(3)Flink学习- Table API & SQL编程
目录
1、概念
2、依赖结构
3、pom.xml
4、java-demo2(单输入、单输出)
5、java-demo3(多输入、多输出、Join)
1、概念
Flink提供不同级别的抽象来开发流/批处理应用程序。
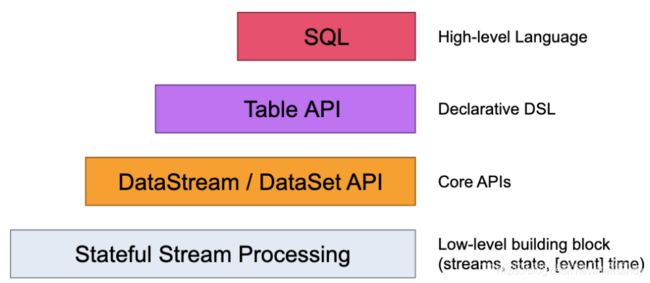
模型类比:
MapReduce ==> Hive SQL
Spark ==> Spark SQL
Flink ==> SQL
2、依赖结构
所有Table API和SQL组件都捆绑在flink-table Maven工件中。
以下依赖项与大多数项目相关:
flink-table-common
通过自定义函数,格式等扩展表生态系统的通用模块。flink-table-api-java
使用Java编程语言的纯表程序的表和SQL API(在早期开发阶段,不推荐!)。flink-table-api-scala
使用Scala编程语言的纯表程序的表和SQL API(在早期开发阶段,不推荐!)。
flink-table-api-java-bridge
使用Java编程语言支持DataStream / DataSet API的Table&SQL API。
flink-table-api-scala-bridge
使用Scala编程语言支持DataStream / DataSet API的Table&SQL API。
flink-table-planner
表程序规划器和运行时。
flink-table-uber
将上述模块打包成大多数Table&SQL API用例的发行版。 uber JAR文件flink-table * .jar位于Flink版本的/ opt目录中,如果需要可以移动到/ lib。
3、pom.xml
4.0.0
com.steven
flink
0.0.1-SNAPSHOT
flink
Demo project for Spring Boot
1.8
org.apache.flink
flink-java
1.9.1
org.apache.flink
flink-streaming-java_2.11
1.9.1
org.apache.flink
flink-table-api-java-bridge_2.11
1.9.1
org.apache.flink
flink-table-planner_2.11
1.9.1
org.projectlombok
lombok
1.16.18
org.springframework.boot
spring-boot-maven-plugin
org.apache.maven.plugins
maven-compiler-plugin
8
8
4、java-demo2(单输入、单输出)
package com.steven.flink;
import lombok.Data;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.BatchTableEnvironment;
import org.apache.flink.table.sinks.CsvTableSink;
import org.apache.flink.table.sinks.TableSink;
/**
* @Description: csv to csv
* @author: : Steven
* @Date: 2020/3/24 20:01
*/
public class Demo2 {
public static void main(String[] args) throws Exception {
//1、获取执行环境 ExecutionEnvironment (批处理用这个对象)
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment bTableEnv = BatchTableEnvironment.create(env);
// DataSet input = env.fromElements(
// WC.of("hello", 1),
// WC.of("hqs", 1),
// WC.of("world", 1),
// WC.of("hello", 1)
// );
//注册数据集
// tEnv.registerDataSet("WordCount", input, "word, frequency");
//2、加载数据源到 DataSet
DataSet csv = env.readCsvFile("D:\\test.csv").ignoreFirstLine().pojoType(Student.class, "name", "age");
//3、将DataSet装换为Table
Table students = bTableEnv.fromDataSet(csv);
bTableEnv.registerTable("student", students);
//4、注册student表
Table result = bTableEnv.sqlQuery("select name,age from student");
DataSet dset = bTableEnv.toDataSet(result, Student.class);
dset.print();
//5、sink输出
CsvTableSink sink1 = new CsvTableSink("D:\\result.csv", "|", 1, FileSystem.WriteMode.OVERWRITE);
String[] fieldNames = {"name", "age"};
TypeInformation[] fieldTypes = {Types.STRING, Types.INT};
bTableEnv.registerTableSink("CsvOutPutTable", fieldNames, fieldTypes, sink1);
result.insertInto("CsvOutPutTable");
env.execute("SQL-Batch");
}
@Data
public static class Student {
private String name;
private int age;
}
}
5、java-demo3(多输入、多输出、Join)
本例实现多输入+多输出+join
package com.steven.flink;
import lombok.Data;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.BatchTableEnvironment;
import org.apache.flink.table.sinks.CsvTableSink;
/**
* @Description: 多输入+多输出+ join
* @author: : Steven
* @Date: 2020/3/24 20:01
*/
public class Demo3 {
public static void main(String[] args) throws Exception {
//1、获取执行环境 ExecutionEnvironment (批处理用这个对象)
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment bTableEnv = BatchTableEnvironment.create(env);
//2、加载数据源到 DataSet
DataSet student = env.readCsvFile("D:\\test.csv").ignoreFirstLine().pojoType(Student.class, "name", "age");
DataSource age = env.readCsvFile("D:\\test2.csv").ignoreFirstLine().pojoType(Age.class, "name", "sex");
//3、将DataSet装换为Table
Table students = bTableEnv.fromDataSet(student);
bTableEnv.registerTable("student", students);
Table ages = bTableEnv.fromDataSet(age);
bTableEnv.registerTable("age", ages);
//4、注册student表
Table result = bTableEnv.sqlQuery("select a.name,age,sex from student a left join age b on a.name=b.name");
result.printSchema();
DataSet dset = bTableEnv.toDataSet(result, Result.class);
dset.print();
// //5、sink 多输出
CsvTableSink sink1 = new CsvTableSink("D:\\result.csv", "|", 1, FileSystem.WriteMode.OVERWRITE);
//“,”分隔符能实现csv的自动分栏,而"|" 则都在一直字段里
CsvTableSink sink2 = new CsvTableSink("D:\\result2.csv", ",", 1, FileSystem.WriteMode.OVERWRITE);
String[] fieldNames = {"name", "age", "sex"};
TypeInformation[] fieldTypes = {Types.STRING, Types.INT, Types.STRING};
bTableEnv.registerTableSink("output1", fieldNames, fieldTypes, sink1);
bTableEnv.registerTableSink("output2", fieldNames, fieldTypes, sink2);
result.insertInto("output1");
result.insertInto("output2");
env.execute("SQL-Batch");
}
@Data
public static class Student {
private String name;
private int age;
}
@Data
public static class Age {
private String name;
private String sex;
}
@Data
public static class Result {
private String name;
private int age;
private String sex;
}
}