【HBase SQL插件 Phoenix Squirrel】Phoenix入门 2019_12_29
Phenix
- 简介
- 优势
- 架构
- 资源
- 部署
- 测试
- 表操作
- C 创建
- R 显示
- U 更新
- D 删除
- H-P 表映射
- 视图映射
- 案例
- 表映射
- 案例1
- 案例2
- P-H 二级索引
- 配置修改
- 二级索引
- Global Index
- Local Index
- 删除索引
- 优化查询方法
- 加盐表
- 盐值设定规则
- 格式
- P-Spark
- Maven 依赖
- 示例代码
- P 可视化工具
- 资源
- 安装
- 连接
简介
Apache Phoenix 是 HBase 开源 SQL 皮肤,使用标准 JDBC API 代替 HBase-Client API 来 DDL,DML HBase数据库。
优势
-
令 hbase 支持标准化 SQL,替代繁复 hbase 命令,降低 hbase 学习成本
-
完美支持 Hbase 二级索引创建
-
更加便捷集成 Spark,Hive,Pig,Flume 和 MapReduce
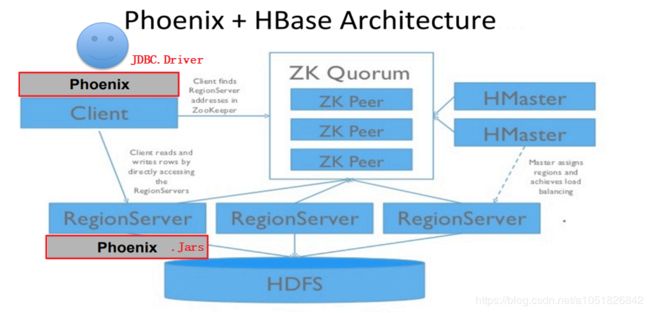
架构
服务器:HBase 集成 Phoenix 十分简单,只需将 Phoenix.Jars 分发到 所有RegionServer HBase_HOME/lib 目录下即可
客户端:使用 org.apache.phoenix.jdbc.PhoenixDriver 即可,究极简单
资源
官网:http://phoenix.apache.org/index.html
下载:http://phoenix.apache.org/download.html
最新版本:分为三类,1.适配 HBase 2.0,2.适配 HBase 1.5,3.适配 CDH 5.14.2
本教程使用: http://archive.apache.org/dist/phoenix/apache-phoenix-4.12.0-HBase-1.3/bin/
部署
1. 上传tar包至 hadoop102,103,104
SecureCRT 8.5: Alt + p
$ cd /opt/software
拖拽tar包至SecureCRT窗口
2. 解压
$ tar -zxvf /opt/software/apache-phoenix-4.14.2-HBase-1.3-bin.tar.gz -C /opt/module
$ cd /opt/module
$ mv apache-phoenix-4.14.2-HBase-1.3-bin phoenix
3. 复制HBase所需 JARs 至 HBASE_HOME/lib
phoenix-4.14.2-HBase-1.3-server.jar
phoenix-4.14.2-HBase-1.3-client.jar
$ cd /opt/module/phoenix/
$ cp phoenix-4.14.2-HBase-1.3-server.jar /opt/module/hbase-1.3.1/lib/
$ cp phoenix-4.14.2-HBase-1.3-client.jar /opt/module/hbase-1.3.1/lib/
$ xsync /opt/module/hbase-1.3.1/lib
# OR
$ scp phoenix-4.14.2-HBase-1.3-server/client.jar hadoop103/104:/opt/module/hbase-1.3.1/lib/
4. 暴露 系统环境变量
$ vim /etc/profile(正确做法是在/etc/profile.d/ 下创建 .sh 文件,写入下列内容)
>>
#phoenix
export PHOENIX_HOME=/opt/module/phoenix
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
<<
测试
1. 群启前置服务:Zookeeper,Hadoop,Hbase
$ zk.sh start # zkServer.sh start *3
$ start-dfs.sh start
$ start-hbase.sh start
2. 启动 Phoenix 命令行客户端,并测试
$ /opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181
...
sqlline version 1.2.0
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> !table
...所有表信息
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104> !quit
退出
表操作
注:所有命令均是在 Linux Phoenix sqlline.py Shell命令行 写入识别
Phoenix 严格区分 大小写,如果不用双引号"“括住的 字段表名,在创表时,均会自动创建为 大写。指定小写使用”"。
C 创建
CREATE TABLE IF NOT EXISTS us_population (
State CHAR(2) NOT NULL,
City VARCHAR NOT NULL,
Population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
注:联合主键,只能通过 constraint 来定义,无法直接写在 多个列后面
R 显示
!table 或 !tables ,显示所有表
select * from us_population where state='NY';,显示指定记录
U 更新
upsert into us_population values('NY','NewYork',8143197);
D 删除
delete from us_population wherestate='NY';,删除指定记录
drop table us_population;,删除指定表
H-P 表映射
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的。如果要在Phoenix中操作在hbase中创建的表,则需要在phoenix中进行表的映射。映射方式有两种:视图映射和表映射
视图映射
只读,只能查询,无法通过视图对源表数据进行修改等操作。
案例
HBase 创建 test 表:hbase(main):001:0> create 'test','name','company'
Phoenix 对已存在的 HBase 表进行 视图映射:
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104>
create view "test"(
empid varchar primary key,
"name"."firstname" varchar,
"name"."lastname" varchar,
"company"."name" varchar,
"company"."address" varchar
);
表映射
完整的操作权限。在查询效率上来说,表映射会高于视图映射的查询效率。
原因是:创建表映射的时候,Phoenix会在表中创建一些空的键值对,这些空键值对的存在可以用来提高查询效率。
案例1
HBase 创建 test 表:hbase(main):001:0> create 'test','name','company'
Phoenix 对已存在的 HBase 表进行 表映射:
# 如 视图映射 ,只需 将 create view 换为 create table 即可
0: jdbc:phoenix:hadoop102,hadoop103,hadoop104>
create table "test"(
empid varchar primary key,
"name"."firstname" varchar,
"name"."lastname" varchar,
"company"."name" varchar,
"company"."address" varchar
);
案例2
直接在 Phoenix 创建 HBase 不存在的表。自动在 Phoenix 和 HBase 中创建 person_infomation 表,并会根据指令内的参数对表结构进行初始化。
0: jdbc:phoenix:hadoop101,hadoop102,hadoop103>
create table "test"(
empid varchar primary key,
"name"."firstname" varchar,
"name"."lastname" varchar,
"company"."name" varchar,
"company"."address" varchar
) column_encoded_bytes=0;
P-H 二级索引
配置修改
HMaster 配置文件 hbase-site.xml
$ vim HBASE_HOME/conf/hbase-site.xml
>>
<property>
<name>hbase.master.loadbalancer.classname>
<value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancervalue>
property>
<property>
<name>hbase.coprocessor.master.classesname>
<value>org.apache.phoenix.hbase.index.master.IndexMasterObservervalue>
property>
<<
HRegionServer 配置文件 hbase-site.xml。全部修改完成后,重启 HBase 集群
$ vim HBASE_HOME/conf/hbase-site.xml
>>
<property>
<name>hbase.regionserver.wal.codecname>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodecvalue>
property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.classname>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactoryvalue>
<description>创建Phoenix RPC调度器,该调度器使用单独的队列进行索引和元数据更新description>
property>
<property>
<name>hbase.rpc.controllerfactory.classname>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactoryvalue>
<description>创建Phoenix RPC调度器,该调度器使用单独的队列进行索引和元数据更新description>
property>
<<
二级索引
注意,如果想使用二级索引,只能是 select 建立索引的字段,如果 select 未建立索引的字段 就仍然是 Full Scan
如果应用上了二级索引则,explain SQL 显示为 round robin range scan
Global Index
Global Index 是默认的索引格式。适用于多读少写的业务场景。
缺点:写数据的时候会造成大量开销,因为索引表也要同时更新,而索引表是分布在不同的数据节点上的,跨节点的数据传输带来了较大的性能消耗。
优点:读数据的时候通过索引表可降低查询消耗的时间。注意如果查询的字段不是索引字段的话索引表就不会被使用。
格式:CREATE INDEX my_index ON my_table (my_cf.my_col)
示例:CREATE INDEX "idx_company_name" ON "emp2"("COMPANY"."NAME")
Local Index
Local Index 适用于写操作频繁的场景。也通常称为 降级索引。
优点:1.索引和表数据是存放在相同的服务器中,避免了写场景下同步更新分布式索引表的额外开销。2.查询的字段不是索引字段索引表也会被使用,这会带来查询速度的提升。
缺点:由于是本地索引,所以查询时,需要先找到数据所在RegionServer服务器,才能利用本地索引表,对于查询时会增加查询时间。
格式:CREATE LOCAL INDEX my_index ON my_table (my_cf.my_col)
示例:CREATE LOCAL INDEX "youtube_index3" ON "hive_hbase_youtube"("info"."uploader")
删除索引
DROP INDEX my_index ON my_table
优化查询方法
include 附加 可能作为查询结果的列,这样就可以通过建立一个过滤索引,提升2个列查询速度
1) CREATE INDEX my_index ON my_table (v1) INCLUDE (cf.v2)
2) SELECT INDEX(my_table my_index) v2 FROM my_table WHERE v1 = ‘foo’
3) CREATE LOCAL INDEX my_index ON my_table (cf.v1)
加盐表
在密码学中,加盐是指在散列之前将散列内容(例如:密码)的任意位置插入特定的字符串。这个在散列中加入字符串的方式称为“加盐”,其作用是让加盐后的散列结果和没有加盐的结果不相同。
在 HBASE 中,如果主键是顺序的序列,频繁插入表中,最终会数据不停的落在一个regionServer中,容易造成热点问题。所以尽量将id打散。利用表中定义盐值,数据会均匀的分布在各个region中。
盐值设定规则
- hbase节点数的倍数,最少是1倍
- 数据量大时可增加盐数,比如对于8个region server集群的大表,可以考虑设计64~128个slat buckets。
格式
就是在建表时的最后,指定 SALT_BUCKETS 即可
create table "user333" ( "user_id" varchar primary key , "info"."name" varchar , "info"."age" varchar)column_encoded_bytes=0,SALT_BUCKETS = 3
P-Spark
官网详解:http://phoenix.apache.org/phoenix_spark.html
Maven 依赖
<dependency>
<groupId>org.apache.phoenixgroupId>
<artifactId>phoenix-sparkartifactId>
<version>4.14.2-HBase-1.3version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.1.1version>
dependency>
示例代码
import org.apache.phoenix.spark._
filterDS.foreachRDD(
rdd=>{
rdd.saveToPhoenix("GMALL0715_DAU",
Seq("MID", "UID", "APPID", "AREA", "OS", "CH", "TYPE", "VS", "LOGDATE", "LOGHOUR", "TS"),
new Configuration,
Some("hadoop102,hadoop103,hadoop104:2181"))
}
)
P 可视化工具
Squirrel 松鼠
资源
官网:http://squirrel-sql.sourceforge.net/
最新版: https://sourceforge.net/projects/squirrel-sql/files/1-stable/4.0.0/squirrel-sql-4.0.0-standard.jar/download
下载后的文件本体:squirrel-sql-4.0.0-standard.jar
安装
自定义安装位置,后面无需更改。
连接
- 复制 apache-phoenix-4.14.2-HBase-1.3-bin.tar.gz 中的 phoenix-4.14.2-HBase-1.3-client.jar 到 Squirrel安装目录下的 lib 目录下
- 启动 Squirrel
- 配置右侧边栏 Drivers,点击 ➕ 按钮
- Name 填写:Phoenix,Example URL 填写:
jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181 - Extra Class Path 选择 phoenix-4.14.2-HBase-1.3-client.jar
- Class Name 选择 org.apache.phoenix.jdbc.PhoenixDriver,然后点击 OK 按钮,查看 Drivers 中显示 蓝色√ Phoenix
- 配置右侧边栏 Aliases,点击 ➕ 按钮
- Name 填写:HBase_102,Driver 选择 Phoenix,URL 不可选中更改,UserName Password 均为空
- 点击 test 按钮,测试连接成功,点击 OK。
- 最后双击 Aliases 内的 Phoenix ,进入 HBase ,查看所有表(只能查看到系统表及在Phoenix创建的表)