在VM上安装centOS7&配置Hadoop环境
主要内容:
1.安装虚拟机和centOS7。
2.理解Hadoop的体系结构。
3.配置Hadoop集群
写在开头(相关软件下载link和参考的博客)
VMware软件的安装
https://blog.csdn.net/sehejs_a/article/details/80633379
这个博客有VMware正版软件的下载地址和激活密钥
centOS7镜像下载:
https://www.centos.org/download/
安装教程:
https://blog.csdn.net/xyphf/article/details/82915311
hadoop2.7.7下载安装配置:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
安装可参考:https://blog.csdn.net/pucao_cug/article/details/71698903
jdk1.8下载安装:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
安装可参考:https://blog.csdn.net/pucao_cug/article/details/68948639
正文
安装VMare14
c盘扩容(由于安装虚拟机需要c盘的存储空间)
使用diskGenius
安装centOS7
error:虚拟机上安装CentOS时出现“此主机支持Inter VT-x,但Inter VT-x处于禁用状态”的解决方法

root密码:root
账户名:node0
密码:root
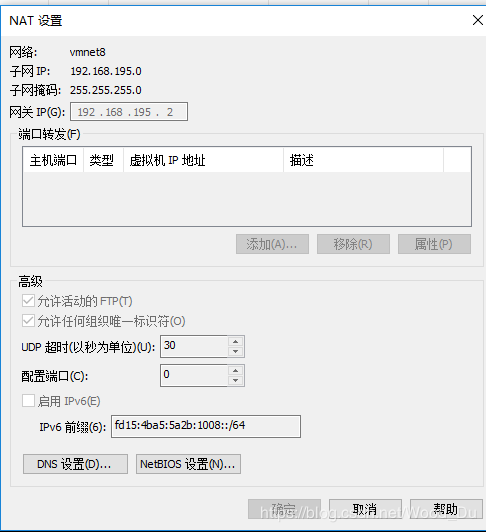


vi /etc/sysconfig/network-scripts/ifcfg-ens33
service network restart //输入命令,使配置有效 改成上面就能与本地连传文件,不然只需要将ONBOOT改成yes即可
yum update //更新yum
yum search ifconfig
yum -y install net-tools //安装工具 yum install net-tools.x86_64
ifconfig //查看ip
ctrl+c //终止ping;从>退出
Ctrl + z //暂停ping命令

安装成功!
关闭防火墙
mkdir xx
查看防火墙状态
systemctl status firewalld.service
关闭防火墙
systemctl stop firewalld.service
禁用防火墙
systemctl disable firewalld.service

安装另外两个虚拟机:node1 node2
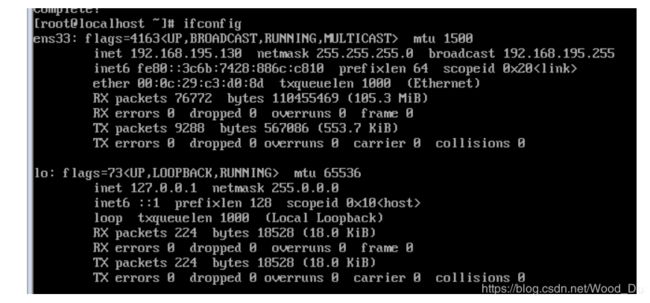
hostname node0 //
node 1
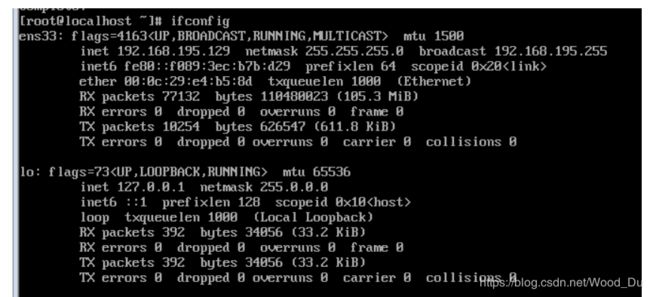
node2
192.168.195.128 node0
192.168.195.129 node1
192.168.195.130 node2
修改/etc/hosts文件
vi /etc/hosts
修改这3台机器的/etc/hosts文件,在文件中添加以下内容:
192.168.195.128 node0
192.168.195.129 node1
192.168.195.130 node2

配置完成后使用ping命令检查这3个机器是否相互ping得通,以node0为例,执行命令:

ping得通,说明机器是互联的,而且hosts配置也正确。
设置免密登录
给3个机器生成秘钥文件
以node0为例,执行命令,生成空字符串的秘钥(后面要使用公钥),命令是:
ssh-keygen -t rsa -P ''
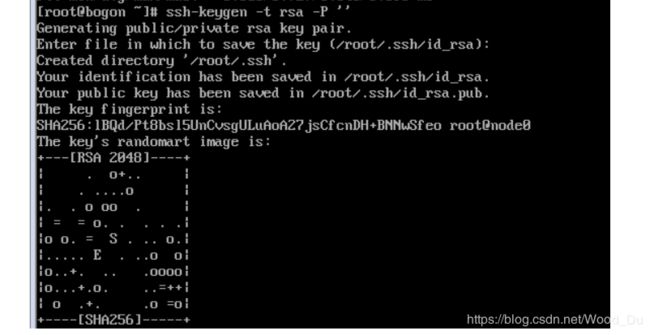
因为我现在用的是root账户,所以秘钥文件保存到了/root/.ssh/目录内,可以使用命令查看,命令是:
ls /root/.ssh/
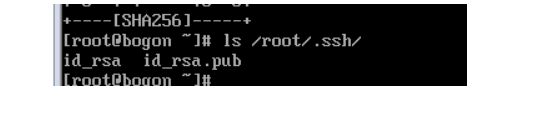
使用同样的方法为node1和node2生成秘钥(命令完全相同,不用做如何修改)。
在node0上创建authorized_keys文件
接下来要做的事情是在3台机器的/root/.ssh/目录下都存入一个内容相同的文件,文件名称叫authorized_keys,文件内容是我们刚才为3台机器生成的公钥。为了方便,我下面的步骤是现在node0上生成authorized_keys文件,然后把3台机器刚才生成的公钥加入到这个node0的authorized_keys文件里,然后在将这个authorized_keys文件复制到node1和node2上面。
首先使用命令,在node0的/root/.ssh/目录中生成一个名为authorized_keys的文件,命令是:
touch /root/.ssh/authorized_keys
可以使用命令看,是否生成成功,命令是:
ls /root/.ssh/
其次将node0上的/root/.ssh/id_rsa.pub文件内容,node1上的/root/.ssh/id_rsa.pub文件内容,node2上的/root/.ssh/id_rsa.pub文件内容复制到这个authorized_keys文件中,复制的方法很多了,可以用cat命令和vim命令结合来弄,也可以直接把这3台机器上的/root/.ssh/id_rsa.pub文件下载到本地,在本地将authorized_keys文件编辑好在上载到这3台机器上。
测试使用ssh进行无密码登录
ssh node1
exit
一定要注意的是,每次ssh完成后,都要执行exit,否则你的后续命令是在另外一台机器上执行的。
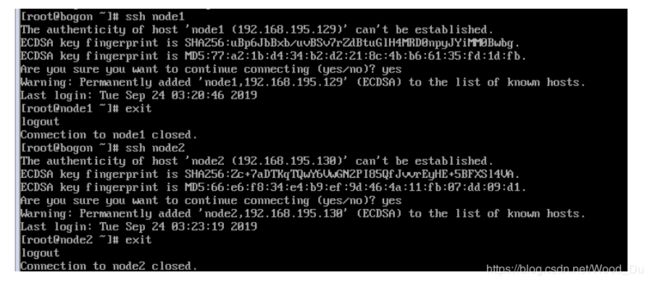
在node1,node2上测试
ok!
安装配置jdk和hadoop
配置jdk1.8.0_221
参考:https://blog.csdn.net/pucao_cug/article/details/68948639
tar -zxvf jdk-8u121-linux-x64.tar.gz
vi /etc/profile
只要在/etc/profile文件中增加如下配置即可,增加的内容是:
export JAVA_HOME=/opt/java/jdk1.8.0_221
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
执行命令
source /etc/profile //将文件中保存的命令执行一次
java -version //测试是否安装成功

注意:将配置内容(其实是命令脚本)写到/etc/profile中目的就是让任意用户登录后,都会自动执行该脚本,这样这些登录的用户就可以直接使用jdk了。如果因为某个原因该脚本没有自动执行,自己手动执行以下就可以了(也就是执行命令source /etc/profile)
ok!
安装hadoop
注意: 3台机器上都需要重复下面所讲的步骤。
在opt目录下新建一个名为hadoop的目录,并将下载得到的hadoop压缩包上载到该目录下,
cd /opt/hadoop
tar -xvf file //解压
rm -rf dir1 // 删除 ‘dir1’ 目录及其子目录内容
mkdir dir1 //创建 ‘dir1’ 目录
mkdir dir1 dir2 //同时创建两个目录
mkdir -p /tmp/dir1/dir2 //创建一个目录树
mv dir1 dir2 //移动/重命名一个目录
rm -f file1 //删除 ‘file1’
新建几个目录
在/root目录下新建几个目录,复制粘贴执行下面的命令:
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
修改etc/hadoop中的一系列配置文件
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop目录内的一系列文件。
1、修改core-site.xml
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/core-site.xml文件
在节点内加入配置:
hadoop.tmp.dir
/root/hadoop/tmp
Abase for other temporary directories.
fs.default.name
hdfs://node0:9000
2、修改hadoop-env.sh
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/hadoop-env.sh文件
将export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/opt/java/jdk1.8.0_221
说明:修改为自己的JDK路径
3、修改hdfs-site.xml
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/hdfs-site.xml文件
在节点内加入配置:
dfs.name.dir
/root/hadoop/dfs/name
Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.
dfs.data.dir
/root/hadoop/dfs/data
Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.
dfs.replication
2
dfs.permissions
false
need not permissions
**说明:**dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true。
4、新建并且修改mapred-site.xml
在该版本中,有一个名为mapred-site.xml.template的文件,复制该文件,然后改名为mapred-site.xml,命令是:
cp file1 file2 //将file1复制为file2
cp /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml
修改这个新建的mapred-site.xml文件,在节点内加入配置:
mapred.job.tracker
node0:49001
mapred.local.dir
/root/hadoop/var
mapreduce.framework.name
yarn
5、修改slaves文件
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop/slaves文件,将里面的localhost删除,添加如下内容:
node1
node2
6.修改yarn-site.xml文件
yarn.resourcemanager.hostname
node0
The address of the applications manager interface in the RM.
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
The address of the scheduler interface.
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
The http address of the RM web application.
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
The https adddress of the RM web application.
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
The address of the RM admin interface.
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.scheduler.maximum-allocation-mb
2048
每个节点可用内存,单位MB,默认8182MB
yarn.nodemanager.vmem-pmem-ratio
2.1
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.vmem-check-enabled
false
说明:yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
//什么都没改 将node0中改的配置文件直接替换了node1和node2中的配置文件
启动hadoop
因为node0是namenode,node1和node2都是datanode,所以只需要对node0进行初始化操作,也就是对hdfs进行格式化。
进入到node0这台机器的/opt/hadoop/hadoop-2.7.7/bin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.8.0/bin
执行初始化脚本,也就是执行命令:
./hadoop namenode -format
稍等几秒,不报错的话,即可执行成功,如图:
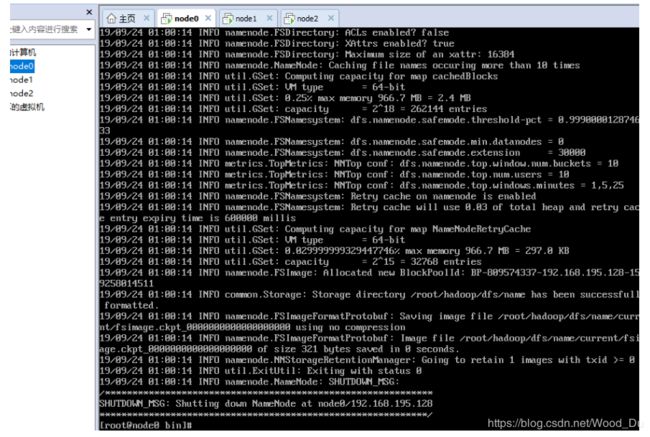
格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件

在namenode上执行启动命令
因为node0是namenode,node1和node2都是datanode,所以只需要再node0上执行启动命令即可。
进入到hserver1这台机器的/opt/hadoop/hadoop-2.8.0/sbin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.7.7/sbin
执行初始化脚本,也就是执行命令:
./start-all.sh
第一次执行上面的启动命令,会需要我们进行交互操作,在问答界面上输入yes回车

测试hadoop
haddoop启动了,需要测试一下hadoop是否正常。
确定已关闭防火墙。
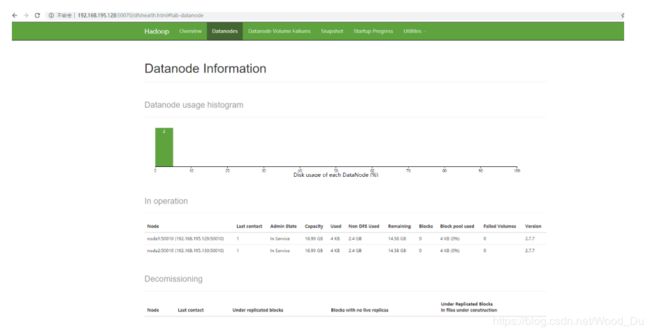
node0是我们的namanode,该机器的IP是192.168.195.128,在本地电脑访问如下地址:
http://192.168.195.128:50070/
自动跳转到了overview页面


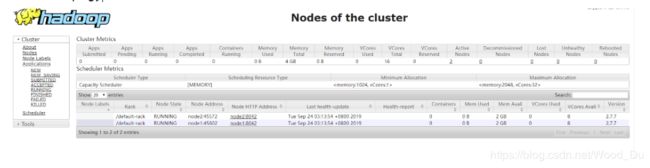
在本地浏览器里访问如下地址:
http://192.168.195.128:8088/
自动跳转到了cluster页面
问题:不能跳转???????????
问题:修改yarn-site.xml文件时里面没有改成node0
修改之后 jps

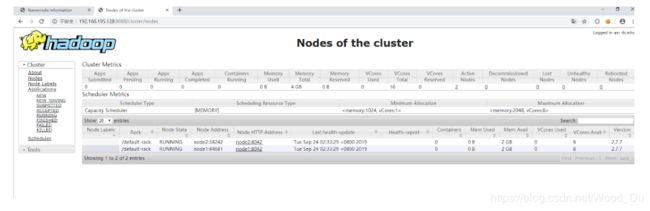
ok!
但是这个时候发现50070LiveNode变为了0
将/etc/hosts中修改 (127.0.0.1的删掉) ---------不行
重新生成------------不行
直接对每个机器,把dfs目录和tmp目录全部删掉,然后对每个机器进行格式化。----------------ok!
结果:
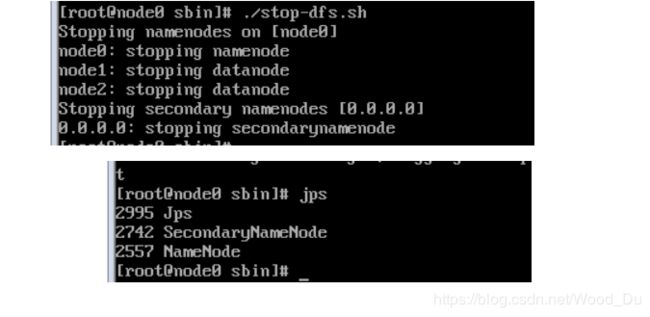
//关闭:
./stop-dfs.sh
./stop-all.sh
jps //查看启动进程
三、心得总结:
本来准备直接在服务器上centos下配置hadoop框架的。看了下还挺麻烦的,尤其需要配置主节点和数据节点。还是老老实实安装虚拟机,老老实实C盘扩了一下容,配置的整个过程肯定是遇到了很多问题,在实验步骤中也有一些体现。在最后启动和测试的时候也发现了很多细节问题。有一种感觉,这一个月配了各种环境,所以在配置hadoop的整个过程中心态也与前段时间不同,直觉与熟练程度很明显不一样。在环境配置好之后,再看hadoop架构,也有了新的理解。
Hadoop是用于在计算机集群上进行分布式计算和超大型数据集存储的框架。
三个核心组件:
HDFS, MapReduce, YARN
HDFS:
分布式文件系统,提供高吞吐量的应用程序数据访问,对外部客户机而言,HDFS 就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的。
NameNode:主节点(一个)
提供元数据服务;
客户端的主控和代理访问文件的角色;
DataNode:数据节点
保存数据块;它为 HDFS 提供存储块。由于仅存在一个 NameNode,存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。
MapReduce
一个分布式海量数据处理的软件框架集计算集群。
MapReduce主要由Map阶段和Reduce阶段构成。Map阶段实现的是映射,主要用来把一组键值对映射成一组新的键值对,Reduce阶段实现的是归纳,用来保证所有映射的键值对中的每一个共享相同的键值对。
YARN
ResourceManager(每个集群一个)
是全局的,负责对于系统中的所有资源有最高的支配权。
它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。
应用程序管理器负责管理整个系统中所有应用程序,
ApplicationMaster(每个应用程序一个)
每一个job有一个ApplicationMaster
主要功能包括:
与RM调度器协商以获取资源(用Container表示);
将得到的任务进一步分配给内部的任务;
与NM通信以启动/停止任务;
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
NodeManager(每个节点一个)
NM是每个节点上的资源和任务管理。
一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;
另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
一个分布式海量数据处理的软件框架集计算集群。
MapReduce主要由Map阶段和Reduce阶段构成。Map阶段实现的是映射,主要用来把一组键值对映射成一组新的键值对,Reduce阶段实现的是归纳,用来保证所有映射的键值对中的每一个共享相同的键值对。
YARN
ResourceManager(每个集群一个)
是全局的,负责对于系统中的所有资源有最高的支配权。
它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。
应用程序管理器负责管理整个系统中所有应用程序,
ApplicationMaster(每个应用程序一个)
每一个job有一个ApplicationMaster
主要功能包括:
与RM调度器协商以获取资源(用Container表示);
将得到的任务进一步分配给内部的任务;
与NM通信以启动/停止任务;
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
NodeManager(每个节点一个)
NM是每个节点上的资源和任务管理。
一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;
另一方面,它接收并处理来自AM的Container启动/停止等各种请求。