高德地图上那种轨迹纠偏是如何实现的
原文地址: nyc taxi bootcamp
这里介绍一个好玩的开源项目Arctern。
这个项目好玩在哪里呢,下图是纽约出租车上车点的原始数据
 从图上可以明显的看到,有些上车点并不在道路上,这表明GPS信号数据存在噪声。
从图上可以明显的看到,有些上车点并不在道路上,这表明GPS信号数据存在噪声。
Arctern的解决方案是这样的,把每个点偏移到离他最近的道路上去,下图是处理结果,效果相当明显

以下为原文
环境准备
-
安装 Arctern
-
安装 Jupyter
在上一步中的
arctern_env环境中执行以下命令安装 Jupyter Notebook:$ conda install -c conda-forge notebook -
安装依赖库
在
arctern_env环境中执行以下命令安装相关依赖库:$ pip install keplergl pyshp sridentify
下载数据
我们需要下载 20 万条纽约出租车数据和纽约市的地形数据图数据,默认将其下载至 /tmp 下:
$ cd /tmp
# 下载纽约出租车数据
$ wget https://raw.githubusercontent.com/zilliztech/arctern-bootcamp/master/nytaxi/file/0_2M_nyc_taxi_and_building.csv
# 下载并解压纽约市的地形数据图
$ wget https://github.com/zilliztech/arctern-bootcamp/raw/master/nytaxi/file/taxi_zones.zip
$ unzip -d taxi_zones taxi_zones.zip
# 下载纽约市的道路网数据
$ wget https://raw.githubusercontent.com/zilliztech/arctern-bootcamp/master/nytaxi/file/nyc_road.csv
# 下载 kepler 配置文件
$ wget https://raw.githubusercontent.com/zilliztech/arctern-bootcamp/master/nytaxi/file/map_config.json
运行 jupyter-notebook
下载 arctern_nytaxi_bootcamp.ipynb 文件,在 arctern_env 环境中运行 jupyter notebook:
$ wget https://raw.githubusercontent.com/zilliztech/arctern-bootcamp/master/nytaxi/arctern_nytaxi_bootcamp.ipynb
# 运行 jupyter notebook
$ jupyter notebook
在 jupyter 网页中打开 arctern_nytaxi_bootcamp.ipynb 文件,就可以开始运行代码了。
纽约出租车数据分析示例
接下来将介绍关于纽约出租车数据的数据清理和数据分析过程。
1. 数据预处理
本文示例数据提取自纽约出租车中的 20 万条,当我们在处理大规模数据时通常会存在一些噪点数据,而这些噪点数据通常不易发现却又影响分析结果,那么如何快速发现噪点数据以及数据预处理就是我们分析数据的一个重点。
1.1 数据加载
首先根据纽约出租车数据集中各个字段的名称和数据类型,构建数据的 nyc_schema 并导入数据。
import pandas as pd
nyc_schema={
"VendorID":"string",
"tpep_pickup_datetime":"string",
"tpep_dropoff_datetime":"string",
"passenger_count":"int64",
"trip_distance":"double",
"pickup_longitude":"double",
"pickup_latitude":"double",
"dropoff_longitude":"double",
"dropoff_latitude":"double",
"fare_amount":"double",
"tip_amount":"double",
"total_amount":"double",
"buildingid_pickup":"int64",
"buildingid_dropoff":"int64",
"buildingtext_pickup":"string",
"buildingtext_dropoff":"string",
}
nyc_df=pd.read_csv("/tmp/0_2M_nyc_taxi_and_building.csv",
dtype=nyc_schema,
date_parser=pd.to_datetime,
parse_dates=["tpep_pickup_datetime","tpep_dropoff_datetime"])
1.2 数据展示
我们本次处理的 gis 数据主要包括出租车辆的上车点和下车点的经纬度, 接下来将 Arctern 结合 keplergl 展示在地图上所有 gis 点位置,根据可视化结果可以看出数据集的一些情况。首先加载车辆的上车点数据:
import arctern
from arctern import GeoSeries
from keplergl import KeplerGl
pickup_points = GeoSeries.point(nyc_df.pickup_longitude,nyc_df.pickup_latitude)
KeplerGl(data={"pickup_points": pd.DataFrame(data={'pickup_points':pickup_points.to_wkt()})})
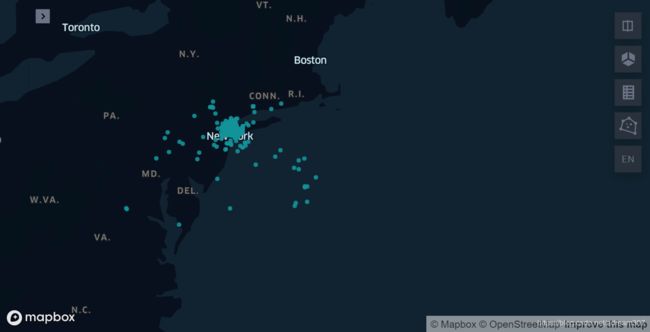
返回的结果在地图上支持交互操作,可以发现输入的出租车数据存有噪点,有些上车点已经到海面上了,实际上所有数据应该都集中在陆地上才是合理的,这些噪点数据就需要我们通过一定的方法进行清洗过滤。
1.3 数据过滤
为了正确分析纽约市区中的出租车数据,接下来我们会根据纽约市的地形图来过滤数据,即不在纽约市地图中的数据视为噪点数据并进行过滤,这一步骤也会介绍如何将加载的 GeoJSON 数据转换为 “EPSG:4326” ,即纬度和经度坐标。
1.3.1 数据转换
读取纽约市的地形数据图,该地形数据是以 GeoJSON 格式存储的,首先使用 Arctern 解析 GeoJSON 数据:
import shapefile
import json
# 读取纽约市的地形数据图
nyc_shape = shapefile.Reader("/tmp/taxi_zones/taxi_zones.shp")
nyc_zone=[ shp.shape.__geo_interface__ for shp in nyc_shape.shapeRecords()]
nyc_zone=[json.dumps(shp) for shp in nyc_zone]
# 使用 Arctern 读取数据
nyc_zone_series=pd.Series(nyc_zone)
nyc_zone_arctern=GeoSeries.geom_from_geojson(nyc_zone_series)
nyc_zone_arctern.to_wkt()
Arctern 读取的数据结果如下:
0 POLYGON ((933100.91835271 192536.085697202,933...
1 MULTIPOLYGON (((1033269.24359129 172126.007812...
2 POLYGON ((1026308.76950666 256767.697540373,10...
3 POLYGON ((992073.46679686 203714.07598877,9920...
4 POLYGON ((935843.310493261 144283.335850656,93...
...
258 POLYGON ((1025414.78196019 270986.139363825,10...
259 POLYGON ((1011466.96605045 216463.005203798,10...
260 POLYGON ((980555.204311222 196138.486258477,98...
261 MULTIPOLYGON (((999804.794550449 224498.527048...
262 POLYGON ((997493.322715312 220912.386162326,99...
Length: 263, dtype: object
获得当前纽约市地形数据文件的坐标系,并利用 Arctern 将该坐标系转成经纬度坐标系,即 “EPSG:4326” :
from sridentify import Sridentify
ident = Sridentify()
ident.from_file('/tmp/taxi_zones/taxi_zones.prj')
src_crs = ident.get_epsg()
nyc_zone_arctern.set_crs(f'EPSG:{src_crs}')
nyc_arctern_4326 = nyc_zone_arctern.to_crs(crs="EPSG:4326")
nyc_arctern_4326.to_wkt()
坐标转换后的结果如下:
0 POLYGON ((-74.184453 40.694996,-74.184489 40.6...
1 MULTIPOLYGON (((-73.8233759726066 40.638987047...
2 POLYGON ((-73.8479261409998 40.871342234,-73.8...
3 POLYGON ((-73.9717741096532 40.7258212813371,-...
4 POLYGON ((-74.1742173809999 40.5625680859999,-...
...
258 POLYGON ((-73.851071161919 40.910371520111,-73...
259 POLYGON ((-73.9017537339999 40.760775475,-73.9...
260 POLYGON ((-74.0133261089999 40.7050307879999,-...
261 MULTIPOLYGON (((-73.9438325669999 40.782859089...
262 POLYGON ((-73.95218622 40.7730198449999,-73.95...
Length: 263, dtype: object
根据转换后的经纬度坐标,绘制的纽约市地形图如下:
KeplerGl(data={"nyc_zones": pd.DataFrame(data={'nyc_zones':nyc_arctern_4326.to_wkt()})})

1.3.2 数据清洗
我们认为不在纽约市轮廓图内的点即为噪点,以此过滤出租车数据,首先我们根据纽约市区的轮廓图对上车点进行过滤:
index_nyc = arctern.within_which(pickup_points, nyc_arctern_4326)
is_in_nyc = index_nyc.notna()
pickup_in_nyc = pickup_points[pd.Series(is_in_nyc)]
绘制出数据过滤后的上车点:
KeplerGl(data={"pickup_points": pd.DataFrame(data={'pickup_points':pickup_in_nyc.to_wkt()})})

那么根据同样的方法,对乘客的下车点进行过滤:
dropoff_points = GeoSeries.point(nyc_df.dropoff_longitude,nyc_df.dropoff_latitude)
index_nyc = arctern.within_which(dropoff_points, nyc_arctern_4326)
is_dorpoff_in_nyc = index_nyc.notna()
dropoff_in_nyc=dropoff_points[is_dorpoff_in_nyc]
KeplerGl(data={"drop_points": pd.DataFrame(data={'drop_points':dropoff_in_nyc.to_wkt()})})
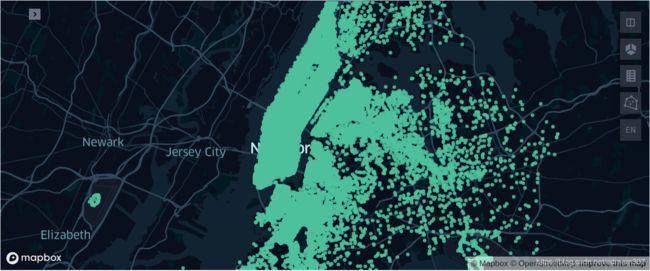
根据上车点和下车点经纬度数据,在最初的数据上过滤所有的非法数据:
in_nyc_df=nyc_df[is_in_nyc & is_dorpoff_in_nyc]
in_nyc_df.fare_amount.describe()
过滤后的数据关于行程费用的描述信息为:
count 195479.000000
mean 9.791914
std 7.266372
min 2.500000
25% 5.700000
50% 7.700000
75% 11.300000
max 175.000000
Name: fare_amount, dtype: float64
根据纽约市轮廓图对租车数据过滤后,我们发现很多上车点的位置和道路有一些偏差,甚至偏离到某些建筑物内:
import json
with open("/tmp/map_config.json", "r") as f:
config = json.load(f)
KeplerGl(data={"projectioned_point": pd.DataFrame(data={'projectioned_point':pickup_in_nyc.to_wkt()})},config=config)

我们认为离道路较远的数据同样为噪点(默认离道路距离大于 100m 视为较远),通过匹配纽约市的道路网将偏离道路较远的租车数据过滤掉,首先加载纽约市道路网:
import arctern
nyc_road=pd.read_csv("/tmp/nyc_road.csv", dtype={"roads":"string"}, delimiter='|')
roads=GeoSeries(nyc_road.roads)
然后根据纽约市的道路网对上车点和下车点进行过滤:
pickup_points = GeoSeries.point(in_nyc_df.pickup_longitude,in_nyc_df.pickup_latitude)
pickup_points.set_axis(in_nyc_df.index,inplace=True)
dropoff_points = GeoSeries.point(in_nyc_df.dropoff_longitude,in_nyc_df.dropoff_latitude)
dropoff_points.set_axis(in_nyc_df.index,inplace=True)
is_pickup_near_road = arctern.near_road(roads, pickup_points)
is_dropoff_near_road = arctern.near_road(roads, dropoff_points)
is_near_road = is_pickup_near_road & is_dropoff_near_road
on_road_nyc_df = in_nyc_df[is_near_road]
过滤距离道路较远的租车数据之后,我们将上车点绑定到最近的道路上,生成新的上车点:
pickup_points = GeoSeries.point(on_road_nyc_df.pickup_longitude,on_road_nyc_df.pickup_latitude)
pickup_points.set_axis(on_road_nyc_df.index,inplace=True)
projectioned_pickup = arctern.nearest_location_on_road(roads, pickup_points)
projectioned_pickup = GeoSeries(projectioned_pickup)
绘制出数据绑定道路后的上车点:
KeplerGl(data={"projectioned_point": pd.DataFrame(data={'projectioned_point':projectioned_pickup.to_wkt()})},config=config)
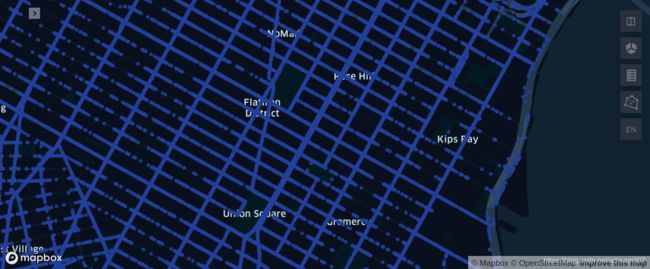
根据同样的方法,将乘客下车点绑定到最近的道路上,生成新的下车点:
dropoff_points = GeoSeries.point(on_road_nyc_df.dropoff_longitude,on_road_nyc_df.dropoff_latitude)
dropoff_points.set_axis(on_road_nyc_df.index,inplace=True)
projectioned_dropoff = arctern.nearest_location_on_road(roads, dropoff_points)
projectioned_dropoff = GeoSeries(projectioned_dropoff)
KeplerGl(data={"projectioned_point": pd.DataFrame(data={'projectioned_point':projectioned_dropoff.to_wkt()})},config=config)

将绑路后的乘客上下车位置信息添加到 on_road_nyc_df 中:
on_road_nyc_df.insert(16,'pickup_on_road',projectioned_pickup)
on_road_nyc_df.insert(17,'dropoff_on_road',projectioned_dropoff)
on_road_nyc_df.fare_amount.describe()
过滤后的数据关于行程费用的描述信息为:
count 194786.000000
mean 9.692384
std 6.976573
min 2.500000
25% 5.700000
50% 7.700000
75% 11.000000
max 175.000000
Name: fare_amount, dtype: float64
综上我们完成了数据过滤,根据预处理的数据我们将对出租车数据进行分析。
2. 数据分析
数据过滤这一步十分重要,它可以保证我后期的数据分析结果有效。接下来我们将根据交易额和直线距离分析出租车的运营情况。
2.1 关于交易额
我们按照交易额提取费用大于 50 美元的数据,并绘制出租车的上车点和下车点:
fare_amount_gt_50 = on_road_nyc_df[on_road_nyc_df.fare_amount > 50]
KeplerGl(data={"pickup": pd.DataFrame(data={'pickup':fare_amount_gt_50.pickup_on_road.to_wkt()}),
"dropoff":pd.DataFrame(data={'dropoff':fare_amount_gt_50.dropoff_on_road.to_wkt()})
})

可以展开结果地图中左上角的小三角,对当前的图层进行操作,例如隐藏上车点或下车点,我们发现费用大于 50 美元的,基本都是从市中心触发去周边比较远的地方。
2.2 关于距离
我们还可以计算上车点和下车点的直线距离:
on_road_nyc_df.pickup_on_road.set_crs("EPSG:4326")
on_road_nyc_df.dropoff_on_road.set_crs("EPSG:4326")
nyc_distance=on_road_nyc_df.pickup_on_road.distance_sphere(on_road_nyc_df.dropoff_on_road)
nyc_distance.describe()
车辆的直线距离结果描述为:
count 194786.000000
mean 3113.344497
std 3232.008220
min 0.000000
25% 1224.650347
50% 2087.753029
75% 3730.790193
max 35418.698339
dtype: float64
获得直线距离大于 20 公里的点,并绘制所有直线距离大于 20 公里的上车点和下车点:
nyc_with_distance=pd.DataFrame({"pickup":on_road_nyc_df.pickup_on_road,
"dropoff":on_road_nyc_df.dropoff_on_road,
"sphere_distance":nyc_distance
})
nyc_dist_gt = nyc_with_distance[nyc_with_distance.sphere_distance > 20e3]
KeplerGl(data={"pickup": pd.DataFrame(data={'pickup':nyc_dist_gt.pickup.to_wkt()}),
"dropoff":pd.DataFrame(data={'dropoff':nyc_dist_gt.dropoff.to_wkt()})
})
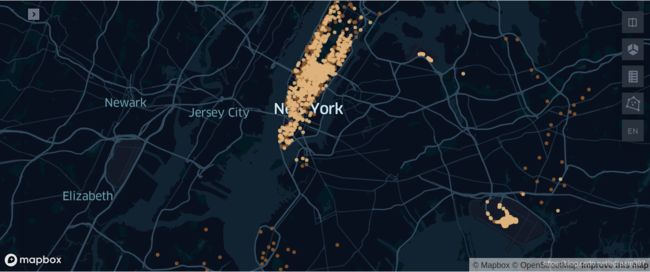
同样我们发现直线距离大于 20 公里的,也都是从市中心触发去周边比较远的地方。综上我们完成了对出租车数据关于交易额和里程距离的分析,更多分析功能可以参考 Arctern API。