Git 底层原理
文章目录
- 一.git 介绍
- 一.git 简介
- 二.git 历史
- 三.集中式与分布式
- 四.git 大致结构
- 二. .git 目录结构
- 三.git add 与 git commit 简单原理
- 四.创建与合并分支简单原理
- 五.git rebase 简单原理
- 六.开始从底层入手 git
- 七.git add 命令底层原理
- 八.git add 和 git commit 中间的操作(tree 对象的生成)
- 九.git commit 命令底层原理
这里有几篇 git 相关的博文推荐
git 常用命令
git 常见场景操作
一.git 介绍
git 底层原理的讲解中看到一篇非常非常赞的博文,此文中有很多内容摘自下面这篇博文,做了小汇总,强烈推荐
Yelbosh 大神的 git 博文
一.git 简介
目前最先进的开源分布式版本控制系统,来源思想是,代码开发了多个版本,以往的思想是每个版本在电脑中 copy 一份保存,以免以后版本的代码出现问题,可以直接找之前几个版本的代码,这种就好似只有两层多子树的树形结构,git 的思想是自己电脑中不用 copy 下来每个版本,每个版本逻辑上是一个结点,每次更新到下一个版本,结点就自动往后延伸,是一个线性结构,若想恢复到之前哪个版本,也就是恢复到之前哪个结点,可以用 git 相关命令来将版本变为历史版本。git 比其他版本控制优秀在于其跟踪管理是改动而不是文件本身
二.git 历史
1991 年 Linus 创建了开源的 Linux,自此 Linux 不断发展成为服务器系统首选,2002 年之前各地开源 Linux 的代码贡献者通过 diff 方式把源代码发给 Linus,然后 Linus 本人通过手工方式合并代码,Linus 那时坚定反对 CSV 和 SVN,因为这些集中式版本控制系统不但速度慢而且需要联网才行,虽然有一些好用的商用版本控制系统,可惜需要付费,这与 Linus 提倡的开源精神不符合,到 2002 年 Linux 代码库已经大到 Linus 很难维护了,社区成员也对此表示不满,于是 Linus 选择使用了商业版本控制系统 BitKeeper,该系统的公司处于人道主义授权 Linux 社区免费使用该版本控制系统,可是在 2005 年的时候,Liunx 社区中的开发 Samba 的安德鲁视图破解 BitKeeper 协议,其实还有社区里的其他人,被 BitKeeper 公司发现,一气之下,公司决定收回 Linux 社区免费授权,之后 Linus 没有选择向 BitKeeper 所有的公司道歉,而是选择自己花了两周左右的时间自己用 C 写了一个分布式版本控制系统,这就是 Git,一个月的之内 Linux 系统源码已经可以被 Git 管理了,接着 Git 就迅速成为最流行的分布式版本控制系统,2008 年的时候,GitHub 上线,无数开源项目通过 Git 存储在 GitHub 中直到现今
三.集中式与分布式
-
集中式
版本库放置于中央服务器,常规操作是先从中央库拉取最新版本信息,之后在自己电脑中修改,再把新版本推送给中央服务器。但需要联网才能操作,速度慢。常见有 SVN,CSV 等
-
分布式
每个人电脑里都有个版本库,有个人电脑坏掉,不要紧可以直接从其他人电脑复制一份过来即可,但实际使用中,很少有人在两人之间电脑推送修改,为了方便交换,通常也有个类似中央服务器的电脑,但是其仅仅是为了方便大家代码统一在此处交换
四.git 大致结构
git 工作区有个隐藏目录 .git,这是 git 的版本库,其中有暂存区,默认的 master 分支以及指向 master 的 HEAD 指针
二. .git 目录结构
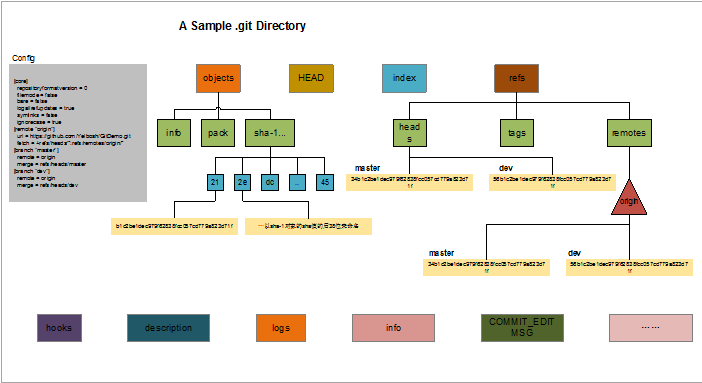
进入隐藏的 .git 目录之后可以看到如上图所示结构
-
核心文件:config,objects,HEAD,index,refs 这 5 个文件夹
- config:这里存储项目的一些配置信息,比如是否以 bare 方式初始化,remote 信息等。git remote add 添加的远程分支信息就保存在这里
- objects:这里保存 git 对象,git 中的一些操作以及文件都会以 git 对象形式保存在这里,git 对象分为 BLOB,tree,commit 三种类型,比如 git commit 就是 commit 类型变量,各个版本之间通过版本树进行组织,比如 HEAD 指向某个 commit 对象,而 commit 对象又会指向几个 BLOB 对象或者 tree 对象。objects 文件夹中有很多子文件夹,其中 git 对象保存在以其 sha-1 值的前两位为子文件夹后 38 位为文件名的文件中,此外 git 为了节省存储对象所占用的磁盘空间,会定期对 git 对象进行压缩和打包,其中 pack 文件夹用于存放打包压缩的对象,info 文件夹用于从打包的文件中查找 git 对象
- HEAD:该文件指明了本地的分支结果,如本地分支是 master,那么 HEAD 就指向 master,分支在 refs 中就会表示成
refs:refs/heads/master - index:该文件 stage 暂存区信息,也就是 add 之后保存到的区域,内容包括它指向的文件的时间戳,文件名,sha1 值等
- refs:该文件夹保存了指向分支的提交对象也就是 commit 对象的指针,其中的 heads 文件夹存储了本地每一个分支最近一次提交的 sha-1 值,即 commit 对象的 sha-1 值,每个分支一个文件;remotes 文件夹则记录你最后一次和远程仓库的通信,也就是说这里会记录最后一次每个分支推送到远端的值;tags 文件夹存储分支别名
-
sha-1 算法介绍说明:其实 sha-1 算法在两千零几年中国已经被攻破,有人就提出 git 的安全性问题,由于 git 是 linus 在此算法还没被攻破时候创建,linus 现在不以为然,因为他认为没有人会发这么大经理偷偷篡改他人代码树,他认为即使是使用老掉牙的 md5 都是可行,未来 git 中的 sha-1 算法还是有可能被替换,参见 http://www.itxm.cn/post/14240.html
-
其他文件:
- hooks:这里主要定义了客户端或服务端的 hook 脚本,这些脚本用于在特定命令和操作之前、之后进行特殊处理
- description:仅供 GitWeb 程序使用
- logs:记录了本地仓库和远程仓库的每一个分支的提交信息,即所有 commit 对象都会被记录在此,这个文件夹内容应该是我们查看最频繁的,如 git log
- info:其中保存了一份不希望在 .gitignore 文件中管理的忽略的全局可执行文件
- COMMIT_EDITMSG:记录了最后一次提交时的注释信息
我们可以看到 .git 目录中的文件会因为几次提交就成倍的增长,因为其中要生成对象
三.git add 与 git commit 简单原理
平时我们在工作区修改文件,没有 add 操作之前我们通过 git status 命令可以查看到有文件被 modified 而且是 not staged,这个时候修改的文件仅仅是在工作区内,之后通过 git add 操作,被修改的文件从工作区提交到暂存区(驿站)也就是 stage 里,再通过 commit 操作把暂存区 stage 中所有的内容全部提交到当前的分支结构当中,即
工作区(文件修改后 add 前)→ stage 暂存区(add 后 commit 前)→ 本地分支结构(本地 commit 后)
这样的一种三层结构
四.创建与合并分支简单原理
分支被合并可以被 -d 删除,分支没有被合并后 -d 删除会出错,需要 -D 强制删除
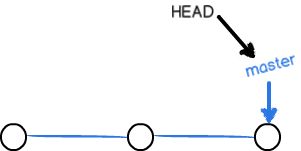
- master分支
一个分支就是一条时间线,默认有一条时间线master,其中有个指针master,这个master指针是指向提交的,还有个HEAD指针,这个指针是指向当前的指向提交的指针的指针,也就是指向当前分支的指针。每次提交,master指针都会向后移一位,这样不断去提交,master分支就会越来越长。如下图1:
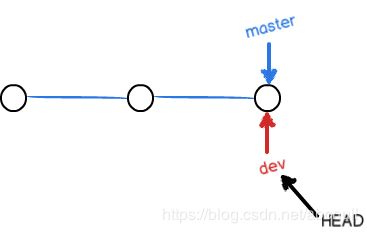
- 创建dev新分支
若创建新分支,如dev分支,git会新建一个dev指针,与master指针功能一样。先是指向和master同样的位置,当checkout切换到dev分支时候,HEAD指针就指向了dev指针了,当在dev分支下提交,master指针不动。如下图2和图3:
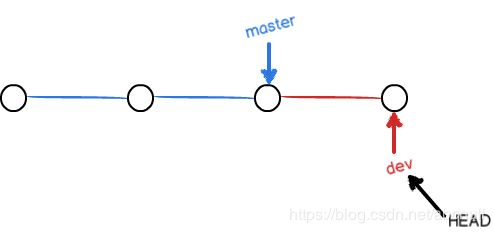
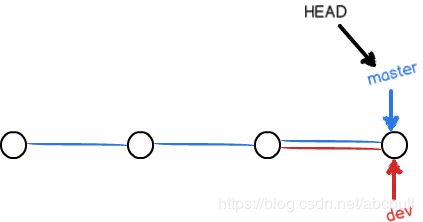
- 分支的合并
分支合并,操作很简单,若将dev分支内容合到master上,就是将master的指针指向dev指针指向的位置即可,如图4:
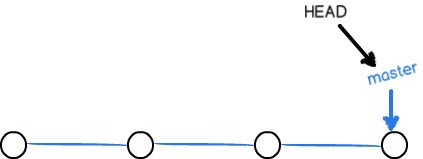
- 删除dev分支
删除分支就是讲dev指针删除掉,如图5:
五.git rebase 简单原理
把一个分支的修改整合到另一个分支的办法有两种,第一种就是 git merge 操作,另一种就是 git rebase 操作,该命令原理就是回到两个分支最近的共同祖先,根据当前分支(也就是要进行衍合的分支experiment)后续的历次提交对象(这里只有一个 C3),生成一系列文件补丁,然后以基底分支(也就是主干分支master)最后一个提交对象(C4)为新的出发点,逐个应用之前准备好的补丁文件,最后会生成一个新的合并提交对象(C3’),从而改写 experiment 的提交历史,使它成为 master 分支的直接下游。如下图所示:
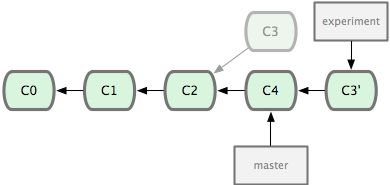
在rebase的过程中,也许会出现冲突。在这种情况,Git会停止rebase并会让你去解决冲突;在解决完冲突后,用git add命令去更新这些内容的索引, 然后,你无需执行git-commit,只要执行git rebase –continue,这样git会继续应用(apply)余下的补丁。如果要舍弃本次衍合,只需要git rebase --abort即可。切记,一旦分支中的提交对象发布到公共仓库,就千万不要对该分支进行rebase操作。
六.开始从底层入手 git
git 命令分为 procelain 和 plumbing 命令,前者是基于后者来实现的,若把 git 看成一个操作系统那么 plumbing 命令更像是一个 shell 命令,而 procelain 命令就像是通过利用 shell 命令编写的一系列系统功能或工具,下面会重点讲解 plumbing 命令以及 git 对象
-
plumbing 命令:
git 本质上一套内容寻址(content-addressable)文件系统,寻址无非就是查找,这样的寻址系统对于完成过 linux 系统构建的 linus 肯定不算难事。寻址无非就是查找,git 采用的是 HashTable 的方式进行查找,即 git 是通过简单键值对形式实现内容寻址,键就是文件(头+内容)的哈希值(前面 .git 目录结构中也讲了采用 sha-1 加密方式,40位,点击这里跳转到前面),值是经过压缩后的文件内容,plumbing 操作实际上是 40 位的哈希值来进行压缩包的查找
git 对象存储方式表示式:
Key = sha1(file_header + file_content) Value = zlib(file_content) -
git 对象:
前面也讲了 git 对象有 BLOB(binary large object),tree,commit 三种,点击这里跳转到前面,BLOB 存储几乎所有的文件类型,BLOB 大的二进制表示的对象,和数据库中 BLOB 类型,常用来存储数据库中图片视频是一样的;tree 是用来组织 BLOB 对象的一种数据类型,你完全可以理解成二叉树中的树结点,只不过 git 中的可是“多叉树”,commit 对象表示每一次的提交操作,是由 tree 对象衍生出来,通过每次提交,这样所有的 commit 操作便可连成一个提交树,一个 branch 实际上就是这个大树中的一个子树
七.git add 命令底层原理
stage 暂存区又叫索引库,因为暂存区信息内容保存在 .git 目录结构的 index 文件夹,git add 就是把工作区 modified 文件添加到 stage 暂存区,那么 git add 底层是如何通过 plumbing 命令完成文件索引操作的?
-
git add 对应着的两个基本 plumbing 命令
git hash-object #获取指定文件的key,如果带上-w选项,则会将该对象的value进行存储 git update-index #将指定的object加入索引库,需要带上—add选项先用第一个命令将需要暂存的文件进行 key-value 转化成 git 对象,进行存储(.git 中的 objects 文件夹中),拿到这些文件的 key,然后通过第二条命令将这些对象加入到 stage 暂存区中暂存(.git 中的 index 文件夹中)
若还要根据 git 对象的 key 来查看文件信息,需要如下 plumbing 命令
git cat-file –p/-t key #获取指定key的对象信息,-p打印详细信息,-t打印对象的类型也就是说 git add 命令本质上就是把工作区修改的文件变成 git 对象并且拿到 sha-1 值放在 objects 文件夹中,然后连同 key 一起转存到另一个 index 文件夹中(暂存区)。实际上 index 库记录是从项目初始化起,每次 add 在这里都会把文件的索引信息(时间戳和大小)更新,也就是说这个库只会越来越大
八.git add 和 git commit 中间的操作(tree 对象的生成)
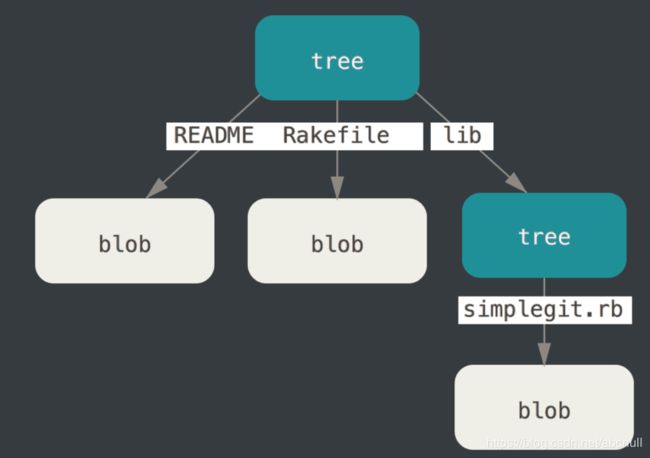
git 中所有内容以 BLOB 或者 tree 对象形式存储。如果把 git 看做 unix 系统,那么 tree 对象就好似文件系统中的目录,BLOB 对象就好似 inodes 或文件内容。我们平时操作的 add 和 commit 操作似乎没有涉及到这个 tree 对象的生成,其实有的,tree 对象只是 add 和 commit 中间的一个缓冲步骤,因为 commit 对象要根据 tree 对象来创建,下面创建 tree 对象:
git write-tree #根据索引库中的信息创建tree对象
这条命令的作用是返回生成 tree 对象的 key 值
整个工作目录对应一个 tree 对象,并且其下每一个子文件夹都是一个 tree 对象,每次的 commit 对象都对应着根 tree 对象,任何一个对象的改变都会导致其上层所有 tree 对象的重新存储
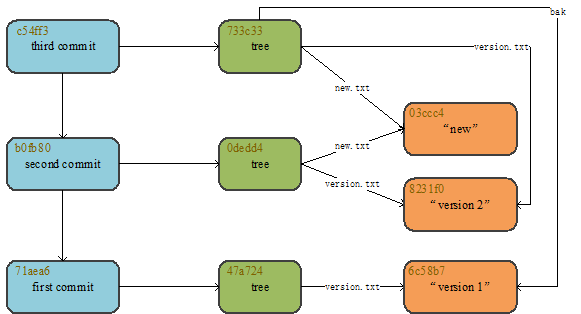
九.git commit 命令底层原理
index 暂存区包括了项目仓库中所有的文件,commit 对象所对应的 tree 对象永远都是工作区根目录所对应的 tree 对象,也就是说每次 commit 之后,commit 对象会依附在这个工作区的 tree 对象上。要是仔细观察目录结构的话,可以发现对象文件夹,子文件夹对应着一个 tree 结点,文件的话对应着一个 BLOB 结点,创建 commit 对象的命令:
git commit-tree key –p key2 #根据tree对象创建commit对象,-p表示前继commit对象
该命令实现的操作类似于数据结构树中增加结点的操作,在这个命令中若是第一次提交则不需要指定 -p 选项指明父节点
下一篇
git 常用命令
git 常见场景操作