超详细Apache NIFI同步Mysql (读取binlog)数据变化到Hbase教程
文章目录
- 受众人群
- 阅读须知(免责声明)
- 简介
- 软件环境
- 参考内容
- 操作流程
- 开启Mysql的binlog
- Apache NIFI使用简介
- 个人理解NIFI使用流程
- 提供本文模板xml文件
- 读取Mysql的binlog信息
- 添加CaptureChangeMySQL Processor
- 添加DistributedMapCacheServer
- 路由binlog的操作类型
- 添加RouteOnAttribute Processor
- 添加我们第一个Connection
- 启动CaptureChangeMysql 试一试
- 整理binlog的数据格式
- 保证执行顺序
- 再新建个RouteOnAttribute Processor
- 新建EvaluateJsonPath Processor(删除操作分支)
- 新建DeleteHBaseRow Processor(删除操作实现)
- 新建PutHBaseJSON Processor(insert/update操作对应分支)
- 启动整个流程测试效果
受众人群
适合对于NIFI使用一脸懵逼的萌新小伙伴.希望根据本文可以帮助大家从懵逼状态过渡到小懵逼状态:P
内容会多图细致指导,NIFI懂得越多看完越会觉得本文很啰嗦.
//TODO删除此行:观众:只不过没找到简介明了的说明方法吧.作者:闭嘴!你懂得太多了
阅读须知(免责声明)
能力有限,NIFI新手入门所写,希望本篇内容错误少一些,避免误导大家的内容存在.
本文由互联网知识内容汇总实现的功能,步骤流程有不完善或可优化的地方,欢迎讨论指正.也希望这篇可以抛砖引玉,对于同样NIFI的新手提供一些帮助,少走一些弯路.
本文对于作者自身遇到的一些NIFI操作的知识点,会以TIPS作为前缀,属于辅助讲解.根据自身掌握需求情况,有选择性的跳过即可.
简介
使用Apache NIFI通过读取mysql开启的binlog日志,同步数据库变化到Hbase.
软件环境
NIFI 1.9.2
HBASE 2.1.4
mysql 5.7
参考内容
使用NiFi将数据从Mysql导入至HBase
学习这篇内容,可以先实现全量同步mysql到Hbase的操作实现.
Change Data Capture (CDC) with Apache NiFi(1/3)
这个教程共3篇,文章末尾有跳转到下一篇的超链接,将使用NIFI利用binlog同步mysql的设置流程.
Delete Row Key(s) using DeleteHBaseRow processor in NiFi
NIFI根据Rowkey删除Hbase一行内容.
Jolt Transform DemoJolt简易DEMO教学和使用测试
操作流程
开启Mysql的binlog
参考这篇文章linux开启MySQL binlog日志.(这篇文章没有配置binlog_format=row)
稍微介绍下修改my.cfg(linux),my.ini(windows版,在mysql安装目录根目录下)里面的参数
推荐阅读:
binlog之四:mysql中binlog_format模式与配置详解,binlog的日志格式详解
# 服务器ID,多台服务器集群配置这个属性注意不要重复
server_id = 1
#binlog文件存储路径及文件名前缀(本例前缀是mysql-bin,回头生成binlog文件会有:mysql-bin.index,mysql-bin.000001,mysql-bin000002等)
log-bin=D:\developSetup\mysql-5.7.22-winx64\mysql-bin
#很重要 必须有
#很重要 必须有
#很重要 必须有 因为好根据row级别数据改变内容去修改hbase对应记录.(不清楚其他模式是否可以同步到hbase里)
binlog_format=row
# 哪些数据库启用binlog
binlog_do_db = source1
binlog_do_db = source2
binlog_do_db = source3
Apache NIFI使用简介
推荐阅读:Apache NiFi用户指南
个人理解NIFI使用流程
把整个过程拆成一个一个处理功能点,把功能点用有向/且有条件匹配关系进行关联.实现最终功能需求.
功能点对应:NIFI里的各个Processor(即下图里的各种矩形方框).
有向关系:对应NIFI里的Releation,就是下图有向连接线
最后做完像一个流程图.见下图

提供本文模板xml文件
文件地址戳我
读取Mysql的binlog信息
CaptureChangeMySQL是NIFI用于读取Mysql的binlog内容的Processor.
添加CaptureChangeMySQL Processor
拖动一个Processor到工作区域,见下图

之后松开鼠标左边,会有弹窗弹出,见下图.在下图红框里输入cap即可,会根据输入的内容过滤出符合名字的Processor.之后点击右下角ADD,确认添加.

TIPS:processor上有橙色小叹号
鼠标指上去会有弹出提示有何种错误,不解决一般会导致这个Processor无法启动正常工作.见下图,提示我们新添加的Processor没有设置Mysql的hosts

右键我们刚ADD的CaptureChangeMySQL ,选择Configure(配置)

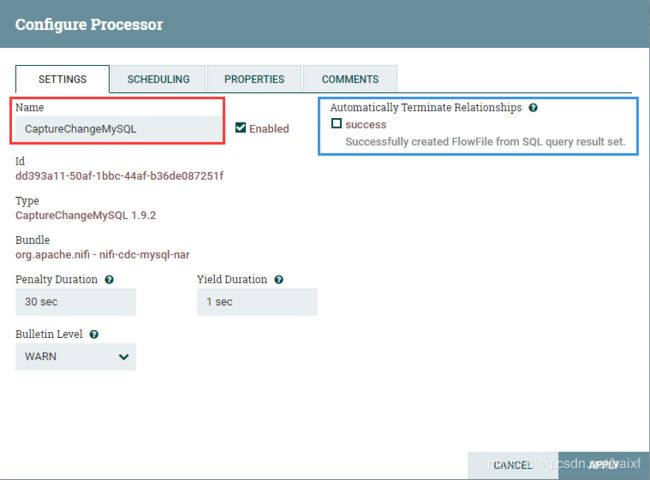
SETTINGS标签:
红框name可以修改这个Processor的名称,可无视.
蓝框设置自动停止的触发关系条件.
SCHEDULING标签:
设置调度模式,按时间或者CRON模式(可配置CRON表达式)
COMMENTS标签:
字面意思,评论,备注之类的描述信息.
压轴的PROPERTIES标签:
配置样例见下图,
配置的Mysql链接的jar包自行下载下,对于配置参数有疑问,可以鼠标指向参数名称后面的小问号,会有提示.
贼关键点!
贼关键点!
贼关键点!
Distributed Map Cache Client一定要设置,我最开始理解错误以为需要依赖第三方的存储来实现这个功能,而且我没有了解到这个配置的重要性.,我手欠的删除了.引发惨痛的教训如下:
不用Distributed Map Cache Client读取到的binlog里的字符串类型信息(数据库名,数据表名,字符串类的字段内容会是null,还会缺失mysql字段名称,后面会举例说明).
点击Distributed Map Cache Client后面空白区域会像下图所示,选择红框内容,并确认


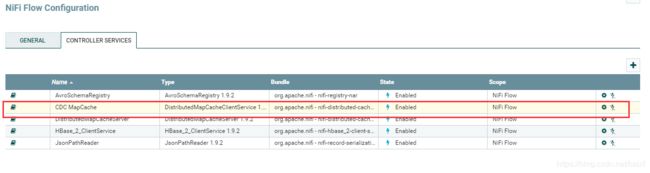
再点击上图界面,CDC MapCache 右边的向右小箭头去配置和启用,见下图界面.
我当前截图是停用状态,这时可以去点齿轮图标进行配置修改,这个地方默认级可以,不需要修改,可以直接点击最右边闪电进行启用.

可以看到图中右上方CaptureChangeMySQL Processor有橙色叹号,是因为我们这个CDC MapCaches属于的这个Processor,但是还不是启用状态导致的.点击右下角ENABEL确认启用.

启用后截图见下图,status列会显示Enabled
TIPS:我们如何快速进入这个NiFi Flow Configuration,去配置这些CONTROLLER SERVICES?
毕竟每次我们设置这些内容,或是开启需要找到对应的 Processor,再进去有些小麻烦.捷径见下图,下图呈现的是选中了CaptureChangeMySQL Processor,左边Operate处显示被选中的Processor

此时,我们可以单击空白处,Operate会变为下图状态,再点击齿轮可以进入NiFi Flow Configuration.
后面依次是
全部启动CONTROLLER SERVICES,
全部禁用CONTROLLER SERVICES,
全部启动工作区域内所有Processor,
全部停用工作区域内所有Processor,
将当前工作区域内的内容存储为模板,
上传一个模板文件(xml格式),
复制,
粘贴,
Group(没用过.不知道干嘛的…),
修改Processor颜色,
删除选中的Processor
TIPS删除Processor前提条件
1不是其余Processor的下游组件(没有上级Processor)
2与其关联的关系(有向线)里不存在数据,如果存在数据可以右键关系,选择Empty queue来清空关系里的队列数据,之后再删除Processor
添加DistributedMapCacheServer
进入NiFi Flow Configuration,选择CONTROLLER SERVICES标签,见下图

我们已经有了上图红框内容,可以看到其类型Type列内容是:
DistributedMapCacheClientService 1.9.2
单词client表明是一个使用的客户端,所以我们还需要添加一个server服务器端,来给client提供服务,也就是需要要添加上图橙色框内容Type类是:
DistributedMapCacheServer
点击上图右上角加号添加,进入下图界面,在文本框里输入DistributedMapCacheServer
选中过滤出来的这个,并点击ADD添加.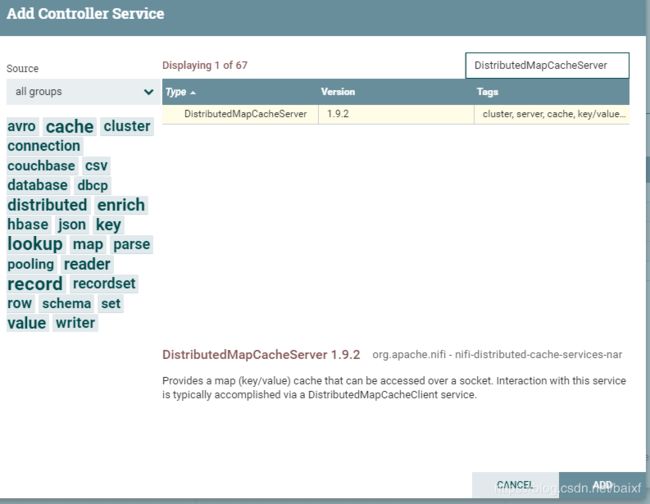
之后效果如下图,类似刚才的DistributedMapCacheClient ,不用配置修改什么,直接点击启用就可以.(前提之前的DistributedMapCacheClient 没有做过什么修改也是默认配置,保证端口号之类的属性对应的上)
![]()
TIPS清空CaptureChangeMySQL的state
用于测试时,从头读取binlog数据使用,省去我们每次测试再去mysql一顿猛如虎的增删改查操作产生新的binlog.
这是因为正常不清空state状态时,CaptureChangeMySQL会记录读取Mysql binlog的位置,下回(哪怕重启CaptureChangeMySQL Processor)读取时,会读取记录位置后面的内容.这样设计是合理的,避免数据重复读取的问题.但是对于我们测试期间就没有必要性.
所以为了方便测试我们可以清空这个记录的状态,从头读取mysql的binlog记录.
点击下图红框处的Clear state即可.

路由binlog的操作类型
作用说明:
根据binlog中含有的类型参数,把binlog记录的日志操作根据类型进行路由处理,提供给不同的下游分支操作.
添加RouteOnAttribute Processor
还是拖动个
进入工作区,搜索框输入
RouteOnAttribute
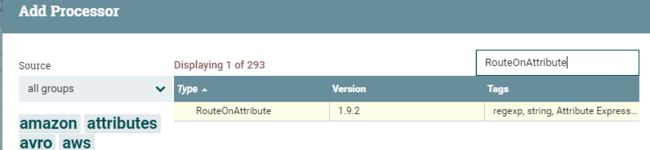
并点击右下角ADD.
下一步开始设置
右键这个processor,点击configure.,选择PROPERTIES标签进入下图
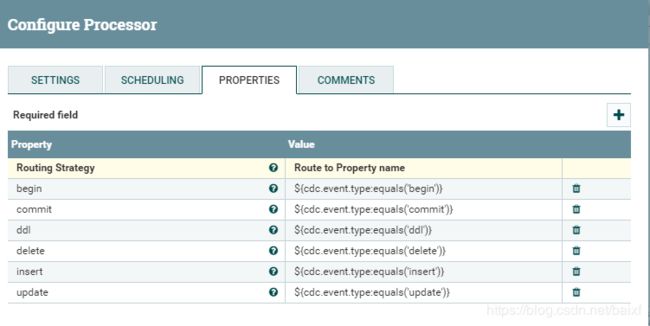
Routing Strategy:路由策略用默认的Route toProperty name,根据属性名进行路由.
上图下面一堆内容是点击图中右侧小加号一个一个添加进去的,分别应对Mysql的binglog操作类型,本示例最终只演示对于insert/delete/update的处理其余类型的会被舍弃处理(咳咳因为业务没需求使用ddl,begin,commit,所以没研究,还不会 ).
PS:为何采集还要带着ddl,begin,commit这些类型数据内容?
因为抄袭的国外那个demo带着,而且后面沿用的流程,会有一个强制保持顺序的processor,后文会详细介绍下.
这个Processor会将读取binlog的所有操作按顺序排序传递给下游其余processor.如果缺失中间的几个binlog操作导致序号无法顺序执行,
添加我们第一个Connection
至此我们新建了2个Processor,当前他们还是彼此孤立无援,而其鼠标指向叹号三角会看到配置不完整的报错提示,表示需要发生点什么关系才行,否则这个Processor是无法正常启动使用的.

所以我们需要将它们连接起来,鼠标指向CaptureChangeMysql Processor,中间会有下图所示的一个箭头图标,鼠标指向这个图标并按住,拖向我们的RouteOnAttribute Processor(并使其边框变绿即可松手)

之后弹出下图,创建连接的配置页面.我们需要关注的是截图For Relationships这里,勾选你希望达成什么关系,才会让数据从上游Processor流到下游Processor.这里我们只有一个success关系可选,在后面会有多种关系可以多选的情况.在这里我们直接点击ADD确认添加一个Conection就好了,有兴趣可以看看SETTINGS标签可以重命名这个Concetion名称,以及队列消息的进出顺序规则,((由于后面选择了强制排序的Processor所以这里没有配置顺序规则也没影响)
如果想配置可以配置如下图所示样子,将规则FirstInFirstOutPriorltizer等拖到下面Selected Prioritizers下方,可以拖动多个规则,越在上面,优先级越高.
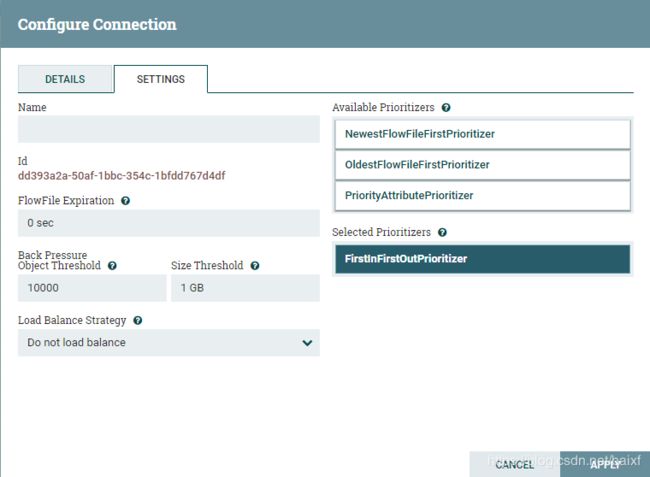
TIPS:Prioritizer(优先排序)默认优先规则是什么?
google了下2015年NIFI版本,以效率优先,规则会动态变动,帖子内容戳我
当前(2019年7月份)的规则是以OldestFlowFileFirstPrioritizer规则为默认.点击这里查看官方prioritization介绍
那么问题来了FirstInFirstOutPrioritizer(FIFO) 和OldestFlowFileFirstPrioritizer(OFF)有啥区别哟?
stackoverflow的解答
我个人理解完,解释如下:设想一个数据源,不同数据类型会分几个不同分支来处理数据,处理完最终再次汇总到一个Processor里,那么汇总procssor再向其下游Processor传递数据的Conection关系,可以看出这两类区别
.比如数据内容1,2,3代表3条有顺序数据,数字越大表示数据越新,123交给不同分支处理.如果以312顺序到达汇总后的Conection里,且还没有被发送时,这时候会评定发送给下游的传输顺序
如果是FIFO,那么输出就是312,因为谁先到这个Conection谁先出.
但是如果是OFF,由于1最老最先进入NIFI处理的,所以最后发出顺序是123,简单来说就是尊老不爱幼原则.
启动CaptureChangeMysql 试一试
我们现在已经有2个Processor和一个Conection了,我们已经可以启动CaptureChangeMysql 来试一试效果了.
注意前提
- CaptureChangeMysql 没有橙色叹号
- 确保mysql那边已经有binlog产生
- 防火墙等限制网络通信情况
让我们来试试吧,右键CaptureChangeMysql ,在弹出菜单里选择Start,静等效果
如果成功会类似下图所示,我们的关系是Success的Conection里堆积了数据,而且CaptureChangeMysql 也显示read/write以及Out里也会有数据大小

当然也有可能报错了,实践的道路上怎能少了这些挫折的调味品!
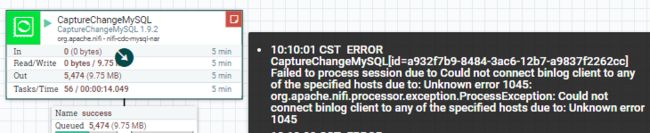
TIPS:如何查看Processor报错信息?
见下图,鼠标指向processor红色便签图标处,会有详细信息
另外下图说Unknown error 1045,并没有说明是啥错误啊?鉴于我们这个是读取binlog的Processor,所以这里其实是反馈的Mysql的报错代码,百度下mysql 1045就有想要的错误解决方案了.
TIPS:我怎么查看Processor里的数据?
右键选择下面菜单View Data provenance内容,
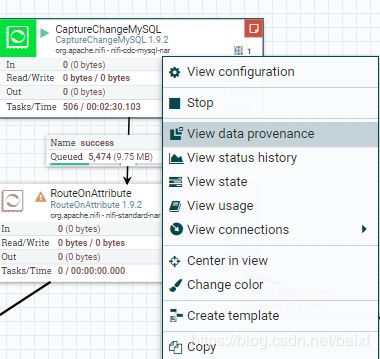
想看数据可以,点击每条记录最前面的圈i,小图标.
行尾部的两个操作
第一个是查看数据到这里走过了哪些processor流程缩略图,
第二个右箭头,点击会跳到你当前查看的是哪个processor.

根据兴趣查看下新弹出窗口三个标签内容,提及下第二个ATTRIBUTES标签,我标红框的那个地方有个cdc.sequence.id属性.
我个人不负责任猜测理解是:CaptureChangeMysql 读取binlog自己打上的一个序列号.
可以有什么用呢?后文用它最后汇总排序作为一个依据

查看具体一条数据内容点第三个标签CONTENT,点击下面红框里的VIEW可以查看单条binlog数据内容(因为我们binlog是Row格式的所以是单条对应一条数据记录),也可以点击旁边的download 下载这条数据.

点击VIEW后如下图,可以选择下View as的下拉框内容:选择formatted格式化下,否则就是一行代码不好查看.
type:表示是删除操作类型
database:表示来源于哪个数据库名
table_name:数据表名
columns:列信息
columns.id数据表里的第几列(从1开始)
columns.name列名称
columns.column_type:数据类型的对应数字
columns.value:这列的值是多少
columns.last_value: update操作类型会有,记录修改前的值是多少.

TIPS:我怎么查看Concetion里的数据?
右键Conection,选择List queue,类似查看Processor的界面,不再赘述(老子懒了,写不动了 )

整理binlog的数据格式
NIFI读取的mysql binlog日志是json格式数据,里面会有一些我们不需要的key,value,为了方便给hbase操作使用,需要处理过滤下.
这就涉及到一门语言JOLT(折磨我最久的一个环节…至今还没掌握皮毛)
用于处理JSON数据格式转换为想要的数据格式.
本文开头提到的这个网站使用体验下Jolt
Jolt Transform Demo
本文只是简单把表属性全量的存储进Hbase的一个列簇下,需要取舍字段,根据需求自行研究Jolt语法来转换实现即可.
闲话至此,我们开始操作
- 先弄个JoltTransformJSON Processor进到工作区.
- 右键选择菜单configure
- 在SETTINGS标签可以在左上角Name下面给processor起个名字,右边自动终止关系勾选failure

- 设置PROPERTIES标签,
Jolt Transformation DSL 默认Chain就好,表示一次可以设置多个jolt操作配置,顺序执行.
其余也是默认值即可.
我们需要改动的就是Jolt Specification这一栏,
但是不着急,我们先点左下角的ADVANCED这个按钮.

会打开如下图Jolt测试界面
上面有红叉子的那个区域Jolt Specification是填写我们的Jolt语句的;
左下方区域JSON Input是输入要被处理前的Json数据.
右下方区域JSON Output是输出Input被jolt语句处理后的结果.
1
Jolt Specification区域输入以下内容
[
{
"operation": "shift",
"spec": {
"columns": {
"*": {
"@(value)": "@(1,name)"
}
}
}
}, {
"operation": "modify-default-beta",
"spec": {
"apid": "=concat('ap_',@(1,id))"
}
}
]
“operation”: “shift”:实现整理出key,value格式
“operation”: “modify-default-beta”:实现拼接了一个带前缀字符串的新字段apid,以及value是字符串ap_拼接id的value值.
PS: 刚才我们Jolt Transformation DSL选择是chain模式,所以支持执行2或多个operation来执行
JSON Input输入以下内容
{
"type" : "update",
"timestamp" : 1562211746000,
"binlog_filename" : "mysql-bin.000006",
"binlog_position" : 13105,
"database" : "dataBaseName",
"table_name" : "tableName",
"table_id" : 358,
"columns" : [ {
"id" : 1,
"name" : "id",
"column_type" : -5,
"last_value" : 195501,
"value" : 195501
}, {
"id" : 2,
"name" : "somecolumn",
"column_type" : -5,
"last_value" : 6103026,
"value" : 6103026
} ]
}
最后点击TRANSFORM按钮查看效果

测试没问题,可以复制我们调试好的Jolt Specification内容,返回刚才Jolt Specification这里,贴进去保存配置.
- 从RouteOnAttribute到JoltTransformJSON建立Conection,关系选择delete,insert,update.

保证执行顺序
拖进来EnforceOrder Processor,第一个SETTINGS标签勾选overtook

之后设置第三个标签SETTINGS
Group Identifier:分组标示,填写一个写死的1(因为本例没有啥分组)
Order Attribute:顺序标示属性cdc.sequence.id(曾记否,上面提到的这个属性,我们的第一个CaptureChangeMySQL processor读取binlog会生成这个属性)
Initial Order:起始顺序 0(因为强制顺序这个会严格按照不长1递增,所以遇到缺失中间顺序号的时候,可以调整下起始顺序,而且这个processor类似 第一个CaptureChangeMySQL Processor是有状态存储的,会记录当前Order Attribute处理到哪个顺序值了.如果记录处理到第100顺序号了,但是没有拿到101这个顺序号数据,101之后的所有数据会进入wati等待状态.
Wait TImeout:出于等待的数据,超过这个设置的时间会进入overtook状态(我们设置的overtook会终止这个processor的运行)
inactive Timeout:如果一个分组在设定的时间(下面图中30min)内没有新的数据来源,会判定为非活动组,会清空该组状态跟数据,导致迟到的数据一致无法匹配被清空的数据状态序号了,最终会等待超时,打到Overtook.
但是如果有需求需要反复重用组(每次重用从0开始),可以设置时间小一些.但是时间不能小于wait Timeout时间,

建立JoltTransformJSON processor到EnforceOrder Processor的Conection;
关系选择success.
建立RouteOnAttribute processor到EnforceOrder Processor的Conection;
关系选择ddl,begin,commit.(由于这几个操作我们最后会舍弃,所以没有像insert,update,delete进行额外处理)
建立EnforceOrder Processor 到自己的Conection
关系选择wait
新建一个LogAttribute processor
建立LogAttribute processor 到EnforceOrder Processor Conection
关系选择failure,skipped.
再新建个RouteOnAttribute Processor
可以直接复制上面那个RouteOnAttribute Processor,这里使用是为了将从EnforceOrder 拿到处理后以及排序好的数据进行再次分支处理.本文称其为RouteOnAttribute2
将EnforceOrder 到这第二个RouteOnAttribute2 Processor建立conection关系是success
新建EvaluateJsonPath Processor(删除操作分支)
配置参考下图,点右上角加号,添加一个属性用于下个hbase删除row时需要的rowkey.用表达式读取我们处理完的$.apid值(就是之前jolt处理新增的value是ap_前缀+id的那个key)

新建RouteOnAttribute2 Processor到EvaluateJsonPath Processor的Conection,关系选择delete.
再建个LogAttribute Processor,称其为LogAttribute2
建立EvaluateJsonPath Processor到LogAttribute2 Processor的Conection,关系选择failure,unmatch(用一个LogAttribute其实也够用了,不过为了方便清晰的分类查看成功或失败的记录,所以会多创建些)
新建DeleteHBaseRow Processor(删除操作实现)
配置参考下图,
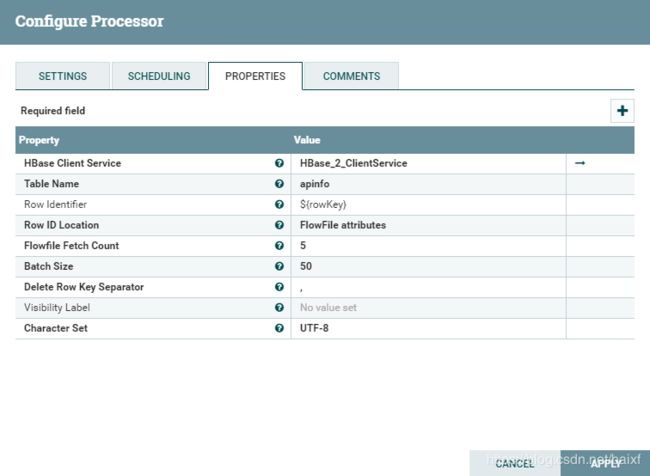
主要关注
Hbase Clinet Service(建立一个跟HBbase的链接服务,可复用)
点击后面空白区域,选择下拉create new service,再根据使用的Hbase版本选择合适的下拉框内容(本文用的hbase2,所以选择的Hbase_2_ClientService这个下拉框内容)
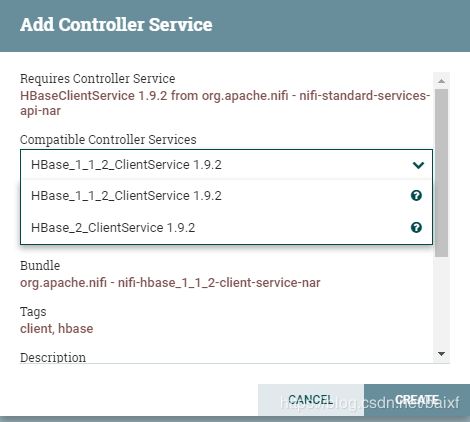
之后点击右边小箭头,进行配置,进入下图界面,点后面的齿轮进入配置界面,
配置详情参考如下,也就是配置下hbase的链接信息,根目录之类信息,根据自己情况酌情修改.都配置妥当,别忘了点闪电图标启用.

TableName,对应Hbase下的数据表名称
Row Identifier:删除hbase Row所需要的行键值,写表达式对应读取上一个EvaluateJsonPath Processor里的$.apid的属性key名称rowKey
Row ID LOcation选择FlowFile attributes
更多关于NIFI删除Hbase的操作,参考本文开头介绍的参考文章
Delete Row Key(s) using DeleteHBaseRow processor in NiFi
新建EvaluateJsonPath 到DeleteHBaseRow Processor的Conection,关系选择matched.
新建DeleteHBaseRow Processor 到LogAttribute2 Processor的Concetion,关系选择failure.
新建一个LogAttribute3 Processor
新建DeleteHBaseRow Processor 到LogAttribute3 Processor的Conection,关系选择success.
新建LogAttribute Processor(就是第一个LogAttribute)到LogAttribute3 Processor的Conection.关系选择success
新建PutHBaseJSON Processor(insert/update操作对应分支)
新建完,右键配置,修改PROPETIES,
HBase Client Service选择我们刚才创建好的那个 Hbase_2_ClientServcie(如果没有重命名的话)
Table Name :要写入HBase的数据表名称
Row Identifier Field Name:去json里哪个key作为行主键apid
Row Identifier Encoding Strategy:编码策略,我们是用的String,根据自己情况自行选择
Column Family:把这些json数据存入那个Family(列簇)中,下图是用的result

新建PutHBaseJSON Processor到LogAttribute2 Processor的Conection
关系选择Failure
新建PutHBaseJSON Processor到LogAttribute3 Processor的Conection
关系选择Success
启动整个流程测试效果
- 如果之前测试过,别忘了清空各个Conections里的 队列数据和CaptureChangeMySQL,EnforceOrder的state状态(右键 View State,点clear state)
- 单击空白区域点击下图的红框里的按钮,启动所有Processor,(也可以点闪电批量启动/停止service,那些需要点闪电启动的那帮家伙门)

TIPS:导出模板到xml文件
在页面右上角点击三道杠菜单,选择Templates
点击行最后面垃圾桶前面的按个按钮,可以导出XML进行备份或分享用.

