【GANs学习笔记】(十一)DCGAN、ImprovedDCGAN
完整笔记:http://www.gwylab.com/note-gans.html
———————————————————————
本章借鉴内容:
http://blog.sina.com.cn/s/blog_76d02ce90102xq4d.html
Part2 GANs基于Network的改进
在这一部分我们开始探讨generator与discriminator内部网络的结构,之前我们一直在探讨二者在外部的连接方式和如何使用divergence能让结果更好,而涉及到generator与discriminator本身时一直粗略地描述成神经网络,但其实,使用不同的神经网络的结构对结果会产生不同的影响。本章我们首先介绍基于卷积网络改进的DCGAN与ImprovedDCGAN,然后介绍消除感受野障碍的SAGAN,最后会介绍迄今为止规模最大、效果最好的BigGAN。
1. DCGAN
我们知道深度学习中对图像处理应用最好的模型是CNN,那么如何把CNN与GAN结合?DCGAN是这方面最好的尝试之一。
DCGAN的原理和GAN是一样的,这里就不在赘述。它只是把上述的G和D换成了两个卷积神经网络(CNN)。但不是直接换就可以了,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
?取消所有pooling层。G网络中使用微步幅度卷积(fractionally strided convolution)代替pooling层,D网络中使用步幅卷积(strided convolution)代替pooling层。
?在D和G中均使用batch normalization
?去掉FC层,使网络变为全卷积网络
?G网络中使用ReLU作为激活函数,最后一层使用tanh
?D网络中使用LeakyReLU作为激活函数
我们来看一下DCGAN中G的具体网络结构:
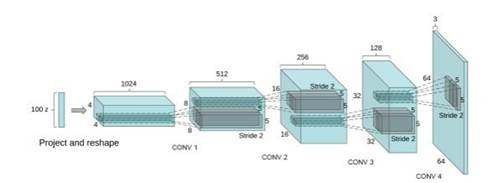
可以看出,generator的输入是一个100维的噪声,中间会通过4层卷积层,每通过一个卷积层通道数减半,长宽扩大一倍 ,最终产生一个64*64*3大小的图片输出。值得说明的是,在很多引用DCGAN的paper中,误以为这4个卷积层是deconv(反卷积)层,但其实在DCGAN的介绍中这4个卷积层是fractionally strided convolution(微步幅度卷积),二者的差别如下图所示:
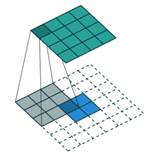
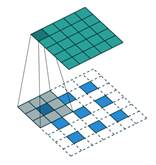
上图左边是反卷积,用3*3的卷积核把2*2的矩阵反卷积成4*4的矩阵;而右边是微步幅度卷积,用3*3的卷积核把3*3的矩阵卷积成5*5的矩阵,二者的差别在于,反卷积是在整个输入矩阵周围添0,而微步幅度卷积会把输入矩阵拆开,在每一个像素点的周围添0。
接下来我们再看一下DCGAN中D网络的结构,由于原论文中没有给出相关图,我找了一篇近似论文中的图说明:
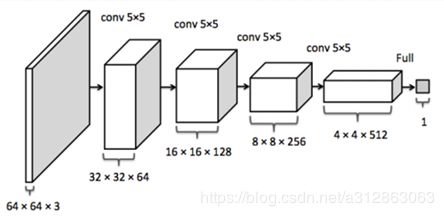
D可以看成是G结构反过来的样子,那具体结构也没什么好说的了,简言之不断地做卷积,最终得到一个0,1之间的结果。
最后,见到有人在博客中给出了一个建议,引述如下:上述结构是DCGAN应用在LSUN数据集上的架构,我们自己搭建DCGAN的时候应该视实际数据集大小做相应更改,譬如在MNIST数据上网络结构的参数就应该要适当调小。
2. ImprovedDCGAN
GANs的主要问题之一是收敛性不稳定,尽管DCGAN做了结构细化,训练过程仍可能难以收敛。我们先来分析一下为什么会出现收敛性不稳定。
GANs的优化就是寻找两玩家非合作博弈的纳什均衡点。这里的两玩家指的就是生成式generator和判别式discriminator。generator的目标是最小化目标函数:
![]()
discriminator的目标是最小化目标函数:
![]()
纳什均衡点就是使得上面两个目标都能最小的θ(D)和θ(G)。GANs的训练常常是同时在两个目标上使用梯度下降,然而这并不能保证到达均衡点,毕竟目标未必是凸的。也就是说GANs可能永远达不到这样的均衡点,于是就会出现收敛性不稳定。
为了解决这一问题,ImprovedDCGAN针对DCGAN训练过程提出了不同的增强方法。以下是其主要内容:
特征匹配(feature mapping)
为了不让生成器尽可能地去蒙骗鉴别器,ImprovedDCGAN希望以特征作为匹配标准,而不是图片作为匹配标准,于是提出了一种新的生成器的目标函数,即:
![]()
其中f(x)是指的generator把discriminator的中间层输出f(x)作为目标(一般中间层都是D最后几层,f(x)实际上是feature map),这样可以让生成的中间层输出和真实数据的中间层输出尽可能相同。这种做法虽然不能保证到达均衡点,但是收敛的稳定性应该是有所提高。
批次判别(minibatch discrimination)
GAN的一个常见的失败就是收敛到同一个点,并没有什么机制可以让generator生成不一样的内容。而只要生成一个会被discriminator误认的内容,那么梯度方向就会不断朝那个方向前进。
ImprovedDCGAN使用的方法是用minibatch discriminator。也就是说每次不是判别单张图片,而是判别一批图片。
具体来说,将一个中间层f(x)乘以一个tensor,得到一个新的矩阵M,计算M每一行之间的L1距离o,以此为f(x)下一层的输入。
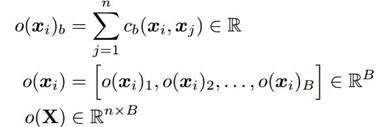
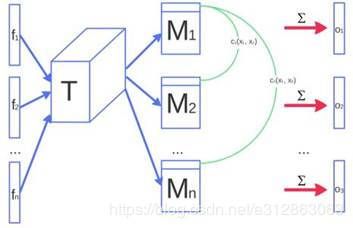
假设x是从generator生成的,并且收敛到同一点,那么对应的f(x)必然很相似,由f(x)生成的M也必然非常相似。而这些M每一行的L1距离c(xi,xj)也就会非常接近0,这也导致o(X)几乎是0向量。相对的,如果x是真实数据,那么o(X)一般不会太接近0向量,这样discriminator就可以更简单的区分生成数据或真实数据(在generator收敛到一点的情况下)。
历史平均(historical averaging)
在更新参数值时,把它们过去的值也纳入考虑,也就是在目标函数中加入下面这项:
![]()
单侧标签平滑(one-sided label smoothing)
判别式的目标函数中正负样本的系数不再是0-1,而是α和β,这样判别式的目标就变成了下面这个式子。这相当于,原本判别器的目标数出值是[0=假图像,1=真图像],现在可能变成了[0=假图像,0.9=真图像]。
![]()
虚拟批次正态化(virtual batch normalization)
batch normalize在神经网络领域有广泛应用,但是也有一些问题,比如特定样例x在神经网络上的输出会受到minibatch上其他的样本影响。文中提出了一种virtual batch normalization(VBN),会在训练前提取一个batch,以后就根据这个batch做normalize,不过由于这样的计算成本很高,所以它仅仅被用在生成器当中。
综上便是ImprovedDCGAN提出来的改进方法,这些方法能够让模型在生成高分辨率图像时表现得更好,而这正是GANs的弱项之一。