Html.fromHtml()中Html.TagHandler()的使用
,前几天跑到这么个问题,要求显示这样的文字 1500/天 原价:20000元,而且文字的样式由服务器控制,所以我就自然的想到了Html.fromHtml()这个方法,它是用来解析Html的。好!我就用它来解析一下上面的文字的Html,先把上面文字的html贴出看看: 1500/天 原价:20000元 >,就是这样的一段html。
好了上代码:
布局文件(其实就是一个TextView控件):
java代码:
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView textView = (TextView) findViewById(R.id.testHtml);
String htmlStr = " 1500/天 原价:20000元 ";
textView.setText(Html.fromHtml(htmlStr));
}
额!完全没有样式显示出来,就简简单单的把文字内容显示出来了。Html确定是没有写错的。那么是为什么呢?
Html.fromHtml(),呃!机智的我知道了,他是Html.fromHtml()不是Html.fromCss(),应该是不支持样式的。好!那我改改,改成全部用Html标签表示。 1500/天 原价:20000元,这个就是用html标签表示的。代码: 1500/天 原价:20000元 ,好!那我来试试。
java代码:
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView textView = (TextView) findViewById(R.id.testHtml);
String htmlStr = " 1500/天 原价:20000元 ";
String htmlStr_1 = " 1500/天 原价:20000元 ";
textView.setText(Html.fromHtml(htmlStr_1));
}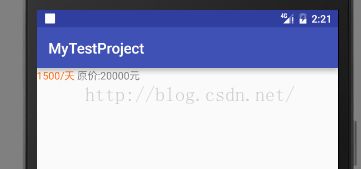
font标签的color属性表现出来,但是del标签和font标签的size属性没有表现出来。难道Html.fromHtml()不支持del标签?那我用strike试试!html代码改为: 1500/天 原价:20000元 这样。
java代码:
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView textView = (TextView) findViewById(R.id.testHtml);
String htmlStr = " 1500/天 原价:20000元 ";
String htmlStr_1 = " 1500/天 原价:20000元 ";
String htmlStr_2 = " 1500/天 原价:20000元 ";
textView.setText(Html.fromHtml(htmlStr_2));
}
额!貌似strike也不支持。那Html.fromHtml()这个到底支持什么啊。
来来~我们看看它的庐山真面目,找到这个类:android.text.Html
看看它的这个方法:
private void handleStartTag(String tag, Attributes attributes) {
if (tag.equalsIgnoreCase("br")) {
// We don't need to handle this. TagSoup will ensure that there's a for each
// so we can safely emite the linebreaks when we handle the close tag.
} else if (tag.equalsIgnoreCase("p")) {
handleP(mSpannableStringBuilder);
} else if (tag.equalsIgnoreCase("div")) {
handleP(mSpannableStringBuilder);
} else if (tag.equalsIgnoreCase("strong")) {
start(mSpannableStringBuilder, new Bold());
} else if (tag.equalsIgnoreCase("b")) {
start(mSpannableStringBuilder, new Bold());
} else if (tag.equalsIgnoreCase("em")) {
start(mSpannableStringBuilder, new Italic());
} else if (tag.equalsIgnoreCase("cite")) {
start(mSpannableStringBuilder, new Italic());
} else if (tag.equalsIgnoreCase("dfn")) {
start(mSpannableStringBuilder, new Italic());
} else if (tag.equalsIgnoreCase("i")) {
start(mSpannableStringBuilder, new Italic());
} else if (tag.equalsIgnoreCase("big")) {
start(mSpannableStringBuilder, new Big());
} else if (tag.equalsIgnoreCase("small")) {
start(mSpannableStringBuilder, new Small());
} else if (tag.equalsIgnoreCase("font")) {
startFont(mSpannableStringBuilder, attributes);
} else if (tag.equalsIgnoreCase("blockquote")) {
handleP(mSpannableStringBuilder);
start(mSpannableStringBuilder, new Blockquote());
} else if (tag.equalsIgnoreCase("tt")) {
start(mSpannableStringBuilder, new Monospace());
} else if (tag.equalsIgnoreCase("a")) {
startA(mSpannableStringBuilder, attributes);
} else if (tag.equalsIgnoreCase("u")) {
start(mSpannableStringBuilder, new Underline());
} else if (tag.equalsIgnoreCase("sup")) {
start(mSpannableStringBuilder, new Super());
} else if (tag.equalsIgnoreCase("sub")) {
start(mSpannableStringBuilder, new Sub());
} else if (tag.length() == 2 &&
Character.toLowerCase(tag.charAt(0)) == 'h' &&
tag.charAt(1) >= '1' && tag.charAt(1) <= '6') {
handleP(mSpannableStringBuilder);
start(mSpannableStringBuilder, new Header(tag.charAt(1) - '1'));
} else if (tag.equalsIgnoreCase("img")) {
startImg(mSpannableStringBuilder, attributes, mImageGetter);
} else if (mTagHandler != null) {
mTagHandler.handleTag(true, tag, mSpannableStringBuilder, mReader);
}
}它支持:
| br | 换行符 | |
| p | 定义段落 | |
| div | 定义文档中的分区或节 | |
| strong | 用于强调文本 | 用于强调文本 |
| b | 粗体文本 | 粗体文本 |
| em | 斜体显示 | 斜体显示 |
| cite | 斜体显示 | 斜体显示 |
| dfn | 斜体显示 | 斜体显示 |
| i | 斜体显示 | 斜体显示 |
| big | 大号字体 | 大号字体 |
| small | 小号字体 | 小号字体 |
| font | 字体标签 | 字体标签 |
| blockquote | 标签定义块引用 |
标签定义块引用 |
| tt | 字体显示为等宽字体 | 字体显示为等宽字体 |
| a | 超链接 | 百度 |
| u | 下划线 | 下划线 |
| sup | 上标 | 我有上标上标 |
| sub | 下标 | 我有下标下标 |
| h1-h6 | 标题字体 | 这是标题 1这是标题 2这是标题 3这是标题 4这是标题 5这是标题 6 |
| img | 图片 |
private static void startFont(SpannableStringBuilder text,
Attributes attributes) {
String color = attributes.getValue("", "color");
String face = attributes.getValue("", "face");
int len = text.length();
text.setSpan(new Font(color, face), len, len, Spannable.SPAN_MARK_MARK);
}那我的 1500/天 原价:20000元这个效果就不能做到吗?也不是,其实要解决的问题也就只有2个,一个就是让Html.fromHtml()可以认识标签,另一个就是让font支持size属性,这就要用到Html.TagHandler()了。
我们首先解决第一个问题:让Html.fromHtml()可以认识标签。
java代码:
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView textView = (TextView) findViewById(R.id.testHtml);
String htmlStr = " 1500/天 原价:20000元 ";
String htmlStr_1 = " 1500/天 原价:20000元 ";
String htmlStr_2 = " 1500/天 原价:20000元 ";
textView.setText(Html.fromHtml(htmlStr_1,null, new Html.TagHandler() {
int startTag;
int endTag;
@Override
public void handleTag(boolean opening, String tag, Editable output, XMLReader xmlReader) {
if (tag.equalsIgnoreCase("del")){
if(opening){
startTag = output.length();
}else{
endTag = output.length();
output.setSpan(new StrikethroughSpan(),startTag,endTag, Spanned.SPAN_EXCLUSIVE_EXCLUSIVE);
}
}
}
}));
}用tag来识别标签,然后用SpannableString对文字进行样式。
SpannableString功能有以下:
1、BackgroundColorSpan 背景色
2、ClickableSpan 文本可点击,有点击事件
3、ForegroundColorSpan 文本颜色(前景色)
4、MaskFilterSpan 修饰效果,如模糊(BlurMaskFilter)、浮雕(EmbossMaskFilter)
5、MetricAffectingSpan 父类,一般不用
6、RasterizerSpan 光栅效果
7、StrikethroughSpan 删除线(中划线)
8、SuggestionSpan 相当于占位符
9、UnderlineSpan 下划线
10、AbsoluteSizeSpan 绝对大小(文本字体)
11、DynamicDrawableSpan 设置图片,基于文本基线或底部对齐。
12、ImageSpan 图片
13、RelativeSizeSpan 相对大小(文本字体)
14、ReplacementSpan 父类,一般不用
15、ScaleXSpan 基于x轴缩放
16、StyleSpan 字体样式:粗体、斜体等
17、SubscriptSpan 下标(数学公式会用到)
18、SuperscriptSpan 上标(数学公式会用到)
19、TextAppearanceSpan 文本外貌(包括字体、大小、样式和颜色)
20、TypefaceSpan 文本字体
21、URLSpan 文本超链接
好了我们看看识别之后的效果:

中划线种出来了。
再解决第二个问题:
java代码:
/**
* 自定义的一html标签解析
*
* Created by Siy on 2016/11/19.
*/
public class CustomerTagHandler implements Html.TagHandler {
/**
* html 标签的开始下标
*/
private Stack startIndex;
/**
* html的标签的属性值 value,如: propertyValue;
@Override
public void handleTag(boolean opening, String tag, Editable output, XMLReader xmlReader) {
Log.e("TAG","handleTag:"+tag);
if (opening) {
handlerStartTAG(tag, output, xmlReader);
} else {
handlerEndTAG(tag, output);
}
}
/**
* 处理开始的标签位
*
* @param tag
* @param output
* @param xmlReader
*/
private void handlerStartTAG(String tag, Editable output, XMLReader xmlReader) {
if (tag.equalsIgnoreCase("del")) {
handlerStartDEL(output);
} else if (tag.equalsIgnoreCase("font")) {
handlerStartSIZE(output, xmlReader);
}
}
/**
* 处理结尾的标签位
*
* @param tag
* @param output
*/
private void handlerEndTAG(String tag, Editable output) {
if (tag.equalsIgnoreCase("del")) {
handlerEndDEL(output);
} else if (tag.equalsIgnoreCase("font")) {
handlerEndSIZE(output);
}
}
private void handlerStartDEL(Editable output) {
if (startIndex == null) {
startIndex = new Stack<>();
}
startIndex.push(output.length());
}
private void handlerEndDEL(Editable output) {
output.setSpan(new StrikethroughSpan(), startIndex.pop(), output.length(), Spanned.SPAN_EXCLUSIVE_EXCLUSIVE);
}
private void handlerStartSIZE(Editable output, XMLReader xmlReader) {
if (startIndex == null) {
startIndex = new Stack<>();
}
startIndex.push(output.length());
if (propertyValue == null) {
propertyValue = new Stack<>();
}
propertyValue.push(getProperty(xmlReader, "size"));
}
private void handlerEndSIZE(Editable output) {
if (!isEmpty(propertyValue)) {
try {
int value = Integer.parseInt(propertyValue.pop());
output.setSpan(new AbsoluteSizeSpan(sp2px(MainApplication.getInstance(), value)), startIndex.pop(), output.length(), Spanned.SPAN_EXCLUSIVE_EXCLUSIVE);
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 利用反射获取html标签的属性值
*
* @param xmlReader
* @param property
* @return
*/
private String getProperty(XMLReader xmlReader, String property) {
try {
Field elementField = xmlReader.getClass().getDeclaredField("theNewElement");
elementField.setAccessible(true);
Object element = elementField.get(xmlReader);
Field attsField = element.getClass().getDeclaredField("theAtts");
attsField.setAccessible(true);
Object atts = attsField.get(element);
Field dataField = atts.getClass().getDeclaredField("data");
dataField.setAccessible(true);
String[] data = (String[]) dataField.get(atts);
Field lengthField = atts.getClass().getDeclaredField("length");
lengthField.setAccessible(true);
int len = (Integer) lengthField.get(atts);
for (int i = 0; i < len; i++) {
// 这边的property换成你自己的属性名就可以了
if (property.equals(data[i * 5 + 1])) {
return data[i * 5 + 4];
}
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
/**
* 集合是否为空
*
* @param collection
* @return
*/
public static boolean isEmpty(Collection collection) {
return collection == null || collection.isEmpty();
}
/**
* 缩放独立像素 转换成 像素
* @param context
* @param spValue
* @return
*/
public static int sp2px(Context context, float spValue){
return (int)(TypedValue.applyDimension(TypedValue.COMPLEX_UNIT_SP,spValue,context.getResources().getDisplayMetrics())+0.5f);
}
}
getProperty()方法是用来获取标签的属性值。
这里还是有一个问题,直接看运行结果:
font 还是没有处理字体大小。为什么了?看回前面的handleStartTag方法,用的是if...else if语法,而且对mTagHandler!=null的判断是放在最后的,只要前面有一个标签成功就不会执行这里,所以对Html.formHtml()支持的标签加属性支持是行不通的。既然对支持的标签加属性行不通,那我们自己增加一size 标签给他value属性标识size的大小不就行了。
java代码:
这里我们要改一下html代码,注意htmlStr_3:
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView textView = (TextView) findViewById(R.id.testHtml);
String htmlStr = " 1500/天 原价:20000元 ";
String htmlStr_1 = " 1500/天 原价:20000元 ";
String htmlStr_2 = " 1500/天 原价:20000元 ";
String htmlStr_3 = " 1500/天 原价:20000元 /**
* 自定义的一html标签解析
*
* Created by Siy on 2016/11/19.
*/
public class CustomerTagHandler implements Html.TagHandler {
/**
* html 标签的开始下标
*/
private Stack startIndex;
/**
* html的标签的属性值 value,如: propertyValue;
@Override
public void handleTag(boolean opening, String tag, Editable output, XMLReader xmlReader) {
Log.e("TAG","handleTag:"+tag);
if (opening) {
handlerStartTAG(tag, output, xmlReader);
} else {
handlerEndTAG(tag, output);
}
}
/**
* 处理开始的标签位
*
* @param tag
* @param output
* @param xmlReader
*/
private void handlerStartTAG(String tag, Editable output, XMLReader xmlReader) {
if (tag.equalsIgnoreCase("del")) {
handlerStartDEL(output);
} else if (tag.equalsIgnoreCase("size")) {
handlerStartSIZE(output, xmlReader);
}
}
/**
* 处理结尾的标签位
*
* @param tag
* @param output
*/
private void handlerEndTAG(String tag, Editable output) {
if (tag.equalsIgnoreCase("del")) {
handlerEndDEL(output);
} else if (tag.equalsIgnoreCase("size")) {
handlerEndSIZE(output);
}
}
private void handlerStartDEL(Editable output) {
if (startIndex == null) {
startIndex = new Stack<>();
}
startIndex.push(output.length());
}
private void handlerEndDEL(Editable output) {
output.setSpan(new StrikethroughSpan(), startIndex.pop(), output.length(), Spanned.SPAN_EXCLUSIVE_EXCLUSIVE);
}
private void handlerStartSIZE(Editable output, XMLReader xmlReader) {
if (startIndex == null) {
startIndex = new Stack<>();
}
startIndex.push(output.length());
if (propertyValue == null) {
propertyValue = new Stack<>();
}
propertyValue.push(getProperty(xmlReader, "value"));
}
private void handlerEndSIZE(Editable output) {
if (!isEmpty(propertyValue)) {
try {
int value = Integer.parseInt(propertyValue.pop());
output.setSpan(new AbsoluteSizeSpan(sp2px(MainApplication.getInstance(), value)), startIndex.pop(), output.length(), Spanned.SPAN_EXCLUSIVE_EXCLUSIVE);
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 利用反射获取html标签的属性值
*
* @param xmlReader
* @param property
* @return
*/
private String getProperty(XMLReader xmlReader, String property) {
try {
Field elementField = xmlReader.getClass().getDeclaredField("theNewElement");
elementField.setAccessible(true);
Object element = elementField.get(xmlReader);
Field attsField = element.getClass().getDeclaredField("theAtts");
attsField.setAccessible(true);
Object atts = attsField.get(element);
Field dataField = atts.getClass().getDeclaredField("data");
dataField.setAccessible(true);
String[] data = (String[]) dataField.get(atts);
Field lengthField = atts.getClass().getDeclaredField("length");
lengthField.setAccessible(true);
int len = (Integer) lengthField.get(atts);
for (int i = 0; i < len; i++) {
// 这边的property换成你自己的属性名就可以了
if (property.equals(data[i * 5 + 1])) {
return data[i * 5 + 4];
}
}
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
/**
* 集合是否为空
*
* @param collection
* @return
*/
public static boolean isEmpty(Collection collection) {
return collection == null || collection.isEmpty();
}
/**
* 缩放独立像素 转换成 像素
* @param context
* @param spValue
* @return
*/
public static int sp2px(Context context, float spValue){
return (int)(TypedValue.applyDimension(TypedValue.COMPLEX_UNIT_SP,spValue,context.getResources().getDisplayMetrics())+0.5f);
}
}

这里控制字体的大小并不是用font的size属性控制的(前面说了,font并不会进入TagHandler中),而是自己自定义了一个size标签里面定义了一个value属性(
这如果有小伙伴说我有执念,我就是想用font里面的font属性怎么办。不想再自定义一个size标签。额!
这个是有办法的。
java代码(这个类是实现小伙伴执念的关键类,来自于这里,英语好的可以自己看):
/**
* Created by Siy on 2016/11/23.
*/
public class HtmlParser implements Html.TagHandler, ContentHandler
{
//This approach has the advantage that it allows to disable processing of some tags while using default processing for others,
// e.g. you can make sure that ImageSpan objects are not created:
public interface TagHandler
{
// return true here to indicate that this tag was handled and
// should not be processed further
boolean handleTag(boolean opening, String tag, Editable output, Attributes attributes);
}
public static Spanned buildSpannedText(String html, TagHandler handler)
{
// add a tag at the start that is not handled by default,
// allowing custom tag handler to replace xmlReader contentHandler
return Html.fromHtml(" tagStatus = new ArrayDeque<>();
private HtmlParser(TagHandler handler)
{
this.handler = handler;
}
@Override
public void handleTag(boolean opening, String tag, Editable output, XMLReader xmlReader)
{
if (wrapped == null)
{
// record result object
text = output;
// record current content handler
wrapped = xmlReader.getContentHandler();
// replace content handler with our own that forwards to calls to original when needed
xmlReader.setContentHandler(this);
// handle endElement() callback for
/**
* Created by Siy on 2016/11/23.
*/
public class CustomerTagHandler_1 implements HtmlParser.TagHandler {
/**
* html 标签的开始下标
*/
private Stack startIndex;
/**
* html的标签的属性值 value,如: propertyValue;
@Override
public boolean handleTag(boolean opening, String tag, Editable output, Attributes attributes) {
if (opening) {
handlerStartTAG(tag, output, attributes);
} else {
handlerEndTAG(tag, output, attributes);
}
return handlerBYDefault(tag);
}
private void handlerStartTAG(String tag, Editable output, Attributes attributes) {
if (tag.equalsIgnoreCase("font")) {
handlerStartFONT(output, attributes);
} else if (tag.equalsIgnoreCase("del")) {
handlerStartDEL(output);
}
}
private void handlerEndTAG(String tag, Editable output, Attributes attributes) {
if (tag.equalsIgnoreCase("font")) {
handlerEndFONT(output);
} else if (tag.equalsIgnoreCase("del")) {
handlerEndDEL(output);
}
}
private void handlerStartFONT(Editable output, Attributes attributes) {
if (startIndex == null) {
startIndex = new Stack<>();
}
startIndex.push(output.length());
if (propertyValue == null) {
propertyValue = new Stack<>();
}
propertyValue.push(HtmlParser.getValue(attributes, "size"));
}
private void handlerEndFONT(Editable output) {
if (!isEmpty(propertyValue)) {
try {
int value = Integer.parseInt(propertyValue.pop());
output.setSpan(new AbsoluteSizeSpan(sp2px(MainApplication.getInstance(), value)), startIndex.pop(), output.length(), Spanned.SPAN_EXCLUSIVE_EXCLUSIVE);
} catch (Exception e) {
e.printStackTrace();
}
}
}
private void handlerStartDEL(Editable output) {
if (startIndex == null) {
startIndex = new Stack<>();
}
startIndex.push(output.length());
}
private void handlerEndDEL(Editable output) {
output.setSpan(new StrikethroughSpan(), startIndex.pop(), output.length(), Spanned.SPAN_EXCLUSIVE_EXCLUSIVE);
}
/**
* 返回true表示不交给系统后续处理
* false表示交给系统后续处理
*
* @param tag
* @return
*/
private boolean handlerBYDefault(String tag) {
if (tag.equalsIgnoreCase("del")) {
return true;
}
return false;
}
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView textView = (TextView) findViewById(R.id.testHtml);
String htmlStr = " 1500/天 原价:20000元 ";
String htmlStr_1 = " 1500/天 原价:20000元 ";
String htmlStr_2 = " 1500/天 原价:20000元 ";
String htmlStr_3 = " 1500/天 原价:20000元 
那为什么用HtmlParser就可以得到font标签,前面我不是说Html.fromHtml支持的标签不会进入TagHandler中吗!实力打自己的脸了,其实并不是的,大家看HtmlParser的第53行获取了默认的ContentHanler,然后第56行又把自己的ContentHandler设置了进去,然后在69行判断ishandler(HtmlParser.TagHandler的handleTag方法的返回值),如果ishandler是false就会执行默认的ContentHandler,也就是说我们在默认的ContentHandler处理之前就自己解析了html标签,当然就能获得font标签了。
本文中关于读取标签属性的方法来自于这里