像上找 4 个点,以及他们在输出图 像上对应的位置。这四个点中的任意三个都不能共线。这个变换矩阵可以有 函数 cv2.getPerspectiveTransform() 构建。然后把这个矩阵传给函数 cv2.warpPerspective。
代码如下:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img=cv2.imread('sudokusmall.png')
rows,cols,ch=img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M=cv2.getPerspectiveTransform(pts1,pts2)
dst=cv2.warpPerspective(img,M,(300,300))
plt.subplot(121,plt.imshow(img),plt.title('Input'))
plt.subplot(121,plt.imshow(img),plt.title('Output'))
plt.show()结果如下:

15.图像阈值
15.1简单阈值
当像素值高于阈值时,我们给这个像素 赋予一个新值(可能是白色),否则我们给它赋予另外一种颜色(也许是黑色)。 这个函数就是 cv2.threshhold()。这个函数的第一个参数就是原图像,原图像应该是灰度图;第二个参数就是用来对像素值进行分类的阈值;第三个参数就是当像素值高于(有时是小于)阈值时应该被赋予的新的像素值。OpenCV 提供了多种不同的阈值方法,这是由第四个参数来决定的。这些方法包括:
· cv2.THRESH_BINARY
- cv2.THRESH_BINARY_INV
- cv2.THRESH_TRUNC
- cv2.THRESH_TOZERO
- cv2.THRESH_TOZERO_INV

上图摘选自《学习 OpenCV》中文版,其实这些在文档中都有详细介绍, 你也可以直接查看文档。
这个threshhold函数有两个返回值,第一个为 retVal,我们后面会解释。第二个就是 阈值化之后的结果图像了。
代码:
import cv2
from matplotlib import pyplot as plt
img=cv2.imread('gradient.png',0)
ret,thresh1=cv2.threshold(img,127,255,cv2.THRESH_BINARY)
ret,thresh2=cv2.threshold(img,127,255,cv2.THRESH_BINARY_INV)
ret,thresh3=cv2.threshold(img,127,255,cv2.THRESH_TRUNC)
ret,thresh4=cv2.threshold(img,127,255,cv2.THRESH_TOZERO)
ret,thresh5=cv2.threshold(img,127,255,cv2.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()注意:为了同时在一个窗口中显示多个图像,我们使用函数 plt.subplot()。你 可以通过查看 Matplotlib 的文档获得更多详细信息。
结果如下:

15.2自适应阈值
在前面的部分我们使用是全局阈值,整幅图像采用同一个数作为阈值。当 时这种方法并不适应与所有情况,尤其是当同一幅图像上的不同部分的具有不 同亮度时。这种情况下我们需要采用自适应阈值。此时的阈值是根据图像上的 每一个小区域计算与其对应的阈值。因此在同一幅图像上的不同区域采用的是 不同的阈值,从而使我们能在亮度不同的情况下得到更好的结果。
这种方法需要我们指定三个参数,返回值只有一个。
- Adaptive Method- 指定计算阈值的方法.
- cv2.ADPTIVE_THRESH_MEAN_C:阈值取自相邻区域的平 均值.
- cv2.ADPTIVE_THRESH_GAUSSIAN_C:阈值取值相邻区域 的加权和,权重为一个高斯窗口.
• Block Size - 邻域大小(用来计算阈值的区域大小).
• C - 一个常数,阈值就等于的平均值或者加权平均值减去这个常数.
我们使用下面的代码来展示简单阈值与自适应阈值的差别:
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('dave.jpg',0)
img = cv2.medianBlur(img,5) # 中值滤波
ret,th1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY)
#11 为 Block size, 2 为 C 值
th2 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,11,2)
th3 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,2)
titles = ['Original Image', 'Global Thresholding (v = 127)',
'Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']
images = [img, th1, th2, th3]
for i in range(4):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()结果:

15.3 Otsu二值化
当我们使用 Otsu 二值化时会用到retVal。在使用全局阈值时,我们就是随便给了一个数来做阈值,那我们怎么知道 我们选取的这个数的好坏呢?答案就是不停的尝试。如果是一副双峰图像(简 单来说双峰图像是指图像直方图中存在两个峰)呢?我们岂不是应该在两个峰 之间的峰谷选一个值作为阈值?这就是 Otsu 二值化要做的。简单来说就是对 一副双峰图像自动根据其直方图计算出一个阈值。(对于非双峰图像,这种方法得到的结果可能会不理想)。
这里用到的函数是 cv2.threshold(),但是需要多传入一个参数
(flag):cv2.THRESH_OTSU。这时要把阈值设为 0。然后算法会找到最 优阈值,这个最优阈值就是返回值 retVal。如果不使用 Otsu 二值化,返回的 retVal 值与设定的阈值相等。
下面的例子中,输入图像是一副带有噪声的图像。第一种方法:设 127 为全局阈值。第二种方法:直接使用 Otsu 二值化。第三种方法:首先使用一个 5x5 的高斯核除去噪音,然后再使用 Otsu 二值化。看看噪音去除对结果的影响有多大吧。
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('noisy2.png', 0)
# 全局阈值化
ret1, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# Otsu's thresholding
ret2, th2 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 高斯滤波后的阈值化
# (5,5)为高斯核的大小,0 为标准差
blur = cv2.GaussianBlur(img, (5, 5), 0)
ret3, th3 = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 绘制所有图像及其直方图
images = [img, 0, th1, img, 0, th2, blur, 0, th3]
titles = ['Original Noisy Image', 'Histogram', 'Global Thresholding (v=127)',
'Original Noisy Image', 'Histogram', "Otsu's Thresholding",
'Gaussian filtered Image', 'Histogram',
"Otsu's Thresholding"]
# 这里使用了 pyplot 中画直方图的方法,plt.hist, 要注意的是它的参数是一维数组
# 所以这里使用了(numpy)ravel 方法,将多维数组转换成一维,也可以使用 flatten 方法
# ndarray.flat 1-D iterator over an array.
# ndarray.flatten 1-D array copy of the elements of an array in row-major order.
for i in range(3):
plt.subplot(3, 3, i * 3 + 1), plt.imshow(images[i * 3], 'gray')
plt.title(titles[i * 3]), plt.xticks([]), plt.yticks([])
plt.subplot(3, 3, i * 3 + 2), plt.hist(images[i * 3].ravel(), 256)
plt.title(titles[i * 3 + 1]), plt.xticks([]), plt.yticks([])
plt.subplot(3, 3, i * 3 + 3), plt.imshow(images[i * 3 + 2], 'gray')
plt.title(titles[i * 3 + 2]), plt.xticks([]), plt.yticks([])
plt.show()结果:

Otsu’s 二值化的工作原理:
在这一部分我们会演示怎样使用 Python 来实现 Otsu 二值化算法,从而 告诉大家它是如何工作的。如果你不感兴趣的话可以跳过这一节。
因为是双峰图,Otsu 算法就是要找到一个阈值(t), 使得同一类加权方 差最小,需要满足下列关系式:
![]()
其中:
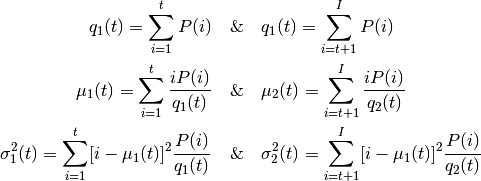
其实就是在两个峰之间找到一个阈值 t,将这两个峰分开,并且使每一个 峰内的方差最小。实现这个算法的 Python 代码如下:
import cv2
import numpy as np
img = cv2.imread('noisy2.png',0)
blur = cv2.GaussianBlur(img,(5,5),0)
# 找到normalized_histogram及其累积分布函数
# 计算归一化直方图
#CalcHist(image, accumulate=0, mask=NULL)
hist = cv2.calcHist([blur],[0],None,[256],[0,256])
hist_norm = hist.ravel()/hist.max()
Q = hist_norm.cumsum()
bins = np.arange(256)
fn_min = np.inf
thresh = -1
for i in range(1,256):
p1,p2 = np.hsplit(hist_norm,[i]) # probabilities
q1,q2 = Q[i],Q[255]-Q[i] # cum sum of classes
b1,b2 = np.hsplit(bins,[i]) # weights
# 求均值和方差
m1,m2 = np.sum(p1*b1)/q1, np.sum(p2*b2)/q2
v1,v2 = np.sum(((b1-m1)**2)*p1)/q1,np.sum(((b2-m2)**2)*p2)/q2
# 计算最小化函数
fn = v1*q1 + v2*q2
if fn < fn_min:
fn_min = fn
thresh = i
# 使用OpenCV函数查找otsu's阈值
ret, otsu = cv2.threshold(blur,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)
print (thresh,ret)
16.图像平滑(图像模糊)
16.1 2D卷积(图像过滤)
与一维信号一样,还可以使用各种低通滤波器(LPF),高通滤波器(HPF)等对图像进行滤波。LPF有助于消除噪声,使图像模糊等。HPF滤波器有助于在图像中找到边缘。OpenCV 提供的函数 cv.filter2D() 可以让我们对一幅图像进行卷积操作。下面我们将对一幅图像使用平均滤波器。下面是一个 5x5 的平均滤波器核:

操作如下:将核放在图像的一个像素 A 上,求与核对应的图像上 25(5x5) 个像素的和,在取平均数,用这个平均数替代像素 A 的值。重复以上操作直到 将图像的每一个像素值都更新一边。代码如下,运行一下吧。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('opencv_logo.png')
kernel = np.ones((5,5),np.float32)/25
#cv.Filter2D(src, dst, kernel, anchor=(-1, -1))
#ddepth –desired depth of the destination image;
#if it is negative, it will be the same as src.depth();
#the following combinations of src.depth() and ddepth are supported:
#src.depth() = CV_8U, ddepth = -1/CV_16S/CV_32F/CV_64F
#src.depth() = CV_16U/CV_16S, ddepth = -1/CV_32F/CV_64F
#src.depth() = CV_32F, ddepth = -1/CV_32F/CV_64F
#src.depth() = CV_64F, ddepth = -1/CV_64F
#when ddepth=-1, the output image will have the same depth as the source.
dst = cv2.filter2D(img,-1,kernel)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(dst),plt.title('Averaging')
plt.xticks([]), plt.yticks([])
plt.show()结果:

使用低通滤波器可以达到图像模糊的目的。这对与去除噪音很有帮助。其 实就是去除图像中的高频成分(比如:噪音,边界)。所以边界也会被模糊一 点。(当然,也有一些模糊技术不会模糊掉边界)。OpenCV 提供了四种模糊技 术。
16.2图像模糊(图像平滑)
(1).平均(Averaging)
这是由一个归一化卷积框完成的。他只是用卷积框覆盖区域所有像素的平均值来代替中心元素。可以使用函数 cv2.blur() 和 cv2.boxFilter() 来完这个任务。我们需要设定卷积框的宽和高。下面是一个 3x3 的归一化卷积框:

注意:如果你不想使用归一化卷积框,你应该使用 cv2.boxFilter(),这时要 传入参数 normalize=False。
示例:
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('opencv_logo.png')
blur = cv2.blur(img,(5,5))
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()结果:

(2).高斯模糊(Gaussian Blurring)
现在把卷积核换成高斯核(简单来说,方框不变,将原来每个方框的值是 相等的,现在里面的值是符合高斯分布的,方框中心的值最大,其余方框根据 距离中心元素的距离递减,构成一个高斯小山包。原来的求平均数现在变成求 加权平均数,全就是方框里的值)。实现的函数是 cv2.GaussianBlur()。我 们需要指定高斯核的宽和高(必须是奇数)。以及高斯函数沿 X,Y 方向的标准 差。如果我们只指定了 X 方向的的标准差,Y 方向也会取相同值。如果两个标 准差都是 0,那么函数会根据核函数的大小自己计算。高斯滤波可以有效的从 图像中去除高斯噪音。
你也可以使用函数 cv2.getGaussianKernel() 自己构建一个高斯核。
如果要使用高斯模糊的话,上边的代码应该写成:
#0 是指根据窗口大小(5,5)来计算高斯函数标准差
blur = cv2.GaussianBlur(img,(5,5),0)结果:

(3).中值模糊(Median Blurring)
顾名思义就是用与卷积框对应像素的中值来替代中心像素的值。这个滤波器经常用来去除椒盐噪声。前面的滤波器都是用计算得到的一个新值来取代中心像素的值,而中值滤波是用中心像素周围(也可以使他本身)的值来取代它。 它能有效的去除噪声。卷积核的大小也应该是一个奇数。
在这个例子中,我们给原始图像加上 50% 的噪声然后再使用中值模糊。 代码:
median = cv2.medianBlur(img,5)结果:

(4).双边滤波(Bilateral Filtering)
函数 cv2.bilateralFilter() 能在保持边界清晰的情况下有效的去除噪 音。但是这种操作与其他滤波器相比会比较慢。我们已经知道高斯滤波器是求中心点邻近区域像素的高斯加权平均值。这种高斯滤波器只考虑像素之间的空间关系,而不会考虑像素值之间的关系(像素的相似度)。所以这种方法不会考 虑一个像素是否位于边界。因此边界也会别模糊掉,而这正不是我们想要。
双边滤波在同时使用空间高斯权重和灰度值相似性高斯权重。空间高斯函 数确保只有邻近区域的像素对中心点有影响,灰度值相似性高斯函数确保只有 与中心像素灰度值相近的才会被用来做模糊运算。所以这种方法会确保边界不 会被模糊掉,因为边界处的灰度值变化比较大。
进行双边滤波的代码如下:
#cv2.bilateralFilter(src, d, sigmaColor, sigmaSpace)
#d – 滤波过程中使用的每个像素邻域的直径。如果它是非正的,则从sigmaSpace计算
#9 邻域直径,两个 75 分别是空间高斯函数标准差,灰度值相似性高斯函数标准差
blur = cv2.bilateralFilter(img,9,75,75)结果:

上图中的纹理被模糊掉了,但是边界还在。
Details about the bilateral filtering
17.形态学转换
17.1理论
形态学操作是根据图像形状进行的简单操作。一般情况下对二值化图像进行的操作。需要输入两个参数:一个是原始图像,第二个被称为结构化元素或核,它是用来决定操作的性质的。两个基本的形态学操作是腐蚀和膨胀。他们的变体构成了开运算,闭运算,梯度等。我们会以下图为例逐一介绍它们。

(1).腐蚀
就像土壤侵蚀一样,这个操作会把前景物体的边界腐蚀掉(但是前景仍然 是白色)。这是怎么做到的呢?卷积核沿着图像滑动,如果与卷积核对应的原图 像的所有像素值都是 1,那么中心元素就保持原来的像素值,否则就变为零。
这回产生什么影响呢?根据卷积核的大小靠近前景的所有像素都会被腐蚀掉(变为 0),所以前景物体会变小,整幅图像的白色区域会减少。这对于去除白噪声很有用,也可以用来断开两个连在一块的物体等。
这里我们有一个例子,使用一个 5x5 的卷积核,其中所有的值都是1。让我们看看它是如何工作的:
import cv2
import numpy as np
img = cv2.imread('j.png',0)
kernel = np.ones((5,5),np.uint8)
erosion = cv2.erode(img,kernel,iterations = 1)结果:

(2).膨胀
与腐蚀相反,与卷积核对应的原图像的像素值中只要有一个是 1,中心元 素的像素值就是 1。所以这个操作会增加图像中的白色区域(前景)。一般在去 噪声时先用腐蚀再用膨胀。因为腐蚀在去掉白噪声的同时,也会使前景对象变 小。所以我们再对他进行膨胀。这时噪声已经被去除了,不会再回来了,但是 前景还在并会增加。膨胀也可以用来连接两个分开的物体。
dilation = cv2.dilate(img,kernel,iterations = 1)结果:

(3).开运算
先进性腐蚀再进行膨胀就叫做开运算。就像我们上面介绍的那样,它被用 来去除噪声。这里我们用到的函数是 cv2.morphologyEx()。
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)结果:

(4).闭运算
先膨胀再腐蚀。它经常被用来填充前景物体中的小洞,或者前景物体上的 小黑点。
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)结果:

(5).形态学梯度
其实就是一幅图像膨胀与腐蚀的差别。 结果看上去就像前景物体的轮廓。
gradient = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel)结果:

(6).Top Hat
原始图像与进行开运算之后得到的图像的差。下面的例子是用一个 9x9 的 核进行礼帽操作的结果。
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)结果:

(7).Black Hat
进行闭运算之后得到的图像与原始图像的差。
blackhat = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
结果:

17.2结构化元素
在前面的例子中,我们使用 Numpy 构建了结构化元素,它是正方形的。但有时我们需要构建一个椭圆形/圆形的核。为了实现这种要求,OpenCV提供了函数 cv2.getStructuringElement()。你只需要告诉他你需要的核的形状和大小。
# Rectangular Kernel
>>> cv2.getStructuringElement(cv.MORPH_RECT,(5,5))
array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], dtype=uint8)
# Elliptical Kernel
>>> cv2.getStructuringElement(cv.MORPH_ELLIPSE,(5,5))
array([[0, 0, 1, 0, 0],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[0, 0, 1, 0, 0]], dtype=uint8)
# Cross-shaped Kernel
>>> cv2.getStructuringElement(cv.MORPH_CROSS,(5,5))
array([[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0],
[1, 1, 1, 1, 1],
[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0]], dtype=uint8)18.图像梯度
梯度简单来说就是求导。
OpenCV 提供了三种不同的梯度滤波器,或者说高通滤波器:Sobel, Scharr和Laplacian。Sobel,Scharr 其实就是求一阶或二阶导数。Scharr 是对 Sobel(使用小的卷积核求解求解梯度角度时)的优化。Laplacian 是求二阶导数。
18.1 Sobel算子和Scharr算子
Sobel 算子是高斯平滑与微分操作的结合体,所以它的抗噪声能力很好。你可以设定求导的方向(xorder 或 yorder)。还可以设定使用的卷积核的大小(ksize)。如果 ksize=-1,使用 3x3 的 Scharr 滤波器要 比 3x3 的 Sobel 滤波器的效果好(而且速度相同,所以在使用 3x3 滤波器时应该尽量使用 Scharr 滤波器)。3x3 的 Scharr 滤波器卷积核如下:

18.2 Laplacian算子
拉普拉斯(Laplacian)算子可以使用二阶导数的形式定义,可假设其离散实现类似于二阶 Sobel 导数,事实上,OpenCV 在计算拉普拉斯算子时直接调用 Sobel 算 子。计算公式如下:
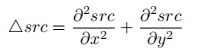
拉普拉斯滤波器使用的卷积核:

代码
下面的代码分别使用以上三种滤波器对同一幅图进行操作。使用的卷积核都是5x5。
import cv2
from matplotlib import pyplot as plt
img=cv2.imread('dave.jpg',0)
#cv2.CV_64F 输出图像的深度(数据类型),可以使用-1, 与原图像保持一致 np.uint8
laplacian=cv2.Laplacian(img,cv2.CV_64F)
# 参数 1,0 为只在 x 方向求一阶导数,最大可以求 2 阶导数。
sobelx=cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5) # 参数 0,1 为只在 y 方向求一阶导数,最大可以求 2 阶导数。
sobely=cv2.Sobel(img,cv2.CV_64F,0,1,ksize=5)
plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y'), plt.xticks([]), plt.yticks([])
plt.show()结果:

注意!
在查看上面这个例子的注释时不知道你有没有注意到:当我们可以通过参 数 -1 来设定输出图像的深度(数据类型)与原图像保持一致,但是我们在代码中使用的却是 cv2.CV_64F。这是为什么呢?想象一下一个从黑到白的边界的导数是整数,而一个从白到黑的边界点导数却是负数。如果原图像的深度是 np.int8 时,所有的负值都会被截断变成 0,换句话说就是把边界丢失掉。
所以如果这两种边界你都想检测到,最好的的办法就是将输出的数据类型设置的更高,比如 cv2.CV_16S,cv2.CV_64F 等。取绝对值然后再把它转回到cv2.CV_8U。下面的示例演示了输出图片的深度不同造成的不同效果。
import cv2
import numpy as np
img = cv2.imread('boxs.png',0)
frame_blurred = cv2.GaussianBlur(img, (5, 5), 1.5)
#sobelx = cv2.Sobel(frame_blurred, cv2.CV_8U, 1, 0)
sobelx = cv2.Sobel(frame_blurred, cv2.CV_64F, 1, 0)
sobely = cv2.Sobel(frame_blurred, cv2.CV_64F, 0, 1)
sobelx = np.uint8(np.absolute(sobelx))
sobely = np.uint8(np.absolute(sobely))
sobelcombine = cv2.bitwise_or(sobelx,sobely)
cv2.imshow("Sobel-x", sobelx)
cv2.imshow("Sobel-y", sobely)
cv2.imshow("Sobel-contour", sobelcombine)19.Canny边缘检测
边缘检测是图像处理和计算机视觉的基本问题,边缘检测的目的是标识数字图像中亮度变化明显的点,图像属性中的显著变化通常反映了属性的重要事件和变化。这些包括:深度上的不连续,表面方向的不连续,物质属性变化和场景照明变化。边缘检测是图像处理和计算机视觉中尤其是特征提取中的一个研究领域。图像边缘检测大幅度的减少了数据量,并且剔除了可以认为不相关的信息,保留了图像重要的结构属性。
在实际的图像分割中,往往只用到一阶和二阶导数,虽然原理上,可以用更高阶的导数,但是因为噪声的影响,在纯粹二阶的导数操作中就会出现对噪声的敏感现象,三阶以上的导数信息往往失去了应用价值。二阶导数还可以说明灰度突变的类型。在某些情况下,如灰度变化均匀的图像,只利用一阶导数可能找不到边界,此时二阶导数就能提供很有用的信息。二阶导数对噪声也比较敏感,解决的方法是先对图像进行平滑滤波,消除部分噪声,再进行边缘检测。不过,利用二阶导数信息的算法是基于过零检测的,因此得到的边缘点数比较少,有利于后继的处理和识别工作。
人类视觉系统认识目标的过程分为两步:首先,把图像边缘与背景分离出来;然后,才能知觉到图像的细节,辨认出图像的轮廓。计算机视觉正是模仿人类视觉的这个过程。因此在检测物体边缘时,先对其轮廓点进行粗略检测,然后通过链接规则把原来检测到的轮廓点连接起来,同时也检测和连接遗漏的边界点及去除虚假的边界点。图像的边缘是图像的重要特征,是计算机视觉、模式识别等的基础,因此边缘检测是图象处理中一个重要的环节。然而,边缘检测又是图象处理中的一个难题,由于实际景物图像的边缘往往是各种类型的边缘及它们模糊化后结果的组合,且实际图像信号存在着噪声。噪声和边缘都属于高频信号,很难用频带做取舍。
这就需要边缘检测来进行解决的问题了。边缘检测的基本方法有很多,一阶的有Roberts Cross算子,Prewitt算子,Sobel算子,Canny算子,Krisch算子,罗盘算子;而二阶的还有Marr-Hildreth,在梯度方向的二阶导数过零点。各种算子的存在就是对这种导数分割原理进行的实例化计算,是为了在计算过程中直接使用的一种计算单位。在对图像的操作,我们采用模板对原图像进行卷积运算,从而达到我们想要的效果。而获取一幅图像的梯度就转化为:模板(Roberts、Prewitt、Sobel、Lapacian算子)对原图像进行卷积。
Canny边缘检测算子:是一种多级检测算法。1986年由John F. Canny提出,同时提出了边缘检测的三大准则:
(1).低错误率的边缘检测:检测算法应该精确地找到图像中的尽可能多的边缘,尽可能的减少漏检和误检。
(2).最优定位:检测的边缘点应该精确地定位于边缘的中心。
(3).图像中的任意边缘应该只被标记一次,同时图像噪声不应产生伪边缘。
Canny边缘检测是一种比较新的边缘检测算子,具有很好地边缘检测性能,该算子功能比前面几种都要好,但是它实现起来较为麻烦,Canny算子是一个具有滤波,增强,检测的多阶段的优化算子,在进行处理前,Canny算子先利用高斯平滑滤波器来平滑图像以除去噪声,Canny分割算法采用一阶偏导的有限差分来计算梯度幅值和方向,在处理过程中,Canny算子还将经过一个非极大值抑制的过程,最后Canny算子还采用两个阈值来连接边缘。
19.1原理
Canny 边缘检测是一种非常流行的边缘检测算法,是 John F.Canny 在1986 年提出的。它是一个有很多步构成的算法,我们接下来会逐步介绍。
(1).噪声去除
由于边缘检测很容易受到噪声影响,所以第一步是使用 5x5 的高斯滤波器 去除噪声,这个前面我们已经学过了。
(2).计算图像梯度
对平滑后的图像使用 Sobel 算子计算水平方向和竖直方向的一阶导数(图 像梯度)(Gx 和 Gy)。根据得到的这两幅梯度图(Gx 和 Gy)找到边界的梯 度和方向,公式如下:
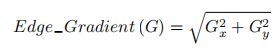

梯度的方向一般总是与边界垂直。梯度方向被归为四类:垂直,水平,和两个对角线。
(3).非极大值抑制
在获得梯度的方向和大小之后,应该对整幅图像做一个扫描,去除那些非 边界上的点。对每一个像素进行检查,看这个点的梯度是不是周围具有相同梯 度方向的点中最大的。如下图所示:

现在你得到的是一个包含“窄边界”的二值图像。
(4).滞后阈值
现在要确定那些边界才是真正的边界。 这时我们需要设置两个阈值: minVal 和 maxVal。当图像的灰度梯度高于 maxVal 时被认为是真的边界, 那些低于 minVal 的边界会被抛弃。如果介于两者之间的话,就要看这个点是 否与某个被确定为真正的边界点相连,如果是就认为它也是边界点,如果不是就抛弃。如下图:

A 高于阈值 maxVal 所以是真正的边界点,C 虽然低于 maxVal 但高于 minVal 并且与 A 相连,所以也被认为是真正的边界点。而 B 就会被抛弃,因 为他不仅低于 maxVal 而且不与真正的边界点相连。所以选择合适的 maxVal 和 minVal 对于能否得到好的结果非常重要。
在这一步,一些小的噪声点也会被除去,因为我们假设边界都是一些长的线段。
19.2 OpenCV中的Canny边界检测

在 OpenCV 中只需要一个函数:cv2.Canny(),就可以完成以上几步。 让我们看如何使用这个函数。

这个函数的第1个参数是输入图像。第2和第3 个分别是 minVal 和 maxVal,其中maxVal用于检测图像中明显的边缘,但一般情况下检测的效果不会那么完美,边缘检测出来是断断续续的。所以这时候用minVal用于将这些间断的边缘连接起来。第4个参数(可选)用来计算图像梯度的 Sobel 卷积核的大小,默认值为 3。最后一个参数(可选) L2gradient是一个布尔值,用来设定 求梯度大小的方程。如果设为 True,就使用更精确的L2范数进行计算(即两个方向的倒数的平方和再开放),否则使用方程:![]() 代替,默认值为 False。
代替,默认值为 False。
import cv2
from matplotlib import pyplot as plt
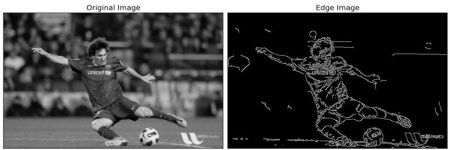
img = cv2.imread('messi5.jpg',0)
edges = cv2.Canny(img,100,200)
plt.subplot(121),plt.imshow(img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])
plt.show()结果:
示例二:
# -*- coding:utf-8 -*-
import cv2
import numpy as np
'''
步骤:
(1).彩色图像转换为灰度图像(以灰度图或者单通道图读入)
(2).对图像进行高斯模糊(去噪)
(3).计算图像梯度,根据梯度计算图像边缘幅值与角度
(4).沿梯度方向进行非极大值抑制(边缘细化)
(5).双阈值边缘连接处理
(6).二值化图像输出结果
'''
cv2.namedWindow('Cannys', 0)
# 创建滑动条
cv2.createTrackbar('minval', 'Cannys', 120, 300, lambda x: None)
cv2.createTrackbar('maxval', 'Cannys', 200, 300, lambda x: None)
cv2.createTrackbar('blur', 'Cannys', 12, 100, lambda x: None)
# 绘制等高线轮廓
def draw_Contour_Line(frame):
# 去噪
blur = cv2.getTrackbarPos('blur', 'Cannys')
frame = cv2.GaussianBlur(frame, (5, 5), blur*0.1)
# 读取滑动条数值
minval = cv2.getTrackbarPos('minval', 'Cannys')
maxval = cv2.getTrackbarPos('maxval', 'Cannys')
# threshold1 threshold2 两个阈值,小的控制边缘连接,大的控制强边缘的初始分割。如果一个像素的梯度大于上限值,则认为是边缘像素,如果小于下限阈值,则抛弃,如若点的梯度在两者之间,则当这个点与高于上限值的像素点连接时才保留,否则删除。
# aperture_size 算子内核大小,表示Sobel 算子大小,默认为3即表示一个3*3的矩阵
canny = cv2.Canny(frame, threshold1=minval, threshold2=maxval)
# canny = cv2.Canny(frame, threshold1=60, threshold2=180)
# RETR_EXTERNAL:表示只检测最外层轮廓; RETR_CCOMP:提取所有轮廓; RETR_TREE:提取所有轮廓并重新建立网状轮廓结构
# CHAIN_APPROX_SIMPLE:压缩水平方向,垂直方向,对角线方向的元素,值保留该方向的重点坐标; CHAIN_APPROX_NONE:获取每个轮廓的每个像素,相邻的两个点的像素位置差不超过1
thresh, contours, hierarchy = cv2.findContours(canny, cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
frameProcessed = np.zeros(frame.shape, dtype=np.uint8)
frameProcessed = cv2.cvtColor(frameProcessed, cv2.COLOR_GRAY2BGR)
cv2.drawContours(frameProcessed, contours, -1, color=(255, 0, 0), thickness=2) # blue
return frameProcessed
def draw_Contour_Line2(frame):
frame = cv2.GaussianBlur(frame, (5, 5), 1.5)
minval = cv2.getTrackbarPos('minval', 'Cannys')
maxval = cv2.getTrackbarPos('maxval', 'Cannys')
canny = cv2.Canny(frame, threshold1=minval, threshold2=maxval)
#canny = cv2.Canny(frame, 60, 180)
return canny
def draw_Contour_Line3(frame):
frame = cv2.GaussianBlur(frame, (5, 5), 1.5)
canny = cv2.Canny(frame, threshold1=60, threshold2=180)
# 形态学:边缘检测
_, Thr_img = cv2.threshold(canny, 210, 255, cv2.THRESH_BINARY) # 设定红色通道阈值210(阈值影响梯度运算效果)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3,3)) # 定义矩形结构元素
gradient = cv2.morphologyEx(Thr_img, cv2.MORPH_GRADIENT, kernel) # 梯度
return gradient
camera = cv2.VideoCapture(1)
while True:
ret, frame = camera.read()
gray_L = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frame_edge1 = draw_Contour_Line(gray_L)
frame_edge2 = draw_Contour_Line2(gray_L)
frame_edge3 = draw_Contour_Line3(gray_L)
cv2.imshow("frame", frame)
cv2.imshow("Canny-contour1", frame_edge1)
cv2.imshow("Canny-contour2", frame_edge2)
cv2.imshow("Canny-contour3", frame_edge3)
if cv2.waitKey(1) == ord("q"):
break
camera.release()
cv2.destroyAllWindows()结果略.
更多资源
- Canny edge detector at Wikipedia
- Canny Edge Detection Tutorial by Bill Green, 2002.

20.图像金字塔
20.1原理
一般情况下,我们要处理是一副具有固定分辨率的图像。但是有些情况下, 我们需要对同一图像的不同分辨率的子图像进行处理。比如,我们要在一幅图 像中查找某个目标,比如脸,我们不知道目标在图像中的尺寸大小。这种情况 下,我们需要创建创建一组图像,这些图像是具有不同分辨率的原始图像。我 们把这组图像叫做图像金字塔(简单来说就是同一图像的不同分辨率的子图集 合)。如果我们把最大的图像放在底部,最小的放在顶部,看起来像一座金字 塔,故而得名图像金字塔。
有两类图像金字塔:高斯金字塔和拉普拉斯金字塔。 高斯金字塔的顶部是通过将底部图像中的连续的行和列去除得到的。顶
部图像中的每个像素值等于下一层图像中 5 个像素的高斯加权平均值。这样 操作一次一个 MxN 的图像就变成了一个 M/2xN/2 的图像。所以这幅图像 的面积就变为原来图像面积的四分之一。这被称为 Octave。连续进行这样 的操作我们就会得到一个分辨率不断下降的图像金字塔。我们可以使用函数 cv2.pyrDown() 和 cv2.pyrUp() 构建图像金字塔。
函数 cv2.pyrDown() 从一个高分辨率大尺寸的图像向上构建一个金子塔
(尺寸变小,分辨率降低)。
img = cv2.imread('messi5.jpg')
lower_reso = cv2.pyrDown(higher_reso)
下图是一个四层的图像金字塔:

函数 cv2.pyrUp() 从一个低分辨率小尺寸的图像向下构建一个金子塔(尺寸变大,但分辨率不会增加)。
higher_reso2 = cv2.pyrUp(lower_reso)
higher_reso2 和 higher_reso 是不同的。因为一旦使 用 cv2.pyrDown(),图像的分辨率就会降低,信息就会被丢失。下图就是 从 cv2.pyrDown() 产生的图像金字塔的(由下到上)第三层图像使用函数 cv2.pyrUp() 得到的图像,与原图像相比分辨率差了很多。

拉普拉斯金字塔可以有高斯金字塔计算得来,公式如下:
Li = Gi − PyrUp (Gi+1)
拉普拉金字塔的图像看起来就像边界图,其中很多像素都是 0。他们经常 被用在图像压缩中。下图就是一个三层的拉普拉斯金字塔:

20.2使用金字塔进行图像融合
图像金字塔的一个应用是图像融合。例如,在图像缝合中,你需要将两幅 图叠在一起,但是由于连接区域图像像素的不连续性,整幅图的效果看起来会很差。这时图像金字塔就可以排上用场了,他可以帮你实现无缝连接。这里的一个经典案例就是将两个水果融合成一个,看看下图也许你就明白我在讲什么了:

你可以通过阅读后边的更多资源来了解更多关于图像融合,拉普拉斯金字 塔的细节。实现上述效果的步骤如下:
1. 读入两幅图像,苹果和句子
2. 构建苹果和橘子的高斯金字塔(6 层)
3. 根据高斯金字塔计算拉普拉斯金字塔
4. 在拉普拉斯的每一层进行图像融合(苹果的左边与橘子的右边融合)
5. 根据融合后的图像金字塔重建原始图像。
下图是摘自《学习 OpenCV》展示了金子塔的构建,以及如何从金字塔重建原 始图像的过程。

整个过程的代码如下。(为了简单,每一步都是独立完成的,这回消耗更多 的内存,如果你愿意的话可以对他进行优化)
import cv2
import numpy as np
A = cv2.imread('apple.jpg')
B = cv2.imread('orange.jpg')
# generate Gaussian pyramid for A
G = A.copy()
gpA = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpA.append(G)
# generate Gaussian pyramid for B
G = B.copy()
gpB = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpB.append(G)
# generate Laplacian Pyramid for A
lpA = [gpA[5]]
for i in range(5,0,-1):
GE = cv2.pyrUp(gpA[i])
L = cv2.subtract(gpA[i-1],GE)
lpA.append(L)
# generate Laplacian Pyramid for B
lpB = [gpB[5]]
for i in range(5,0,-1):
GE = cv2.pyrUp(gpB[i])
L = cv2.subtract(gpB[i-1],GE)
lpB.append(L)
# Now add left and right halves of images in each level
#numpy.hstack(tup)
#Take a sequence of arrays and stack them horizontally to make a single array.
LS = []
for la,lb in zip(lpA,lpB):
rows,cols,dpt = la.shape
ls = np.hstack((la[:,0:cols/2], lb[:,cols/2:]))
LS.append(ls)
# now reconstruct
ls_ = LS[0]
for i in range(1,6):
ls_ = cv2.pyrUp(ls_)
ls_ = cv2.add(ls_, LS[i])
# image with direct connecting each half
real = np.hstack((A[:,:cols/2],B[:,cols/2:]))
cv2.imwrite('Pyramid_blending2.jpg',ls_)
cv2.imwrite('Direct_blending.jpg',real)21.OpenCV中的轮廓
21.1初识轮廓
(1).轮廓的概念
轮廓可以简单认为成将连续的点(连着边界)连在一起的曲线,具有相同 的颜色或者灰度。轮廓在形状分析和物体的检测和识别中很有用。
• 为了更加准确,要使用二值化图像。在寻找轮廓之前,要进行阈值化处理 或者 Canny 边界检测。
• 查找轮廓的函数会修改原始图像。如果你在找到轮廓之后还想使用原始图像的话,你应该将原始图像存储到其他变量中。
• 在 OpenCV 中,查找轮廓就像在黑色背景中超白色物体。你应该记住, 要找的物体应该是白色而背景应该是黑色。
让我们看看如何在一个二值图像中查找轮廓:
函数 cv2.findContours() 有三个参数,第一个是输入图像,第二个是 轮廓检索模式,第三个是轮廓近似方法。返回值有三个,第一个是图像,第二个 是轮廓,第三个是(轮廓的)层析结构。轮廓(第二个返回值)是一个 Python 列表,其中存储这图像中的所有轮廓。每一个轮廓都是一个 Numpy 数组,包 含对象边界点(x,y)的坐标。
注意:我们后边会对第二和第三个参数,以及层次结构进行详细介绍。在那之 前,例子中使用的参数值对所有图像都是适用的。
(2).轮廓的绘制
函数 cv2.drawContours() 可以被用来绘制轮廓。它可以根据你提供 的边界点绘制任何形状。它的第一个参数是原始图像,第二个参数是轮廓,一 个 Python 列表。第三个参数是轮廓的索引(在绘制独立轮廓是很有用,当设置 -1时绘制所有轮廓)。接下来的参数是轮廓的颜色和厚度等。
在一幅图像上绘制所有的轮廓:
import cv2
im = cv2.imread('test.jpg')
imgray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
ret,thresh = cv2.threshold(imgray,127,255,0)
image, contours, hierarchy = cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)绘制独立轮廓,如第四个轮廓:
img = cv2.drawContour(img, contours, -1, (0,255,0), 3)但是大多数时候,下面的方法更有用:
img = cv2.drawContours(img, contours, 3, (0,255,0), 3)注意:最后这两种方法结果是一样的,但是后边的知识会告诉你最后一种方法 更有用。
(3).轮廓的近似方法
这是函数 cv2.findCountours() 的第三个参数。它到底代表什么意思呢?
上边我们已经提到轮廓是一个形状具有相同灰度值的边界。它会存贮形状边界上所有的 (x,y) 坐标。但是需要将所有的这些边界点都存储吗?这就是这 个参数要告诉函数 cv2.findContours 的。
这个参数如果被设置为 cv2.CHAIN_APPROX_NONE,所有的边界点 都会被存储。但是我们真的需要这么多点吗?例如,当我们找的边界是一条直 线时。你用需要直线上所有的点来表示直线吗?不是的,我们只需要这条直线 的两个端点而已。这就是cv2.CHAIN_APPROX_SIMPLE 要做的。它会将轮廓上的冗余点都去掉,压缩轮廓,从而节省内存开支。 我们用下图中的矩形来演示这个技术。在轮廓列表中的每一个坐标上画一个蓝色圆圈。第一个图显示使用 cv2.CHAIN_APPROX_NONE 的效果, 一共 734 个点。第二个图是使用 cv2.CHAIN_APPROX_SIMPLE 的结果,只有 4 个点。

21.2轮廓特征
(1).矩
图像的矩可以用于计算图像的质心,面积等。详细信息请查看Image Moments。
函数 cv2.moments() 会将计算得到的矩以一个字典的形式返回。如下:
import cv2
img = cv2.imread('star.jpg', 0)
ret, thresh = cv2.threshold(img, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, 1, 2)
cnt = contours[0]
M = cv2.moments(cnt)
print(M)根据这些矩的值,我们可以计算出对象的重心:
![]()
cx = int(M['m10']/M['m00'])
cy = int(M['m01']/M['m00'])(2).轮廓面积
轮廓的面积可以使用函数 cv2.contourArea() 计算得到,也可以使用矩(0 阶矩),M['m00']。
area = cv2.contourArea(cnt)(3).轮廓周长
也被称为弧长。可以使用函数 cv2.arcLength() 计算得到。这个函数 的第二参数可以用来指定对象的形状是闭合的(True),还是打开的(一条曲 线)。
perimeter = cv2.arcLength(cnt,True)(4).轮廓近似
将轮廓形状近似到另外一种由更少点组成的轮廓形状,新轮廓的点的数目 由我们设定的准确度来决定。使用的Douglas-Peucker算法,你可以到维基百 科获得更多此算法的细节。
为了帮助理解,假设我们要在一幅图像中查找一个矩形,但是由于图像的 种种原因,我们不能得到一个完美的矩形,而是一个“坏形状”(如下图所示)。 现在你就可以使用这个函数来近似这个形状()了。这个函数的第二个参数叫 epsilon,它是从原始轮廓到近似轮廓的最大距离。它是一个准确度参数。选 择一个好的 epsilon 对于得到满意结果非常重要。
epsilon = 0.1*cv2.arcLength(cnt,True)
approx = cv2.approxPolyDP(cnt,epsilon,True)下边,第二幅图中的绿线是当 epsilon = 10% 时得到的近似轮廓,第三幅 图是当 epsilon = 1% 时得到的近似轮廓。第三个参数设定弧线是否闭合。

(5).凸包
凸包与轮廓近似相似,但不同,虽然有些情况下它们给出的结果是一样的。 函数 cv2.convexHull() 可以用来检测一个曲线是否具有凸性缺陷,并能纠正缺陷。一般来说,凸性曲线总是凸出来的,至少是平的。如果有地方凹进去了就被叫做凸性缺陷。例如下图中的手。红色曲线显示了手的凸包,凸性缺陷被双箭头标出来了。

关于他的语法还有一些需要交代:
hull = cv2.convexHull(points[, hull[, clockwise[, returnPoints]]参数:
• points 我们要传入的轮廓
• hull 输出,通常不需要
• clockwise 方向标志。如果设置为 True,输出的凸包是顺时针方向的。 否则为逆时针方向。
• returnPoints 默认值为 True。它会返回凸包上点的坐标。如果设置 为False,就会返回与凸包点对应的轮廓上的点。
要获得上图的凸包,下面的命令就够了:
hull = cv2.convexHull(cnt)
但是如果你想获得凸性缺陷,需要把 returnPoints 设置为 False。以 上面的矩形为例,首先我们找到他的轮廓 cnt。现在我把 returnPoints 设置 为 True 查找凸包,我得到下列值:
[[[234 202]], [[ 51 202]], [[ 51 79]], [[234 79]]],其实就是矩形的四个角点。
现在把 returnPoints 设置为 False,我得到的结果是[[129],[ 67],[ 0],[142]]
他们是轮廓点的索引。例如:cnt[129] = [[234, 202]],这与前面我们得到结 果的第一个值是一样的。
(6).凸性检测
函数 cv2.isContourConvex() 可以可以用来检测一个曲线是不是凸 的。它只能返回 True 或 False。没什么大不了的。
k = cv2.isContourConvex(cnt)(7).边界矩形
有两类边界矩形:
直边界矩形 一个直矩形(就是没有旋转的矩形)。它不会考虑对象是否旋转。 所以边界矩形的面积不是最小的。可以使用函数 cv2.boundingRect() 查 找得到。(x,y)为矩形左上角的坐标,(w,h)是矩形的宽和高。
x,y,w,h = cv2.boundingRect(cnt)
img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)旋转的边界矩形 这个边界矩形是面积最小的,因为它考虑了对象的旋转。用到的函数为 cv2.minAreaRect()。返回的是一个 Box2D 结构,其中包含矩形左上角角点的坐标(x,y),矩形的宽和高(w,h),以及旋转角度。但是 要绘制这个矩形需要矩形的 4 个角点,可以通过函数 cv2.boxPoints() 获 得。
x,y,w,h = cv2.boundingRect(cnt)
img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)把这两中边界矩形显示在下图中,其中绿色的为直矩形,红的为旋转矩形。

(8).最小外接圆
函数 cv2.minEnclosingCircle() 可以帮我们找到一个对象的外切圆。它是所有能够包括对象的圆中面积最小的一个。
(x,y),radius = cv2.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
(9).椭圆拟合
使用的函数为cv2.ellipse(),返回值其实就是旋转边界矩形的内切圆。
ellipse = cv2.fitEllipse(cnt)
im = cv2.ellipse(im,ellipse,(0,255,0),2)
(10).直线拟合
我们也可以为图像中的白色点拟合出一条直线。

rows,cols = img.shape[:2]
#cv2.fitLine(points, distType, param, reps, aeps[, line ]) → line
#points – Input vector of 2D or 3D points, stored in std::vector<> or Mat.
#line – Output line parameters. In case of 2D fitting, it should be a vector of 4 elements (likeVec4f) - (vx, vy, x0, y0), where (vx, vy) is a normalized vector collinear to the line and (x0, y0) is a point on the line. In case of 3D fitting, it should be a vector of 6 elements (like Vec6f) - (vx, vy, vz,x0, y0, z0), where (vx, vy, vz) is a normalized vector collinear to the line and (x0, y0, z0) is a point on the line.
#distType – Distance used by the M-estimator
#distType=CV_DIST_L2
#ρ(r) = r2 /2 (the simplest and the fastest least-squares method)
#param – Numerical parameter ( C ) for some types of distances. If it is 0, an optimal value is chosen.
#reps – Sufficient accuracy for the radius (distance between the coordinate origin and the line).
#aeps – Sufficient accuracy for the angle. 0.01 would be a good default value for reps and aeps.
[vx,vy,x,y] = cv2.fitLine(cnt, cv2.DIST_L2,0,0.01,0.01)
lefty = int((-x*vy/vx) + y)
righty = int(((cols-x)*vy/vx)+y)
img = cv2.line(img,(cols-1,righty),(0,lefty),(0,255,0),2)21.3轮廓的属性
本小节我们将要学习提取一些经常使用的对象特征。你可以在Matlab regionprops documentation学习更多的图像特征。
(1).纵横比(Aspect Ratio)
边界矩形的宽高比:
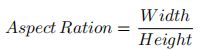
x,y,w,h = cv2.boundingRect(cnt)
aspect_ratio = float(w)/h(2). 范围(Extent)
范围是轮廓面积与边界矩形面积的比值:

area = cv2.contourArea(cnt)
x,y,w,h = cv2.boundingRect(cnt)
rect_area = w*h
extent = float(area)/rect_area(3). 固体度(Solidity)
固体度是轮廓面积与凸包面积的比:
![]()
area = cv2.contourArea(cnt)
hull = cv2.convexHull(cnt)
hull_area = cv2.contourArea(hull)
solidity = float(area)/hull_area(4).等效直径(Equivalent Diameter)
与轮廓面积相等的圆形的直径:
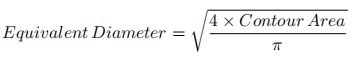
area = cv2.contourArea(cnt)
equi_diameter = np.sqrt(4*area/np.pi)(5).方向(Orientation)
方向是物体被指向的角度。下面的方法还会返回长轴和短轴的长度:
(x,y),(MA,ma),angle = cv2.fitEllipse(cnt)(6).掩模和像素点
有时我们需要构成对象的所有像素点,我们可以这样做:
mask = np.zeros(imgray.shape,np.uint8)
# 这里一定要使用参数-1, 绘制填充的的轮廓
cv2.drawContours(mask,[cnt],0,255,-1)
#返回数组的元组,每个数组对应一个维度a,其中包含该维度中非零元素的索引.
#结果总是一个二维数组,每个非零元素都有一行.
#若要按元素(而非维度)对索引进行分组,请使用:transpose(nonzero(a))
#>>> x = np.eye(3)
#>>> x
#array([[ 1., 0., 0.],
# [ 0., 1., 0.],
# [ 0., 0., 1.]])
#>>> np.nonzero(x)
#(array([0, 1, 2]), array([0, 1, 2]))
#>>> x[np.nonzero(x)]
#array([ 1., 1., 1.])
#>>> np.transpose(np.nonzero(x))
#array([[0, 0],
# [1, 1],
# [2, 2]])
pixelpoints = np.transpose(np.nonzero(mask))
#pixelpoints = cv2.findNonZero(mask)这里用了两种方法:第一种方法使用 Numpy 函数,第二种使用 OpenCV 函数。结果相同,但还是有点不同。Numpy 给出的坐标是(row, colum)形式的。而 OpenCV 给出的格式是(x,y)形式的。所以这两个结果基本是可以互换的。row=x,colunm=y。
(7).最大值和最小值及它们的位置
我们可以使用掩模图像得到这些参数:
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(imgray,mask = mask)(8).平均颜色及平均灰度
我们也可以使用相同的掩模求一个对象的平均颜色或平均灰度
mean_val = cv2.mean(im,mask = mask)(9).极点
如下图所示:

一个对象最上面,最下面,最左边,最右边的点。
leftmost = tuple(cnt[cnt[:,:,0].argmin()][0])
rightmost = tuple(cnt[cnt[:,:,0].argmax()][0])
topmost = tuple(cnt[cnt[:,:,1].argmin()][0])
bottommost = tuple(cnt[cnt[:,:,1].argmax()][0])21.4轮廓的其他函数
(1).凸缺陷(Convexity Defects)
前面我们已经学习了轮廓的凸包,对象上的任何凹陷都被成为凸缺陷。OpenCV 中有一个函数 cv2.convexityDefect() 可以帮助我们找到凸缺陷。函数调用如下:
hull = cv2.convexHull(cnt,returnPoints = False)
defects = cv2.convexityDefects(cnt,hull)注意:如果要查找凸缺陷,在使用函数 cv2.convexHull 找凸包时,参数returnPoints 一定要是 False。
它会返回一个数组,其中每一行包含的值是 [起点,终点,最远的点,到最 远点的近似距离]。我们可以在一张图上显示它。我们将起点和终点用一条绿线 连接,在最远点画一个圆圈,要记住的是返回结果的前三个值是轮廓点的索引。 所以我们还要到轮廓点中去找它们。
import cv2
img = cv2.imread('star.jpg')
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(img_gray, 127, 255,0)
contours,hierarchy = cv2.findContours(thresh,2,1)
cnt = contours[0]
hull = cv2.convexHull(cnt,returnPoints = False)
defects = cv2.convexityDefects(cnt,hull)
for i in range(defects.shape[0]): s,e,f,d = defects[i,0]
start = tuple(cnt[s][0])
end = tuple(cnt[e][0])
far = tuple(cnt[f][0])
cv2.line(img,start,end,[0,255,0],2)
cv2.circle(img,far,5,[0,0,255],-1)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()结果如下:

(2).多边形点测试(pointPolygonTest)
求解图像中的一个点到一个对象轮廓的最短距离。如果点在轮廓的外部, 返回值为负;如果在轮廓上,返回值为 0; 如果在轮廓内部,返回值为正。
下面我们以点(50,50)为例:
dist = cv2.pointPolygonTest(cnt,(50,50),True)此函数的第三个参数是 measureDist。如果设置为 True,就会计算最短距离。如果是 False,只会判断这个点与轮廓之间的位置关系(返回值为+1,-1,0)。
注意:如果不需要知道具体距离,建议将第三个参数设为 False,这样速 度会提高 2 到 3 倍.
(3).形状匹配(Match Shapes)
函数 cv2.matchShape() 可以帮我们比较两个形状或轮廓的相似度。如果返回值越小,匹配越好。它是根据 Hu 矩值来计算的。文档中对不同的方法都有解释。
我们试着将下面的图形进行比较:
import cv2
img1 = cv2.imread('star.jpg',0)
img2 = cv2.imread('star2.jpg',0)
ret, thresh = cv2.threshold(img1, 127, 255,0)
ret, thresh2 = cv2.threshold(img2, 127, 255,0)
contours,hierarchy = cv2.findContours(thresh,2,1)
cnt1 = contours[0]
contours,hierarchy = cv2.findContours(thresh2,2,1)
cnt2 = contours[0]
ret = cv2.matchShapes(cnt1,cnt2,1,0.0)
print (ret)
得到的结果是:
• A 与自己匹配 0.0
• A 与 B 匹配 0.001946
• A 与 C 匹配 0.326911
看见了吗,及时发生了旋转对匹配的结果影响也不是非常大。
注意:Hu 矩是归一化中心矩的线性组合,之所以这样做是为了能够获取代表图像的某个特征的矩函数,这些矩函数对某些变化如缩放,旋转,镜像映射(除了 h1)具有不变形。此段摘自《学习 OpenCV》中文版。
21.5轮廓的层次结构
在前面的内容中我们使用函数 cv2.findContours 来查找轮廓,我们需 要传入一个参数:轮廓提取模式(Contour_Retrieval_Mode)。我们总是把它设置为 cv2.RETR_LIST 或者 cv2.RETR_TREE,效果还可以。同时,我们得到的结果包含 3 个数组:第一个是图像,第二个是轮廓,第三 个是层次结构。
(1).层次结构的概念
通常我们使用函数 cv2.findContours 在图片中查找一个对象。有时对 象可能位于不同的位置。还有些情况,一个形状在另外一个形状的内部。这种情况下我们称外部的形状为父,内部的形状为子。按照这种方式分类,一幅图 像中的所有轮廓之间就建立父子关系。这样我们就可以确定一个轮廓与其他轮 廓是怎样连接的,比如它是不是某个轮廓的子轮廓,或者是父轮廓。这种关系就成为组织结构。
下图就是一个简单的例子:
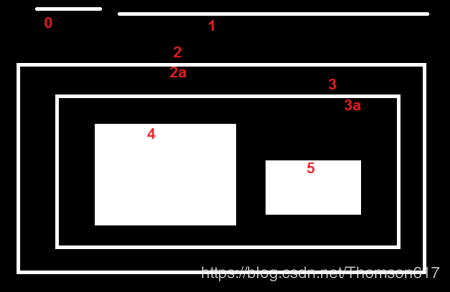
在这幅图像中,我给这几个形状编号为 0-5。2 和 2a 分别代表最外边矩形的外轮廓和内轮廓。在这里边轮廓 0,1,2 在外部或最外边。我们可以称他们为(组织结构)0 级,简单来说就是他们属于同一级。我们把2a当成轮廓 2 的子轮廓,它就成为(组织结构)第1 级。同样轮廓 3 是轮廓 2 的子轮廓,成为(组织结构)第 3 级。最后轮廓4,5 是轮廓 3a 的子轮廓,成为(组织结构)4 级(最后一级)。按照这种方式 给这些形状编号,我们可以说轮廓 4 是轮廓 3a 的子轮廓(当然轮廓 5也是)。
(2).OpenCV中的层次结构
不管层次结构是什么样的,每一个轮廓都包含自己的信息:谁是父,谁 是子等。OpenCV 使用一个含有四个元素的数组表示。[Next,Previous, First_Child,Parent]。
Next 表示同一级组织结构中的下一个轮廓。
以上图中的轮廓 0 为例,轮廓 1 就是他的 Next。同样,轮廓 1 的 Next是 2,Next=2。
那轮廓 2 呢?在同一级没有 Next。这时 Next=-1。而轮廓 4 的 Next为 5,所以它的 Next=5。
Previous 表示同一级结构中的前一个轮廓。
与前面一样,轮廓 1 的 Previous 为轮廓 0,轮廓 2 的 Previous 为轮 廓 1。轮廓 0 没有 Previous,所以 Previous=-1。
First_Child 表示它的第一个子轮廓。
没有必要再解释了,轮廓 2 的子轮廓为 2a。所以它的 First_Child 为 2a。那轮廓 3a 呢?它有两个子轮廓。但是我们只要第一个子轮廓,所以是轮 廓 4(按照从上往下,从左往右的顺序排序)。
Parent 表示它的父轮廓。
与 First_Child 刚好相反。轮廓 4 和 5 的父轮廓是 3a。而轮廓 3a的父轮廓是3。
注意:如果没有父或子,就为 -1。
现在我么了解了 OpenCV 中的轮廓组织结构。我们还是根据上边的图片 再学习一下 OpenCV 中的轮廓检索模式。
cv2.RETR_LIST,cv2.RETR_TREE,cv2.RETR_CCOMP,cv2.RETR_EXTERNAL
到底代表什么意思?
(3).轮廓检索模式
RETR_LIST 从解释的角度来看,这中应是最简单的。它只是提取所有的轮 廓,而不去创建任何父子关系。换句话说就是“人人平等”,它们属于同一级组织轮廓。
所以在这种情况下,组织结构数组的第三和第四个数都是 -1。但是,很明显,Next 和 Previous 要有对应的值,你可以自己试着看看。下面就是得到的结果,每一行是对应轮廓的组织结构细节。例如,第一 行对应的是轮廓 0。下一个轮廓为 1,所以 Next=1。前面没有其他轮廓,所 以 Previous=0。接下来的两个参数就是-1,与刚才我们说的一样。

如果你不关心轮廓之间的关系,这是一个非常好的选择。
RETR_EXTERNAL 如果你选择这种模式的话,只会返回最外边的的轮廓, 所有的子轮廓都会被忽略掉。
所以在上图中使用这种模式的话只会返回最外边的轮廓(第 0 级):轮廓0,1,2。下面是我选择这种模式得到的结果:

当你只想得到最外边的轮廓时,你可以选择这种模式。这在有些情况下很 有用。
RETR_CCOMP 在这种模式下会返回所有的轮廓并将轮廓分为两级组织结 构。例如,一个对象的外轮廓为第 1 级组织结构。而对象内部中空洞的轮廓为第 2 级组织结构,空洞中的任何对象的轮廓又是第 1 级组织结构。空洞的组织结构为第 2 级。想象一下一副黑底白字的图像,图像中是数字 0。0 的外边界属于第一级 组织结构,0 的内部属于第 2 级组织结构。
我们可以以下图为例简单介绍一下。我们已经用红色数字为这些轮廓编号, 并用绿色数字代表它们的组织结构。顺序与 OpenCV 检测轮廓的顺序一直。

现在考虑轮廓 0,它的组织结构为第 1 级。其中有两个空洞 1 和 2, 它们属于第 2 级组织结构。所以对于轮廓 0 来说跟他属于同一级组织结构的 下一个(Next)是轮廓 3,并且没有 Previous。它的 Fist_Child 为轮廓 1, 组织结构为 2。由于它是第 1 级,所以没有父轮廓。因此它的组织结构数组为 [3,-1,1,-1]。
现在是轮廓 1,它是第 2 级。处于同一级的下一个轮廓为 2。没有 Previ- ous,也没有 Child,(因为是第 2 级所以有父轮廓)父轮廓是 0。所以数组是 [2,-1,-1,0]。
轮廓 2:它是第 2 级。在同一级的组织结构中没有 Next。Previous 为轮 廓 1。没有子,父轮廓为 0,所以数组是 [-1,1,-1,0]
轮廓 3:它是第 1 级。在同一级的组织结构中 Next 为 5。Previous 为 轮廓 0。子为 4,没有父轮廓,所以数组是 [5,0,4,-1]
轮廓 4:它是第 2 级。在同一级的组织结构中没有 Next。没有 Previous, 没有子,父轮廓为 3,所以数组是 [-1,-1,-1,3]
下面是我得到的答案:

RETR_TREE 是最完美的一个。这种模式下会返回所有轮廓,并且创建一个完整的组织结构列表。它甚至会告诉你谁是爷爷,爸 爸,儿子,孙子等。
还是以上图为例,使用这种模式,对 OpenCV 返回的结果重新排序并分 析它,红色数字是边界的序号,绿色是组织结构。
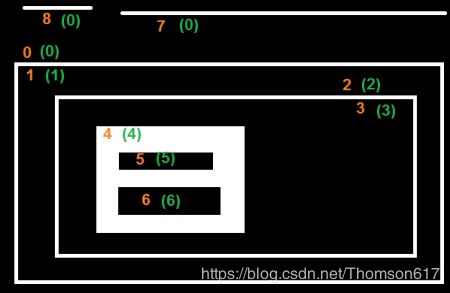
轮廓 0 的组织结构为 0,同一级中 Next 为 7,没有 Previous。子轮廓 是 1,没有父轮廓。所以数组是 [7,-1,1,-1]。
轮廓 1 的组织结构为 1,同一级中没有其他,没有 Previous。子轮廓是 2,父轮廓为 0。所以数组是 [-1,-1,2,0]。
剩下的自己试试计算一下吧。下面是结果:

22.直方图
22.1直方图的计算,绘制与分析
-
-
-
- 使用 OpenCV 或 Numpy 函数计算直方图
- 使用 Opencv 或者 Matplotlib 函数绘制直方图
- 将要学习的函数有:cv2.calcHist(),np.histogram()
-
-
什么是直方图呢?通过直方图你可以对整幅图像的灰度分布有一个整体的 了解。直方图的 x 轴是灰度值(0 到 255),y 轴是图片中具有同一个灰度值的 点的数目。
直方图其实就是对图像的另一种解释。一下图为例,通过直方图我们可以 对图像的对比度,亮度,灰度分布等有一个直观的认识。几乎所有的图像处理 软件都提供了直方图分析功能。下图来自Cambridge in Color website,强 烈推荐你到这个网站了解更多知识。
让我们来一起看看这幅图片和它的直方图吧。(要记住,直方图是根据灰度 图像绘制的,而不是彩色图像)。直方图的左边区域像是了暗一点的像素数量, 右侧显示了亮一点的像素的数量。从这幅图上你可以看到灰暗的区域比两的区 域要大,而处于中间部分的像素点很少。
(1).统计直方图
现在我们知道什么是直方图了, 那怎样获得一副图像的直方图呢? OpenCV和Numpy 都有内置函数做这件事。在使用这些函数之前我们有 必要想了解一下直方图相关的术语。
BINS:上面的直方图显示了每个灰度值对应的像素数。如果像素值为 0 到 255,你就需要 256 个数来显示上面的直方图。但是,如果你不需要知道每一个像素值的像素点数目的,而只希望知道两个像素值之间的像素点数目怎么办呢?举例来说,我们想知道像素值在 0 到 15 之间的像素点的数目,接着 是 16 到 31,....,240 到 255。我们只需要 16 个值来绘制直方图。OpenCV Tutorials on histograms中例子所演示的内容。
那到底怎么做呢?你只需要把原来的 256 个值等分成 16 小组,取每组的总和。而这里的每一个小组就被成为 BIN。第一个例子中有 256 个 BIN,第 二个例子中有 16个 BIN。在 OpenCV 的文档中用 histSize 表示 BINS。
DIMS:表示我们收集数据的参数数目。在本例中,我们对收集到的数据只考虑一件事:灰度值。所以这里就是 1。
RANGE:就是要统计的灰度值范围,一般来说为 [0,256],也就是说所有的灰度值
使用 OpenCV 统计直方图 函数 cv2.calcHist 可以帮助我们统计一幅图像的直方图。我们一起来熟悉一下这个函数和它的参数:
cv2.calcHist(images, channels, mask, histSize, ranges[, hist[, accumulate]])
1. images: 原图像(图像格式为 uint8 或 float32)。当传入函数时应该 用中括号 [] 括起来,例如:[img]。
2. channels: 同样需要用中括号括起来,它会告诉函数我们要统计那幅图 像的直方图。如果输入图像是灰度图,它的值就是 [0];如果是彩色图像 的话,传入的参数可以是 [0],[1],[2] 它们分别对应着通道 B,G,R。
3. mask: 掩模图像。要统计整幅图像的直方图就把它设为 None。但是如 果你想统计图像某一部分的直方图的话,你就需要制作一个掩模图像,并 使用它。(后边有例子)
4. histSize:BIN 的数目。也应该用中括号括起来,例如:[256]。
5. ranges: 像素值范围,通常为 [0,256]
让我们从一副简单图像开始吧。以灰度格式加载一幅图像并统计图像的直方图。
img = cv2.imread('home.jpg',0)
# 别忘了中括号 [img],[0],None,[256],[0,256],只有 mask 没有中括号
hist = cv2.calcHist([img],[0],None,[256],[0,256])
hist 是一个 256x1 的数组,每一个值代表了与次灰度值对应的像素点数目。
使用 Numpy 统计直方图 Numpy 中的函数 np.histogram() 也可以帮 我们统计直方图。你也可以尝试一下下面的代码:
#img.ravel() 将图像转成一维数组,这里没有中括号。
hist,bins = np.histogram(img.ravel(),256,[0,256])
hist 与上面计算的一样。但是这里的 bins 是 257,因为 Numpy 计算 bins 的方式为:0-0.99,1-1.99,2-2.99 等。所以最后一个范围是 255-255.99。 为了表示它,所以在 bins 的结尾加上了 256。但是我们不需要 256,到 255 就够了。
其 他:Numpy 还 有 一 个 函 数 np.bincount(), 它 的 运 行 速 度 是 np.histgram 的 十 倍。 所 以 对 于 一 维 直 方 图, 我 们 最 好 使 用 这 个 函 数。 使 用 np.bincount 时 别 忘 了 设 置 minlength=256。 例 如, hist=np.bincount(img.ravel(),minlength=256)
注 意:OpenCV的函数要比 np.histgram()快40倍.所以坚持使用OpenCV 函数.
(2).绘制直方图
有两种方法来绘制直方图:
1.Short Way(简单方法):使用 Matplotlib 中的绘图函数。
2.Long Way(复杂方法):使用 OpenCV 绘图函数
使用 Matplotlib 中有直方图绘制函数:matplotlib.pyplot.hist()
它可以直接统计并绘制直方图。你应该使用函数 calcHist() 或 np.histogram()
统计直方图。代码如下:
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('home.jpg',0)
plt.hist(img.ravel(),256,[0,256])
plt.show()你会得到下面这样一幅图:

或者你可以只使用 matplotlib 的绘图功能,这在同时绘制多通道(BGR) 的直方图,很有用。但是要告诉绘图函数你的直方图数据在哪里。运行 一下下面的代码:
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('home.jpg')
color = ('b','g','r')
# 对一个列表或数组既要遍历索引又要遍历元素时使用内置enumerrate函数会有更加直接,优美的做法enumerate 会将数组或列表组成一个索引序列。使我们再获取索引和索引内容的时候更加方便
for i,col in enumerate(color):
histr = cv2.calcHist([img],[i],None,[256],[0,256])
plt.plot(histr,color = col)
plt.xlim([0,256])
plt.show()结果:

从上边的直方图你可以推断出蓝色曲线靠右侧的最多(很明显这些就是天空)
使用 OpenCV 使用 OpenCV 自带函数绘制直方图比较麻烦,这里不作介 绍,有兴趣可以自己研究。可以参考 OpenCV-Python2 的官方示例。
(3).使用掩模
要统计图像某个局部区域的直方图只需构建一副掩模图像。将要统计的部分设置成白色,其余部分为黑色,就构成一副掩模图像。然后把这个掩模图像传给函数就可以了。
img = cv2.imread('home.jpg',0)
# create a mask
mask = np.zeros(img.shape[:2], np.uint8)
mask[100:300, 100:400] = 255
masked_img = cv2.bitwise_and(img,img,mask = mask)
# Calculate histogram with mask and without mask
# Check third argument for mask
hist_full = cv2.calcHist([img],[0],None,[256],[0,256])
hist_mask = cv2.calcHist([img],[0],mask,[256],[0,256])
plt.subplot(221), plt.imshow(img, 'gray')
plt.subplot(222), plt.imshow(mask,'gray')
plt.subplot(223), plt.imshow(masked_img, 'gray')
plt.subplot(224), plt.plot(hist_full), plt.plot(hist_mask)
plt.xlim([0,256])
plt.show()结果如下,其中蓝线是整幅图像的直方图,绿线是进行掩模之后的直方图。

22.2直方图均衡化
如果一副图像中的大多是像素点的像素值都集中在一个像素值范围之内会怎样呢?例如,如果一幅图片整体很亮,那所有的像素值应该都会很高。但是一副高质量的图像的像素值分布应该很广泛。所以你应该把它的直方图做一个横向拉伸(如下图),这就是直方图均衡化要做的事情。通常情况下这种操作会改善图像的对比度。

推荐你去读读维基百科中关于直方图均衡化的条目。其中的解释非常给力, 读完之后相信你就会对整个过程有一个详细的了解了。我们先看看怎样使用 Numpy 来进行直方图均衡化,然后再学习使用 OpenCV 进行直方图均衡化。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('wiki.jpg',0)
#flatten() 将数组变成一维
hist,bins = np.histogram(img.flatten(),256,[0,256])
# 计算累积分布图
cdf = hist.cumsum()
cdf_normalized = cdf * hist.max()/ cdf.max()
plt.plot(cdf_normalized, color = 'b')
plt.hist(img.flatten(),256,[0,256], color = 'r')
plt.xlim([0,256])
plt.legend(('cdf','histogram'), loc = 'upper left')
plt.show()
我们可以看出来直方图大部分在灰度值较高的部分,而且分布很集中。而我们希望直方图的分布比较分散,能够涵盖整个 x 轴。所以,我们就需要一个变换函数帮助我们把现在的直方图映射到一个广泛分布的直方图中。这就是直方图均衡化要做的事情。
我们现在要找到直方图中的最小值(除了 0),并把它用于 wiki 中的直方图均衡化公式。但是我在这里使用了 Numpy 的掩模数组。对于掩模数组的所有操作都只对 non-masked 元素有效。你可以到 Numpy 文档中获取更多掩 模数组的信息。
# 构建 Numpy 掩模数组,cdf 为原数组,当数组元素为 0 时,掩盖(计算时被忽略)。
cdf_m = np.ma.masked_equal(cdf,0)
cdf_m = (cdf_m - cdf_m.min())*255/(cdf_m.max()-cdf_m.min())
# 对被掩盖的元素赋值,这里赋值为 0
cdf = np.ma.filled(cdf_m,0).astype('uint8')现在就获得了一个表,我们可以通过查表得知与输入像素对应的输出像素的值。我们只需要把这种变换应用到图像上就可以了。
img2 = cdf[img]我们再根据前面的方法绘制直方图和累积分布图,结果如下:

另一个重要的特点是,即使我们的输入图片是一个比较暗的图片(不像上边我们用到的整体都很亮的图片),在经过直方图均衡化之后也能得到相同的 结果。因此,直方图均衡化经常用来使所有的图片具有相同的亮度条件的参考工具。这在很多情况下都很有用。例如,脸部识别,在训练分类器前,训练集 的所有图片都要先进行直方图均衡化从而使它们达到相同的亮度条件。
OpenCV中的直方图均衡化
OpenCV 中的直方图均衡化函数为 cv2.equalizeHist()。这个函数的输入图片仅仅是一副灰度图像,输出结果是直方图均衡化之后的图像。
下边的代码还是对上边的那幅图像进行直方图均衡化:
img = cv2.imread('wiki.jpg',0)
equ = cv2.equalizeHist(img)
res = np.hstack((img,equ))
#stacking images side-by-side
cv2.imwrite('res.png',res)
现在你可以拿一些不同亮度的照片自己来试一下了。 当直方图中的数据集中在某一个灰度值范围内时,直方图均衡化很有用。但是如果像素的变化很大,而且占据的灰度范围非常广时,例如:既有很亮的 像素点又有很暗的像素点时。请查看更多资源中的 SOF 链接。
CLAHE有限对比适应性直方图均衡化
我们在上边做的直方图均衡化会改变整个图像的对比度,但是在很多情况下,这样做的效果并不好。例如,下图分别是输入图像和进行直方图均衡化之后的输出图像。

的确在进行完直方图均衡化之后,图片背景的对比度被改变了。但是你再对比一下两幅图像中雕像的面图,由于太亮我们丢失了很多信息。造成这种结果的根本原因在于这幅图像的直方图并不是集中在某一个区域(试着画出它的直方图就明白了)。
为了解决这个问题,我们需要使用自适应的直方图均衡化。这种情况下, 整幅图像会被分成很多小块,这些小块被称为“tiles”(在 OpenCV 中 tiles 的 大小默认是 8x8),然后再对每一个小块分别进行直方图均衡化(跟前面类似)。 所以在每一个的区域中,直方图会集中在某一个小的区域中(除非有噪声干 扰)。如果有噪声的话,噪声会被放大。为了避免这种情况的出现要使用对比度 限制。对于每个小块来说,如果直方图中的 bin 超过对比度的上限的话,就把 其中的像素点均匀分散到其他 bins 中,然后在进行直方图均衡化。最后,为了去除每一个小块之间“人造的”(由于算法造成)边界,再使用双线性差值,对小块进行缝合。
下面的代码显示了如何使用 OpenCV 中的 CLAHE。
import numpy as np
import cv2
img = cv2.imread('tsukuba_l.png',0)
# create a CLAHE object (Arguments are optional).
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
cl1 = clahe.apply(img)
cv2.imwrite('clahe_2.jpg',cl1)下面就是结果了,与前面的结果对比一下,尤其是雕像区域:

更多资源
1. 维基百科中的直方图均衡化。
2. Masked Arrays in Numpy
关于调整图片对比度 SOF 问题:
1. 在 C 语言中怎样使用 OpenCV 调整图像对比度.
2. 怎样使用 OpenCV 调整图像的对比度和亮度.
22.3 2D直方图
在前面的部分我们介绍了如何绘制一维直方图,之所以称为一维,是因为我们只考虑了图像的一个特征:灰度值。但是在 2D 直方图中我们就要考虑 两个图像特征。对于彩色图像的直方图通常情况下我们需要考虑每个的颜色(Hue)和饱和度(Saturation)。根据这两个特征绘制 2D 直方图。
OpenCV 的官方文档中包含一个创建彩色直方图的例子。本节就是要和大 家一起来学习如何绘制颜色直方图,这会对我们下一节学习直方图投影有所帮 助。
OpenCV 中的 2D 直方图
使用函数 cv2.calcHist() 来计算直方图既简单又方便。如果要绘制颜色 直方图的话,我们首先需要将图像的颜色空间从 BGR 转换到 HSV。(记住, 计算一维直方图,要从 BGR 转换到 HSV)。计算 2D 直方图,函数的参数要 做如下修改:
• channels=[0,1] 因为我们需要同时处理 H 和 S 两个通道。
• bins=[180,256]H 通道为 180,S 通道为 256。
• range=[0,180,0,256]H 的取值范围在 0 到 180,S 的取值范围 在 0 到 256。
代码如下:
import cv2
import numpy as np
img = cv2.imread('home.jpg')
hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
hist = cv2.calcHist([hsv], [0, 1], None, [180, 256], [0, 180, 0, 256])Numpy中2D直方图
Numpy 同样提供了绘制 2D 直方图的函数:np.histogram2d()。(还记得吗,绘制 1D 直方图时我们使用的是 np.histogram())。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('home.jpg')
hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
hist, xbins, ybins = np.histogram2d(h.ravel(),s.ravel(),[180,256],[[0,180],[0,256]])第一个参数是 H 通道,第二个参数是 S 通道,第三个参数是 bins 的数 目,第四个参数是数值范围。
现在我们要看看如何绘制颜色直方图。
绘制2D直方图
方法 1:使用 cv2.imshow() 我们得到结果是一个 180x256 的两维数组。 所以我们可以使用函数 cv2.imshow() 来显示它。但是这是一个灰度图,除 非我们知道不同颜色 H 通道的值,否则我们根本就不知道那到底代表什么颜 色。
方法 2:使用 Matplotlib() 我们还可以使用函数 matplotlib.pyplot.imshow() 来绘制 2D 直方图,再搭配上不同的颜色图(color_map)。这样我们会对每 个点所代表的数值大小有一个更直观的认识。但是跟前面的问题一样,你还是 不知道那个数代表的颜色到底是什么。虽然如此,我还是更喜欢这个方法,它 既简单又好用。
注意:在使用这个函数时,要记住设置插值参数为 nearest。
代码如下:
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('home.jpg')
hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
hist = cv2.calcHist( [hsv], [0, 1], None, [180, 256], [0, 180, 0, 256] )
plt.imshow(hist,interpolation = 'nearest')
plt.show()下面是输入图像和颜色直方图。X 轴显示 S 值,Y 轴显示 H 值。
在直方图中,你可以看到在 H=100,S=100 附近有比较高的值。这部分与天的蓝色相对应。同样另一个峰值在 H=25 和 S=100 附近。这一宫殿的黄 色相对应。你可用通过使用图像编辑软件(GIMP)修改图像,然后在绘制直方图看看我说的对不对。
方法 3:OpenCV 风格 在官方文档中有一个关于颜色直方图的例子。运行 一下这个代码,你看到的颜色直方图也显示了对应的颜色。简单来说就是:输 出结果是一副由颜色编码的直方图。效果非常好(虽然要添加很多代码)。
在那个代码中,作者首先创建了一个 HSV 格式的颜色地图,然后把它转 换成 BGR 格式。再将得到的直方图与颜色直方图相乘。作者还用了几步来去 除小的孤立的的点,从而得到了一个好的直方图。
我把对代码的分析留给你们了,自己去玩一下把。下边是对上边的图运行 这段代码之后得到的结果:
从直方图中我们可以很清楚的看出它们代表的颜色,蓝色,换色,还有棋盘带来的白色,漂亮!!
练习
import numpy as np
import cv2
from time import clock
import sys
import video # video 模块也是 opencv 官方文档中自带的
if __name__ == '__main__':
# 构建 HSV 颜色地图
hsv_map = np.zeros((180, 256, 3), np.uint8)
# np.indices 可以返回由数组索引构建的新数组。
# 例如:np.indices( 3,2);其中(3,2)为原来数组的维度:行和列。
# 返回值首先看输入的参数有几维:(3,2)有2维,所以从输出的结果应该是[[a],[b]], 其中包含两个3行,2列数组。第二看每一维的大小,第一维为3,所以a中的值就0到2(最大索引数),a中的每一个值就是它的行索引;同样的方法得到 b(列索引)
# 结果就是: array([[[0, 0],[1, 1],[2, 2]], [[0, 1],0, 1],[0, 1]]])
h, s = np.indices(hsv_map.shape[:2])
hsv_map[:, :, 0] = h
hsv_map[:, :, 1] = s
hsv_map[:, :, 2] = 255
hsv_map = cv2.cvtColor(hsv_map, cv2.COLOR_HSV2BGR)
cv2.imshow('hsv_map', hsv_map)
cv2.namedWindow('hist', 0)
hist_scale = 10
def set_scale(val):
global hist_scale
hist_scale = val
cv2.createTrackbar('scale', 'hist', hist_scale, 32, set_scale)
try:
fn = sys.argv[1]
except:
fn = 0
cam = video.create_capture(fn, fallback='synth:bg=../cpp/baboon.jpg:class=chess:noise=0.05')
while True:
flag, frame = cam.read()
cv2.imshow('camera', frame)
# 图像金字塔
# 通过图像金字塔降低分辨率,但不会对直方图有太大影响。
# 但这种低分辨率,可以很好抑制噪声,从而去除孤立的小点对直方图的影响。
small = cv2.pyrDown(frame)
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
# 取 v 通道 (亮度) 的值。
# dark = hsv[...,2] < 32
# 此步操作得到的是一个布尔矩阵,小于 32 的为真,大于 32 的为假。
dark = hsv[:, :, 2] < 32
hsv[dark] = 0
h = cv2.calcHist([hsv], [0, 1], None, [180, 256], [0, 180, 0, 256])
# numpy.clip(a, a_min, a_max, out=None)[source]
# 给定一个区间,区间外的值被裁剪到区间边缘。例如,如果指定的间隔为[0,1],小于0的值将变为0,大于1的值将变为1。
# >>> a = np.arange(10)
# >>> np.clip(a, 1, 8)
# array([1, 1, 2, 3, 4, 5, 6, 7, 8, 8])
h = np.clip(h * 0.005 * hist_scale, 0, 1)
# 可以在切片语法中使用'newaxis'对象来创建长度为1的轴。也可以用None代替newaxis,效果完全一样
# h 从一维变成 3 维
vis = hsv_map * h[:, :, np.newaxis] / 255.0
cv2.imshow('hist', vis)
ch = 0xFF & cv2.waitKey(1)
if ch == 27:
break
cv2.destroyAllWindows()22.4 直方图反向投影
直方图反向投影是由 Michael J. Swain 和 Dana H. Ballard 在他们的 文章“Indexing via color histograms”中提出。
那它到底是什么呢?它可以用来做图像分割,或者在图像中找寻我们感兴 趣的部分。简单来说,它会输出与输入图像(待搜索)同样大小的图像,其中 的每一个像素值代表了输入图像上对应点属于目标对象的概率。用更简单的话 来解释,输出图像中像素值越高(越白)的点就越可能代表我们要搜索的目标(在输入图像所在的位置)。这是一个直观的解释。直方图投影经常与 camshift算法等一起使用。 我们应该怎样来实现这个算法呢?首先我们要为一张包含我们要查找目标的图像创建直方图(在我们的示例中,我们要查找的是草地,其他的都不要)。 我们要查找的对象要尽量占满这张图像(换句话说,这张图像上最好是有且仅 有我们要查找的对象)。最好使用颜色直方图,因为一个物体的颜色要比它的灰 度能更好的被用来进行图像分割与对象识别。接着我们再把这个颜色直方图投 影到输入图像中寻找我们的目标,也就是找到输入图像中的每一个像素点的像 素值在直方图中对应的概率,这样我们就得到一个概率图像,最后设置适当的 阈值对概率图像进行二值化,就这么简单。
Numpy 中的算法
此处的算法与上边介绍的算法稍有不同。 首先,我们要创建两幅颜色直方图,目标图像的直方图('M'),(待搜索)输入图像的直方图('I')。
import cv2
import numpy as np
from matplotlib import pyplot as plt
#roi is the object or region of object we need to find
roi = cv2.imread('rose_red.png')
hsv = cv2.cvtColor(roi,cv2.COLOR_BGR2HSV)
#target is the image we search in
target = cv2.imread('rose.png')
hsvt = cv2.cvtColor(target,cv2.COLOR_BGR2HSV)
# Find the histograms using calcHist. Can be done with np.histogram2d also
M = cv2.calcHist([hsv],[0, 1], None, [180, 256], [0, 180, 0, 256] )
I = cv2.calcHist([hsvt],[0, 1], None, [180, 256], [0, 180, 0, 256] )计算比值:R = M 。反向投影 R,也就是根据 R 这个”调色板“创建一 副新的图像,其中的每一个像素代表这个点就是目标的概率。例如 B (x, y) = R [h (x, y) , s (x, y)],其中 h 为点(x,y)处的 hue 值,s 为点(x,y)处的 saturation 值。最后加入再一个条件 B (x, y) = min [B (x, y) , 1]。
h,s,v = cv2.split(hsvt)
B = R[h.ravel(),s.ravel()]
B = np.minimum(B,1)
B = B.reshape(hsvt.shape[:2])现在使用一个圆盘算子做卷积,B = D × B,其中 D 为卷积核。
disc = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(5,5))
B=cv2.filter2D(B,-1,disc)
B = np.uint8(B)
cv2.normalize(B,B,0,255,cv2.NORM_MINMAX)现在输出图像中灰度值最大的地方就是我们要查找的目标的位置了。如果 我们要找的是一个区域,我们就可以使用一个阈值对图像进行二值化,这样就 可以得到一个很好的结果了。
ret,thresh = cv2.threshold(B,50,255,0)就是这样。
OpenCV 中的反向投影
OpenCV 提供的函数 cv2.calcBackProject() 可以用来做直方图反向 投影。它的参数与函数 cv2.calcHist 的参数基本相同。其中的一个参数是我 们要查找目标的直方图。同样再使用目标的直方图做反向投影之前我们应该先 对其做归一化处理。返回的结果是一个概率图像,我们再使用一个圆盘形卷积 核对其做卷操作,最后使用阈值进行二值化。下面就是代码和结果:
import cv2
import numpy as np
roi = cv2.imread('tar.jpg')
hsv = cv2.cvtColor(roi,cv2.COLOR_BGR2HSV)
target = cv2.imread('roi.jpg')
hsvt = cv2.cvtColor(target,cv2.COLOR_BGR2HSV)
# calculating object histogram
roihist = cv2.calcHist([hsv],[0, 1], None, [180, 256], [0, 180, 0, 256] )
# normalize histogram and apply backprojection
# 归一化:原始图像,结果图像,映射到结果图像中的最小值,最大值,归一化类型
#cv2.NORM_MINMAX 对数组的所有值进行转化,使它们线性映射到最小值和最大值之间
# 归一化之后的直方图便于显示,归一化之后就成了 0 到 255 之间的数了。
cv2.normalize(roihist,roihist,0,255,cv2.NORM_MINMAX)
dst = cv2.calcBackProject([hsvt],[0,1],roihist,[0,180,0,256],1)
# Now convolute with circular disc
# 此处卷积可以把分散的点连在一起
disc = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(5,5))
dst=cv2.filter2D(dst,-1,disc)
# threshold and binary AND
ret,thresh = cv2.threshold(dst,50,255,0)
# 别忘了是三通道图像,因此这里使用 merge 变成 3 通道
thresh = cv2.merge((thresh,thresh,thresh))
# 按位操作
res = cv2.bitwise_and(target,thresh)
res = np.hstack((target,thresh,res))
cv2.imwrite('res.jpg',res)
# 显示图像
cv2.imshow('1',res) cv2.waitKey(0)下面是我使用的一幅图像。我使用图中蓝色矩形中的区域作为取样对象, 再根据这个样本搜索图中所有的类似区域(草地)。

23.图像变换--傅里叶变换
傅里叶变换经常被用来分析不同滤波器的频率特性。我们可以使用 2D 离 散傅里叶变换 (DFT) 分析图像的频域特性。实现 DFT 的一个快速算法被称为 快速傅里叶变换(FFT)。关于傅里叶变换的细节知识可以在任意一本图像处 理或信号处理的书中找到。请查看本小节中更多资源部分。
对于一个正弦信号:x (t) = A sin (2πft), 它的频率为 f,如果把这个信号 转到它的频域表示,我们会在频率 f 中看到一个峰值。如果我们的信号是由采 样产生的离散信号好组成,我们会得到类似的频谱图,只不过前面是连续的, 现在是离散。你可以把图像想象成沿着两个方向采集的信号。所以对图像同时 进行 X 方向和 Y 方向的傅里叶变换,我们就会得到这幅图像的频域表示(频谱 图)。
更直观一点,对于一个正弦信号,如果它的幅度变化非常快,我们可以说 他是高频信号,如果变化非常慢,我们称之为低频信号。你可以把这种想法应 用到图像中,图像那里的幅度变化非常大呢?边界点或者噪声。所以我们说边 界和噪声是图像中的高频分量(注意这里的高频是指变化非常快,而非出现的 次数多)。如果没有如此大的幅度变化我们称之为低频分量。
23.1 Numpy 中的傅里叶变换
首先我们看看如何使用 Numpy 进行傅里叶变换。Numpy 中的 FFT 包可以帮助我们实现快速傅里叶变换。函数 np.fft.fft2() 可以对信号进行频率转 换,输出结果是一个复杂的数组。本函数的第一个参数是输入图像,要求是灰 度格式。第二个参数是可选的, 决定输出数组的大小。输出数组的大小和输入图 像大小一样。如果输出结果比输入图像大,输入图像就需要在进行 FFT 前补 0。如果输出结果比输入图像小的话,输入图像就会被切割。
现在我们得到了结果,频率为 0 的部分(直流分量)在输出图像的左上角。 如果想让它(直流分量)在输出图像的中心,我们还需要将结果沿两个方向平移2 。函数 np.fft.fftshift() 可以帮助我们实现这一步。(这样更容易分析)。 进行完频率变换之后,我们就可以构建振幅谱了。
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg',0)
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
# 这里构建振幅图的公式没学过
magnitude_spectrum = 20*np.log(np.abs(fshift))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()结果如下:

我们可以看到输出结果的中心部分更白(亮),这说明低频分量更多。 现在我们可以进行频域变换了, 我们就可以在频域对图像进行一些操作了,例如高通滤波和重建图像(DFT 的逆变换)。比如我们可以使用一个 60x60 的矩形窗口对图像进行掩模操作从而去除低频分量。然后再使用函数 np.fft.ifftshift() 进行逆平移操作,所以现在直流分量又回到左上角了,左 后使用函数 np.ifft2() 进行 FFT 逆变换。同样又得到一堆复杂的数字,我们 可以对他们取绝对值:
rows, cols = img.shape
crow,ccol = rows/2 , cols/2
fshift[crow-30:crow+30, ccol-30:ccol+30] = 0
f_ishift = np.fft.ifftshift(fshift)
img_back = np.fft.ifft2(f_ishift)
# 取绝对值
img_back = np.abs(img_back)
plt.subplot(131),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(132),plt.imshow(img_back, cmap = 'gray')
plt.title('Image after HPF'), plt.xticks([]), plt.yticks([]) plt.subplot(133),plt.imshow(img_back)
plt.title('Result in JET'), plt.xticks([]), plt.yticks([])
plt.show()结果如下:

上图的结果显示高通滤波其实是一种边界检测操作。这就是我们在前面图 像梯度那一章看到的。同时我们还发现图像中的大部分数据集中在频谱图的低 频区域。我们现在已经知道如何使用 Numpy 进行 DFT 和 IDFT 了,接着我 们来看看如何使用 OpenCV 进行这些操作。
如果你观察仔细的话,尤其是最后一章 JET 颜色的图像,你会看到一些不 自然的东西(如我用红色箭头标出的区域)。看上图那里有些条带装的结构,这 被成为振铃效应。这是由于我们使用矩形窗口做掩模造成的。这个掩模被转换 成正弦形状时就会出现这个问题。所以一般我们不适用矩形窗口滤波。最好的 选择是高斯窗口。
23.2 OpenCV 中的傅里叶变换
OpenCV 中相应的函数是 cv2.dft() 和 cv2.idft()。和前面输出的结果 一样,但是是双通道的。第一个通道是结果的实数部分,第二个通道是结果的 虚数部分。输入图像要首先转换成 np.float32 格式。我们来看看如何操作。
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg',0)
dft = cv2.dft(np.float32(img),flags = cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
magnitude_spectrum = 20*np.log(cv2.magnitude(dft_shift[:,:,0],dft_shift[:,:,1]))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()注意:你可以使用函数 cv2.cartToPolar(),它会同时返回幅度和相位。
现在我们来做逆 DFT。在前面的部分我们实现了一个 HPF(高通滤波), 现在我们来做 LPF(低通滤波)将高频部分去除。其实就是对图像进行模糊操 作。首先我们需要构建一个掩模,与低频区域对应的地方设置为 1, 与高频区域 对应的地方设置为 0。
rows, cols = img.shape
crow,ccol = rows/2 , cols/2
# create a mask first, center square is 1, remaining all zeros
mask = np.zeros((rows,cols,2),np.uint8)
mask[crow-30:crow+30, ccol-30:ccol+30] = 1
# apply mask and inverse DFT
fshift = dft_shift*mask
f_ishift = np.fft.ifftshift(fshift)
img_back = cv2.idft(f_ishift)
img_back = cv2.magnitude(img_back[:,:,0],img_back[:,:,1])
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img_back, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()结果如下:

注意:OpenCV 中的函数 cv2.dft() 和 cv2.idft() 要比 Numpy 快。但是Numpy 函数更加用户友好。关于性能的描述,请看下面的章节。
23.3 DFT 的性能优化
当数组的大小为某些值时 DFT 的性能会更好。当数组的大小是 2 的指数 时 DFT 效率最高。当数组的大小是 2,3,5 的倍数时效率也会很高。所以 如果你想提高代码的运行效率时,你可以修改输入图像的大小(补 0)。对于 OpenCV 你必须自己手动补 0。但是 Numpy,你只需要指定 FFT 运算的大 小,它会自动补 0。
那我们怎样确定最佳大小呢?OpenCV 提供了一个函数:cv2.getOptimalDFTSize()。 它可以同时被 cv2.dft() 和 np.fft.fft2() 使用。让我们一起使用 IPython 的魔法命令%timeit 来测试一下吧。
import cv2
img = cv2.imread('messi5.jpg',0)
rows,cols = img.shape
print("{} {}".format(rows,cols))
#342 548
nrows = cv2.getOptimalDFTSize(rows)
ncols = cv2.getOptimalDFTSize(cols)
print("{} {}".format(nrows,ncols))
#360 576看到了吧,数组的大小从(342,548)变成了(360,576)。现在我们 为它补 0,然后看看性能有没有提升。你可以创建一个大的 0 数组,然后把我 们的数据拷贝过去,或者使用函数 cv2.copyMakeBoder()。
nimg = np.zeros((nrows,ncols))
nimg[:rows,:cols] = img或者:
right = ncols - cols
bottom = nrows - rows
bordertype = cv2.BORDER_CONSTANT #just to avoid line breakup in PDF file
nimg = cv2.copyMakeBorder(img,0,bottom,0,right,bordertype, value = 0)现在我们看看 Numpy 的表现:
fft1 = np.fft.fft2(img)
#10 loops, best of 3: 40.9 ms per loop
fft2 = np.fft.fft2(img,[nrows,ncols])
#100 loops, best of 3: 10.4 ms per loop速度提高了 4 倍。我们再看看 OpenCV 的表现:
dft1= cv2.dft(np.float32(img),flags=cv2.DFT_COMPLEX_OUTPUT)
#100 loops, best of 3: 13.5 ms per loop
dft2= cv2.dft(np.float32(nimg),flags=cv2.DFT_COMPLEX_OUTPUT)
#100 loops, best of 3: 3.11 ms per loop也提高了 4 倍,同时我们也会发现 OpenCV 的速度是 Numpy 的 3 倍。 你也可以测试一下逆 FFT 的表现。
23.4 为什么拉普拉斯算子是高通滤波器?
我在论坛中遇到了一个类似的问题。为什么拉普拉斯算子是高通滤波器? 为什么 Sobel 是 HPF?等等。对于第一个问题的答案我们以傅里叶变换的形 式给出。我们一起来对不同的算子进行傅里叶变换并分析它们:
import cv2
import numpy as np
from matplotlib import pyplot as plt
# simple averaging filter without scaling parameter
mean_filter = np.ones((3,3))
# creating a guassian filter
x = cv2.getGaussianKernel(5,10)
#x.T 为矩阵转置
gaussian = x*x.T
# different edge detecting filters
# scharr in x-direction
scharr = np.array([[-3, 0, 3],
[-10,0,10],
[-3, 0, 3]])
# sobel in x direction
sobel_x= np.array([[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]])
# sobel in y direction
sobel_y= np.array([[-1,-2,-1],
[0, 0, 0],
[1, 2, 1]])
# laplacian
laplacian=np.array([[0, 1, 0],
[1,-4, 1],
[0, 1, 0]])
filters = [mean_filter, gaussian, laplacian, sobel_x, sobel_y, scharr]
filter_name = ['mean_filter', 'gaussian','laplacian', 'sobel_x', 'sobel_y', 'scharr_x']
fft_filters = [np.fft.fft2(x) for x in filters]
fft_shift = [np.fft.fftshift(y) for y in fft_filters]
mag_spectrum = [np.log(np.abs(z)+1) for z in fft_shift]
for i in range(6): plt.subplot(2,3,i+1),plt.imshow(mag_spectrum[i],cmap = 'gray')
plt.title(filter_name[i]), plt.xticks([]), plt.yticks([])
plt.show()结果:

从图像中我们就可以看出每一个算子允许通过那些信号。从这些信息中我 们就可以知道那些是 HPF 那是 LPF。
更多资源
- An Intuitive Explanation of Fourier Theoryby Steven Lehar
- Fourier Transformat HIPR
- What does frequency domain denote in case of images?
24.模板匹配
模板匹配是用来在一副大图中搜寻查找模版图像位置的方法。OpenCV 为我们提供了函数:cv2.matchTemplate()。和 2D 卷积一样,它也是用模板图像在输入图像(大图)上滑动,并在每一个位置对模板图像和与其对应的 输入图像的子区域进行比较。OpenCV 提供了几种不同的比较方法(细节请看 文档)。返回的结果是一个灰度图像,每一个像素值表示了此区域与模板的匹配程度。
如果输入图像的大小是(WxH), 模板的大小是(wxh), 输出的结果 的大小就是(W-w+1,H-h+1)。当你得到这幅图之后,就可以使用函数 cv2.minMaxLoc() 来找到其中的最小值和最大值的位置了。第一个值为矩 形左上角的点(位置),(w,h)为 moban 模板矩形的宽和高。这个矩形就是 找到的模板区域了。
注意:如果你使用的比较方法是 cv2.TM_SQDIFF,最小值对应的位置才是匹 配的区域。
24.1 OpenCV中的模板匹配
我们这里有一个例子:我们在梅西的照片中搜索梅西的面部。所以我们要 制作下面这样一个模板:
![]()
我们会尝试使用不同的比较方法,这样我们就可以比较一下它们的效果了。
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg',0)
img2 = img.copy()
template = cv2.imread('messi_face.jpg',0)
w, h = template.shape[::-1]
# All the 6 methods for comparison in a list
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR', 'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
for meth in methods: img = img2.copy()
#exec 语句用来执行储存在字符串或文件中的 Python 语句。
# 例如,我们可以在运行时生成一个包含 Python 代码的字符串,然后使用 exec 语句执行这些语句。
#eval 语句用来计算存储在字符串中的有效 Python 表达式
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img,template,method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 使用不同的比较方法,对结果的解释不同
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]: top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img,top_left, bottom_right, 255, 2)
plt.subplot(121),plt.imshow(res,cmap = 'gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img,cmap = 'gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()结果如下:
cv2.TM_CCOEFF

cv2.TM_CCOEFF_NORMED

cv2.TM_CCORR

cv2.TM_CCORR_NORMED

cv2.TM_SQDIFF

cv2.TM_SQDIFF_NORMED

我们看到 cv2.TM_CCORR 的效果不想我们想的那么好。
24.2多对象的模板匹配
在前面的部分, 我们在图片中搜素梅西的脸, 而且梅西只在图片中出 现 了 一 次。 假 如 你 的 目 标 对 象 只 在 图 像 中 出 现 了 很 多 次 怎 么 办 呢? 函 数 cv2.imMaxLoc() 只会给出最大值和最小值。此时,我们就要使用阈值了。 在下面的例子中我们要经典游戏 Mario 的一张截屏图片中找到其中的硬币。
import cv2
import numpy as np
img_rgb = cv2.imread('mario.png')
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread('mario_coin.png',0)
w, h = template.shape[::-1]
res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED)
threshold = 0.8
#umpy.where(condition[, x, y])
#根据条件从x或y返回元素。如果只给出了条件,那么返回condition.nonzero().
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)
cv2.imwrite('res.png',img_rgb)结果:

25.Hough直线变换
霍夫变换在检测各种形状的的技术中非常流行,如果你要检测的形状可以 用数学表达式写出,你就可以是使用霍夫变换检测它。及时要检测的形状存在 一点破坏或者扭曲也可以使用。我们下面就看看如何使用霍夫变换检测直线。
一条直线可以用数学表达式 y = mx + c 或者 ρ = x cos θ + y sin θ 表示。 ρ 是从原点到直线的垂直距离,θ 是直线的垂线与横轴顺时针方向的夹角(如 果你使用的坐标系不同方向也可能不同,我是按 OpenCV 使用的坐标系描述 的)。如下图所示:

所以如果一条线在原点下方经过,ρ 的值就应该大于 0,角度小于 180。 但是如果从原点上方经过的话,角度不是大于 180,也是小于 180,但 ρ 的值 小于 0。垂直的线角度为 0 度,水平线的角度为 90 度。
让我们来看看霍夫变换是如何工作的。每一条直线都可以用 (ρ, θ) 表示。 所以首先创建一个 2D 数组(累加器),初始化累加器,所有的值都为 0。行表 示 ρ,列表示 θ。这个数组的大小决定了最后结果的准确性。如果你希望角度精 确到 1 度,你就需要 180 列。对于 ρ,最大值为图片对角线的距离。所以如果 精确度要达到一个像素的级别,行数就应该与图像对角线的距离相等。
想象一下我们有一个大小为 100x100 的直线位于图像的中央。取直线上 的第一个点,我们知道此处的(x,y)值。把 x 和 y 带入上边的方程组,然后 遍历 θ 的取值:0,1,2,3,. . .,180。分别求出与其对应的 ρ 的值,这样我 们就得到一系列(ρ, θ)的数值对,如果这个数值对在累加器中也存在相应的位 置,就在这个位置上加 1。所以现在累加器中的(50,90)=1。(一个点可能 存在与多条直线中,所以对于直线上的每一个点可能是累加器中的多个值同时 加 1)。
现在取直线上的第二个点。重复上边的过程。更新累加器中的值。现在累 加器中(50,90)的值为 2。你每次做的就是更新累加器中的值。对直线上的 每个点都执行上边的操作,每次操作完成之后,累加器中的值就加 1,但其他地方有时会加 1, 有时不会。按照这种方式下去,到最后累加器中(50,90)的 值肯定是最大的。如果你搜索累加器中的最大值,并找到其位置(50,90),这 就说明图像中有一条直线,这条直线到原点的距离为 50,它的垂线与横轴的 夹角为 90 度。下面的动画很好的演示了这个过程(Image Courtesy: Amos Storkey )。

这就是霍夫直线变换工作的方式。很简单,也许你自己就可以使用 Numpy 搞定它。下图显示了一个累加器。其中最亮的两个点代表了图像中两条直线的 参数。(Image courtesy: Wikipedia)。

25.1 OpenCV中的霍夫变换
上面介绍的整个过程在 OpenCV 中都被封装进了一个函数:cv2.HoughLines()。 返回值就是(ρ, θ)。ρ 的单位是像素,θ 的单位是弧度。这个函数的第一个参 数是一个二值化图像,所以在进行霍夫变换之前要首先进行二值化,或者进行Canny 边缘检测。第二和第三个值分别代表 ρ 和 θ 的精确度。第四个参数是 阈值,只有累加其中的值高于阈值时才被认为是一条直线,也可以把它看成能 检测到的直线的最短长度(以像素点为单位)。
import cv2
import numpy as np
img = cv2.imread('dave.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,50,150,apertureSize = 3)
lines = cv2.HoughLines(edges,1,np.pi/180,200)
for rho,theta in lines[0]: a = np.cos(theta)
b = np.sin(theta)
x0 = a*rho
y0 = b*rho
x1 = int(x0 + 1000*(-b))
y1 = int(y0 + 1000*(a))
x2 = int(x0 - 1000*(-b))
y2 = int(y0 - 1000*(a))
cv2.line(img,(x1,y1),(x2,y2),(0,0,255),2)
cv2.imwrite('houghlines3.jpg',img)结果如下:

25.2 Probabilistic Hough Transform
从上边的过程我们可以发现:仅仅是一条直线都需要两个参数,这需要大 量的计算。Probabilistic_Hough_Transform 是对霍夫变换的一种优化。它 不会对每一个点都进行计算,而是从一幅图像中随机选取(是不是也可以使用 图像金字塔呢?)一个点集进行计算,对于直线检测来说这已经足够了。但是 使用这种变换我们必须要降低阈值(总的点数都少了,阈值肯定也要小呀!)。下图是对两种方法的对比。(Image Courtesy : Franck Bettinger’s home page)

OpenCV 中使用的 Matas, J. ,Galambos, C. 和 Kittler, J.V. 提出的 Progressive Probabilistic Hough Transform。这个函数是 cv2.HoughLinesP()。 它有两个参数。
• minLineLength - 线的最短长度。比这个短的线都会被忽略。
• MaxLineGap - 两条线段之间的最大间隔,如果小于此值,这两条直线 就被看成是一条直线。
更加给力的是,这个函数的返回值就是直线的起点和终点。而在前面的例子中, 我们只得到了直线的参数,而且你必须要找到所有的直线。而在这里一切都很 直接很简单。
import cv2
import numpy as np
img = cv2.imread('dave.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,50,150,apertureSize = 3)
minLineLength = 100
maxLineGap = 10
lines = cv2.HoughLinesP(edges,1,np.pi/180,100,minLineLength,maxLineGap)
for x1,y1,x2,y2 in lines[0]: cv2.line(img,(x1,y1),(x2,y2),(0,255,0),2)
cv2.imwrite('houghlines5.jpg',img)结果如下:

http://en.wikipedia.org/wiki/Hough_transform
26 .Hough圆形变换
圆形的数学表达式为![]() ,其中(xcenter ,ycenter )为圆心的坐标,r 为圆的直径。从这个等式中我们可以看出:一个圆环需要 3个参数来确定。所以进行圆环霍夫变换的累加器必须是 3 维的,这样的话效率就会很低。所以 OpenCV 用一个比较巧妙的办法:霍夫梯度法,它可以使用边界的梯度信息。
,其中(xcenter ,ycenter )为圆心的坐标,r 为圆的直径。从这个等式中我们可以看出:一个圆环需要 3个参数来确定。所以进行圆环霍夫变换的累加器必须是 3 维的,这样的话效率就会很低。所以 OpenCV 用一个比较巧妙的办法:霍夫梯度法,它可以使用边界的梯度信息。
我们要使用的函数为 cv2.HoughCircles()。文档中对它的参数有详细 的解释。这里我们就直接看代码吧。
import cv2
import numpy as np
img = cv2.imread('opencv_logo.png',0)
img = cv2.medianBlur(img,5)
cimg = cv2.cvtColor(img,cv2.COLOR_GRAY2BGR)
circles = cv2.HoughCircles(img,cv2.HOUGH_GRADIENT,1,20,
param1=50,param2=30,minRadius=0,maxRadius=0)
circles = np.uint16(np.around(circles))
for i in circles[0,:]:
# draw the outer circle
cv2.circle(cimg,(i[0],i[1]),i[2],(0,255,0),2)
# draw the center of the circle
cv2.circle(cimg,(i[0],i[1]),2,(0,0,255),3)
cv2.imshow('detected circles',cimg)
cv2.waitKey(0)
cv2.destroyAllWindows()结果如下:

27.分水岭算法图像分割
任何一副灰度图像都可以被看成拓扑平面,灰度值高的区域可以被看成是山峰,灰度值低的区域可以被看成是山谷。我们向每一个山谷中灌不同颜色的水。随着水位的升高,不同山谷的水就会相遇汇合。为了防止不同山谷的水汇合,我们需要在水汇合的地方构建起堤坝。不停的灌水,不停的构建堤坝,直到所有的山峰都被水淹没。我们构建好的堤坝就是对图像的分割。这就是分水岭算法背后的哲理。你可以通过访问网站CMM webpage on watershed来加深自己的理解。
但这种方法通常都会得到过度分割的结果,这是由噪声或者图像中其它不规律的因素造成的。为了减少这种影响,OpenCV 采用了基于掩模的分水岭算法,在这种算法中我们要设置哪些山谷点会汇合,哪些不会。这是一种交互式的图像分割。我们要做的就是给已知的对象打上不同的标签。如果某个区域肯定是前景或对象,就使用某个颜色(或灰度值)标签标记它。如果某个区域肯定不是对象而是背景就使用另外一个颜色标签标记。而剩下的不能确定是前景还是背景的区域就用 0 标记。这就是我们的标签。然后实施分水岭算法。 每一次灌水,我们的标签就会被更新,当两个不同颜色的标签相遇时就构建堤坝,直到将所有山峰淹没,最后得到的边界对象(堤坝)的值为 -1。
下面的例子中我们将就和距离变换和分水岭算法对紧挨在一起的对象进行分割。如下图所示,这些硬币紧挨在一起。就算你使用阈值操作,它们任然是紧挨着的。

我们从找到硬币的近似估计开始。我们可以使用Otsu二值化。
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('water_coins.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)结果:

现在我们要去除图像中的所有的白噪声。这就需要使用形态学中的开运算。 为了去除对象上小的空洞我们需要使用形态学闭运算。所以我们现在知道靠近对象中心的区域肯定是前景,而远离对象中心的区域肯定是背景。而不能确定的区域就是硬币之间的边界。 所以我们要提取肯定是硬币的区域。腐蚀操作可以去除边缘像素。剩下就可以肯定是硬币了。当硬币之间没有接触时,这种操作是有效的。但是由于硬币之间是相互接触的,我们就有了另外一个更好的选择:距离变换再加上合适的阈值。接下来我们要找到肯定不是硬币的区域。这时就需要进行膨胀操作了。 膨胀可以将对象的边界延伸到背景中去。这样由于边界区域被处理,我们就可以知道哪些区域肯定是前景,哪些肯定是背景。如下图所示:

剩下的区域就是我们不知道该如何区分的了。这就是分水岭算法要做的。 这些区域通常是前景与背景的交界处(或者两个前景的交界)。我们称之为边界。从肯定是不是背景的区域中减去肯定是前景的区域就得到了边界区域。
# noise removal
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel, iterations = 2)
# sure background area
sure_bg = cv2.dilate(opening,kernel,iterations=3)
# Finding sure foreground area
# 距离变换的基本含义是计算一个图像中非零像素点到最近的零像素点的距离,也就是到零像素点的最短距离
# 个最常见的距离变换算法就是通过连续的腐蚀操作来实现,腐蚀操作的停止条件是所有前景像素都被完全
# 腐蚀。这样根据腐蚀的先后顺序,我们就得到各个前景像素点到前景中心骨架像素点的
# 距离。根据各个像素点的距离值,设置为不同的灰度值。这样就完成了二值图像的距离变换
#cv2.distanceTransform(src, distanceType, maskSize)
# 第二个参数 0,1,2 分别表示 CV_DIST_L1, CV_DIST_L2 , CV_DIST_C
dist_transform = cv2.distanceTransform(opening,1,5)
ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0)
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg,sure_fg)如结果所示,在阈值化之后的图像中,我们得到了肯定是硬币的区域,而 且硬币之间也被分割开了。(有些情况下你可能只需要对前景进行分割,而不需 要将紧挨在一起的对象分开,此时就没有必要使用距离变换了,腐蚀就足够了。当然腐蚀也可以用来提取肯定是前景的区域。)

现在知道哪些是背景哪些是硬币了,那我们就可以创建标签(一个与原图像大小相同,数据类型为 in32 的数组),并标记了其中的区域。对我们已经确定分类的区域(无论是前景还是背景)使用不同的正整数标记,对我们不确定的区域使用 0 标记。我们可以使用 cv2.connectedComponents() 函数来做这件事。它会将背景标记为 0,其它对象使用从 1 开始的正整数标记。
但如果背景标记为 0, 那分水岭算法就会把它当成未知区域了。所以我们想使用不同的整数标记它们。 而对不确定的区域标记为0(函数 cv2.connectedComponents 输出的结果中使用unknown定义未知区域)。
# Marker labelling
ret, markers1 = cv2.connectedComponents(sure_fg)
# Add one to all labels so that sure background is not 0, but 1
markers = markers1+1
# Now, mark the region of unknown with zero
markers[unknown==255] = 0结果使用 JET 颜色地图表示。深蓝色区域为未知区域。肯定是硬币的区域 使用不同的颜色标记。其余区域就是用浅蓝色标记的背景了。
现在标签准备好了。到最后一步:实施分水岭算法了。标签图像将会被修 改,边界区域的标记将变为 -1.
markers3 = cv2.watershed(img,markers)
img[markers3 == -1] = [255,0,0]结果如下。有些硬币的边界被分割的很好,也有一些硬币之间的边界分割 的不好。

CMM webpage on watershed
28.使用GrabCut算法进行交互式前景提取
原理
GrabCut 算法是由微软剑桥研究院的 Carsten_Rother,Vladimir_Kolmogorov
和 Andrew_Blake 在文章《GrabCut”: interactive foreground extrac- tion using iterated graph cuts》中共同提出的。此算法在提取前景的操作 过程中需要很少的人机交互,结果非常好。
从用户的角度来看它到底是如何工作的呢?开始时用户需要用一个矩形将前景区域框住(前景区域应该完全被包括在矩形框内部)。然后通过迭代分割得到最优结果。但是有时分割的结果不够理想,比如把前景当成了背景,或者把背景当成了前景。在这种情况下,就需要用户来进行修改了。用户只需要在不理想的部位画一笔(点一下鼠标)就可以了。画一笔就等于在告诉计算机:“嗨,老兄,你把这里弄反了,下次迭代的时候记得改过来呀!”。然后在下一轮迭代时你就会得到一个更好的结果了。
如下图所示。运动员和足球被蓝色矩形包围在一起。其中有我做的几个修正,白色画笔表明这里是前景,黑色画笔表明这里是背景。最后得到了一个很好的结果:

在整个过程中到底发生了什么呢?
• 用户输入一个矩形。矩形外的所有区域肯定都是背景(我们在前面已经提 到,所有的对象都要包含在矩形框内)。矩形框内的东西是未知的。同样 用户确定前景和背景的任何操作都不会被程序改变。
• 计算机会对我们的输入图像做一个初始化标记。它会标记前景和背景像 素。
• 使用一个高斯混合模型(GMM)对前景和背景建模。
• 根据我们的输入,GMM 会学习并创建新的像素分布。对那些分类未知 的像素(可能是前景也可能是背景),可以根据它们与已知分类(如背景) 的像素的关系来进行分类(就像是在做聚类操作)。
• 这样就会根据像素的分布创建一副图。图中的节点就是像素点。除了像 素点做节点之外还有两个节点:Source_node 和 Sink_node。所有的 前景像素都和 Source_node 相连。所有的背景像素都和 Sink_node 相 连。
• 将像素连接到 Source_node/end_node 的(边)的权重由它们属于同 一类(同是前景或同是背景)的概率来决定。两个像素之间的权重由边的 信息或者两个像素的相似性来决定。如果两个像素的颜色有很大的不同, 那么它们之间的边的权重就会很小。
• 使用 mincut 算法对上面得到的图进行分割。它会根据最低成本方程将图 分为 Source_node 和 Sink_node。成本方程就是被剪掉的所有边的权 重之和。在裁剪之后,所有连接到 Source_node 的像素被认为是前景, 所有连接到 Sink_node 的像素被认为是背景。
• 继续这个过程直到分类收敛。
下图演示了这个过程(Image Courtesy: http://www.cs.ru.ac.za/research/ g02m1682/):

演示
现在我们进入 OpenCV 中的grabcut 算 法。OpenCV 提供了函数:cv2.grabCut()。我们来先看看它的参数:
• img - 输入图像
• mask-掩模图像,用来确定那些区域是背景,前景,可能是前景/背景等。可以设置为:cv2.GC_BGD,cv2.GC_FGD,cv2.GC_PR_BGD,cv2.GC_PR_FGD, 或者直接输入0,1,2,3也行。
• rect - 包含前景的矩形,格式为 (x,y,w,h)
• bdgModel, fgdModel - 算法内部使用的数组. 你只需要创建两个大 小为 (1,65),数据类型为 np.float64 的数组。
• iterCount - 算法的迭代次数
• mode - 可以设置为 cv2.GC_INIT_WITH_RECT 或 cv2.GC_INIT_WITH_MASK, 也可以联合使用。这是用来确定我们进行修改的方式,矩形模式或者掩模模式。首先,我们来看使用矩形模式。加载图片,创建掩模图像,构建 bdgModel 和 fgdModel。传入矩形参数。都是这么直接。让算法迭代 5 次。由于我们 在使用矩形模式所以修改模式设置为 cv2.GC_INIT_WITH_RECT。运行 grabcut。算法会修改掩模图像,在新的掩模图像中,所有的像素被分为四类: 背景,前景,可能是背景/前景使用 4 个不同的标签标记(前面参数中提到过)。
然后我们来修改掩模图像,所有的 0 像素和 1 像素都被归为 0(例如背景),所
有的 1 像素和 3 像素都被归为 1(前景)。我们最终的掩模图像就这样准备好 了。用它和输入图像相乘就得到了分割好的图像。
# -*- coding:utf-8 -*-
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg')
mask = np.zeros(img.shape[:2],np.uint8)
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
rect = (50,50,450,290)
# 函数的返回值是更新的 mask, bgdModel, fgdModel
cv2.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask2[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show()结果如下:

哎呀,梅西的头发被我们弄没了!让我们来帮他找回头发。所以我们要在 那里画一笔(设置像素为 1,肯定是前景)。同时还有一些我们并不需要的草 地。我们需要去除它们,我们再在这个区域画一笔(设置像素为 0,肯定是背 景)。现在可以象前面提到的那样来修改掩模图像了。
实际上我是怎么做的呢?我们使用图像编辑软件打开输入图像,添加一个 图层,使用笔刷工具在需要的地方使用白色绘制(比如头发,鞋子,球等);使 用黑色笔刷在不需要的地方绘制(比如,logo,草地等)。然后将其他地方用灰 色填充,保存成新的掩码图像。在 OpenCV 中导入这个掩模图像,根据新的 掩码图像对原来的掩模图像进行编辑。代码如下:
# newmask is the mask image I manually labelled
newmask = cv2.imread('newmask.png',0)
# whereever it is marked white (sure foreground), change mask=1
# whereever it is marked black (sure background), change mask=0
mask[newmask == 0] = 0
mask[newmask == 255] = 1
mask, bgdModel, fgdModel = cv2.grabCut(img,mask,None,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_MASK)
mask = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show()结果如下:

就是这样。你也可以不使用矩形初始化,直接进入掩码图像模式。使用 2像素和 3 像素(可能是背景/前景)对矩形区域的像素进行标记。然后象我们在第二个例子中那样对肯定是前景的像素标记为 1 像素。然后直接在掩模图像模 式下使用 grabCut 函数。
因篇幅过长,后续章节参见:<