Golang 基本数据类型,常量,数组,切片,字符串
整数
int8、int16、int32、int64
uint8、uint16、uint32、uint64
int、uint (不同的编译器即使在相同的硬件平台上可能产生不同的大小)
uintptr 无符号的整数类型。指针大小
优先级递减
* / % << >> & &^
+ - | ^
== != < <= > >=
&&
||
bit位操作运算符
Printf函数的%b参数打印二进制格式的数字
& 位运算 AND
| 位运算 OR
^ 位运算 XOR
&^ 位清空 (AND NOT) 先非再与
<< 左移
>> 右移
Printf打印
%之后的[1]副词告诉Printf函数再次使用第一个操作数。
%后的#副词告诉Printf在用%o、%x或%X输出时生成0、0x或0X前缀。
package main
import "fmt"
func main() {
o := 0666
fmt.Printf("%d %[1]o %#[1]o \n", o)
x := int64(0xdeadbeef)
fmt.Printf("%d %[1]x %#[1]x %#[1]X \n", x)
}

浮点数
float32和float64
Printf打印
Printf函数的%g参数打印浮点数,将采用更紧凑的表示形式打印,并提供足够的精度,但是对应表格的数据,使用%e(带指数)或%f的形式打印可能更合适
复数
complex64和complex128
var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // "(-5+10i)"
fmt.Println(real(x*y)) // "-5"
fmt.Println(imag(x*y)) // "10"
x := 1 + 2i
y := 3 + 4i
布尔
bool
%t
func main() {
var a bool = false;
fmt.Println(a)
fmt.Printf("%d", a)
}

布尔值并不会隐式转换为数字值0或1
字符串
底层为[]byte
\uFFFD 无效字符
fmt.Println(string(1234567)) // "�"
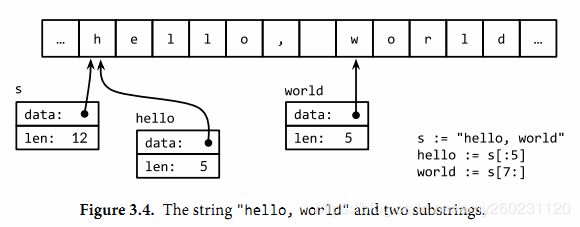
package main
import "fmt"
func main() {
s := "hello, world"
// len 长度
fmt.Println(len(s)) // 12
fmt.Println(s[0], s[7]) // 104 119
fmt.Printf("%c, %c\n", s[0], s[7])
// 越界导致panic异常
// c := s[len(s)] // wpanic: runtime error: index out of range
// fmt.Println(c)
// 生成一段新的字符 子字符串操作s[i:j]
fmt.Println(s[:5]) // "hello"
fmt.Println(s[7:]) // "world"
fmt.Println(s[:]) // "hello, world"
// 无法单个修改
// s[0] = 'c' // cannot assign to s[0]
// range循环在处理字符串的时候,会自动隐式解码UTF8字符串
for i, r := range "Hello, 世界" {
fmt.Printf("%d\t%q\t%d\n", i, r, r)
}
}
byte rune
byte 的操作单位是一个字节,可以理解为一个英文字符
rune 的操作单位是一个字符,不管这个字符是什么字符
type rune = uint32
type byte = uint8
golang中string底层是通过byte数组实现的。中文字符在unicode下占2个字节,在utf-8编码下占3个字节,而golang默认编码正好是utf-8。
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
var str = "hello, 世界"
// 计算的是底层byte数组的字节数
fmt.Println("len(str):", len(str)) // 13
// 获取到str的字符串长度:
// 通过 utf8.RuneCountInString获取实际字符串
fmt.Println("RuneCountInString:", utf8.RuneCountInString(str)) // 9
// 通过包装城rune类型数组
fmt.Println("rune:", len([]rune(str))) // 9
// 如何处理真实字符:
// 1. UTF8解码器
for i := 0; i < len(str); {
// 返回字符和采用UTF8编码后的编码字节数目
r, size := utf8.DecodeRuneInString(str[i:])
fmt.Printf("%d\t%c, size=%d\n", i, r, size)
i += size
}
fmt.Println(".....................")
// 2.range循环会自动隐式解码UTF8字符串
for index, r := range str {
fmt.Printf("%d\t%c\n", index, r)
}
fmt.Println(".....................")
// 因为2,可以直接统计字符串数
n := 0
for range str {
n++
}
fmt.Println("size = ", n) // size = 9
}


bytes、strings、strconv和unicode包 处理字符串
参考
strings包提供了许多如字符串的查询、替换、比较、截断、拆分和合并等功能。
bytes包也提供了很多类似功能的函数,但是针对和字符串有着相同结构的[]byte类型。因为字符串是只读的,因此逐步构建字符串会导致很多分配和复制。在这种情况下,使用bytes.Buffer类型将会更有效,稍后我们将展示。
strconv包提供了布尔型、整型数、浮点数和对应字符串的相互转换,还提供了双引号转义相关的转换。
unicode包提供了IsDigit、IsLetter、IsUpper和IsLower等类似功能,它们用于给字符分类。每个函数有一个单一的rune类型的参数,然后返回一个布尔值。而像ToUpper和ToLower之类的转换函数将用于rune字符的大小写转换。所有的这些函数都是遵循Unicode标准定义的字母、数字等分类规范。strings包也有类似的函数,它们是ToUpper和ToLower,将原始字符串的每个字符都做相应的转换,然后返回新的字符串。
strings:
HasPrefix 判断字符串 s 是否以 prefix 开头:
strings.HasPrefix(s, prefix string) bool
HasSuffix 判断字符串 s 是否以 suffix 结尾:
strings.HasSuffix(s, suffix string) bool
Contains 判断字符串 s 是否包含 substr:
strings.Contains(s, substr string) bool
Index 返回字符串 str 在字符串 s 中的索引(str 的第一个字符的索引),-1 表示字符串 s 不包含字符串 str:
strings.Index(s, str string) int
LastIndex 返回字符串 str 在字符串 s 中最后出现位置的索引(str 的第一个字符的索引),-1 表示字符串 s 不包含字符串 str:
strings.LastIndex(s, str string) int
如果需要查询非 ASCII 编码的字符在父字符串中的位置,建议使用以下函数来对字符进行定位:
strings.IndexRune(s string, r rune) int
Replace 用于将字符串 str 中的前 n 个字符串 old 替换为字符串 new,并返回一个新的字符串,如果 n = -1 则替换所有字符串 old 为字符串 new:
strings.Replace(str, old, new, n) string
Count 用于计算字符串 str 在字符串 s 中出现的非重叠次数:
strings.Count(s, str string) int
Repeat 用于重复 count 次字符串 s 并返回一个新的字符串:
strings.Repeat(s, count int) string
ToLower 将字符串中的 Unicode 字符全部转换为相应的小写字符:
strings.ToLower(s) string
ToUpper 将字符串中的 Unicode 字符全部转换为相应的大写字符:
strings.ToUpper(s) string
TrimSpace 用于修剪字符串,剔除字符串开头和结尾的空白符号
strings.TrimSpace(s)
将开头和结尾的 str 去除掉
strings.Trim(s, str string)
将会利用 1 个或多个空白符号来作为动态长度的分隔符将字符串分割成若干小块,并返回一个 slice,如果字符串只包含空白符号,则返回一个长度为 0 的 slice。
strings.Fields(s)
用于自定义分割符号来对指定字符串进行分割,同样返回 slice。
strings.Split(s, sep)
Join 用于将元素类型为 string 的 slice 使用分割符号来拼接组成一个字符串:
strings.Join(sl []string, sep string) string
函数 strings.NewReader(str) 用于生成一个 Reader 并读取字符串中的内容,然后返回指向该 Reader 的指针,从其它类型读取内容的函数还有:
Read() 从 []byte 中读取内容。
ReadByte() 和 ReadRune() 从字符串中读取下一个 byte 或者 rune。
bytes:
bytes 包和字符串包十分类似(参见第 4.7 节)。而且它还包含一个十分有用的类型 Buffer:(类似于 Java 的 StringBuilder 类)
import "bytes"
type Buffer struct {
...
}
Buffer 可以这样定义:var buffer bytes.Buffer。
或者使用 new 获得一个指针:var r *bytes.Buffer = new(bytes.Buffer)。
或者通过函数:func NewBuffer(buf []byte) *Buffer,创建一个 Buffer 对象并且用 buf 初始化好;NewBuffer 最好用在从 buf 读取的时候使用。
package main
import (
"fmt"
"os"
"bytes"
)
func main() {
var buffer bytes.Buffer
for _, str := range os.Args[1:] {
buffer.WriteString(str) // 将字符串 s 追加到后面
}
fmt.Println(buffer.String()) // 转换为 string
}

unicode:
包 包含了一些针对测试字符的非常有用的函数(其中 ch 代表字符):
判断是否为字母:unicode.IsLetter(ch)
判断是否为数字:unicode.IsDigit(ch)
判断是否为空白符号:unicode.IsSpace(ch)
常量
普通常量
const pi = 3.14159 // approximately; math.Pi is a better approximation
const (
e = 2.71828182845904523536028747135266249775724709369995957496696763
pi = 3.14159265358979323846264338327950288419716939937510582097494459
)
// 一个常量的声明也可以包含一个类型和一个值
const noDelay time.Duration = 0 // type Duration int64
const timeout = 5 * time.Minute // time.Minute : Duration类型常量
fmt.Printf("%T %[1]v\n", noDelay) // "time.Duration 0"
fmt.Printf("%T %[1]v\n", timeout) // "time.Duration 5m0s"
fmt.Printf("%T %[1]v\n", time.Minute) // "time.Duration 1m0s"
类似枚举
const (
a = 1
b
c = 2
d
)
fmt.Println(a, b, c, d) // "1 1 2 2"
iota 常量生成器
const iota = 0 // Untyped int.
type Flags uint
const (
FlagUp Flags = 1 << iota // 0000 0001 iota = 0
FlagBroadcast // 0000 0010 iota = 1
FlagLoopback // 0000 0100 iota = 2
FlagPointToPoint // 0000 1000 iota = 3
FlagMulticast // 0001 0000 iota = 4
)
const (
// 把1左移10*iota次,即1 * 2的10*iota次方
_ = 1 << (10 * iota)
KiB // 1024 1 << 10
MiB // 1048576 1 << 20
GiB // 1073741824 1 << 40
TiB // 1099511627776 (exceeds 1 << 32)
PiB // 1125899906842624
EiB // 1152921504606846976
ZiB // 1180591620717411303424 (exceeds 1 << 64)
YiB // 1208925819614629174706176
)
无类型常量
许多常量并没有一个明确的基础类型。编译器为这些没有明确的基础类型的数字常量提供比基础类型更高精度的算术运算
无类型的布尔型、无类型的整数、无类型的字符、无类型的浮点数、无类型的复数、无类型的字符串。
只有常量可以是无类型的。当一个无类型的常量被赋值给一个变量的时候,无类型的常量将会被隐式转换为对应的类型
var f float64 = 3 + 0i // untyped complex -> float64
f = 2 // untyped integer -> float64
f = 1e123 // untyped floating-point -> float64
f = 'a' // untyped rune -> float64
``
对于一个没有显式类型的变量声明(包括简短变量声明),常量的形式将隐式决定变量的默认类型,
```go
i := 0 // untyped integer; implicit int(0)
r := '\000' // untyped rune; implicit rune('\000')
f := 0.0 // untyped floating-point; implicit float64(0.0)
c := 0i // untyped complex; implicit complex128(0i)
数组(与C数组不同)
数组是一种 值类型
package main
import "fmt"
type Currency int
const (
USD Currency = iota // 美元
EUR // 欧元
GBP // 英镑
RMB // 人民币
)
func main() {
// 声明和初始化
// 1. 【】里写数字的
var a [3]int // 0, 0, 0
var b [3]int = [3]int{1, 2, 3} // 1, 2, 3
var c [3]int = [3]int{1, 2} // 1, 2, 0
// 2. [...]
q := [...]int{1, 2, 3, 4} // 1, 2, 3, 4 [...]长度根据初始化值来计算
p := [...]int{5: -1} // 0, 0, 0, 0, -1
// 3.key: value 语法
symbol := [...]string{USD: "$", EUR: "€", GBP: "£", RMB: "¥"}
fmt.Println(RMB, symbol[RMB]) // "3 ¥"
var arrKeyValue = [5]string{3: "Chris", 4: "Ron"} // 只有索引3,4呗赋值
// 遍历数组
fmt.Println("a:")
for index, value := range a {
fmt.Printf("%d, %d\n", index, value)
}
}
将数组传递给函数
把一个大数组传递给函数会消耗很多内存。有两种方法可以避免这种现象:
- 传递数组的指针
package main
import "fmt"
func main() {
array := [3]float64{7.0, 8.5, 9.1}
x := Sum(&array) // Note the explicit address-of operator
// to pass a pointer to the array
fmt.Printf("The sum of the array is: %f", x)
}
func Sum(a *[3]float64) (sum float64) {
for _, v := range a { // derefencing *a to get back to the array is not necessary!
sum += v
}
return
}
- 使用数组的切片(常用)
func sum(a []int) int {
s := 0
for i := 0; i < len(a); i++ {
s += a[i]
}
return s
}
func main() {
var arr = [5]int{0, 1, 2, 3, 4}
sum(arr[:]) // 创建一个切片引用
}
slice 切片 变长数组
切片是一种 引用类型,指针指向一个数组
- 数组和切片的区别:语法上[]中是否有数组,是否可以使用append
- 底层为数组对象,一个slice由指针、长度、容量构成
指针只向第一个slice元素对应的底层数组元素的地址(不一定是数组第一个)
长度对应slice中元素的数目(len)
容量一般是从slice的开始位置到底层数据的结尾位置(cap) - 多个slice之间可以共享底层的数据,并且引用的数组部分区间可能重叠
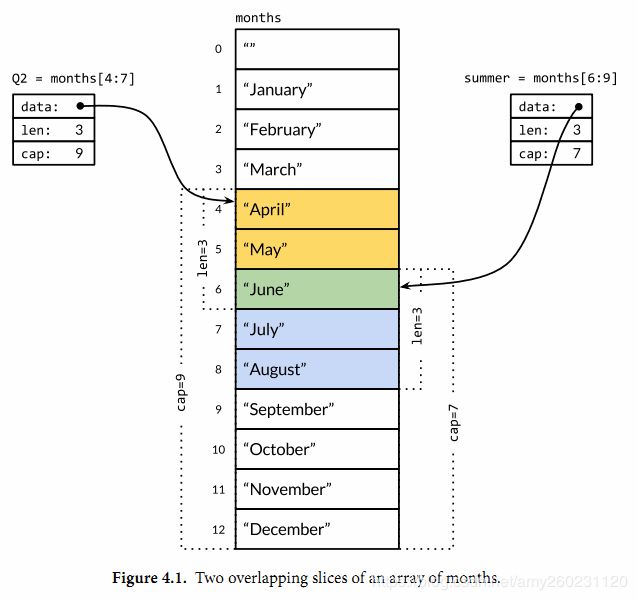
package main
import "fmt"
func main() {
// 1. 声明和初始化
months := [...]string{1: "Jan", 2: "Feb", 3: "Mar", 4: "Apr", 5: "May"}
// 通过数组初始化切片,左闭右开
allMonths := months[:]
spring := months[3:6]
temp := months[1:2:4] // start = 1 ,len: 1~2,end = 4
fmt.Println(spring) // [Mar Apr May]
// 2. 用内置函数make创建slice
// make([]T, len)
// make([]T, len, cap) // same as make([]T, cap)[:len]
slice1 := make([]int, 5)
slice2 := make([]int, 5, 10) // 相当于 new([10]int)[0:5]
fmt.Println(slice1, len(slice1), cap(slice1)) // [0 0 0 0 0] 5 5
fmt.Println(slice2, len(slice1), cap(slice2)) // [0 0 0 0 0] 5 10
// 3. 可修改,说明底层数据共享,spring是数组指针
months[5] = "aaaaa"
fmt.Println(spring) // [Mar Apr aaaaa]
fmt.Println(cap(months)) // 容量 6
fmt.Println(len(months)) // 大小 6
// 4. eg 反转切片
a := [...]int{0, 1, 2, 3, 4, 5}
reverse(a[:])
fmt.Println(a) // "[5 4 3 2 1 0]"
// 5. slice之间不能比较
// 两个字节型slice是否相等([]byte)可以通过库函数bytes.Equal
// 其他类型必须自己展开对每个元素进行比较
p := [...]string{1: "a", 2: "b", 3: "c"}
q := [...]string{1: "a", 2: "b", 3: "c"}
f := p[0:2]
// !!:传参时候必须带上[:],不然就是普通数组
fmt.Println(equal(p[:], q[:])) // true
fmt.Println(equal(p[:], f[:])) // false
// 唯一合法比较 s == nil 一个零值的slice等于nil
var s []int // len(s) == 0, s == nil
s = nil // len(s) == 0, s == nil
s = []int(nil) // len(s) == 0, s == nil
s = []int{} // len(s) == 0, s != nil
fmt.Println(s) // "[]"
// 6. 判断空
if len(s) == 0 {
fmt.Println("empty")
}
}
// reverse reverses a slice of ints in place.
func reverse(s []int) {
for i, j := 0, len(s)-1; i < j; i, j = i+1, j-1 {
s[i], s[j] = s[j], s[i]
}
}
func equal(x, y []string) bool {
if len(x) != len(y) {
return false
}
for i := range x {
if x[i] != y[i] {
return false
}
}
return true
}
切片重组(reslice)
改变切片长度的过程称之为切片重组 reslicing
slice1 := make([]type, start_length, capacity)
切片重组:
slice1 = slice1[0:end] end 是新的末尾索引(即长度)
slice1 := make([]int, 0, 10)
for i := 0; i < cap(slice1); i++ {
slice1 = slice1[0:i+1]
slice1[i] = i
}
fmt.Println(slice1) // [0 1 2 3 4 5 6 7 8 9]
// slice1 = slice1[0:11] // slice bounds out of range
var ar = [10]int{0,1,2,3,4,5,6,7,8,9}
var a = ar[5:7] // 长度5-2,容量取决于原数组长,10-5
fmt.Println(a, len(a), cap(a)) // [5 6] 2 5
// 重新分片
a = a[0:4]
fmt.Println(a, len(a), cap(a)) // [5 6 7 8] 4 5
a = a[1:1]
fmt.Println(a, len(a), cap(a)) // [] 0 4
new() 和 make() 的区别
看起来二者没有什么区别,都在堆上分配内存,但是它们的行为不同,适用于不同的类型。
- new(T) 为每个新的类型T分配一片内存,初始化为 0 并且返回类型为*T的内存地址:这种方法 返回一个指向类型为 T,值为 0 的地址的指针,它适用于值类型如数组和结构体;它相当于 &T{}。
- make(T) 返回一个类型为 T 的初始值,它只适用于3种内建的引用类型:切片、map 和 channel

字符串和Byte切片和数组
Byte切片->char *数组,还是变长的
var str string= "hello 你好"
// string->byte
b := []byte(str)
// byte->string
s2 := string(b)
bytes包提供了Buffer类型
package main
import (
"bytes"
"fmt"
)
func main() {
var buf bytes.Buffer
buf.WriteByte('[') // ASCII字符
buf.WriteString("1")
buf.WriteRune('我') // 添加任意字符的UTF8编码
str := buf.String() // Buffer->string
fmt.Println(str) // "[1我"
}
应用:修改字符串中字符
通过操作切片来完成对字符串的操作
// hello-》cello
s := "hello"
c := []byte(s)
c[0] = 'c'
s2 := string(c) // s2 == "cello"
应用:搜索及排序切片和数组
sort 包来实现常见的搜索和排序操作
Ints(arri)
对 int 类型的切片排序, 其中变量 arri 就是需要被升序排序的数组或切片
IntsAreSorted(a []int) bool
检查某个数组是否已经被排序
SearchInts(a []int, n int) int
在数组或切片中搜索一个元素,该数组或切片必须先被排序,返回对应结果的索引(当元素不存在时, 返回数组最后的索引位置)
func Float64s(a []float64)
排序 float64 的元素
func Strings(a []string)
排序字符串元素。
func SearchFloat64s(a []float64, x float64) int
func SearchStrings(a []string, x string) int
append
append返回值取决于原切片容量够不够大
- 够大,则直接改变原切片
- 不够大,则申请一个更大的空间(可能是2倍可能使用了更加复杂的内存扩展策略),再全体拷贝到新空间中,再添加新元素后返回
所以,使用的时候最好将返回结果直接赋值给参数slice
package main
import (
"fmt"
)
func main() {
var runes []rune
for _, r := range "Hello word" {
// 我们不能确认在原先的slice上的操作是否会影响到新的slice。
// 因此,通常是将append返回的结果直接赋值给输入的slice变量
runes = append(runes, r)
}
fmt.Printf("%q\n", runes) // ['H' 'e' 'l' 'l' 'o' ' ' 'w' 'o' 'r' 'd']
}
可以一次append多个数
var x []int
x = append(x, 1)
x = append(x, 2, 3)
x = append(x, 4, 5, 6)
x = append(x, x...) // append the slice x
fmt.Println(x) // "[1 2 3 4 5 6 1 2 3 4 5 6]"
append扩容本质
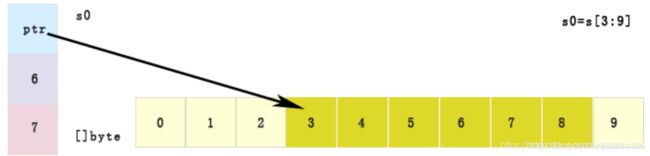
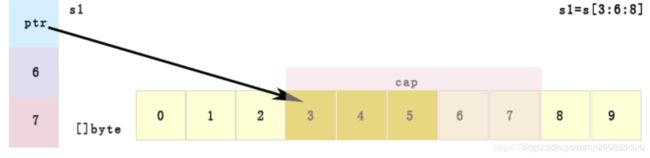
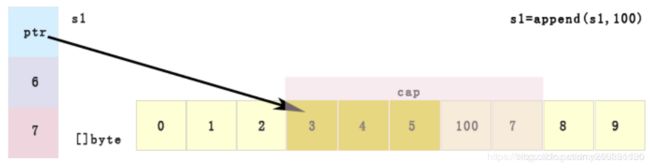
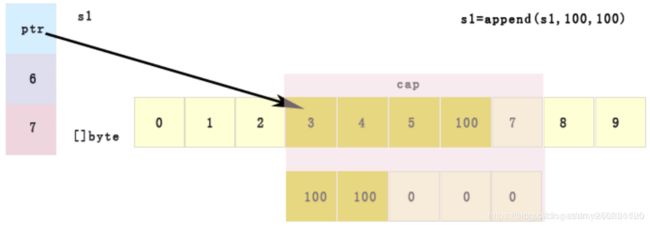
package main
import (
"fmt"
)
func main() {
// 切片
// 1: 占用资源很小
// 2: slice[a:b] 包含a索引值,不包含b索引值,默认容量上界索引为被操作对象容量上界索引
// 3: slice[a:b:c] 包含a索引值,不包含b索引值,容量上界索引为c
// 4: slice 只能向后扩展,不能向前扩展
// 5: slice append
// (1)某次操作未超过该slice容量上界索引,此次改变会更新原数组;
// (2)某次操作超过该slice容量上界索引则新的被操作对象数组会被新建,此次改变不会更新原数组
numArr := [10]uint{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice0 := numArr[3:9] // 容量上界索引为10
fmt.Println("slice0", slice0) // slice0 [3 4 5 6 7 8]
slice1 := numArr[3:6:8] // 容量上界索引为8
fmt.Println("slice1", slice1, len(slice1), cap(slice1)) // slice1 [3 4 5], len=6-3,cap = 8-3
slice1 = append(slice1, 100) // 此次 未超过该slice容量上界索引 更新原数组, 不新建数组
slice1 = append(slice1, 100, 100) // 此次 超过该slice容量上界索引 不更新原数组, 新建数组
var s []int = []int{1, 2, 3, 4}
fmt.Print(s)
for i := 0; i < len(slice0); i++ {
fmt.Println(i, slice0[i])
}
fmt.Println("slice0 ==>", len(slice0), cap(slice0))
for i := 0; i < len(slice1); i++ {
fmt.Println(i, slice1[i])
}
fmt.Println("slice1 ==>", len(slice1), cap(slice1))
for i := 0; i < len(numArr); i++ {
fmt.Println(i, numArr[i])
}
fmt.Println("slice ==>", len(numArr), cap(numArr))
}
append函数常见操作
将切片 b 的元素追加到切片 a 之后:a = append(a, b...)
复制切片 a 的元素到新的切片 b 上:
b = make([]T, len(a))
copy(b, a)
删除位于索引 i 的元素:a = append(a[:i], a[i+1:]...)
切除切片 a 中从索引 i 至 j 位置的元素:a = append(a[:i], a[j:]...)
为切片 a 扩展 j 个元素长度:a = append(a, make([]T, j)...)
在索引 i 的位置插入元素 x:a = append(a[:i], append([]T{x}, a[i:]...)...)
在索引 i 的位置插入长度为 j 的新切片:a = append(a[:i], append(make([]T, j), a[i:]...)...)
在索引 i 的位置插入切片 b 的所有元素:a = append(a[:i], append(b, a[i:]...)...)
取出位于切片 a 最末尾的元素 x:x, a = a[len(a)-1], a[:len(a)-1]
将元素 x 追加到切片 a:a = append(a, x)
因此,您可以使用切片和 append 操作来表示任意可变长度的序列。
从数学的角度来看,切片相当于向量,如果需要的话可以定义一个向量作为切片的别名来进行操作。
练习
将一个表示整值的字符串,每隔三个字符插入一个逗号分隔符,例如“12345”处理后成为“12,345”。
package main
import "fmt"
func comma(s string) string {
n := len(s)
if n <= 3 {
return s
}
return comma(s[:n-3]) + "," + s[n-3:]
}
func main() {
fmt.Println(comma("123456789")) // 123,456,789
}
练习 3.10: 编写一个非递归版本的comma函数,使用bytes.Buffer代替字符串链接操作。
import (
"bytes"
"fmt"
)
func comma(str string) string {
var buf bytes.Buffer
size := len(str)
if size <= 3 {
return str
}
firstINdex := size % 3
for index := 0; index < size; index++ {
buf.WriteByte(str[index])
if index != size - 1 && index % 3 == firstINdex - 1 {
buf.WriteByte(',')
}
}
return buf.String()
}
func main() {
fmt.Println(comma("12345678910"))
}
练习 3.11: 完善comma函数,以支持浮点数处理和一个可选的正负号的处理。
import (
"fmt"
"strings"
)
type Flag int
const (
negative Flag = iota
positive
)
func comma(s string, flag Flag) string {
dian := strings.LastIndex(s, ".")
if dian == -1 {
// 是整数
n := len(s)
if n <= 3 {
return s
}
if flag == 1 {
return comma(s[:n-3], positive) + "," + s[n-3:]
} else {
return s[:3] + "," + comma(s[3:], negative)
}
}
// 浮点数
positiveSize := len(s[:dian])
negativeSize := len(s[dian+1:])
if positiveSize <= 3 && negativeSize <= 3 {
return s
} else if positiveSize <= 3 {
return s[:dian+4] + "," + comma(s[dian+4:], negative)
} else if negativeSize <= 3 {
return comma(s[:dian-3], positive) + "," + s[dian-3:]
} else {
return comma(s[:dian-3], positive) + "," + s[dian-3:dian+4] + "," + comma(s[dian+4:], negative)
}
}
func main() {
fmt.Println(comma("0.3456789",positive))
fmt.Println(comma("123456.3456789",positive))
fmt.Println(comma("111.3456789",positive))
}
练习 3.12: 编写一个函数,判断两个字符串是否是是相互打乱的,也就是说它们有着相同的字符,但是对应不同的顺序。
package main
import "fmt"
func judgeEqual(str1, str2 string) bool {
m1 := make(map[rune]int)
m2 := make(map[rune]int)
for _, c := range str1 {
m1[c]++
}
for _, c := range str2 {
m2[c]++
}
for key, value := range m1 {
if value != m2[key] {
return false
}
}
return true
}
func main() {
fmt.Println(judgeEqual("123", "321")) // true
fmt.Println(judgeEqual("123", "3211")) // false
fmt.Println(judgeEqual("abdsfaads", "afdfadfa")) // true
fmt.Println(judgeEqual("abdsfaads", "sdaaabdsf")) // false
}
for-range下看切片和数组
注意:
1。 for-range相当于 for(auto item : items) item为值
2. range表达式只会在for语句开始执行时被求值一次,无论后边会有多少次迭代
3. 数组是值类型,i和e只是普通数值,被求值一次后就不变了
4. 切片是引用类型,i和e就是引用,被求值以后地址不变但指针指向值会变。
package main
import (
"fmt"
)
func main() {
// 数组
numbers2 := [...]int{1, 2, 3, 4, 5, 6}
maxIndex2 := len(numbers2) - 1
fmt.Println("len:", len(numbers2) - 1)
for i, e := range numbers2 {
fmt.Println(i, e)
if i == maxIndex2 {
numbers2[0] += e
} else {
numbers2[i+1] += e // 数组的e还是原数组,
}
}
fmt.Println(numbers2) // [7 3 5 7 9 11]
// 切片
numbers3 := []int{1, 2, 3, 4, 5, 6}
maxIndex2 = len(numbers3) - 1
fmt.Println("len:", len(numbers3) - 1)
for i, e := range numbers3 {
fmt.Println(i, e)
if i == maxIndex2 {
numbers3[0] += e
} else {
numbers3[i+1] += e // e在变
}
}
fmt.Println(numbers3) // [22 3 6 10 15 21]
}