Hadoop 2.X 管理与开发
一、Hadoop的起源与背景知识
(一)什么是大数据
大数据(Big Data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据的5个特征(IBM提出):
l Volume (大量)
l Velocity(高速)
l Variety (多样)
l Value (价值)
l Veracity(真实性)
大数据的典型案例:
l 电商网站的商品推荐

l 基于大数据的天气预报

(二)OLTP与OLAP
l OLTP:On-Line Transaction Processing(联机事务处理过程)。也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
典型案例:银行转账
|
l OLAP:On-Line Analytic Processing(联机分析处理过程)。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
典型案例:商品推荐
|
l OLTP和OLAP的区别:

(三)数据仓库
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。

(四)Google的基本思想
Hadoop的思想来源:Google
l Google搜索引擎,Gmail,安卓,AppspotGoogle Maps,Google earth,Google学术,Google翻译,Google+,下一步Google what?
l Google的低成本之道
n 不使用超级计算机,不使用存储(淘宝的去i,去e,去o之路)
n 大量使用普通的pc服务器(去掉机箱,外设,硬盘),提供有冗余的集群服务
n 全世界多个数据中心,有些附带发电厂
n 运营商向Google倒付费

l Google的三篇论文(Hadoop的思想来源)
n GFS(Google File System:Google的文件系统)

n 倒排索引

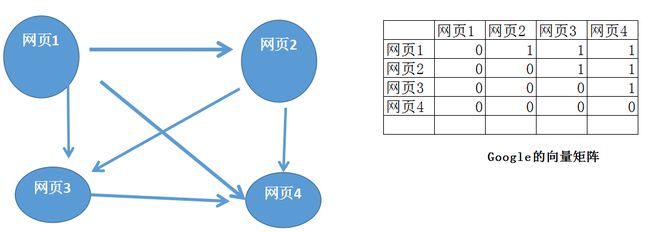
n Page Rank(排名先后)
n BigTable(大表):BigTable是Google设计的分布式数据存储系统,用来处理海量的数据的一种非关系型的数据库。
Eg:什么是关系模型?(关系型数据库)
u 常见的NoSQL数据库(key-value值):
(1) HBase: 基于HDFS的NoSQL数据库、面向列的
(2) Redis: 基于内存的NoSQL数据库、支持持久化: rdb和aof
(3) MongoDB: 面向文档的NoSQL
(4) Cassandra: 面向列的NoSQL数据库
l Hadoop的源起——Lucene,从lucene到nutch,从nutch到hadoop
n 2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,使Nutch性能飙升
n Yahoo招安Doug Cutting及其项目
n Hadoop于2005 年秋天作为Lucene的子项目Nutch的 一部分正式引入Apache基金会。2006 年 3 月份,Map-Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
n 名字来源于Doug Cutting儿子的玩具大象

二、实验环境
| 介质 |
说明 |
| VMware |
虚拟机管理器 |
| MySQL |
MySQL数据库的安装介质 |
| WinSCP-5.9.2-Portable.zip |
FTP客户端工具 |
| Putty |
登录Linux的命令行客户端 |
| Enterprise-R5-U2-Server-i386-dvd.iso |
Oracle Linux安装介质 |
| jdk-7u75-linux-i586.tar.gz |
JDK安装包 |
| hadoop-2.4.1.tar.gz |
Hadoop安装包 |
| hbase-0.96.2-hadoop2-bin.tar.gz |
HBase NoSQL安装包 |
| hue-3.7.0-cdh5.4.2.tar.gz |
HUE(基于Web的管理工具)安装包 |
| apache-hive-0.13.0-bin.tar.gz |
Hive(基于Hadoop的数据仓库)安装包 |
| apache-hive-0.13.0-src.tar.gz |
Hive(基于Hadoop的数据仓库)源码 |
| apache-flume-1.6.0-bin.tar.gz |
Flume(日志采集工具)安装包 |
| sqoop-1.4.5.bin__hadoop-0.23.tar.gz |
Sqoop(HDFS与RDBMS的数据交换)安装包 |
| pig-0.14.0.tar.gz |
Pig(基于Hadoop的数据分析引擎)安装包 |
| zookeeper-3.4.6.tar.gz |
ZooKeeper(实现Hadoop的HA)安装包 |
Eg:Hadoop的HDFS和MapReduce示例Demo。
三、Apache Hadoop的体系结构(重点)
(一)分布式存储:HDFS

l NameNode(名称节点)
1.维护HDFS文件系统,是HDFS的主节点。
2.接受客户端的请求: 上传文件、下载文件、创建目录等等


3.记录客户端操作的日志(edits文件),保存了HDFS最新的状态
① Edits文件保存了自最后一次检查点之后所有针对HDFS文件系统的操作,比如:增加文件、重命名文件、删除目录等等
② 保存目录:$HADOOP_HOME/tmp/dfs/name/current
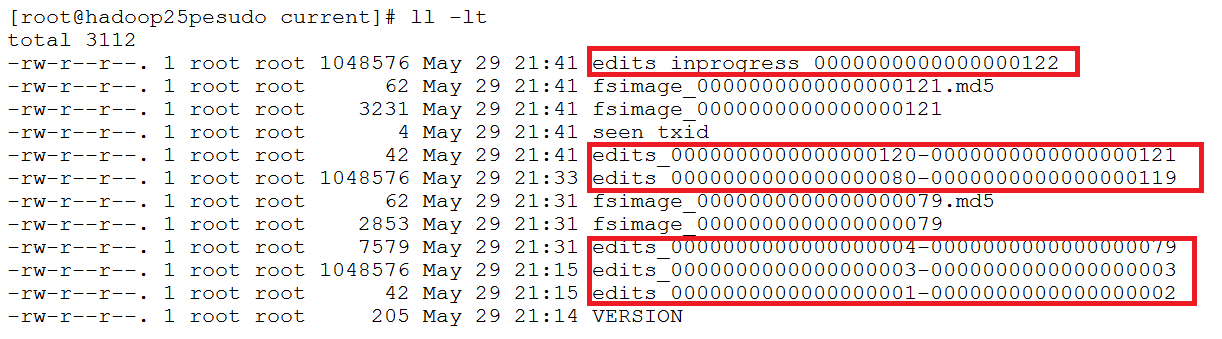
③ 可以使用hdfs oev -i命令将日志(二进制)输出为XML文件

输出结果为:

4.维护文件元信息,将内存中不常用(采用LRU算法)的文件元信息保存在硬盘上(fsimage文件)
① fsimage是HDFS文件系统存于硬盘中的元数据检查点,里面记录了自最后一次检查点之前HDFS文件系统中所有目录和文件的序列化信息
② 保存目录:$HADOOP_HOME/tmp/dfs/name/current
③ 可以使用hdfs oiv -i命令将日志(二进制)输出为文本(文本和XML)

l DataNode(数据节点)
1.以数据块为单位,保存数据
① Hadoop 1.0的数据块大小: 64M
② Hadoop 2.0 的数据块大小:128M
2.在全分布模式下,至少两个DataNode节点
3.数据保存的目录:由hadoop.tmp.dir参数指定
例如:

l Secondary NameNode(第二名称节点)
1.主要作用是进行日志合并
2.日志合并的过程:

l HDFS存在的问题
① NameNode单点故障,难以应用二在线场景
解决方案:Hadoop 1.0中,没有解决方案。
Hadoop 2.0 中,使用ZooKeeper实现NameNode的HA功能。
② NameNode压力过大,且内存受限,影响系统扩展性
解决方案:Hadoop 1.0 中,没有解决方案。
Hadoop 2.0 中,使用NameNode的联盟实现其水平扩展。
(二)YARN: 分布式计算(MapReduce)
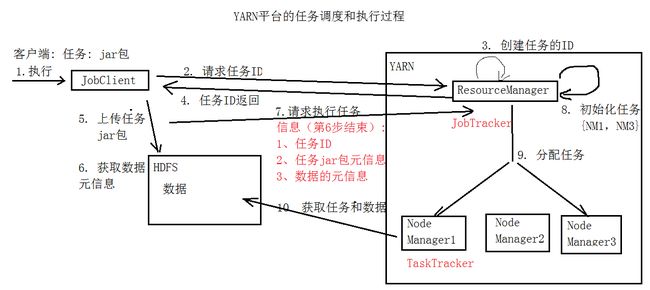
l ResourceManager(资源管理器)
① 接受客户端的请求: 执行任务
② 分配资源
③ 分配任务
l NodeManager(节点管理器:运行任务MapReduce)
① 从DataNode上获取数据,执行任务
(三)HBase的体系结构

四、Hadoop 2.X的安装与配置
(一)Hadoop安装部署的预备条件
l 安装Linux
l 安装JDK
(二)Hadoop的目录结构

(三)Hadoop安装部署的三种模式
l 本地模式
l 伪分布模式
l 全分布模式
本地模式的配置
| 参数文件 |
配置参数 |
参考值 |
| hadoop-env.sh |
JAVA_HOME |
/root/training/jdk1.8.0_144 |
伪分布模式的配置
| 参数文件 |
配置参数 |
参考值 |
| hadoop-env.sh |
JAVA_HOME |
/root/training/jdk1.8.0_144 |
| hdfs-site.xml |
dfs.replication |
1 |
| dfs.permissions |
false |
|
| core-site.xml |
fs.defaultFS |
hdfs:// |
| hadoop.tmp.dir |
/root/training/hadoop-2.7.3/tmp |
|
| mapred-site.xml |
mapreduce.framework.name |
yarn |
| yarn-site.xml |
yarn.resourcemanager.hostname |
|
| yarn.nodemanager.aux-services |
mapreduce_shuffle |
全分布模式的配置
| 参数文件 |
配置参数 |
参考值 |
| hadoop-env.sh |
JAVA_HOME |
/root/training/jdk1.8.0_144 |
| hdfs-site.xml |
dfs.replication |
2 |
| dfs.permissions |
false |
|
| core-site.xml |
fs.defaultFS |
hdfs:// |
| hadoop.tmp.dir |
/root/training/hadoop-2.7.3/tmp |
|
| mapred-site.xml |
mapreduce.framework.name |
yarn |
| yarn-site.xml |
yarn.resourcemanager.hostname |
|
| yarn.nodemanager.aux-services |
mapreduce_shuffle |
|
| slaves |
DataNode的地址 |
从节点1 从节点2 |
如果出现以下警告信息:
只需要在以下两个文件中增加下面的环境变量,即可:
l hadoop-env.sh脚本中
export JAVA_HOME=/root/training/jdk1.8.0_144
export HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
l yarn-env.sh脚本中
export JAVA_HOME=/root/training/jdk1.8.0_144
export HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
(四)验证Hadoop环境
l HDFS Console:http://192.168.157.11:50070

l Yarn Console:http://192.168.157.11:8088

(五)配置SSH免密码登录

Demo:配置Linux SSH的免密码登录。
五、Hadoop应用案例分析
(一)互联网应用的架构
① 传统的架构

② 改良后的架构

③ 完整的架构图
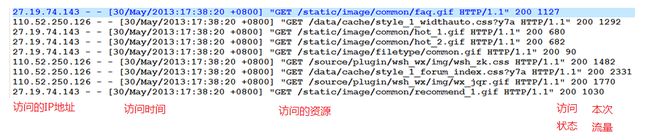
(二)日志分析
① 需求说明
l 对某技术论坛的apache server日志进行分析,计算论坛关键指标,供运营者决策
② 论坛日志数据有两部分
l 历史数据约56GB,统计到2012-05-29
l 自2013-05-30起,每天生成一个数据文件,约150MB
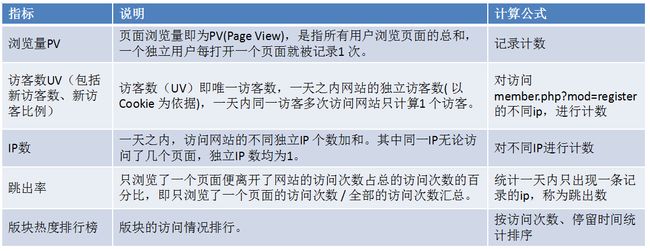
③ 关键指标
④ 系统架构

⑤ 改良后的系统架构

⑥ HBase表的结构
⑦ 日志分析的执行过程
l 周期性把日志数据导入到hdfs中
l 周期性把明细日志导入hbase存储
l 周期性使用hive进行数据的多维分析
l 周期性把hive分析结果导入到mysql中
(三)Hadoop在淘宝的应用
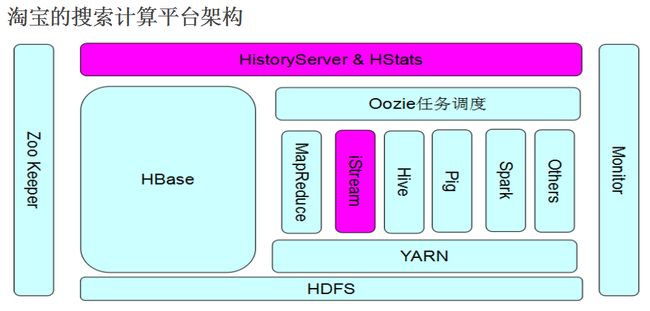
六、HDFS
(一)HDFS的命令行操作
l HDFS操作命令(HDFS操作命令帮助信息:hdfs dfs)
| 命令 |
说明 |
示例 |
|
| -mkdir |
在HDFS上创建目录 |
l 在HDFS上创建目录/data hdfs dfs -mkdir /data l 在HDFS上级联创建目录/data/input hdfs dfs -mkdir -p /data/input |
|
| -ls |
列出hdfs文件系统根目录下的目录和文件 |
l 查看HDFS根目录下的文件和目录 hdfs dfs -ls / l 查看HDFS的/data目录下的文件和目录 hdfs dfs -ls /data |
|
| -ls -R |
列出hdfs文件系统所有的目录和文件 |
l 查看HDFS根目录及其子目录下的文件和目录 hdfs dfs -ls -R / |
|
| -put |
上传文件或者从键盘输入字符到HDFS |
l 将本地Linux的文件data.txt上传到HDFS hdfs dfs -put data.txt /data/input l 从键盘输入字符保存到HDFS的文件 hdfs dfs -put - /aaa.txt |
|
| -moveFromLocal |
与put相类似,命令执行后源文件 local src 被删除,也可以从从键盘读取输入到hdfs file中 |
hdfs dfs -moveFromLocal data.txt /data/input
|
|
| -copyFromLocal |
与put相类似,也可以从从键盘读取输入到hdfs file中 |
hdfs dfs -copyFromLocal data.txt /data/input
|
|
| -copyToLocal |
|
|
|
| -get |
将HDFS中的文件被复制到本地 |
hdfs dfs -get /data/inputdata.txt /root/ |
|
| -rm |
每次可以删除多个文件或目录 |
hdfs dfs -rm < hdfs file > ... 删除多个文件 hdfs dfs -rm -r < hdfs dir>... 删除多个目录 |
|
| -getmerge |
将hdfs指定目录下所有文件排序后合并到local指定的文件中,文件不存在时会自动创建,文件存在时会覆盖里面的内容 |
将HDFS上/data/input目录下的所有文件,合并到本地的a.txt文件中 hdfs dfs -getmerge /data/input /root/a.txt |
|
| -cp |
拷贝HDFS上的文件 |
|
|
| -mv |
移动HDFS上的文件 |
|
|
| -count |
统计hdfs对应路径下的目录个数,文件个数,文件总计大小 显示为目录个数,文件个数,文件总计大小,输入路径 |
||
| -du |
显示hdfs对应路径下每个文件夹和文件的大小 |
hdfs dfs -du / |
|
| -text、-cat |
将文本文件或某些格式的非文本文件通过文本格式输出 |
||
| balancer |
如果管理员发现某些DataNode保存数据过多,某些DataNode保存数据相对较少,可以使用上述命令手动启动内部的均衡过程 |
||
l HDFS管理命令
HDFS管理命令帮助信息:hdfs dfsadmin
| 命令 |
说明 |
示例 |
| -report |
显示文件系统的基本数据 |
hdfs dfsadmin -report |
| -safemode |
HDFS的安全模式命令 < enter | leave | get | wait > |
hdfs dfsadmin -safemode enter|leave|get|wait |
(二)HDFS的Java API
通过HDFS提供的Java API,我们可以完成以下的功能:
① 在HDFS上创建目录
② 通过FileSystem API读取数据(下载文件)
③ 写入数据(上传文件)
④ 查看目录及文件信息
⑤ 查找某个文件在HDFS集群的位置
⑥ 删除数据
⑦ 获取HDFS集群上所有数据节点信息
l 在HDFS上创建目录

l 通过FileSystem API读取数据(下载文件)

l 写入数据(上传文件)

l 查看目录及文件信息
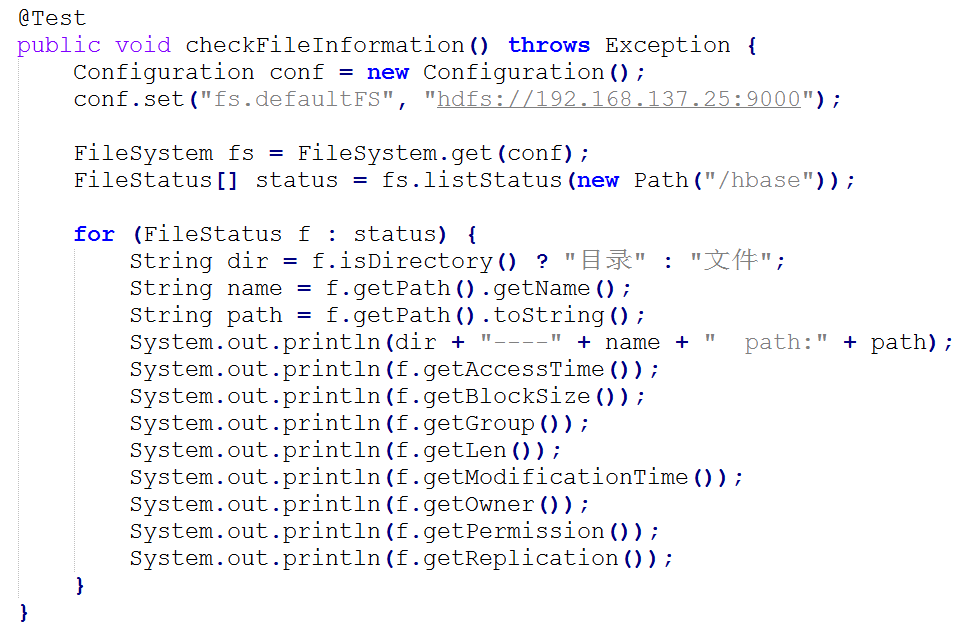
l 查找某个文件在HDFS集群的位置

l 删除数据

l 获取HDFS集群上所有数据节点信息

(三)HDFS的Web Console

(四)HDFS的回收站
l 默认回收站是关闭的,可以通过在core-site.xml中添加fs.trash.interval来打开幵配置时间阀值,例如:

l 删除文件时,其实是放入回收站/trash
l 回收站里的文件可以快速恢复
l 可以设置一个时间阈值,当回收站里文件的存放时间超过返个阈值,就被彻底删除,并且释放占用的数据块
l 查看回收站
hdfs dfs -lsr /user/root/.Trash/Current
l 从回收站中恢复
hdfs dfs -cp /user/root/.Trash/Current/input/data.txt/input
(五)HDFS的快照
l 一个snapshot(快照)是一个全部文件系统、或者某个目录在某一时刻的镜像
l 快照应用在以下场景中:
n 防止用户的错误操作
n 备份
n 试验/测试
n 灾难恢复
l HDFS的快照操作
n 开启快照
hdfs dfsadmin -allowSnapshot /input
n 创建快照
hdfs dfs -createSnapshot /input backup_input_01
n 查看快照
hdfs lsSnapshottableDir
n 对比快照
hdfs snapshotDiff /input backup_input_01 backup_input_02
n 恢复快照
hdfs dfs -cp /input/.snapshot/backup_input_01/data.txt /input
(六)HDFS的用户权限管理
l 超级用户:
n 启动namenode服务的用户就是超级用户, 该用户的组是supergroup

l Shell命令变更
| 命令 |
说明 |
| chmod [-R] mode file … |
只有文件的所有者或者超级用户才有权限改变文件模式。 |
| chgrp [-R] group file …chgrp [-R] group file … |
使用chgrp命令的用户必须属于特定的组且是文件的所有者,或者用户是超级用户 |
| chown [-R] [owner][:[group]] file … |
文件的所有者的只能被超级用户更改。 |
| ls(r) file … |
输出格式做了调整以显示所有者、组和模式。 |
l 文件系统API变更

(七)HDFS的配额管理
l 什么是配额?
n 配额就是HDFS为每个目录分配的大小空间,新建立的目录是没有配额的,最大的配额是Long.Max_Value。配额为1可以强制目录保持为空。
l 配额的类型
n 名称配额
u 用于设置该目录中能够存放的最多文件(目录)个数。
n 空间配额
u 用于设置该目录中最大能够存放的文件大小。
l 配额的应用案例
n 设置名称配额
u 命令:dfsadmin -setQuota
dfsadmin -clrQuota
u 示例:设置/input目录的名称配额为3
hdfs dfsadmin -setQuota 3 /input
清除/input目录的名称配额
hdfs dfsadmin -clrQuota /input
n 设置空间配额
u 命令:dfsadmin -setSpaceQuota
dfsadmin -clrSpaceQuota
u 示例:设置/input目录的空间配额为1M
hdfs dfsadmin -setSpaceQuota 1048576 /input
清除input目录的空间配额
hdfs dfsadmin -clrSpaceQuota /input
l 注意:如果hdfs文件系统中的文件个数或者大小超过了配额限制,会出现错误。
(八)HDFS的安全模式
l 什么时候安全模式?
安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。如果HDFS处于安全模式,则表示HDFS是只读状态。
l 当集群启动的时候,会首先进入安全模式。当系统处于安全模式时会检查数据块的完整性。假设我们设置的副本数(即参数dfs.replication)是5,那么在datanode上就应该有5个副本存在,假设只存在3个副本,那么比例就是3/5=0.6。在配置文件hdfs-default.xml中定义了一个最小的副本的副本率0.999,如图:

我们的副本率0.6明显小于0.99,因此系统会自动的复制副本到其他的dataNode,使得副本率不小于0.999.如果系统中有8个副本,超过我们设定的5个副本,那么系统也会删除多余的3个副本。
l 虽然不能进行修改文件的操作,但是可以浏览目录结构、查看文件内容的。
l 在命令行下是可以控制安全模式的进入、退出和查看的。
n 命令 hdfs dfsadmin -safemode get 查看安全模式状态
n 命令 hdfs dfsadmin -safemode enter 进入安全模式状态
n 命令 hdfs dfsadmin -safemode leave 离开安全模式
(九)HDFS的底层原理
l HDFS的底层通信原理采用的是:RPC和动态代理对象Proxy
l RPC
n 什么是RPC?
Remote Procedure Call,远程过程调用。也就是说,调用过程代码并不是在调用者本地运行,而是要实现调用者与被调用者二地之间的连接与通信。
RPC的基本通信模型是基于Client/Server进程间相互通信模型的一种同步通信形式;它对Client提供了远程服务的过程抽象,其底层消息传递操作对Client是透明的。
在RPC中,Client即是请求服务的调用者(Caller),而Server则是执行Client的请求而被调用的程序 (Callee)。
n RPC示例
l 服务器端

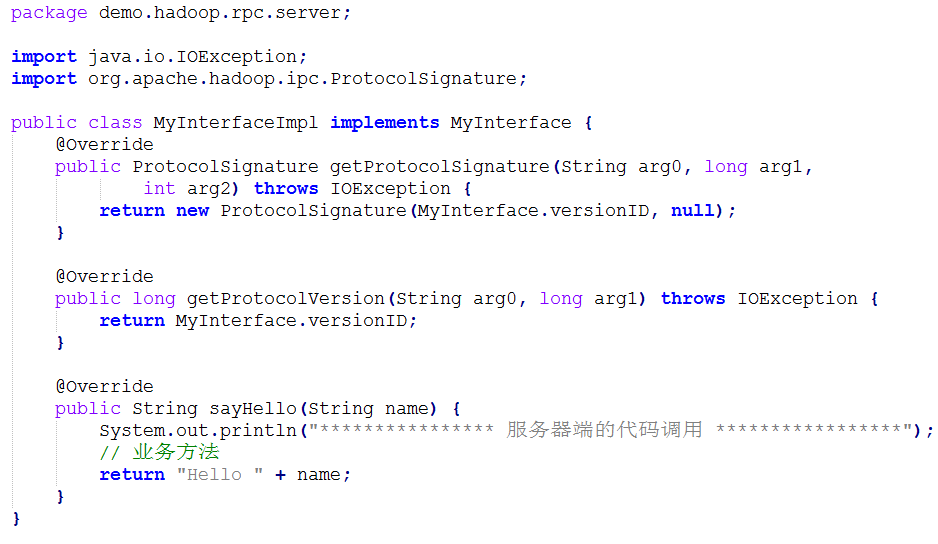

l 客户端

l Java动态代理对象
l 为其他对象提供一种代理以控制对这个对象的访问。
l 核心是使用JDK的Proxy类

七、MapReduce
(一)MapReduce在Yarn平台上 运行过程

(二)第一个MapReduce程序:WordCount
l Mapper的实现

l Reducer的实现
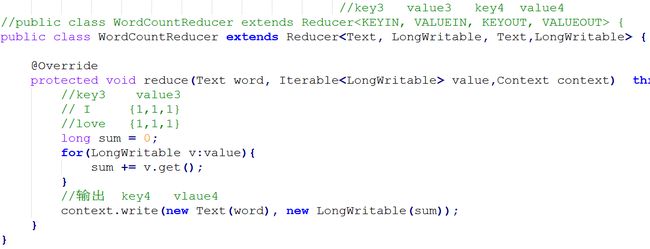
l 主程序的实现

(三)WordCount的数据流过程

(四)使用MapReduce处理数据
emp.csv
① 排序:注意排序按照Key2排序
需要实现WritableComparable接口
SortMapper.java Employee.java SortMain.java
② 分区

EmployeePartition.java EmployeeReduce.java PartitionMain.java Employee.java EmployeeMapper.java
③ 合并:Combiner是一个特殊的Reducer。但不是所有的情况都可以使用Combiner。
(五)Shuffle的过程
(六)使用MRUnit进行单元测试过程
l 使用的时候需要从官网http://mrunit.apache.org/下载jar包
l 基本原理是JUnit和EasyMock,其核心的单元测试依赖于JUnit,并且MRUnit实现了一套Mock对象来控制MapReduce框架的输入和输出;语法也比较简单。
l 注意:需要把mockito-all-1.8.5.jar从Build Path中去掉
l 以WordCount伪列:
n 测试Mapper

n 测试Reducer

n 测试MapReducer

(七)MapReduce作业任务的管理
l 通过Web Console监控作业的运行

l 通过yarn application命令来进行作业管理
① 列出帮助信息:
yarn application --help
② 查看运行Mapreduce程序:
yarn application -list
③ 查看应用状态:
yarn application -status
④ 强制杀死应用:
yarn application –kill
(八)MapReduce案例集锦
l 通过下面六个案例,强化MapReduce程序的开发和理解
n 数据去重
n 数据排序
n 平均成绩
n 单表关联
n 多表关联

n 倒排索引
数据:

结果:
l 数据去重
“数据去重”主要是为了掌握和利用 并行化思想来对数据进行 有意义的 筛选。统计大数据集上的数据种类个数统计大数据集上的数据种类个数、 从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。
1、问题描述
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。
样例输入文件如下所示:
| 文件1: 2012-3-1 a 2012-3-2 b 2012-3-3 c 2012-3-4 d 2012-3-5 a 2012-3-6 b 2012-3-7 c 2012-3-3 c |
文件2: 2012-3-1 b 2012-3-2 a 2012-3-3 b 2012-3-4 d 2012-3-5 a 2012-3-6 c 2012-3-7 d 2012-3-3 c |
样例输出如下所示:
| 结果: 2012-3-1 a 2012-3-1 b 2012-3-2 a 2012-3-2 b 2012-3-3 b 2012-3-3 c 2012-3-4 d 2012-3-5 a 2012-3-6 b 2012-3-6 c 2012-3-7 c 2012-3-7 d |
2、设计思路
数据去重的最终目标是让 原始数据中 出现次数 超过一次的 数据在 输出文件中 只出现一次出现一次。我们自然而然会想到将同一个数据的所有记录都交给台 一台 reduce 机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是 reduce 的 输入应该以 数据作为 key,而对 value-list 则 没有要求。当 reduce 接收到一个
在 MapReduce 流程中, map 的输出
3、程序代码
略:
l 数据排序
“ 数据排序”是许多实际任务执行时要完成的第一项工作,比如 学生成绩评比、数据建立索引数据建立索引等。这个实例和数据去重类似,都是先对原始数据进行 初步处理,为 进一步的数据操作打好基础。
1、问题描述
对输入文件中数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有 两个间隔的数字,其中, 第一个代表原始数据在原始数据集中的位次,第二个代表原始数据。
输入文件:
| 文件1: 2 32 654 32 15 756 65223 |
文件2: 5956 22 650 92 |
文件3: 26 54 6 |
输出文件:
| 输出结果: 1 2 2 6 3 15 4 22 5 26 6 32 7 32 8 54 9 92 10 650 11 654 12 756 13 5956 14 6522 |
2、设计思路
该示例仅仅要求对输入数据进行排序,熟悉 MapReduce 过程的读者会很快想到在MapReduce过程中就有排序,是否可以利用这个 默认的排序,而不需要自己再实现具体的排序呢?答案是肯定的。
但是在使用之前首先需要了解它的 默认排序规则。它是按照 key 值进行排序的,如果key 为封装 int 的 IntWritable 类型,那么 MapReduce 按照 数字大小对 key 排序,如果 key为封装为 String 的 Text 类型,那么 MapReduce 按照 字典顺序对字符串排序。
了解了这个细节,我们就知道应该使用封装 int 的 IntWritable 型数据结构了。也就是在map 中将读入的数据转化成 IntWritable 型,然后作为 key 值输出(value 任意) 。reduce 拿到
l 平均成绩
“平均成绩”主要目的还是在重温经典“WordCount”例子,可以说是在基础上的微变化微变化版,该实例主要就是实现一个计算学生平均成绩的例子。
1. 问题描述
对输入文件中数据进行就算学生平均成绩。 输入文件中的每行内容均为 一个学生的姓名和他相应的 成绩,如果有多门学科,则每门学科为一个文件。要求在输出中每行有两个间隔的数据,其中,第一个代表学生的姓名,第二个代表其平均成绩。
输入文件:
| 数学成绩: Tom 88 Mary 99 Mike 66 Jone 77 |
语文成绩: Tom 78 Mary 89 Mike 96 Jone 67 |
英语成绩: Tom 80 Mary 82 Mike 84 Jone 86 |
输出文件:
| 平均成绩: Tom 82 Mary 90 Mike 82 Jone 76 |
2. 设计思路
计算学生平均成绩是一个仿“WordCount”例子,用来重温一下开发 MapReduce 程序的流程。 程序包括两部分的内容: Map 部分和 Reduce 部分, 分别实现了 map 和 reduce 的功能。
Map处理的是一个纯文本文件,文件中存放的数据时每一行表示一个学生的姓名和他相应一科成绩。Mapper 处理的数据是由 InputFormat 分解过的数据集,其中 InputFormat 的作用是将数据集切割成小数据集 InputSplit,每一个 InputSlit 将由一个 Mapper 负责处理。此外, InputFormat中还提供了一个RecordReader的实现, 并将一个InputSplit解析成
Map 的结果会通过 partion 分发到 Reducer,Reducer 做完 Reduce 操作后,将通过以格式 OutputFormat 输出。
Mapper 最终处理的结果对
l 单表关联
前面的实例都是在数据上进行一些简单的处理,为进一步的操作打基础。 “ 单表关联”这个实例 要求从 给出的数据中 寻找所 关心的数据,它是对 原始数据所包含信息的 挖掘。下面进入这个实例。
1. 问题描述
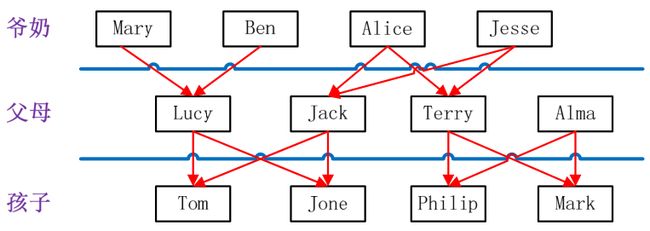
实例中给出 child-parent(孩子——父母)表,要求输出 grandchild-grandparent(孙子——爷奶)表。
样例输入如下所示: 样例输出如下所示:
| child | parent | grandchild | grandparent |
| Tom Tom Jone Jone Lucy Lucy Jack Jack Terry Terry Philip Philip |
Lucy Jack Lucy Jack Mary Ben Alice Jesse Alice Jesse Terry Alma |
Tom Tom Jone Jone Tom Tom Jone Jone Philip Philip Mark Mark |
Alice Jesse Alice Jesse Mary Ben Mary Ben Alice Jesse Alice Jesse |
家族树状关系谱:
2.设计思路
分析这个实例,显然需要进行单表连接,连接的是 左表的 parent 列和 右表的 child 列,且 左表和 右表是 同一个表。
连接结果中 除去连接的两列就是所需要的结果——“grandchild--grandparent”表。要用MapReduce 解决这个实例, 首先应该考虑如何实现 表的 自连接; 其次就是 连接列的 设置;最后是 结果的 整理。
考虑到 MapReduce 的 shuffle 过程会将相同的 key 会连接在一起, 所以可以将 map 结果的 key 设置成 待连接的 列, 然后列中相同的值就自然会连接在一起了。 再与最开始的分析联系起来:
要连接的是左表的 parent 列和右表的 child 列,且左表和右表是同一个表,所以在 map阶段将 读入数据 分割成 child 和 parent 之后,会将 parent 设置成 key,child 设置成 value进行输出,并作为 左表;再将 同一对 child 和 parent 中的 child 设置成 key,parent 设置成value 进行输出,作为 右表。为了 区分输出中的 左右表,需要在输出的 value 中 再加上左右表左右表的 信息,比如在 value 的 String 最开始处加上 字符 1 表示 左表,加上 字符 2 表示 右表。这样在 map 的结果中就形成了左表和右表,然后在 shuffle 过程中完成连接。reduce 接收到连接的结果,其中每个 key 的 value-list 就包含了“grandchild--grandparent”关系。取出每个key 的 value-list 进行解析, 将 左表中的 child 放入一个 数组, 右表中的 parent 放入一个 数组,然后对 两个数组求笛卡尔积就是最后的结果了。
l 多表关联
多表关联和单表关联类似,它也是通过对原始数据进行一定的处理, 从其中挖掘出关心的信息。
1.问题描述
输入是两个文件,一个代表 工厂表,包含 工厂名列和 地址编号列;另一个代表 地址表包 地址名列和 地址编号列。要求从 输入数据中找出 工厂名和 地址名的 对应关系,输出“工厂名——地址名”表。
输入文件:
| 工厂信息: | 地址信息: |
 |
 |
输出文件:

2.设计思路
多表关联和单表关联相似,都类似于 数据库中的 自然连接。相比单表关联,多表关联的左右表和连接列更加清楚。 所以可以采用和 单表关联的 相同的 处理方式, map 识别出输入的行属于哪个表之后,对其进行分割,将 连接的列值保存在 key 中, 另一列和左右表 标识保存在 value 中,然后输出。reduce 拿到连接结果之后,解析 value 内容,根据标志将左右表内容分开存放,然后求 笛卡尔积,最后直接输出。
这个实例的具体分析参考单表关联实例。
l 倒排索引
“ 倒排索引”是 文档检索系统中 最常用的 数据结构,被广泛地应用于 全文搜索引擎。它 主要是用来 存储某个 单词(或词组) 在一个 文档或一组文档中的 存储位置的 映射,即提供了一种 根据内容来查找文档的 方式。 由于不是根据文档来确定文档所包含的内容, 而是进行相反的操作,因而称为倒排索引(Inverted Index) 。
1.问题描述
通常情况下,倒排索引由一个单词(或词组)以及相关的文档列表组成,文档列表中的文档或者是标识文档的 ID 号,或者是指文档所在位置的 URL,如下图所示。

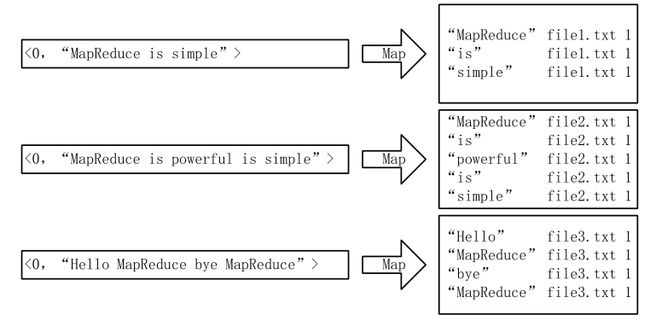
从上图可以看出,单词 1 出现在{文档 1,文档 4,文档 13,……}中,单词 2 出现在{文档 3,文档 5,文档 15,……}中,而单词 3 出现在{文档 1,文档 8,文档 20,……}中。在 实际应用中, 还需要给 每个文档添加一个 权值,用来 指出每个文档与搜索内容的相关度,如下图所示:

最常用的是使用词频作为权重,即记录单词在文档中出现的次数。以英文为例,如下图 所示,索引文件中的“MapReduce”一行表示: “MapReduce”这个单词在文本 T0 中出现过 1 次, T1 中出现过 1 次, T2 中出现过 2 次。 当搜索条件为 “MapReduce” 、 “is” 、 “Simple”时,对应的集合为:{T0,T1,T2}∩{T0,T1}∩{T0,T1}={T0,T1},即文档 T0 和 T1 包含了所要索引的单词,而且只有 T0 是连续的。

更复杂的权重还可能要记录单词在多少个文档中出现过,以实现 TF-IDF(TermFrequency-Inverse Document Frequency)算法,或者考虑单词在文档中的位置信息(单词是否出现在标题中,反映了单词在文档中的重要性)等。
输入文件如下:
| 文件1: MapReduce is simple |
| 文件2: MapReduce is powerful is simple |
| 文件3: Hello MapReduce bye MapReduce |
输出文件如下:

2.设计思路
实现“ 倒排索引”只要关注的信息为: 单词、 文档 URL 及 词频。但是在实现过程中,索引文件的格式与图 6.1-3 会略有所不同,以避免重写 OutPutFormat 类。下面根据 MapReduce 的处理过程给出 倒排索引的 设计思路。
l Mapper的过程
l Combiner的过程

l Reducer的过程
经过上述两个过程后, Reduce 过程只需将相同 key 值的 value 值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给 MapReduce 框架进行处理了。
(十)搭建Hadoop的Eclipse开发环
hadoop-eclipse-plugin-2.4.1.jar

l 设置环境变量:HADOOP_HOME,并把下面的bin目录加入PATH路径中:


l 将hadoop.dll文件复制到C:\Windows\System32目录下
l 修改Hadoop的源码:org.apache.hadoop.io.nativeio.NativeIO

八、Hive
(一)什么是Hive
l 构建在Hadoop上的数据仓库平台,为数据仓库管理提供了许多功能
l 起源自facebook由Jeff Hammerbacher领导的团队
l 2008年facebook把hive项目贡献给Apache
l 定义了一种类SQL语言HiveQL。可以看成是仍SQL到Map-Reduce的映射器
l 提供Hive shell、JDBC/ODBC、Thrift客户端等接
(二)Hive的体系结构
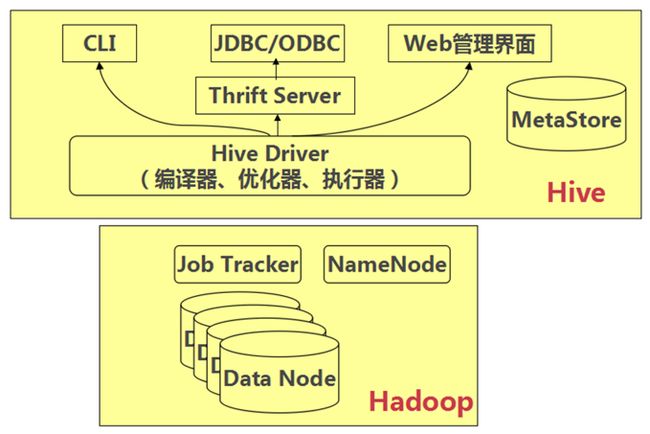
l 用户接口主要有三个:CLI,JDBC/ODBC和 WebUI
n CLI,即Shell命令行
n JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似
n WebGUI是通过浏览器访问 Hive
l Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
l 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行
l Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
(三)Hive的管理
l Hive的安装
n 在虚拟机上安装MySQL:
u yum remove mysql-libs
u rpm -ivh mysql-community-common-5.7.19-1.el7.x86_64.rpm
u rpm -ivh mysql-community-libs-5.7.19-1.el7.x86_64.rpm
u rpm -ivh mysql-community-client-5.7.19-1.el7.x86_64.rpm
u rpm -ivh mysql-community-server-5.7.19-1.el7.x86_64.rpm
u rpm -ivh mysql-community-devel-5.7.19-1.el7.x86_64.rpm (可选)
启动MySQL:service mysqld start
或者:systemctl start mysqld.service
查看root用户的密码:cat /var/log/mysqld.log | grep password
登录后修改密码:alter user 'root'@'localhost' identified by 'Welcome_1';
n MySQL数据库的配置:
u 创建一个新的数据库:create database hive;
u 创建一个新的用户:create user 'hiveowner'@'%' identified by ‘Welcome_1’;
u 给该用户授权
grant all on hive.* TO 'hiveowner'@'%';
grant all on hive.* TO 'hiveowner'@'localhost' identified by 'Welcome_1';
n 嵌入式模式(本地模式)
u 元数据信息存储在内置的Derby数据库中
u 只运行建立一个连接
u 设置Hive的环境变量
u 设置以下参数:
| 参数文件 |
配置参数 |
参考值 |
| hive-site.xml |
javax.jdo.option.ConnectionURL |
jdbc:derby:;databaseName=metastore_db;create=true |
| javax.jdo.option.ConnectionDriverName |
org.apache.derby.jdbc.EmbeddedDriver |
|
| hive.metastore.local |
true |
|
| hive.metastore.warehouse.dir |
file:///root/training/apache-hive-2.3.0-bin/warehouse |
u 初始化MetaStore:
schematool -dbType derby -initSchema
n 远程模式
u 元数据信息存储在远程的MySQL数据库中
u 注意一定要使用高版本的MySQL驱动(5.1.43以上的版本)
mysql-connector-java-5.1.43-bin.jar
| 参数文件 |
配置参数 |
参考值 |
| hive-site.xml |
javax.jdo.option.ConnectionURL |
jdbc:mysql://localhost:3306/hive?useSSL=false |
| javax.jdo.option.ConnectionDriverName |
com.mysql.jdbc.Driver |
|
| javax.jdo.option.ConnectionUserName |
hiveowner |
|
| javax.jdo.option.ConnectionPassword |
Welcome_1 |
u 初始化MetaStore:
schematool -dbType mysql -initSchema
l Hive的管理
n CLI(Command Line Interface)方式
n HWI(Hive Web Interface)方式(只在2.2.0以前的版本才有)
u 安装步骤:
l tar -zxvf apache-hive-0.13.0-src.tar.gz
l jar cvfM0 hive-hwi-0.13.0.war -C web/ .
l 修改hive-site.xml
| 参数文件 |
配置参数 |
参考值 |
| hive-site.xml |
hive.hwi.listen.host |
0.0.0.0 |
| hive.hwi.listen.port |
9999 |
|
| hive.hwi.war.file |
lib/hive-hwi-0.13.0.war |
l 注意:拷贝JDK/lib/tools.jar ----> $HIVE_HOME/lib
u 启动方式:hive --service hwi &
u 用于通过浏览器来访问hive:http://
n 远程服务:端口号10000
u 启动方式:hive --service hiveserver &
(四)Hive的数据类型
l 基本数据类型
n tinyint/smallint/int/bigint:整数类型
n float/double:浮点数类型
n boolean:布尔类型
n string:字符串类型
l 复杂数据类型
n Array:数组类型,由一系列相同数据类型的元素组成
n Map:集合类型,包含key->value键值对,可以通过key来访问元素。
n Struct:结构类型,可以包含不同数据类型的元素。这些元素可以通过”点语法”的方式来得到所需要的元素
l 时间类型
n Date:从Hive0.12.0开始支持
n Timestamp:从Hive0.8.0开始支持
(五)Hive的数据模型
l Hive的数据存储
n 基于HDFS
n 没有专门的数据存储格式
n 存储结构主要包括:数据库、文件、表、视图
n 可以直接加载文本文件(.txt文件)
n 创建表时,指定Hive数据的列分隔符与行分隔符
l 表
n Inner Table(内部表)
u 与数据库中的 Table 在概念上是类似
u 每一个 Table 在 Hive 中都有一个相应的目录存储数据
u 所有的 Table 数据(不包括 External Table)都保存在这个目录中
u 删除表时,元数据与数据都会被删除

n Partition Table (分区表)
u Partition 对应于数据库的 Partition 列的密集索引
u 在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中

u 往分区表中插入数据:

u 在Hive中,通过SQL的执行计划获知分区表提高的效率
n External Table(外部表)
u 指向已经在 HDFS 中存在的数据,可以创建 Partition
u 它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异
u 外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个外部表时,仅删除该链接

n Bucket Table (桶表)
u 桶表是对数据进行哈希取值,然后放到不同文件中存储。
u 需要设置环境变量:set hive.enforce.bucketing = true;

l 视图(View)
n 视图是一种虚表,是一个逻辑概念;可以跨越多张表
n 视图建立在已有表的基础上, 视图赖以建立的这些表称为基表
n 视图可以简化复杂的查询
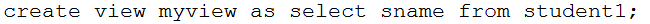
(六)Hive数据的导入
l Hive支持两种方式的数据导入
l 使用load语句导入数据
l 使用sqoop导入关系型数据库中的数据
l 使用load语句导入数据
l 数据文件:

l 导入本地的数据文件

注意:Hive默认分隔符是: tab键。所以需要在建表的时候,指定分隔符。

l 导入HDFS上的数据


l 使用sqoop导入关系型数据库中的数据
n 将关系型数据的表结构复制到hive中
sqoop create-hive-table --connect jdbc:mysql://localhost:3306/test --table username --username root --password 123456 --hive-table test
其中 --table username为mysql中的数据库test中的表 --hive-table test 为hive中新建的表名称
n 从关系数据库导入文件到hive中
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password mysql-password --table t1 --hive-import
n 将hive中的表数据导入到mysql中
sqoop export --connect jdbc:mysql://localhost:3306/test --username root --password admin --table uv_info --export-dir /user/hive/warehouse/uv/dt=2011-08-03
(七)Hive的查询
l 简单查询
l 过滤和排序
l Hive的函数
n 数学函数
u round
u ceil
u floor
n 字符函数
u lower
u upper
u length
u concat
u substr
u trim
u lpad
u rpad
n 收集函数
u size
n 日期函数
u to_date
u year
u month
u day
u weekofyear
u datediff
u date_add
u date_sub
n 条件函数
u if
u coalesce
u case... when...
n 聚合函数
u count
u sum
u min
u max
u avg
l Hive的多表查询
n 只支持:等连接,外连接,左半连接
n 不支持非相等的join条件
n https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Joins
l Hive的子查询
n hive只支持:from和where子句中的子查询
n https://cwiki.apache.org/confluence/display/Hive/LanguageManual+SubQueries
(八)Hive的客户端操作:JDBC
l 首先启动Hive远程服务:hiveserver2 &
l 需要Hive lib目录下的jar包
l 演示案例:查询数据
TestMain.java JDBCUtils.java
l 如果出现以下错误:

修改hadoop 配置文件 etc/hadoop/core-site.xml,加入如下配置项

(十)Hive的自定义函数
l Hive的自定义函数(UDF): User Defined Function
n 可以直接应用于select语句,对查询结构做格式化处理后,再输出内容
l Hive自定义函数的实现细节
n 自定义UDF需要继承org.apache.hadoop.hive.ql.UDF
n 需要实现evaluate函数,evaluate函数支持重载
l Hive自定义函数案例
n 案例一:拼加两个字符串
n 案例二:判断员工表中工资的级别

l Hive自定义函数的部署
n 把程序打包放到目标机器上去
n 进入hive客户端,添加jar包:
hive> add jar /root/temp/udf.jar;
n 创建临时函数:
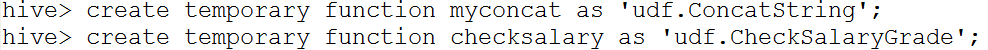
l Hive自定义函数的调用
n 查询HQL语句:
select myconcat(ename,job) from emp;
select ename,sal,checksalary(sal) from emp;
n 销毁临时函数:
hive> DROP TEMPORARY FUNCTION checksalary;
九、Pig
(一)什么是Pig?
l Pig是一个用来处理大规模数据集的平台,由Yahoo!贡献给Apache
l Pig可以简化MapReduce任务的开发
l Pig可以看做hadoop的客户端软件,可以连接到hadoop集群迕行数据分析工作
l Pig方便不熟悉java的用户,使用一种较为简便的类似二SQL的面向数据流的语言pig Latin迕行数据处理
l Pig Latin可以迕行排序、过滤、求和、分组、关联等常用操作,迓可以自定义凼数,返是一种面向数据分析处理的轻量级脚本语言
l Pig可以看做是Pig Latin到MapReduce的映射器
l Pig可以自动对集群迕行分配和回收,幵丏自劢地对MapReduce程序迕行优化
(二)Pig的体系结构

(三)Pig的安装和工作模式
l 安装步骤
n 下载并解压pig安装包( http://pig.apache.org/)
n 设置环境变量
l 工作模式
n 本地模式:pig -x local
n MapReduce模式
u 设置PIG_CLASSPATH环境变量,指向Hadoop的的配置目录
u 启动:pig
l Pig的常用命令
n ls、cd、cat、mkdir、pwd
n copyFromLocal、copyToLocal
n sh
n register、define
(四)Pig的内置函数
l 计算函数
| avg |
计算包中项的平均值 |
| concat |
把两个字节数组或者字符数组连接成一个 |
| count |
计算包中非空值的个数 |
| count_star |
计算包中项的个数,包括空值 |
| diff |
计算两个包的差 |
| max |
计算包中项的最大值 |
| min |
计算包中项的最小值 |
| size |
计算一个类型的大小,数值型的大小为1; 对于字符数组,返回字符的个数; 对于字节数组,返回字节的个数; 对于元组,包,映射,返回其中项的个数。 |
| sum |
计算一个包中项的值的总和 |
| TOKENIZE |
对一个字符数组进行标记解析,并把结果词放入一个包 |
l 过滤函数
| isempty |
判断一个包或映射是否为空 |
l 加载存储函数
| PigStorage |
用字段分隔文本格式加载或存储关系,这是默认的存储函数 |
| BinStorage |
从二进制文件加载一个关系或者把关系存储到二进制文件 |
| BinaryStorage |
从二进制文件加载只是包含一个类型为bytearray的字段的元组到关系,或以这种格式存储一个关系 |
| TextLoader |
从纯文本格式加载一个关系 |
| PigDump |
用元组的tostring()形式存储关系 |
(五)使用Pig Latin语句分析数据
l Pig的数据模型
Bag:表
Tuple:行,记录
Field:属性
Pig不要求同一个bag里面的各个tuple有相同数量或相同类型的field
l 注意:启动historyserver:
mr-jobhistory-daemon.sh start historyserver
可以通过:http://
l 常用的Pig Latin语句
n LOAD:指出载入数据的方法

n FOREACH:逐行扫描进行某种处理
对数据表进行逐行处理是十分重要的功能,因此PIG Latin提供了FOREACH命令。通过一组表达式对数据流中的每一行进行运算,产生的结果就是用于下一个算子的数据集。
下面的语句加载整个数据,但最终结果B中只保留其中的user和id字段:

表达式中可以使用“*”代表全部列,还可以使用“..”表示范围内的列,这对简化命令文本很有用:

n FILTER:过滤行
使用FILTER可以对数据表中的数据进行过滤工作。该关键字经常与 BY 一起联用,对表中对应的特征值进行过滤,例如:

n GROUP分组
按照键值相同的规则归并数据。在SQL中,group操作必然与聚集函数组合使用,而在pig中,group操作将产生与键值有关的bag。

这里的group是默认的变量,表示使用GROUP聚合后得到的数据组,再通过 FOREACH 对每一组数据进行单独处理。

n Distinct 剔除重复项
数据表中若存在重复项,并且需要剔除这些数据,那么可以使用DISTINCT命令,剔除数据表中重复项,该方法与SQL中的用法一致。

n Union 联合
Union 的作用与 SQL 中的 Union 相似,使用该操作符,可以将不同的数据表,组合成同一的数据表。假设我们有数据表A和表B,都记录了行车数据:

n Join 链接

n DUMP:把结果显示到屏幕
n STORE:把结果保存到文件
l WordCount实现
① 加载数据
mydata = load '/data/data.txt' as (line:chararray);
② 将字符串分割成单词
words = foreach mydata generate flatten(TOKENIZE(line)) as word;
③ 对单词进行分组
grpd = group words by word;
④ 统计每组中单词数量
cntd = foreach grpd generate group,COUNT(words);
⑤ 打印结果
dump cntd;
(六)Pig的自定义函数
l 概述
n 支持使用Java、Python、Javascript三种语言编写UDF
n Java自定义函数较为成熟,其它两种功能还有限
n 需要的jar包:
u /root/training/pig-0.14.0/pig-0.14.0-core-h2.jar
u /root/training/pig-0.14.0/lib
u /root/training/pig-0.14.0/lib/h2
u /root/training/hadoop-2.4.1/share/hadoop/common
u /root/training/hadoop-2.4.1/share/hadoop/common/lib
l Pig函数的类型
n 自定义过滤函数
n 自定义运算函数
n 自定义加载函数
l 部署自定义函数
n 注册jar包 register /root/temp/pig.jar
n 为自定义函数起别名:define myfilter demo.pig.MyFilterFunction;
l 自定义过滤函数
n 示例:如果员工工资大于等于3000块钱,则被选择出来。

n 用法:filter emp by demo.pig.IsSalaryTooHigh(sal)
n 也可以创建函数的别名
l 自定义运算函数
n 判断员工薪水是级别
u 如果sal <= 1000,则为:Grade A
u 如果sal > 1000 && sal<=3000,则为:Grade B
u 如果sal > 3000,则为:Grade C
n 参考运行结果


n 用法:emp1 = foreach emp generate ename,demo.pig.CheckSalaryGrade(sal);
l 自定义加载函数
n 默认情况下,一行数据会被解析成一个Tuple
n 比如:员工信息
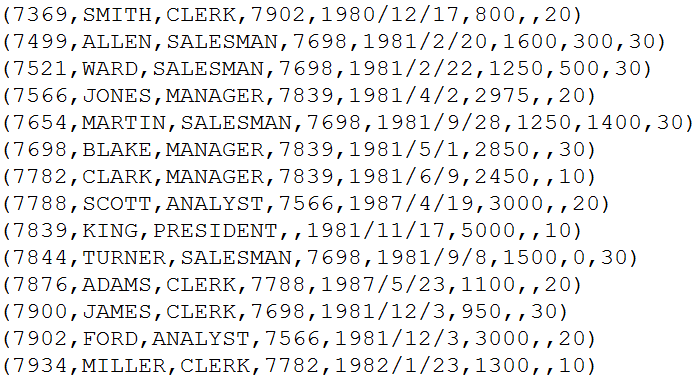
n 特殊情况:单词统计的时候。这时候:希望每个单词能被解析成一个Tuple,从而便于处理

n 需要MapReduce的库(jar文件)
 |
n 运行加载函数:records = load '/input/data.txt' using demo.pig.MyLoadFunction();

十、HBase
(一)什么是HBase?
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
(二)HBase的体系结构
(三)HBase的表结构
(四)HBase的安装和部署
l 本地模式
l 伪分布模式
l 集群模式
本地模式的配置
| 参数文件 |
配置参数 |
参考值 |
| .bash_profile |
HBASE_HOME |
/root/training/hbase-1.3.1 |
| hbase-env.sh |
JAVA_HOME |
/root/training/jdk1.8.0_144 |
| hbase-site.xml |
hbase.rootdir |
file:///root/training/hbase-1.3.1/data |
伪分布模式
| 参数文件 |
配置参数 |
参考值 |
| .bash_profile |
HBASE_HOME |
/root/training/hbase-1.3.1 |
| hbase-env.sh |
JAVA_HOME |
/root/training/jdk1.8.0_144 |
| HBASE_MANAGES_ZK |
true |
|
| hbase-site.xml |
hbase.rootdir |
hdfs://192.168.157.111:9000/hbase |
| hbase.cluster.distributed |
true |
|
| hbase.zookeeper.quorum |
192.168.157.111 |
|
| dfs.replication |
1 |
|
| regionservers |
|
192.168.157.111 |
集群模式
| 参数文件 |
配置参数 |
参考值 |
| .bash_profile |
HBASE_HOME |
/root/training/hbase-1.3.1 |
| hbase-env.sh |
JAVA_HOME |
/root/training/jdk1.8.0_144 |
| HBASE_MANAGES_ZK |
true |
|
| hbase-site.xml |
hbase.rootdir |
hdfs://192.168.157.111:9000/hbase |
| hbase.cluster.distributed |
true |
|
| hbase.zookeeper.quorum |
192.168.157.111 |
|
| dfs.replication |
2 |
|
| hbase.master.maxclockskew |
180000 |
|
| regionservers |
|
192.168.157.113 192.168.157.114 |
注意每台机器的时间,可以使用 date -s 11/22/2016 设置时间
HBase Web Console(端口:16010)
(五)-ROOT-和.META.
n HBase中有两张特殊的Table,-ROOT-和.META.
u -ROOT- :记录了.META.表的Region信息,-ROOT-只有一个region
u .META. :记录了用户创建的表的Region信息,.META.可以有多个regoin
n Zookeeper中记录了-ROOT-表的location
n Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问。
(六)HBase Shell
n HBase提供了一个shell的终端给用户交互

(七)HBase的Java编程接口
l 创建表

l 删除表

l 插入单条数据
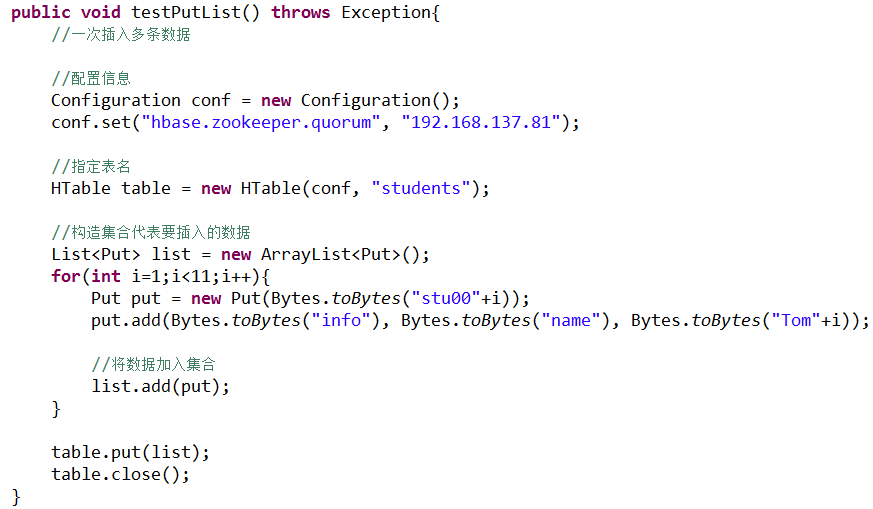
l 插入多条数据
l 查询数据

l 扫描表的数据

(八)HBase上的过滤器
DataInit.java
l 列值过滤器

l 列名前缀过滤器

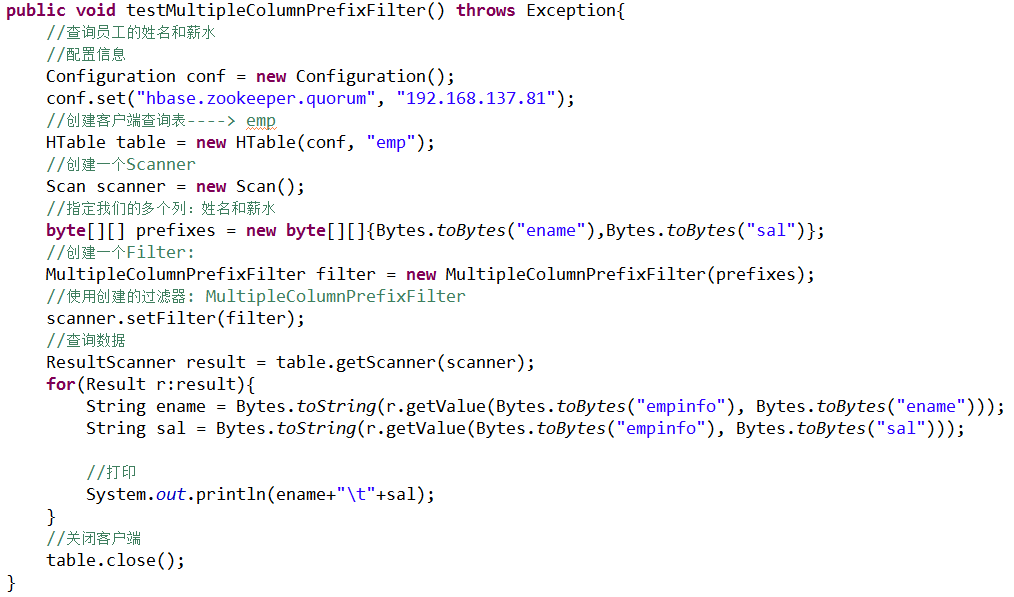
l 多个列名前缀过滤器
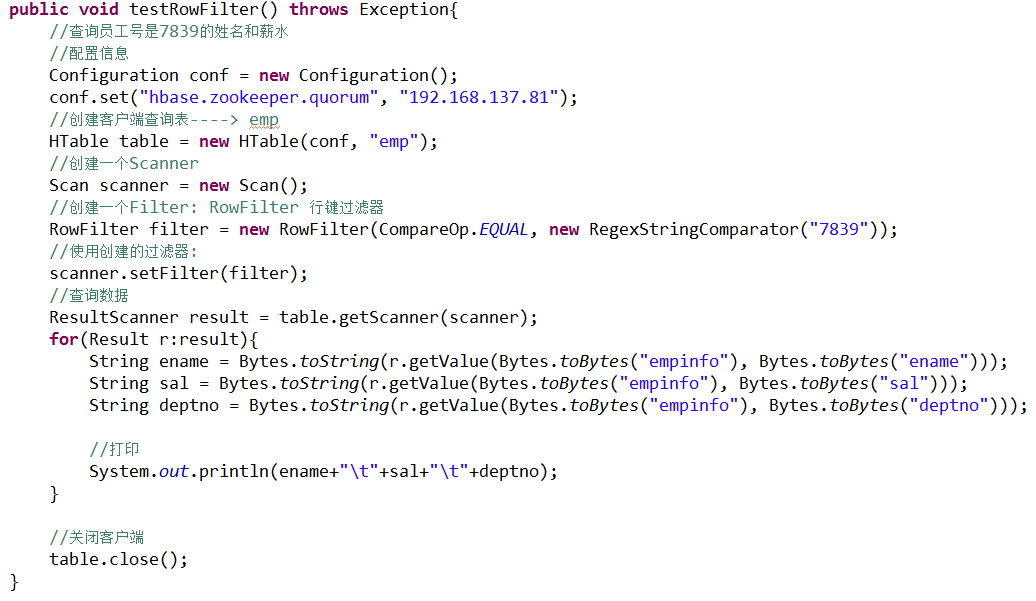
l Rowkey过滤器
l 在查询中使用多个过滤器

(九)HBase上的MapReduce
l 实现WordCount
建立测试数据:
create 'word','content'
put 'word','1','content:info','I love Beijing'
put 'word','2','content:info','I love China'
put 'word','3','content:info','Beijing is the capital of China'
create 'stat','content'
l Mapper

l Reducer

l 主程序
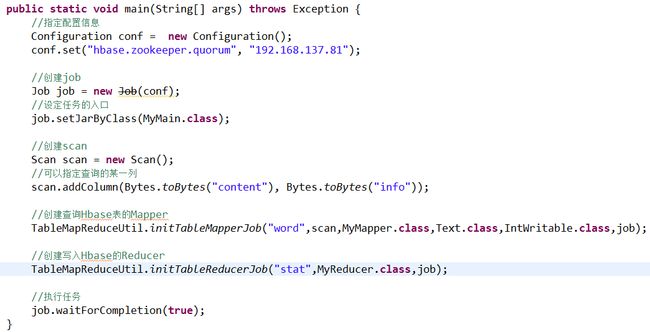
l export HADOOP_CLASSPATH=$HBASE_HOME/lib/*:$CLASSPATH
l 练习:求每个部门的工资总额。
(十)HBase的HA
l 架构

l 配置参数:hbase.zookeeper.quorum
l 单独启动HMaster:hbase-daemon.sh start master
十一、Sqoop
(一)什么是Sqoop?
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
(二)Sqoop是如何工作?
u 利用JDBC连接关系型数据库
u 安装包:sqoop-1.4.5.bin__hadoop-0.23.tar.gz
(三)使用Sqoop
| 命令 |
说明 |
| codegen |
将关系数据库表映射为一个Java文件、Java class类、以及相关的jar包 |
| create-hive-table |
生成与关系数据库表的表结构对应的HIVE表 |
| eval |
以快速地使用SQL语句对关系数据库进行操作,这可以使得在使用import这种工具进行数据导入的时候,可以预先了解相关的SQL语句是否正确,并能将结果显示在控制台。 |
| export |
从hdfs中导数据到关系数据库中 |
| help |
|
| import |
将数据库表的数据导入到HDFS中 |
| import-all-tables |
将数据库中所有的表的数据导入到HDFS中 |
| job |
用来生成一个sqoop的任务,生成后,该任务并不执行,除非使用命令执行该任务。 |
| list-databases |
打印出关系数据库所有的数据库名 |
| list-tables |
打印出关系数据库某一数据库的所有表名 |
| merge |
将HDFS中不同目录下面的数据合在一起,并存放在指定的目录中 |
| metastore |
记录sqoop job的元数据信息 |
| version |
显示sqoop版本信息 |
注意:大小写
实例一:
sqoop codegen --connect jdbc:oracle:thin:@192.168.137.129:1521:orcl --username SCOTT --password tiger --table EMP
也可以写成下面的形式:
sqoop codegen \
--connect jdbc:oracle:thin:@192.168.137.129:1521:orcl \
--username SCOTT --password tiger \
--table EMP
实例二:
sqoop create-hive-table --connect jdbc:oracle:thin:@192.168.137.129:1521:orcl --username SCOTT --password tiger --table EMP --hive-table emphive
实例三:
sqoop eval --connect jdbc:oracle:thin:@192.168.137.129:1521:orcl --username SCOTT --password tiger --query "select ename from emp where deptno=10"
sqoop eval --connect jdbc:oracle:thin:@192.168.137.129:1521:orcl --username SCOTT --password tiger --query "select ename,dname from emp,dept where emp.deptno=dept.deptno"
实例四:
sqoop export --connect jdbc:oracle:thin:@192.168.137.129:1521:orcl --username SCOTT --password tiger --table STUDENTS --export-dir /students
实例五:
sqoop import --connect jdbc:oracle:thin:@192.168.137.129:1521:orcl --username SCOTT --password tiger --table EMP --target-dir /emp
实例六:
sqoop import-all-tables --connect jdbc:oracle:thin:@192.168.137.129:1521:orcl --username SCOTT --password tiger -m 1
实例七:
sqoop list-databases --connect jdbc:oracle:thin:@192.168.137.129:1521:orcl --username SYSTEM --password password
实例八:
sqoop list-tables --connect jdbc:oracle:thin:@192.168.137.129:1521:orcl --username SCOTT --password tiger
实例九:
sqoop version
实例十:将数据导入HBase(需要事先将表创建)
sqoop import --connect jdbc:oracle:thin:@192.168.137.129:1521:orcl --username SCOTT --password tiger --table EMP --columns empno,ename,sal,deptno --hbase-table emp --hbase-row-key empno --column-family empinfo
十二、Flume
(一)什么是Flume?
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
MyDemoWeb.war
(二)Flume的体系结构
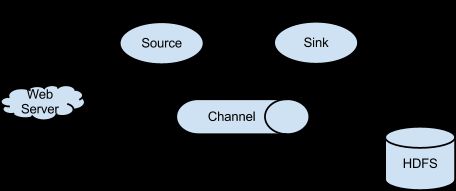
(三)安装和配置Flume
1、解压
2、修改conf/flume-env.sh设置JAVA_HOME即可
(四)使用Flume采集日志数据
案例一:
#bin/flume-ng agent -n a1 -f myagent/a1.conf -c conf -Dflume.root.logger=INFO,console
#定义agent名, source、channel、sink的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#具体定义source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 8888
#具体定义channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#具体定义sink
a1.sinks.k1.type = logger
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
案例二:
#bin/flume-ng agent -n a2 -f myagent/a2.conf -c conf -Dflume.root.logger=INFO,console
#定义agent名, source、channel、sink的名称
a2.sources = r1
a2.channels = c1
a2.sinks = k1
#具体定义source
a2.sources.r1.type = exec
a2.sources.r1.command = tail -f /home/hadoop/a.log
#具体定义channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
#具体定义sink
a2.sinks.k1.type = logger
#组装source、channel、sink
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
案例三:
#bin/flume-ng agent -n a3 -f myagent/a3.conf -c conf -Dflume.root.logger=INFO,console
#定义agent名, source、channel、sink的名称
a3.sources = r1
a3.channels = c1
a3.sinks = k1
#具体定义source
a3.sources.r1.type = spooldir
a3.sources.r1.spoolDir = /root/training/logs1
#具体定义channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
#具体定义sink
a3.sinks.k1.type = logger
#组装source、channel、sink
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
案例四:
#bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
#定义agent名, source、channel、sink的名称
a4.sources = r1
a4.channels = c1
a4.sinks = k1
#具体定义source
a4.sources.r1.type = spooldir
a4.sources.r1.spoolDir = /root/training/logs
#具体定义channel
a4.channels.c1.type = memory
a4.channels.c1.capacity = 10000
a4.channels.c1.transactionCapacity = 100
#定义拦截器,为消息添加时间戳
a4.sources.r1.interceptors = i1
a4.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#具体定义sink
a4.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.path = hdfs://192.168.56.111:9000/flume/%Y%m%d
a4.sinks.k1.hdfs.filePrefix = events-
a4.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a4.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a4.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a4.sinks.k1.hdfs.rollInterval = 60
#组装source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1
十三、HUE
(一)什么是HUE?
Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job等等。

(二)HUE所需要的rpm包
| gcc g++ libxml2-devel libxslt-devel cyrus-sasl-devel cyrus-sasl-gssapi |
python-devel python-setuptools sqlite-devel ant libsasl2-dev libsasl2-modules-gssapi-mit libkrb5-dev |
libtidy-0.99-0 mvn openldap-dev libldap2-dev |
步骤:
l 挂载光盘(rhel-server-7.4-x86_64-dvd.iso):mount /dev/cdrom /mnt
l 创建rpm源文件 vi /etc/yum.repos.d/rhel7.repo
[rhel-yum]
name=rhel7
baseurl=file:///mnt
enabled=1
gpgcheck=0
l 执行下面的语句:
yum install gcc g++ libxml2-devel libxslt-devel cyrus-sasl-devel cyrus-sasl-gssapi mysql-devel python-devel python-setuptools sqlite-devel ant ibsasl2-dev libsasl2-modules-gssapi-mit libkrb5-dev libtidy-0.99-0 mvn openldap-dev libffi-devel gmp-devel openldap-devel
l 安装HUE
n 解压:
u tar -xvf hue-4.0.1.tgz
n 编译安装:注意系统时间
u PREFIX=/root/training/ make install
n 添加用户hue
u adduser hue
u chown -R hue.hue /root/training/hue/
(三)HUE与Hadoop集成
l 编辑Hadoop的配置文件

l 修改hue.ini($HUE_HOME/desktop/conf)参数文件(hue.ini)

l 启动HUE
启动Hadoop相关组件
启动Hue: bin/supervisor (/root/training/hue/build/env)
访问首页:http://192.168.157.111:8888/
(四)HUE与HBase集成
l Hue需要读取Hbase的数据是使用thrift的方式,默认HBase的thrift服务没有开启,所有需要手动额外开启thrift 服务。
thrift service默认使用的是9090端口,使用如下命令查看端口是否被占用
netstat -nl|grep 9090
l 启动HBase thrift service
hbase-daemon.sh start thrift
l 配置HUE
hbase_clusters=(Cluster|192.168.157.11:9090)
hbase_conf_dir=/root/training/hbase-1.3.1/conf
(五)HUE与Hive集成
l 配置HUE
hive_server_host=192.168.157.11
hive_server_port=10000
hive_conf_dir=/root/training/apache-hive-2.3.0-bin/conf
l 启动Hive
hive --service metastore
hiveserver2
(六)HUE的文档
http://cloudera.github.io/hue/docs-4.0.0/manual.html
十四、ZooKeeper
(一)什么是ZooKeeper?
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
(二)ZooKeeper的体系结构

(三)Zookeeper能帮我们做什么?
l Hadoop2.0,使用Zookeeper的事件处理确保整个集群只有一个活跃的NameNode,存储配置信息等.
l HBase,使用Zookeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等.
(四)安装和配置Zookeeper
1、在主节点(hadoop112)上配置ZooKeeper
(*)配置/root/training/zookeeper-3.4.6/conf/zoo.cfg文件
dataDir=/root/training/zookeeper-3.4.6/tmp
server.1=hadoop112:2888:3888
server.2=hadoop113:2888:3888
server.3=hadoop114:2888:3888
(*)在/root/training/zookeeper-3.4.6/tmp目录下创建一个myid的空文件
echo 1 > /root/training/zookeeper-3.4.6/tmp/myid
(*)将配置好的zookeeper拷贝到其他节点,同时修改各自的myid文件
scp -r /root/training/zookeeper-3.4.6/ hadoop113:/root/training
scp -r /root/training/zookeeper-3.4.6/ hadoop114:/root/training
2、启动ZooKeeper和查看ZooKeeper的状态
zkServer.sh start
zkServer.sh status
(五)操作Zookeeper
l 通过ZooKeeper的命令行
n zkCli.sh
n 创建一个节点(数据):create /mydata helloworld
l Demo:ZooKeeper集群间信息的同步。
l Demo:ZooKeeper实现分布式锁。
pom.xml TestDistributedLock.java
十五、Hadoop的集群和HA
(一)HDFS的联盟

l 配置HDFS的联盟
HDFS的Federation(联盟):即 集群中存在多个namenode,每个数据节点需要向不同的Namenode注册
| 参数文件 |
配置参数 |
参考值 |
| hadoop-env.sh |
JAVA_HOME |
/root/training/jdk1.8.0_144 |
| core-site.xml |
hadoop.tmp.dir |
/root/training/hadoop-2.7.3/tmp |
| hdfs-site.xml |
dfs.nameservices |
ns1,ns2 |
| dfs.namenode.rpc-address.ns1 |
192.168.157.12:9000 |
|
| dfs.namenode.http-address.ns1 |
192.168.157.12:50070 |
|
| dfs.namenode.secondaryhttp-address.ns1 |
192.168.157.12:50090 |
|
| dfs.namenode.rpc-address.ns2 |
192.168.157.13:9000 |
|
| dfs.namenode.http-address.ns2 |
192.168.157.13:50070 |
|
| dfs.namenode.secondaryhttp-address.ns2 |
192.168.157.13:50090 |
|
| dfs.replication |
2 |
|
| dfs.permissions |
false |
|
| mapred-site.xml |
mapreduce.framework.name |
yarn |
| yarn-site.xml |
yarn.resourcemanager.hostname |
192.168.157.12 |
| yarn.nodemanager.aux-services |
mapreduce_shuffle |
|
| slaves |
DataNode的地址 |
192.168.157.15 192.168.157.14 |
在每个NameNode上格式化:hdfs namenode -format -clusterId xdl1
l 配置viewFS
修改core-site.xml文件,直接加入以下内容:
三、创建对应的目录:
hadoop fs -mkdir hdfs://192.168.157.12:9000/movie
hadoop fs -mkdir hdfs://192.168.157.13:9000/mp3
四、就可以使用了
hdfs dfs -put a.txt /movie/a.txt
hdfs dfs -cat /movie/a.txt
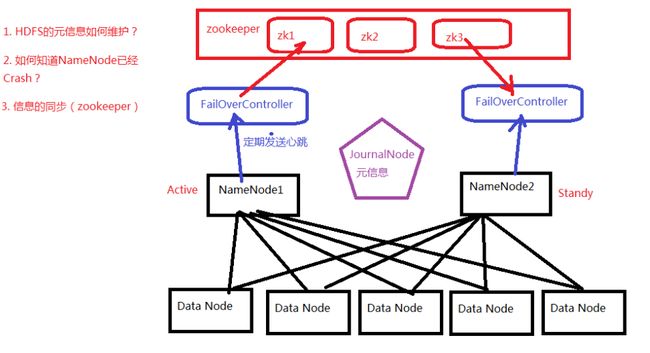
(二)利用ZooKeeper实现Hadoop的HA
实现Hadoop的HA.txt
注意:
bigdata113上的ResourceManager需要单独启动
命令:yarn-daemon.sh start resourcemanager
十六、Storm
(一)什么是Storm?
Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。它还可被用于“分布式RPC”,以并行的方式运行昂贵的运算。
Storm可以方便地在一个计算机集群中编写与扩展复杂的实时计算,Storm用于实时处理,就好比 Hadoop 用于批处理。Storm保证每个消息都会得到处理,而且它很快——在一个小集群中,每秒可以处理数以百万计的消息。更棒的是你可以使用任意编程语言来做开发。
(二)离线计算和流式计算
① 离线计算
l 离线计算:批量获取数据、批量传输数据、周期性批量计算数据、数据展示
l 代表技术:Sqoop批量导入数据、HDFS批量存储数据、MapReduce批量计算、Hive
② 流式计算
l 流式计算:数据实时产生、数据实时传输、数据实时计算、实时展示
l 代表技术:Flume实时获取数据、Kafka/metaq实时数据存储、Storm/JStorm实时数据计算、Redis实时结果缓存、持久化存储(mysql)。
l 一句话总结:将源源不断产生的数据实时收集并实时计算,尽可能快的得到计算结果
③ Storm与Hadoop的区别
| Storm用于实时计算 |
Hadoop用于离线计算 |
| Storm处理的数据保存在内存中,源源不断 |
Hadoop处理的数据保存在文件系统中,一批一批 |
| Storm的数据通过网络传输进来 |
Hadoop的数据保存在磁盘中 |
| Storm与Hadoop的编程模型相似 |
|
(三)Storm的体系结构

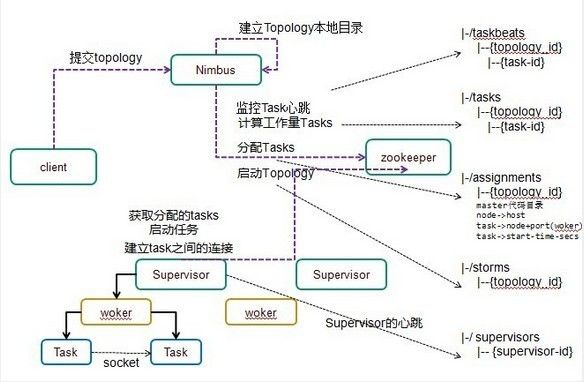
l Nimbus:负责资源分配和任务调度。
l Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。通过配置文件设置当前supervisor上启动多少个worker。
l Worker:运行具体处理组件逻辑的进程。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
l Executor:Storm 0.8之后,Executor为Worker进程中的具体的物理线程,同一个Spout/Bolt的Task可能会共享一个物理线程,一个Executor中只能运行隶属于同一个Spout/Bolt的Task。
l Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。

(四)Storm的运行机制

n 整个处理流程的组织协调不用用户去关心,用户只需要去定义每一个步骤中的具体业务处理逻辑
n 具体执行任务的角色是Worker,Worker执行任务时具体的行为则有我们定义的业务逻辑决定

(五)Storm的安装配置
l 解压:tar -zxvf apache-storm-1.0.3.tar.gz -C ~/training/
l 设置环境变量
l 编辑配置文件:$STORM_HOME/conf/storm.yaml
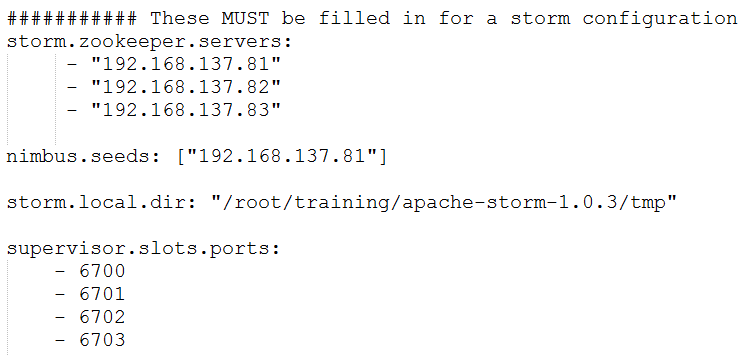
n 注意:如果要搭建Storm的HA,只需要在nimbus.seeds中设置多个nimbus即可。
l 把安装包复制到其他节点上。
(六)启动和查看Storm
l 在nimbus.host所属的机器上启动 nimbus服务和logviewer服务
n storm nimbus &
n storm logviewer &
l 在nimbus.host所属的机器上启动ui服务
n storm ui &
l 在其它个点击上启动supervisor服务和logviewer服务
n storm supervisor &
n storm logviewer &
l 查看storm集群:访问nimbus.host:/8080,即可看到storm的ui界面

(七)Storm的常用命令
有许多简单且有用的命令可以用来管理拓扑,它们可以提交、杀死、禁用、再平衡拓扑。
① 提交任务命令格式:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
![]()
② 杀死任务命令格式:storm kill 【拓扑名称】 -w 10
(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
③ 停用任务命令格式:storm deactivte 【拓扑名称】
storm deactivte topology-name
④ 启用任务命令格式:storm activate【拓扑名称】
storm activate topology-name
⑤ 重新部署任务命令格式:storm rebalance 【拓扑名称】
storm rebalance topology-name
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重分配工人,并重启拓扑。
(八)Demo演示:WordCount及流程分析
通过查看Storm UI上每个组件的events链接,可以查看Storm的每个组件(spout、blot)发送的消息。但Storm的event logger的功能默认是禁用的,需要在配置文件中设置:topology.eventlogger.executors: 1,具体说明如下:
l "topology.eventlogger.executors": 0 默认,禁用
l "topology.eventlogger.executors": 1 一个topology分配一个Event Logger.
l "topology.eventlogger.executors": nil 每个worker.分配一个Event Logger

WordCount的数据流程分析

(九)Storm的编程模型
l Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
l Spout:在一个topology中获取源数据流的组件。
n 通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
l Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
l Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。
l Stream:表示数据的流向。
l StreamGroup:数据分组策略
n Shuffle Grouping :随机分组,尽量均匀分布到下游Bolt中
n Fields Grouping :按字段分组,按数据中field值进行分组;相同field值的Tuple被发送到相同的Task
n All grouping :广播
n Global grouping :全局分组,Tuple被分配到一个Bolt中的一个Task,实现事务性的Topology。
n None grouping :不分组
n Direct grouping :直接分组 指定分组
(十)Storm编程案例:WordCount
流式计算一般架构图:

l Flume用来获取数据。
l Kafka用来临时保存数据。
l Strom用来计算数据。
l Redis是个内存数据库,用来保存数据。
n 创建Spout(WordCountSpout)组件采集数据,作为整个Topology的数据源

n 创建Bolt(WordCountSplitBolt)组件进行分词操作
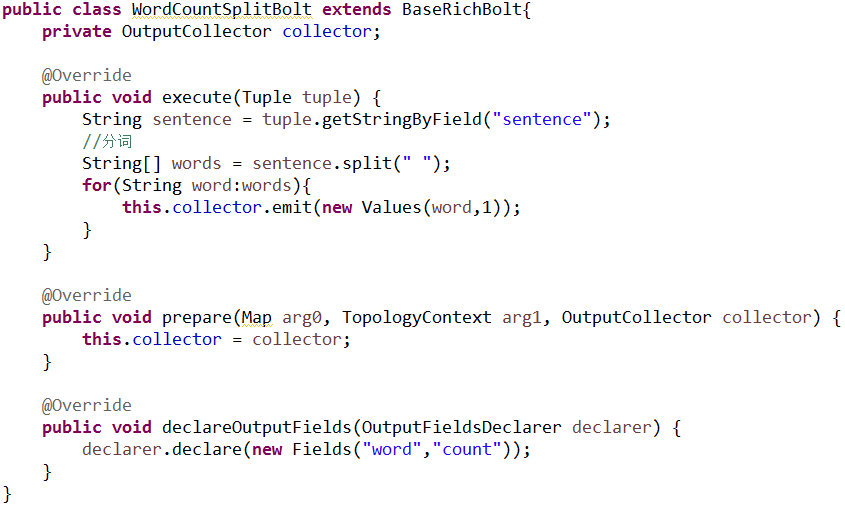
n 创建Bolt(WordCountBoltCount)组件进行单词计数作

n 创建主程序Topology(WordCountTopology),并提交到本地运行

n 也可以将主程序Topology(WordCountTopology)提交到Storm集群运行

(十一)Storm集群在ZK上保存的数据结构

(十二)Storm集群任务提交流程

(十三)Storm内部通信机制


(十四)集成Storm
(1)与JDBC集成
l 将Storm Bolt处理的结果插入MySQL数据库中
l 需要依赖的jar包
n $STORM_HOME\external\sql\storm-sql-core\*.jar
n $STORM_HOME\external\storm-jdbc\storm-jdbc-1.0.3.jar
n mysql的驱动
n commons-lang3-3.1.jar
mysql-connector-java-5.1.7-bin.jar commons-lang3-3.1.jar
l 与JDBC集成的代码实现
n 修改主程序WordCountTopology,增加如下代码:

增加一个新方法创建JDBCBolt组件

n 实现ConnectionProvider接口

n 修改WordCountBoltCount组件,将统计后的结果发送给下一个组件写入MySQL
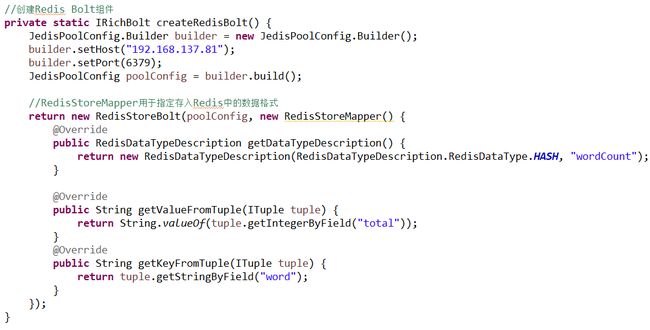
(2)与Redis集成
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。与Memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。Redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。[1]
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。
集成redis的jar包.zip
l 修改代码:WordCountTopology.java

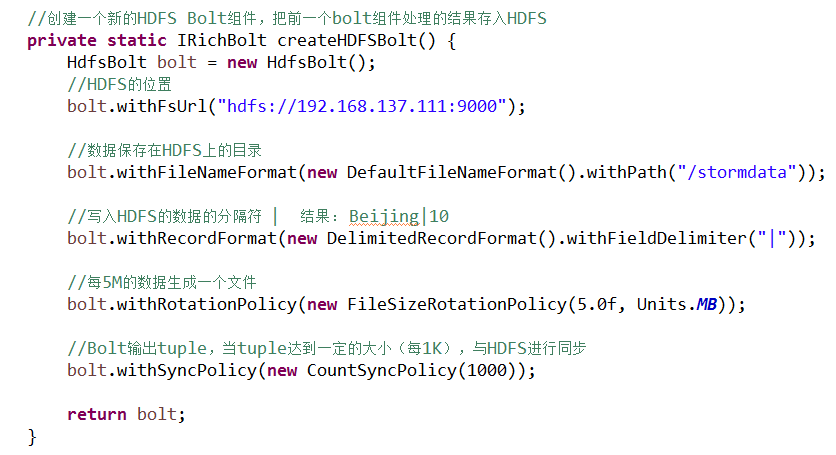
(3)与HDFS集成
u 需要的jar包:
l $STORM_HOME\external\storm-hdfs\storm-hdfs-1.0.3.jar
l HDFS相关的jar包
u 开发新的bolt组件
(4)与HBase集成
u 需要的jar包:HBase的相关包
u 开发新的bolt组件(WordCountBoltHBase.java)



(5)与Apache Kafka集成
l 注意:需要把slf4j-log4j12-1.6.4.jar包去掉,有冲突(有两个)

(6)与Hive集成
u 由于集成Storm和Hive依赖的jar较多,并且冲突的jar包很多,强烈建议使用Maven来搭建新的工程。
u 需要对Hive做一定的配置(在hive-site.xml文件中):
u 需要使用下面的语句在hive中创建表:
create table wordcount
(word string,total int)
clustered by (word) into 10 buckets
stored as orc TBLPROPERTIES('transactional'='true');
u 启动metastore服务:hive --service metastore
u 开发新的bolt组件,用于将前一个bolt处理的结果写入Hive

u 为了测试的方便,我们依然采用之前随机产生字符串的Spout组件产生数据
(7)与JMS集成
JMS即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。Java消息服务是一个与具体平台无关的API,绝大多数MOM提供商都对JMS提供支持。
JMS的两种消息类型:Queue和Topic
基于Weblogic的JMS架构:


WordCountTopology.java
l 需要的weblogic的jar包
wljmsclient.jar wlclient.jar
l permission javax.management.MBeanTrustPermission "register";